 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAda-MK: Adaptive MegaKernel Optimization via Automated DAG-based Search for LLM Inference
May 12, 2026When large language models (LLMs) serve real-time inference in commercial online advertising systems, end-to-end latency must be strictly bounded to the millisecond range. Yet every token generated during the decode phase triggers thousands of kernel launches, and kernel launch overhead alone can account for 14.6% of end-to-end inference time. MegaKernel eliminates launch overhead and inter-operator HBM round-trips by fusing multiple operators into a single persistent kernel. However, existing MegaKernel implementations face a fundamental tension between portability and efficiency on resource-constrained GPUs such as NVIDIA Ada: hand-tuned solutions are tightly coupled to specific architectures and lack portability, while auto-compiled approaches introduce runtime dynamic scheduling whose branch penalties are unacceptable in latency-critical settings. We observe that under a fixed deployment configuration, the optimal execution path of a MegaKernel is uniquely determined, and runtime dynamic decision-making can be entirely hoisted to compile time. Building on this insight, we propose Ada-MK: (1) a three-dimensional shared-memory constraint model combined with K-dimension splitting that reduces peak shared memory usage by 50%; (2) MLIR-based fine-grained DAG offline search that solidifies the optimal execution path, completely eliminating runtime branching; and (3) a heterogeneous hybrid inference engine that embeds MegaKernel as a plugin into TensorRT-LLM, combining high-throughput Prefill with low-latency Decode. On an NVIDIA L20, Ada-MK improves single-batch throughput by up to 23.6% over vanilla TensorRT-LLM and 50.2% over vLLM, achieving positive gains across all tested scenarios--the first industrial deployment of MegaKernel in a commercial online advertising system.
Efficient LLM-based Advertising via Model Compression and Parallel Verification
May 12, 2026Large language models (LLMs) have shown remarkable potential in advertising scenarios such as ad creative generation and targeted advertising. However, deploying LLMs in real-time advertising systems poses significant challenges due to their high inference latency and computational cost. In this paper, we propose an Efficient Generative Targeting framework that integrates adaptive group quantization, layer-adaptive hierarchical sparsification, and prefix-tree parallel verification to accelerate LLM inference while preserving generation quality. Extensive experiments on two real-world advertising scenarios demonstrate that our framework achieves significant speedup with acceptable quality degradation, making it operationally viable for practical deployments.
Communication-Efficient TeraByte-Scale Model Training Framework for Online Advertising
Jan 05, 2022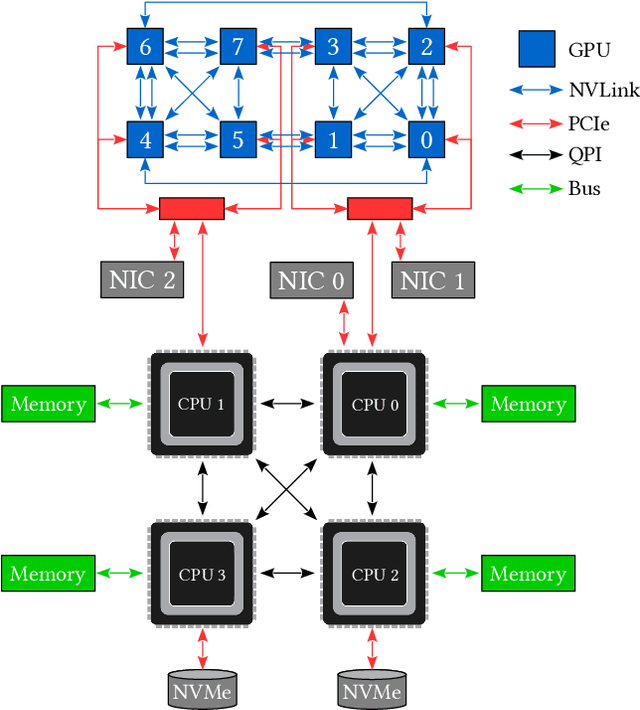
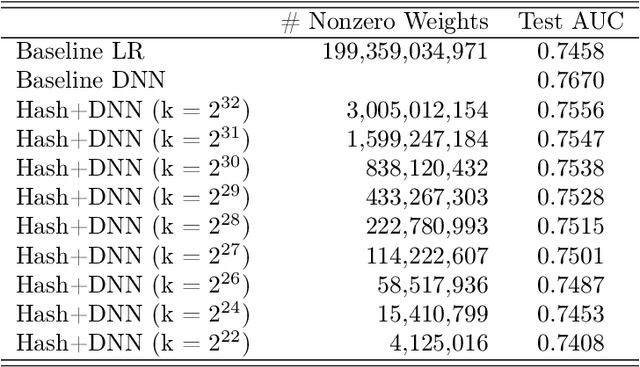
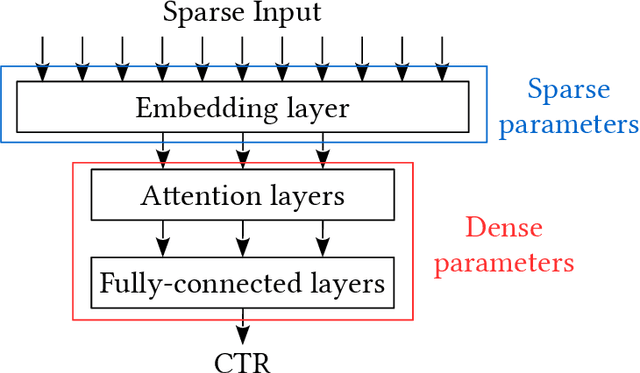
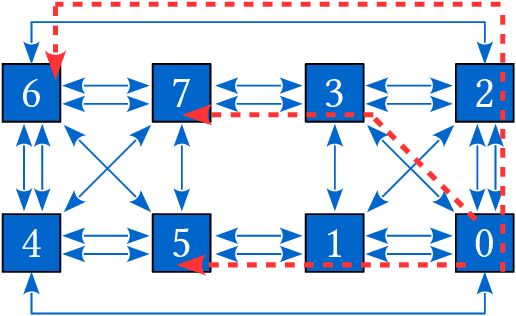
Click-Through Rate (CTR) prediction is a crucial component in the online advertising industry. In order to produce a personalized CTR prediction, an industry-level CTR prediction model commonly takes a high-dimensional (e.g., 100 or 1000 billions of features) sparse vector (that is encoded from query keywords, user portraits, etc.) as input. As a result, the model requires Terabyte scale parameters to embed the high-dimensional input. Hierarchical distributed GPU parameter server has been proposed to enable GPU with limited memory to train the massive network by leveraging CPU main memory and SSDs as secondary storage. We identify two major challenges in the existing GPU training framework for massive-scale ad models and propose a collection of optimizations to tackle these challenges: (a) the GPU, CPU, SSD rapidly communicate with each other during the training. The connections between GPUs and CPUs are non-uniform due to the hardware topology. The data communication route should be optimized according to the hardware topology; (b) GPUs in different computing nodes frequently communicates to synchronize parameters. We are required to optimize the communications so that the distributed system can become scalable. In this paper, we propose a hardware-aware training workflow that couples the hardware topology into the algorithm design. To reduce the extensive communication between computing nodes, we introduce a $k$-step model merging algorithm for the popular Adam optimizer and provide its convergence rate in non-convex optimization. To the best of our knowledge, this is the first application of $k$-step adaptive optimization method in industrial-level CTR model training. The numerical results on real-world data confirm that the optimized system design considerably reduces the training time of the massive model, with essentially no loss in accuracy.