 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Optical Flow Estimation for Time-of-Flight
Oct 11, 2022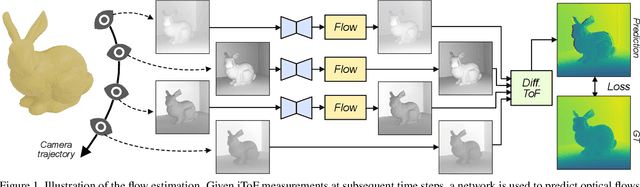
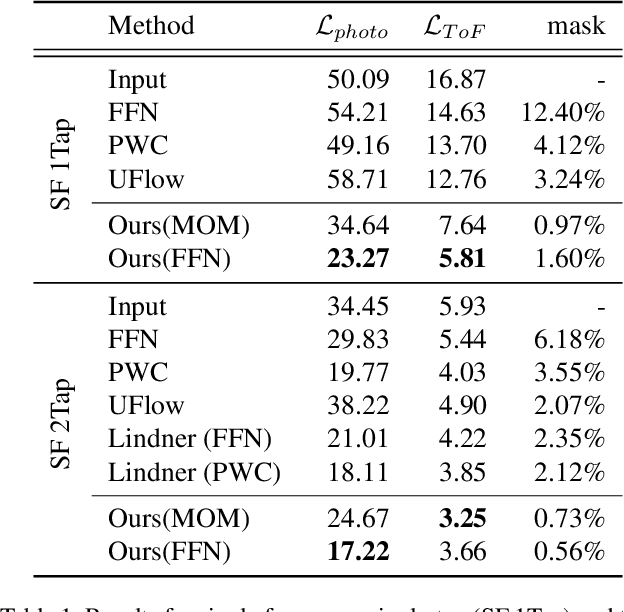
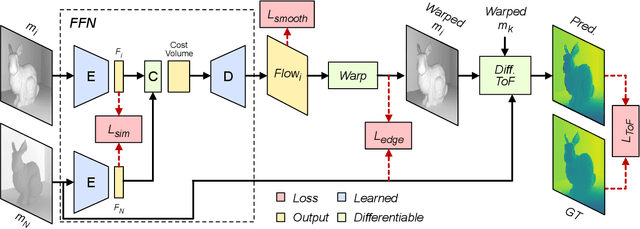
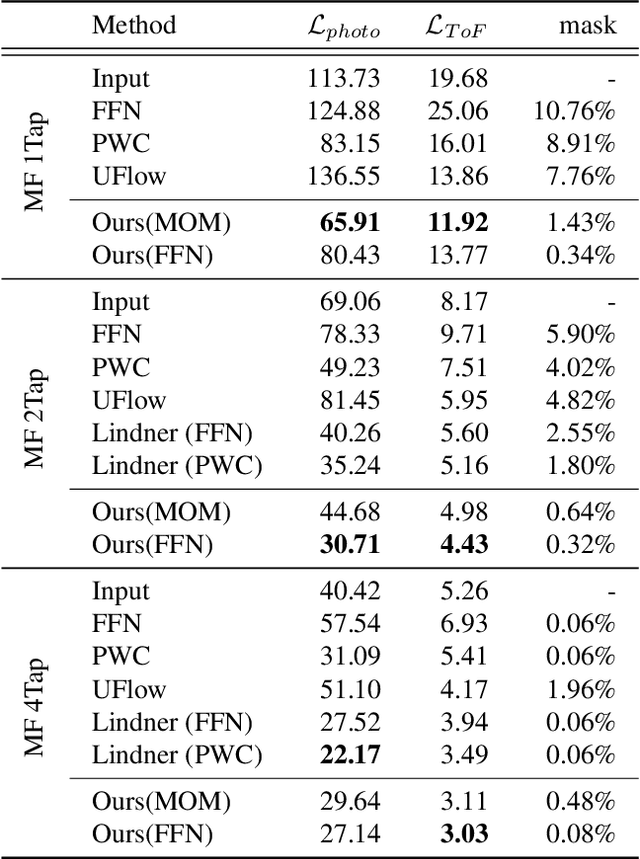
Indirect Time-of-Flight (iToF) cameras are a widespread type of 3D sensor, which perform multiple captures to obtain depth values of the captured scene. While recent approaches to correct iToF depths achieve high performance when removing multi-path-interference and sensor noise, little research has been done to tackle motion artifacts. In this work we propose a training algorithm, which allows to supervise Optical Flow (OF) networks directly on the reconstructed depth, without the need of having ground truth flows. We demonstrate that this approach enables the training of OF networks to align raw iToF measurements and compensate motion artifacts in the iToF depth images. The approach is evaluated for both single- and multi-frequency sensors as well as multi-tap sensors, and is able to outperform other motion compensation techniques.
Variance-Aware Weight Initialization for Point Convolutional Neural Networks
Dec 07, 2021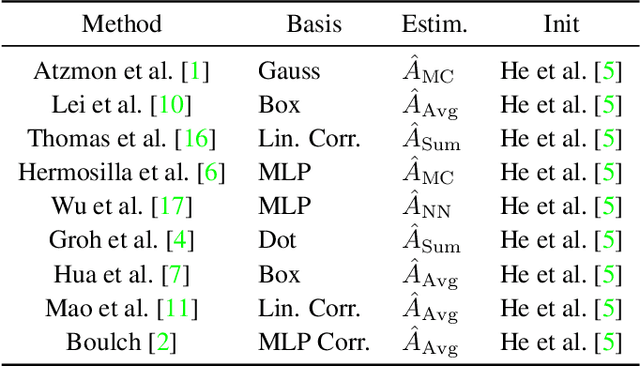
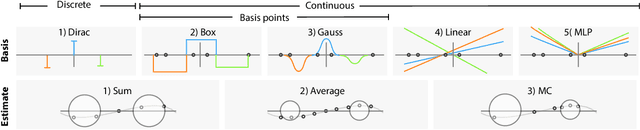
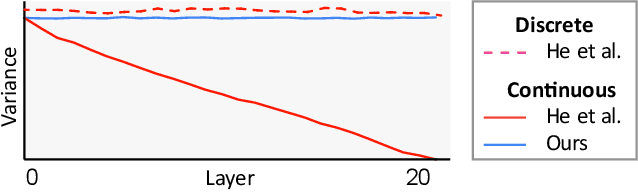
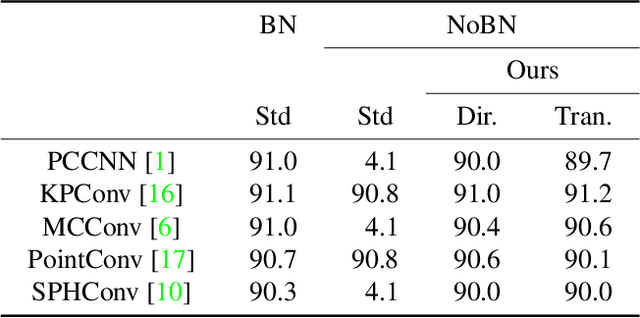
Appropriate weight initialization has been of key importance to successfully train neural networks. Recently, batch normalization has diminished the role of weight initialization by simply normalizing each layer based on batch statistics. Unfortunately, batch normalization has several drawbacks when applied to small batch sizes, as they are required to cope with memory limitations when learning on point clouds. While well-founded weight initialization strategies can render batch normalization unnecessary and thus avoid these drawbacks, no such approaches have been proposed for point convolutional networks. To fill this gap, we propose a framework to unify the multitude of continuous convolutions. This enables our main contribution, variance-aware weight initialization. We show that this initialization can avoid batch normalization while achieving similar and, in some cases, better performance.
RADU: Ray-Aligned Depth Update Convolutions for ToF Data Denoising
Nov 30, 2021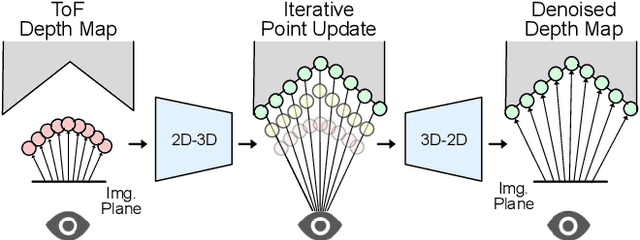
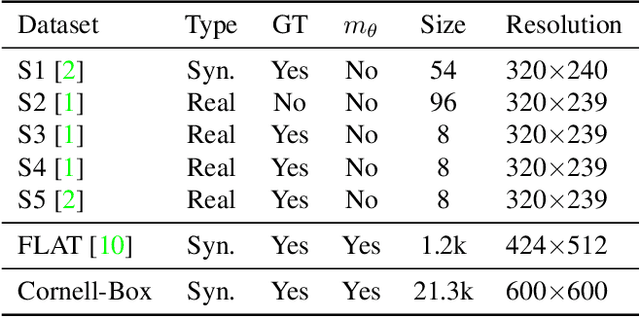
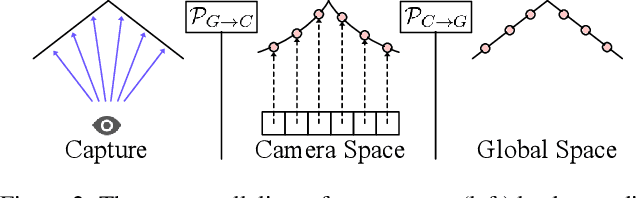
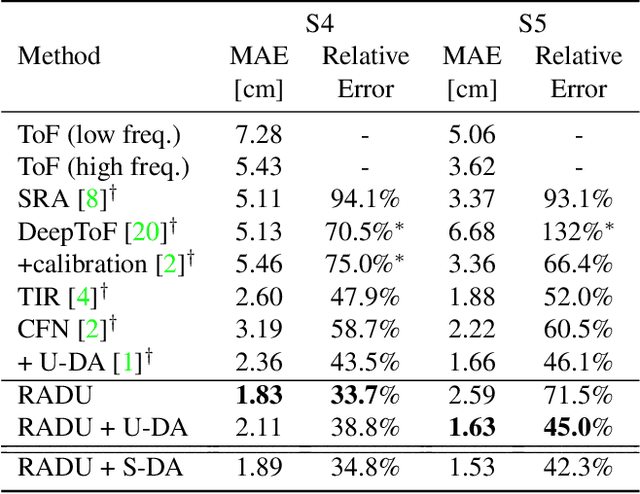
Time-of-Flight (ToF) cameras are subject to high levels of noise and distortions due to Multi-Path-Interference (MPI). While recent research showed that 2D neural networks are able to outperform previous traditional State-of-the-Art (SOTA) methods on denoising ToF-Data, little research on learning-based approaches has been done to make direct use of the 3D information present in depth images. In this paper, we propose an iterative denoising approach operating in 3D space, that is designed to learn on 2.5D data by enabling 3D point convolutions to correct the points' positions along the view direction. As labeled real world data is scarce for this task, we further train our network with a self-training approach on unlabeled real world data to account for real world statistics. We demonstrate that our method is able to outperform SOTA methods on several datasets, including two real world datasets and a new large-scale synthetic data set introduced in this paper.
Enabling Viewpoint Learning through Dynamic Label Generation
Mar 10, 2020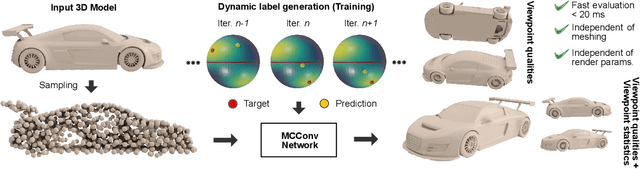
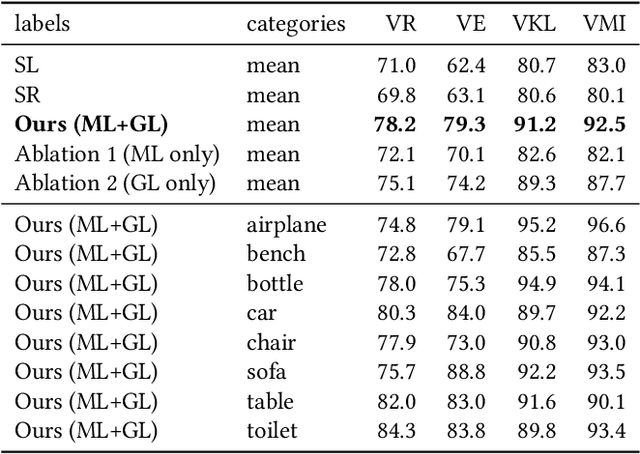
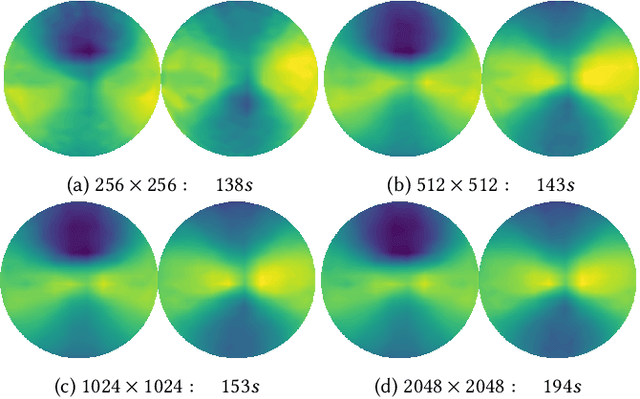
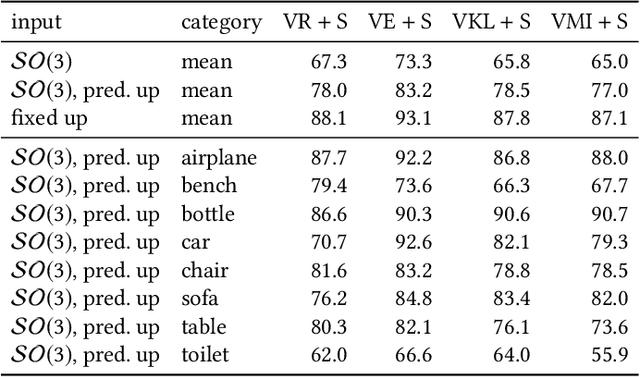
Optimal viewpoint prediction is an essential task in many computer graphicsapplications. Unfortunately, common viewpoint qualities suffer from majordrawbacks: dependency on clean surface meshes, which are not alwaysavailable, insensitivity to upright orientation, and the lack of closed-formexpressions, which requires a costly sampling process involving rendering.We overcome these limitations through a 3D deep learning approach, whichsolely exploits vertex coordinate information to predict optimal viewpointsunder upright orientation, while reflecting both informational content andhuman preference analysis. To enable this approach we propose a dynamiclabel generation strategy, which resolves inherent label ambiguities dur-ing training. In contrast to previous viewpoint prediction methods, whichevaluate many rendered views, we directly learn on the 3D mesh, and arethus independent from rendering. Furthermore, by exploiting unstructuredlearning, we are independent of mesh discretization. We show how the pro-posed technology enables learned prediction from model to viewpoints fordifferent object categories and viewpoint qualities. Additionally, we showthat prediction times are reduced from several minutes to a fraction of asecond, as compared to viewpoint quality evaluation. We will release thecode and training data, which will to our knowledge be the biggest viewpointquality dataset available.