 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Experimental Study of the Impact of Pre-training on the Pruning of a Convolutional Neural Network
Dec 15, 2021
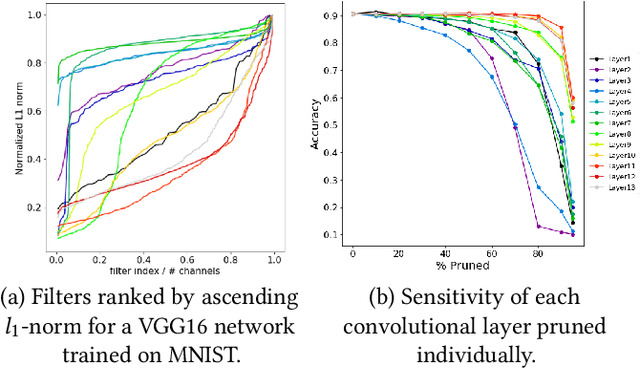
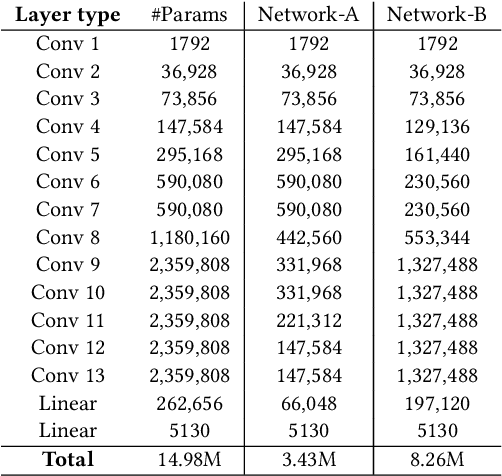
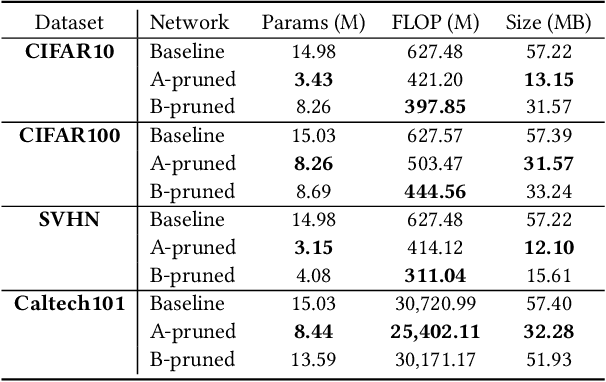
In recent years, deep neural networks have known a wide success in various application domains. However, they require important computational and memory resources, which severely hinders their deployment, notably on mobile devices or for real-time applications. Neural networks usually involve a large number of parameters, which correspond to the weights of the network. Such parameters, obtained with the help of a training process, are determinant for the performance of the network. However, they are also highly redundant. The pruning methods notably attempt to reduce the size of the parameter set, by identifying and removing the irrelevant weights. In this paper, we examine the impact of the training strategy on the pruning efficiency. Two training modalities are considered and compared: (1) fine-tuned and (2) from scratch. The experimental results obtained on four datasets (CIFAR10, CIFAR100, SVHN and Caltech101) and for two different CNNs (VGG16 and MobileNet) demonstrate that a network that has been pre-trained on a large corpus (e.g. ImageNet) and then fine-tuned on a particular dataset can be pruned much more efficiently (up to 80% of parameter reduction) than the same network trained from scratch.
Employing chunk size adaptation to overcome concept drift
Oct 25, 2021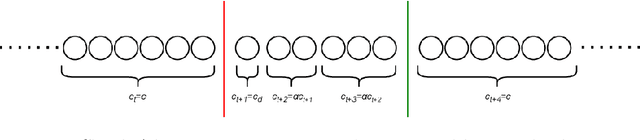
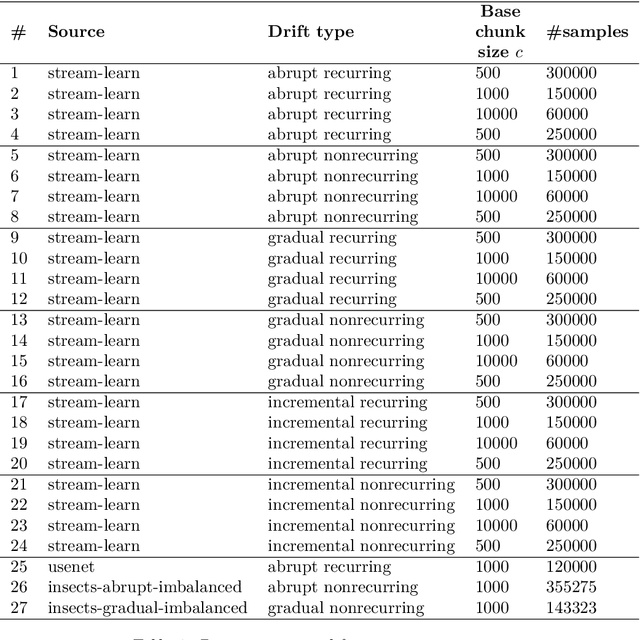
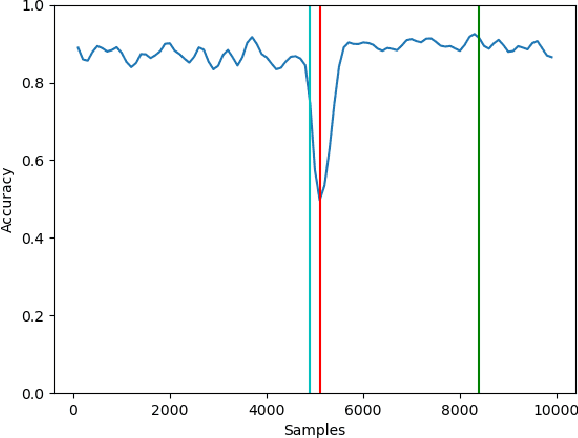
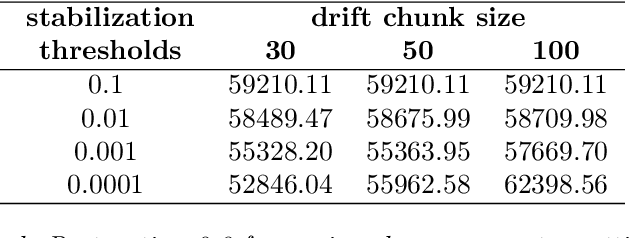
Modern analytical systems must be ready to process streaming data and correctly respond to data distribution changes. The phenomenon of changes in data distributions is called concept drift, and it may harm the quality of the used models. Additionally, the possibility of concept drift appearance causes that the used algorithms must be ready for the continuous adaptation of the model to the changing data distributions. This work focuses on non-stationary data stream classification, where a classifier ensemble is used. To keep the ensemble model up to date, the new base classifiers are trained on the incoming data blocks and added to the ensemble while, at the same time, outdated models are removed from the ensemble. One of the problems with this type of model is the fast reaction to changes in data distributions. We propose a new Chunk Adaptive Restoration framework that can be adapted to any block-based data stream classification algorithm. The proposed algorithm adjusts the data chunk size in the case of concept drift detection to minimize the impact of the change on the predictive performance of the used model. The conducted experimental research, backed up with the statistical tests, has proven that Chunk Adaptive Restoration significantly reduces the model's restoration time.
Recursive Feasibility Guided Optimal Parameter Adaptation of Differential Convex Optimization Policies for Safety-Critical Systems
Sep 22, 2021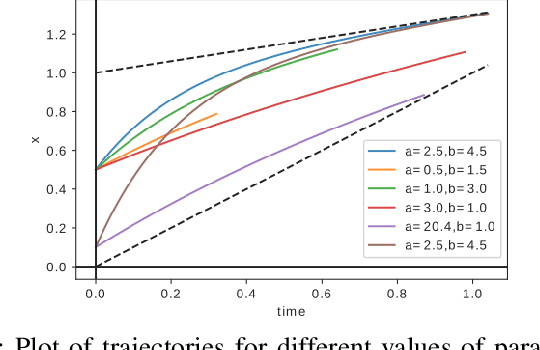
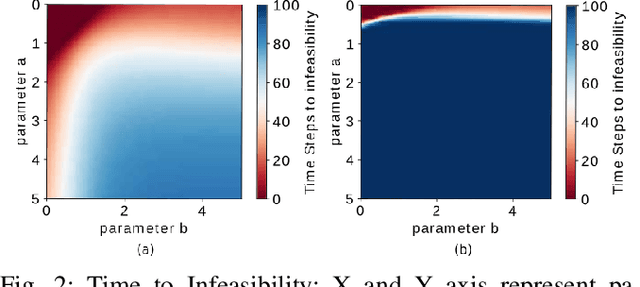
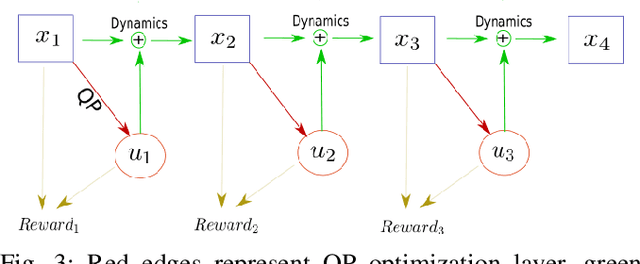
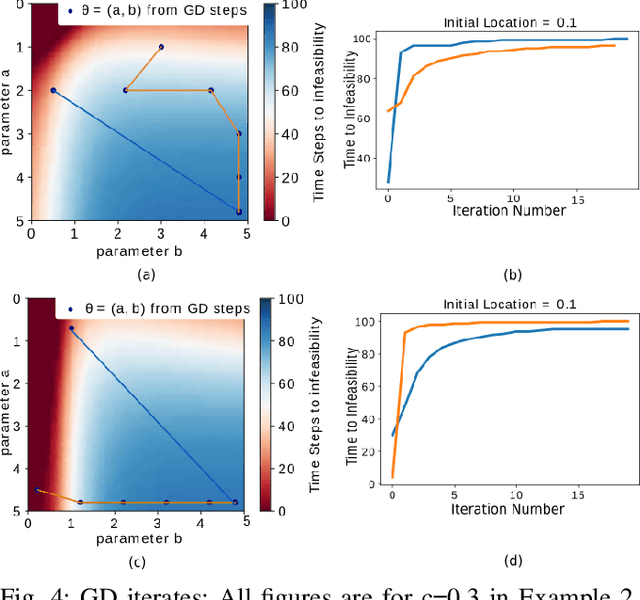
Quadratic programs (QPs) that enforce control barrier functions (CBFs) have become popular for safety-critical control synthesis, in part due to their ease of implementation and constraint specification. The construction of valid CBFs, however, is not straightforward, and for arbitrarily chosen parameters of the QP, the system trajectories may enter states at which the QP either eventually becomes infeasible, or may not achieve desired performance. In this work, we pose the control synthesis problem as a differential policy whose parameters are optimized for performance over a time horizon at high level, thus resulting in a bi-level optimization routine. In the absence of knowledge of the set of feasible parameters, we develop a Recursive Feasibility Guided Gradient Descent approach for updating the parameters of QP so that the new solution performs at least as well as previous solution. By considering the dynamical system as a directed graph over time, this work presents a novel way of optimizing performance of a QP controller over a time horizon for multiple CBFs by (1) using the gradient of its solution with respect to its parameters by employing sensitivity analysis, and (2) backpropagating these as well as system dynamics gradients to update parameters while maintaining feasibility of QPs.
Optimizing Bayesian acquisition functions in Gaussian Processes
Nov 09, 2021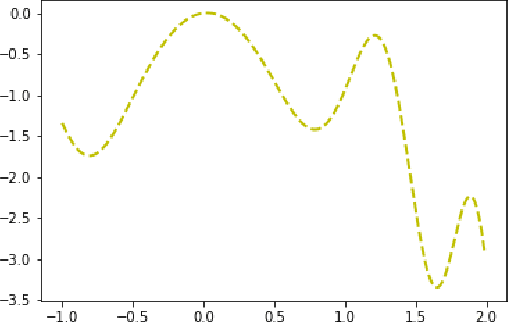

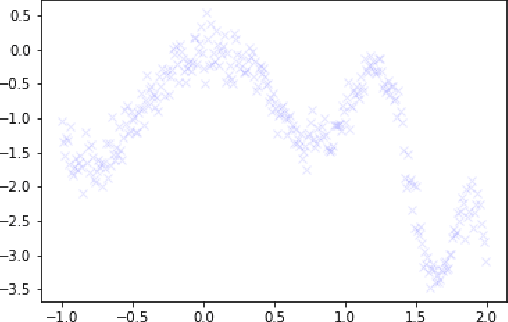
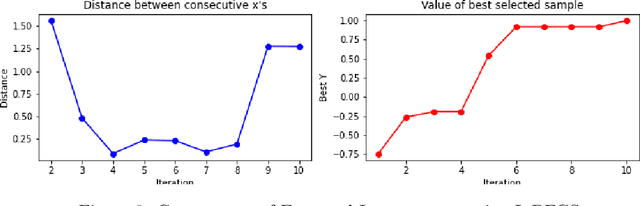
Bayesian Optimization is an effective method for searching the global maxima of an objective function especially if the function is unknown. The process comprises of using a surrogate function and choosing an acquisition function followed by optimizing the acquisition function to find the next sampling point. This paper analyzes different acquistion functions like Maximum Probability of Improvement and Expected Improvement and various optimizers like L-BFGS and TNC to optimize the acquisitions functions for finding the next sampling point. Along with the analysis of time taken, the paper also shows the importance of position of initial samples chosen.
Fusion and Orthogonal Projection for Improved Face-Voice Association
Dec 20, 2021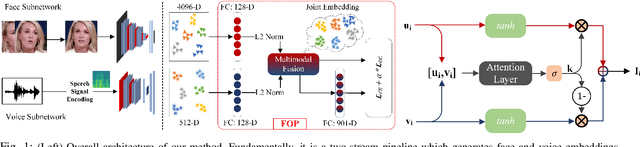
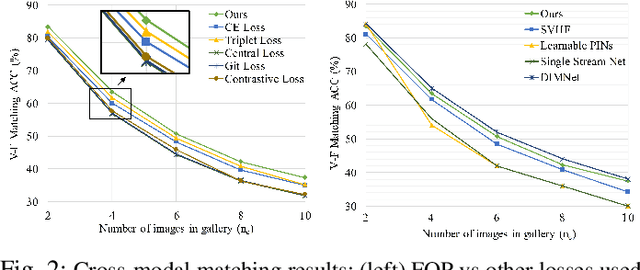
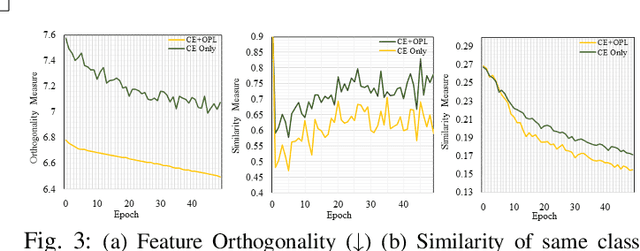
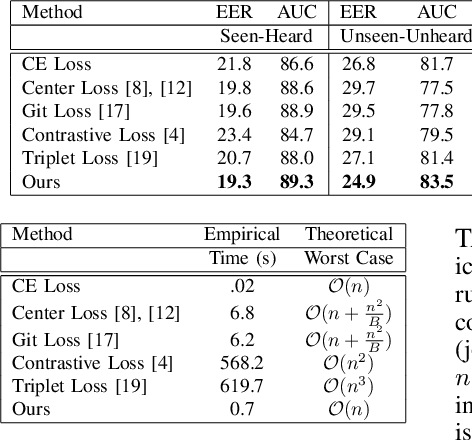
We study the problem of learning association between face and voice, which is gaining interest in the computer vision community lately. Prior works adopt pairwise or triplet loss formulations to learn an embedding space amenable for associated matching and verification tasks. Albeit showing some progress, such loss formulations are, however, restrictive due to dependency on distance-dependent margin parameter, poor run-time training complexity, and reliance on carefully crafted negative mining procedures. In this work, we hypothesize that enriched feature representation coupled with an effective yet efficient supervision is necessary in realizing a discriminative joint embedding space for improved face-voice association. To this end, we propose a light-weight, plug-and-play mechanism that exploits the complementary cues in both modalities to form enriched fused embeddings and clusters them based on their identity labels via orthogonality constraints. We coin our proposed mechanism as fusion and orthogonal projection (FOP) and instantiate in a two-stream pipeline. The overall resulting framework is evaluated on a large-scale VoxCeleb dataset with a multitude of tasks, including cross-modal verification and matching. Results show that our method performs favourably against the current state-of-the-art methods and our proposed supervision formulation is more effective and efficient than the ones employed by the contemporary methods.
Probabilistic Model of Narratives Over Topical Trends in Social Media: A Discrete Time Model
Apr 14, 2020
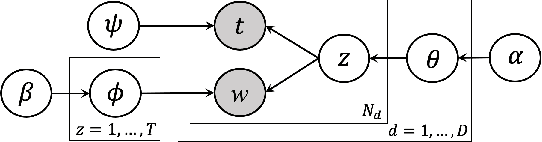
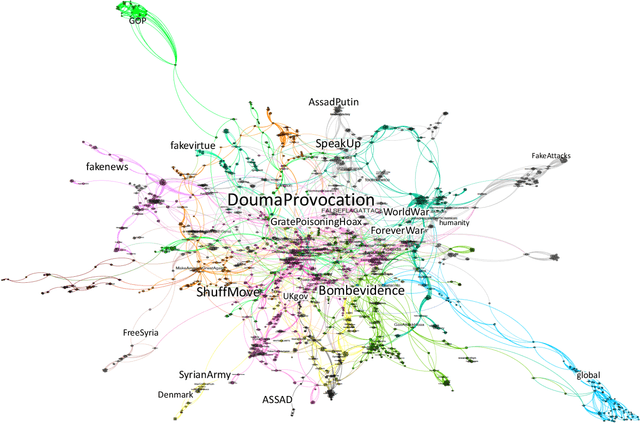

Online social media platforms are turning into the prime source of news and narratives about worldwide events. However,a systematic summarization-based narrative extraction that can facilitate communicating the main underlying events is lacking. To address this issue, we propose a novel event-based narrative summary extraction framework. Our proposed framework is designed as a probabilistic topic model, with categorical time distribution, followed by extractive text summarization. Our topic model identifies topics' recurrence over time with a varying time resolution. This framework not only captures the topic distributions from the data, but also approximates the user activity fluctuations over time. Furthermore, we define significance-dispersity trade-off (SDT) as a comparison measure to identify the topic with the highest lifetime attractiveness in a timestamped corpus. We evaluate our model on a large corpus of Twitter data, including more than one million tweets in the domain of the disinformation campaigns conducted against the White Helmets of Syria. Our results indicate that the proposed framework is effective in identifying topical trends, as well as extracting narrative summaries from text corpus with timestamped data.
The Effectiveness of Discretization in Forecasting: An Empirical Study on Neural Time Series Models
May 20, 2020
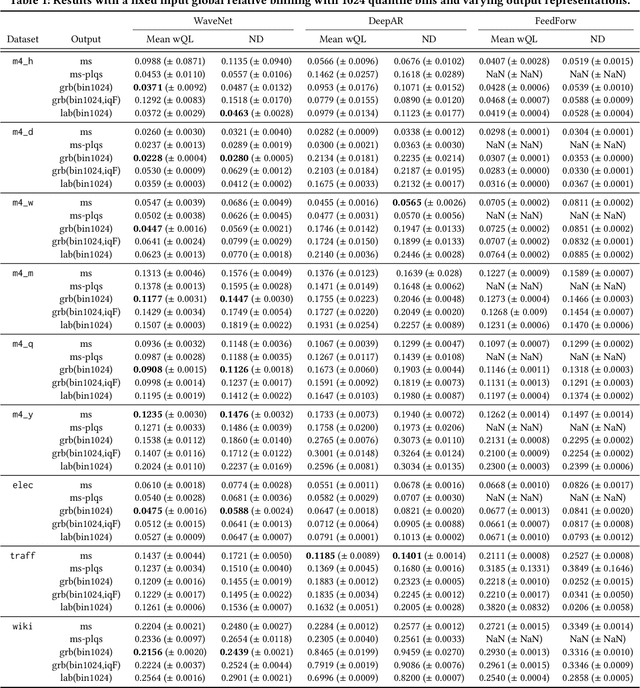
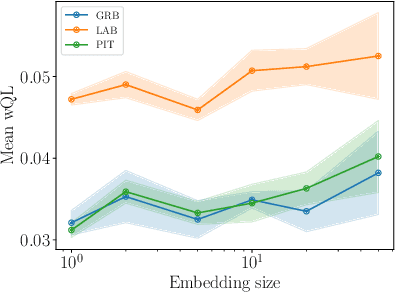
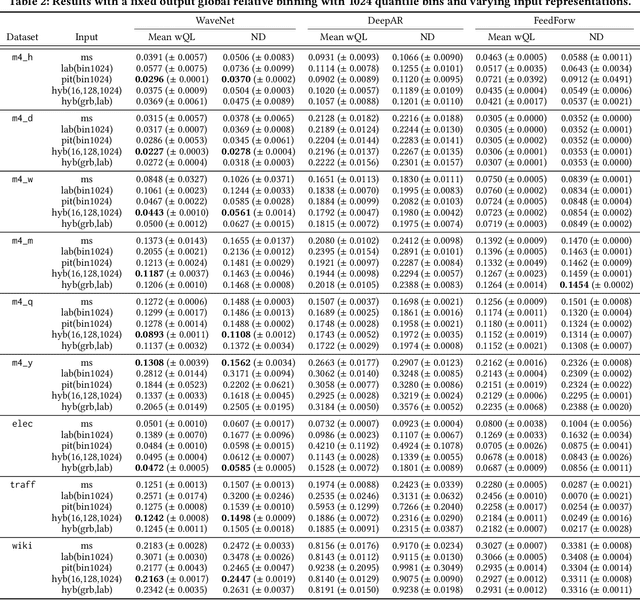
Time series modeling techniques based on deep learning have seen many advancements in recent years, especially in data-abundant settings and with the central aim of learning global models that can extract patterns across multiple time series. While the crucial importance of appropriate data pre-processing and scaling has often been noted in prior work, most studies focus on improving model architectures. In this paper we empirically investigate the effect of data input and output transformations on the predictive performance of several neural forecasting architectures. In particular, we investigate the effectiveness of several forms of data binning, i.e. converting real-valued time series into categorical ones, when combined with feed-forward, recurrent neural networks, and convolution-based sequence models. In many non-forecasting applications where these models have been very successful, the model inputs and outputs are categorical (e.g. words from a fixed vocabulary in natural language processing applications or quantized pixel color intensities in computer vision). For forecasting applications, where the time series are typically real-valued, various ad-hoc data transformations have been proposed, but have not been systematically compared. To remedy this, we evaluate the forecasting accuracy of instances of the aforementioned model classes when combined with different types of data scaling and binning. We find that binning almost always improves performance (compared to using normalized real-valued inputs), but that the particular type of binning chosen is of lesser importance.
LDDMM meets GANs: Generative Adversarial Networks for diffeomorphic registration
Nov 24, 2021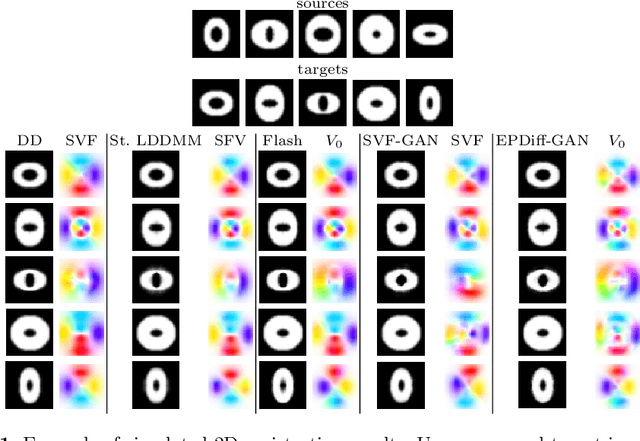
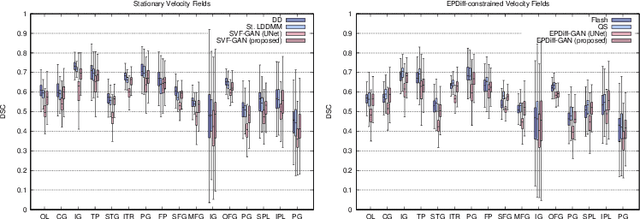
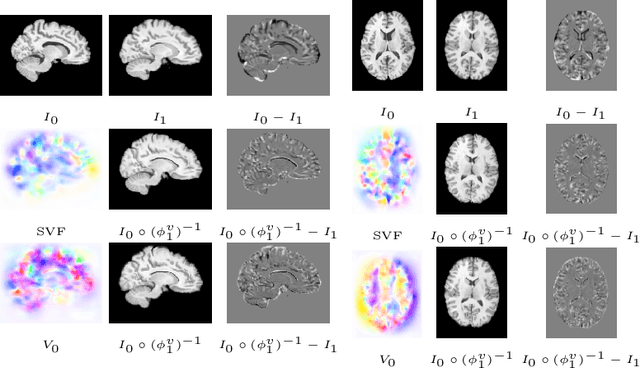
The purpose of this work is to contribute to the state of the art of deep-learning methods for diffeomorphic registration. We propose an adversarial learning LDDMM method for pairs of 3D mono-modal images based on Generative Adversarial Networks. The method is inspired by the recent literature for deformable image registration with adversarial learning. We combine the best performing generative, discriminative, and adversarial ingredients from the state of the art within the LDDMM paradigm. We have successfully implemented two models with the stationary and the EPDiff-constrained non-stationary parameterizations of diffeomorphisms. Our unsupervised and data-hungry approach has shown a competitive performance with respect to a benchmark supervised and rich-data approach. In addition, our method has shown similar results to model-based methods with a computational time under one second.
Regret Lower Bounds for Learning Linear Quadratic Gaussian Systems
Jan 05, 2022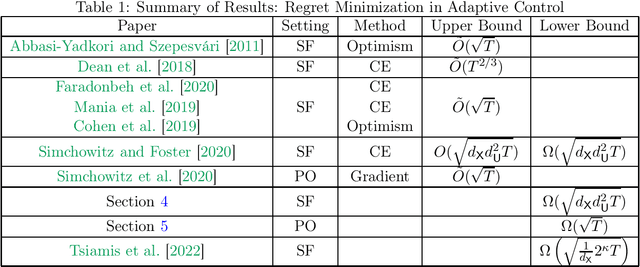
This paper presents local minimax regret lower bounds for adaptively controlling linear-quadratic-Gaussian (LQG) systems. We consider smoothly parametrized instances and provide an understanding of when logarithmic regret is impossible which is both instance specific and flexible enough to take problem structure into account. This understanding relies on two key notions: That of local-uninformativeness; when the optimal policy does not provide sufficient excitation for identification of the optimal policy, and yields a degenerate Fisher information matrix; and that of information-regret-boundedness, when the small eigenvalues of a policy-dependent information matrix are boundable in terms of the regret of that policy. Combined with a reduction to Bayesian estimation and application of Van Trees' inequality, these two conditions are sufficient for proving regret bounds on order of magnitude $\sqrt{T}$ in the time horizon, $T$. This method yields lower bounds that exhibit tight dimensional dependencies and scale naturally with control-theoretic problem constants. For instance, we are able to prove that systems operating near marginal stability are fundamentally hard to learn to control. We further show that large classes of systems satisfy these conditions, among them any state-feedback system with both $A$- and $B$-matrices unknown. Most importantly, we also establish that a nontrivial class of partially observable systems, essentially those that are over-actuated, satisfy these conditions, thus providing a $\sqrt{T}$ lower bound also valid for partially observable systems. Finally, we turn to two simple examples which demonstrate that our lower bound captures classical control-theoretic intuition: our lower bounds diverge for systems operating near marginal stability or with large filter gain -- these can be arbitrarily hard to (learn to) control.
Unsupervised Statistical Learning for Die Analysis in Ancient Numismatics
Dec 01, 2021
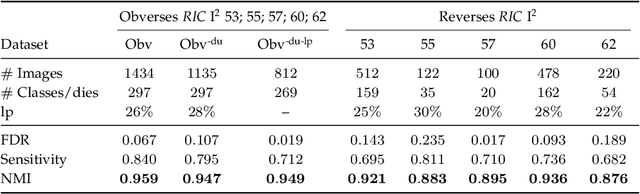
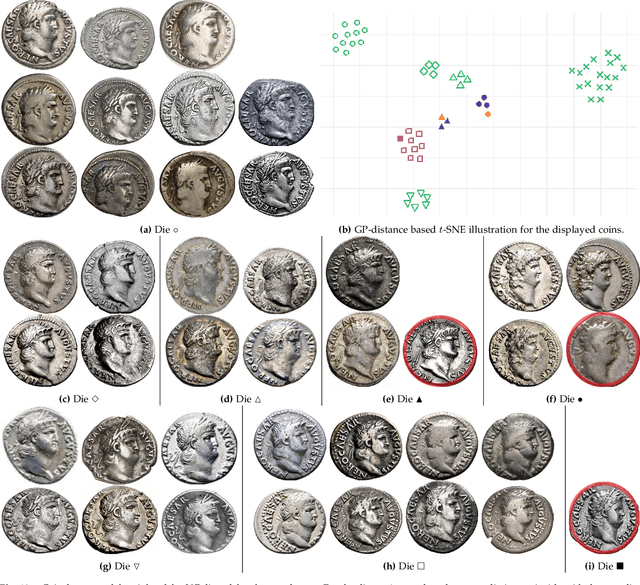
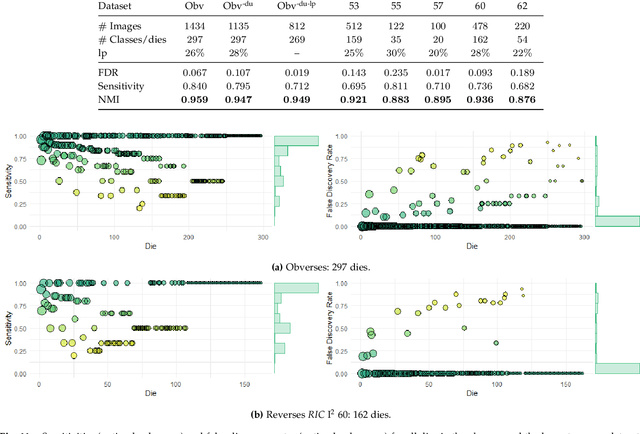
Die analysis is an essential numismatic method, and an important tool of ancient economic history. Yet, manual die studies are too labor-intensive to comprehensively study large coinages such as those of the Roman Empire. We address this problem by proposing a model for unsupervised computational die analysis, which can reduce the time investment necessary for large-scale die studies by several orders of magnitude, in many cases from years to weeks. From a computer vision viewpoint, die studies present a challenging unsupervised clustering problem, because they involve an unknown and large number of highly similar semantic classes of imbalanced sizes. We address these issues through determining dissimilarities between coin faces derived from specifically devised Gaussian process-based keypoint features in a Bayesian distance clustering framework. The efficacy of our method is demonstrated through an analysis of 1135 Roman silver coins struck between 64-66 C.E..