 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatio-Temporal Urban Knowledge Graph Enabled Mobility Prediction
Nov 10, 2021

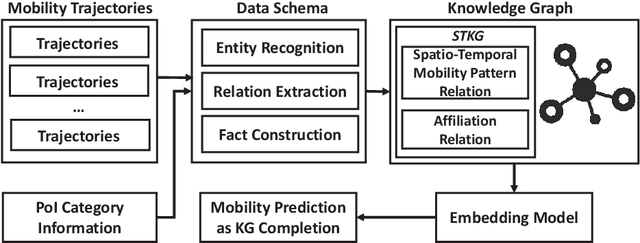

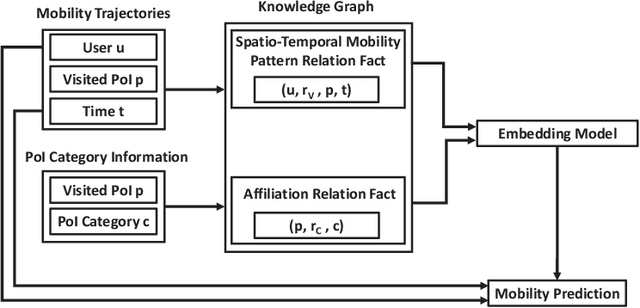
With the rapid development of the mobile communication technology, mobile trajectories of humans are massively collected by Internet service providers (ISPs) and application service providers (ASPs). On the other hand, the rising paradigm of knowledge graph (KG) provides us a promising solution to extract structured "knowledge" from massive trajectory data. In this paper, we focus on modeling users' spatio-temporal mobility patterns based on knowledge graph techniques, and predicting users' future movement based on the "knowledge'' extracted from multiple sources in a cohesive manner. Specifically, we propose a new type of knowledge graph, i.e., spatio-temporal urban knowledge graph (STKG), where mobility trajectories, category information of venues, and temporal information are jointly modeled by the facts with different relation types in STKG. The mobility prediction problem is converted to the knowledge graph completion problem in STKG. Further, a complex embedding model with elaborately designed scoring functions is proposed to measure the plausibility of facts in STKG to solve the knowledge graph completion problem, which considers temporal dynamics of the mobility patterns and utilizes PoI categories as the auxiliary information and background knowledge. Extensive evaluations confirm the high accuracy of our model in predicting users' mobility, i.e., improving the accuracy by 5.04% compared with the state-of-the-art algorithms. In addition, PoI categories as the background knowledge and auxiliary information are confirmed to be helpful by improving the performance by 3.85% in terms of accuracy. Additionally, experiments show that our proposed method is time-efficient by reducing the computational time by over 43.12% compared with existing methods.
Uncertainty-Aware Cascaded Dilation Filtering for High-Efficiency Deraining
Jan 07, 2022



Deraining is a significant and fundamental computer vision task, aiming to remove the rain streaks and accumulations in an image or video captured under a rainy day. Existing deraining methods usually make heuristic assumptions of the rain model, which compels them to employ complex optimization or iterative refinement for high recovery quality. This, however, leads to time-consuming methods and affects the effectiveness for addressing rain patterns deviated from from the assumptions. In this paper, we propose a simple yet efficient deraining method by formulating deraining as a predictive filtering problem without complex rain model assumptions. Specifically, we identify spatially-variant predictive filtering (SPFilt) that adaptively predicts proper kernels via a deep network to filter different individual pixels. Since the filtering can be implemented via well-accelerated convolution, our method can be significantly efficient. We further propose the EfDeRain+ that contains three main contributions to address residual rain traces, multi-scale, and diverse rain patterns without harming the efficiency. First, we propose the uncertainty-aware cascaded predictive filtering (UC-PFilt) that can identify the difficulties of reconstructing clean pixels via predicted kernels and remove the residual rain traces effectively. Second, we design the weight-sharing multi-scale dilated filtering (WS-MS-DFilt) to handle multi-scale rain streaks without harming the efficiency. Third, to eliminate the gap across diverse rain patterns, we propose a novel data augmentation method (i.e., RainMix) to train our deep models. By combining all contributions with sophisticated analysis on different variants, our final method outperforms baseline methods on four single-image deraining datasets and one video deraining dataset in terms of both recovery quality and speed.
Cinderella's shoe won't fit Soundarya: An audit of facial processing tools on Indian faces
Dec 17, 2021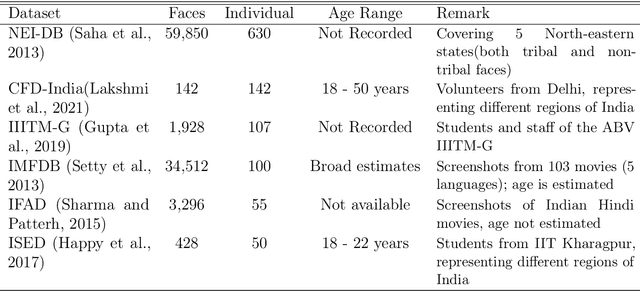
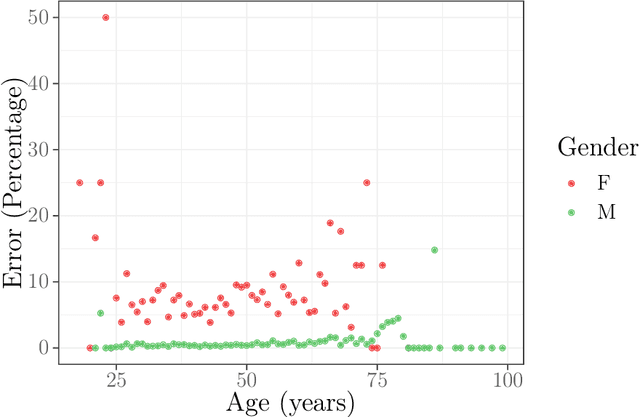
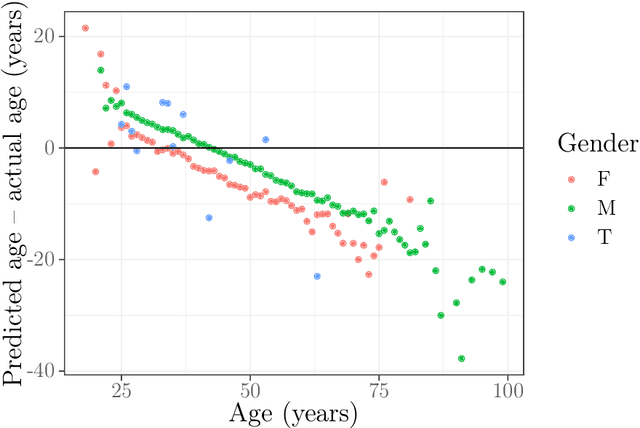
The increasing adoption of facial processing systems in India is fraught with concerns of privacy, transparency, accountability, and missing procedural safeguards. At the same time, we also know very little about how these technologies perform on the diverse features, characteristics, and skin tones of India's 1.34 billion-plus population. In this paper, we test the face detection and facial analysis functions of four commercial facial processing tools on a dataset of Indian faces. The tools display varying error rates in the face detection and gender and age classification functions. The gender classification error rate for Indian female faces is consistently higher compared to that of males -- the highest female error rate being 14.68%. In some cases, this error rate is much higher than that shown by previous studies for females of other nationalities. Age classification errors are also high. Despite taking into account an acceptable error margin of plus or minus 10 years from a person's actual age, age prediction failures are in the range of 14.3% to 42.2%. These findings point to the limited accuracy of facial processing tools, particularly for certain demographic groups, and the need for more critical thinking before adopting such systems.
Traditional Chinese Synthetic Datasets Verified with Labeled Data for Scene Text Recognition
Nov 26, 2021

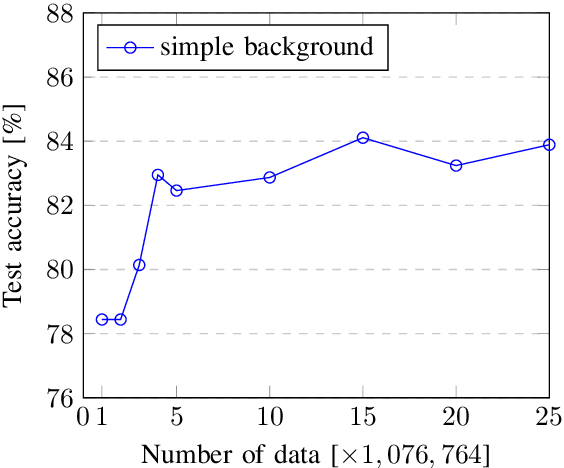
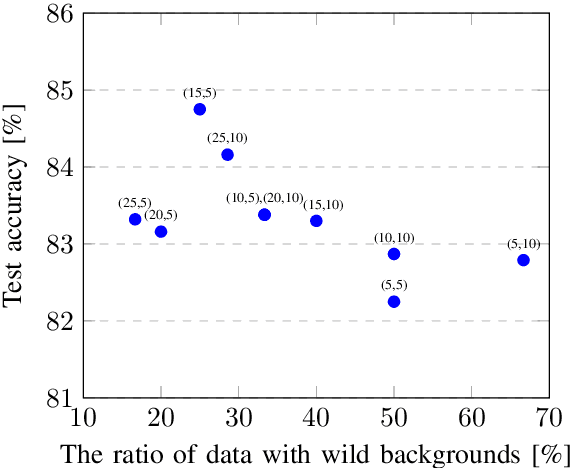
Scene text recognition (STR) has been widely studied in academia and industry. Training a text recognition model often requires a large amount of labeled data, but data labeling can be difficult, expensive, or time-consuming, especially for Traditional Chinese text recognition. To the best of our knowledge, public datasets for Traditional Chinese text recognition are lacking. This paper presents a framework for a Traditional Chinese synthetic data engine which aims to improve text recognition model performance. We generated over 20 million synthetic data and collected over 7,000 manually labeled data TC-STR 7k-word as the benchmark. Experimental results show that a text recognition model can achieve much better accuracy either by training from scratch with our generated synthetic data or by further fine-tuning with TC-STR 7k-word.
Nanorobot queue: Cooperative treatment of cancer based on team member communication and image processing
Nov 22, 2021

Although nanorobots have been used as clinical prescriptions for work such as gastroscopy, and even photoacoustic tomography technology has been proposed to control nanorobots to deliver drugs at designated delivery points in real time, and there are cases of eliminating "superbacteria" in blood through nanorobots, most technologies are immature, either with low efficiency or low accuracy, Either it can not be mass produced, so the most effective way to treat cancer diseases at this stage is through chemotherapy and radiotherapy. Patients are suffering and can not be cured. Therefore, this paper proposes an ideal model of a treatment method that can completely cure cancer, a cooperative treatment method based on nano robot queue through team member communication and computer vision image classification (target detection).
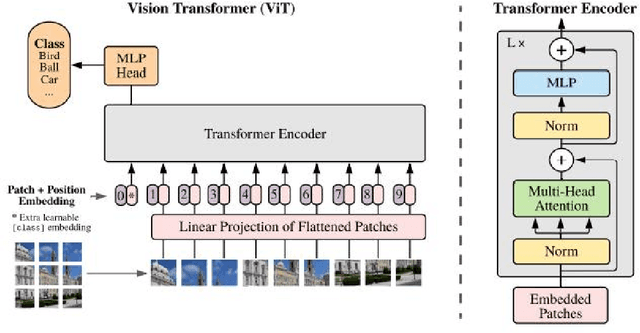
InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation
Dec 02, 2021
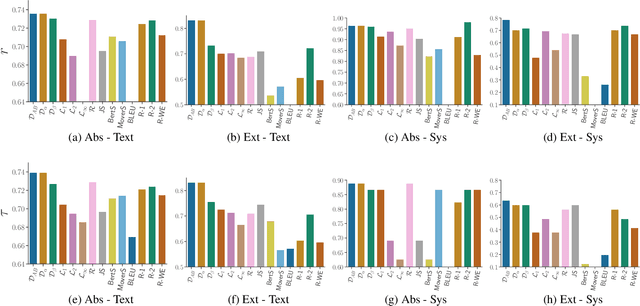
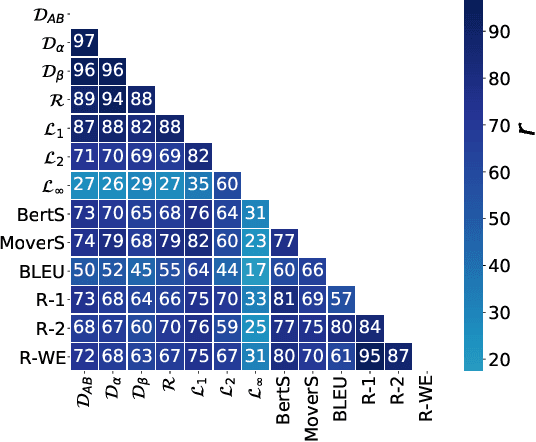
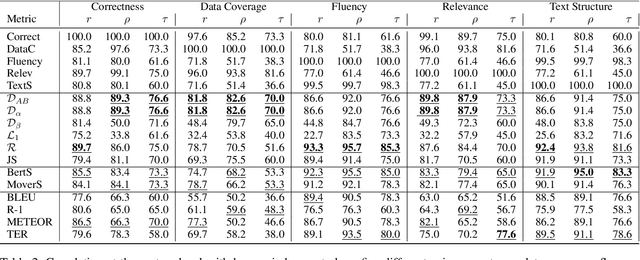
Assessing the quality of natural language generation systems through human annotation is very expensive. Additionally, human annotation campaigns are time-consuming and include non-reusable human labour. In practice, researchers rely on automatic metrics as a proxy of quality. In the last decade, many string-based metrics (e.g., BLEU) have been introduced. However, such metrics usually rely on exact matches and thus, do not robustly handle synonyms. In this paper, we introduce InfoLM a family of untrained metrics that can be viewed as a string-based metric that addresses the aforementioned flaws thanks to a pre-trained masked language model. This family of metrics also makes use of information measures allowing the adaptation of InfoLM to various evaluation criteria. Using direct assessment, we demonstrate that InfoLM achieves statistically significant improvement and over $10$ points of correlation gains in many configurations on both summarization and data2text generation.
Self-Initiated Open World Learning for Autonomous AI Agents
Oct 21, 2021As more and more AI agents are used in practice, it is time to think about how to make these agents fully autonomous so that they can learn by themselves in a self-motivated and self-supervised manner rather than being retrained periodically on the initiation of human engineers using expanded training data. As the real-world is an open environment with unknowns or novelties, detecting novelties or unknowns, gathering ground-truth training data, and incrementally learning the unknowns make the agent more and more knowledgeable and powerful over time. The key challenge is how to automate the process so that it is carried out on the agent's own initiative and through its own interactions with humans and the environment. Since an AI agent usually has a performance task, characterizing each novelty becomes necessary so that the agent can formulate an appropriate response to adapt its behavior to cope with the novelty and to learn from it to improve its future responses and task performance. This paper proposes a theoretic framework for this learning paradigm to promote the research of building self-initiated open world learning agents.
Latent ODEs for Irregularly-Sampled Time Series
Jul 08, 2019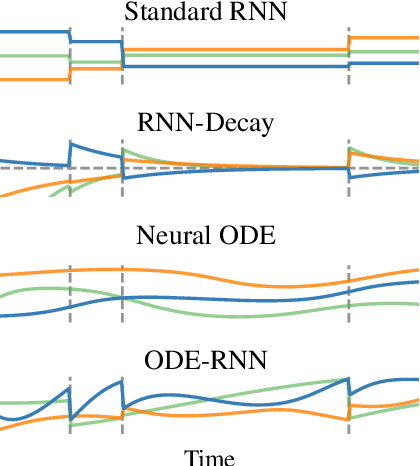
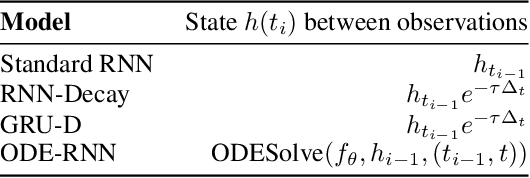
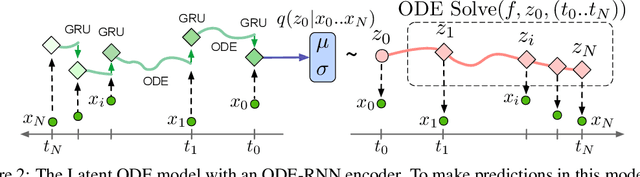
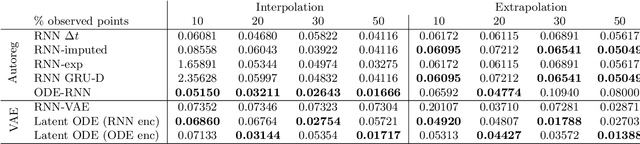
Time series with non-uniform intervals occur in many applications, and are difficult to model using standard recurrent neural networks (RNNs). We generalize RNNs to have continuous-time hidden dynamics defined by ordinary differential equations (ODEs), a model we call ODE-RNNs. Furthermore, we use ODE-RNNs to replace the recognition network of the recently-proposed Latent ODE model. Both ODE-RNNs and Latent ODEs can naturally handle arbitrary time gaps between observations, and can explicitly model the probability of observation times using Poisson processes. We show experimentally that these ODE-based models outperform their RNN-based counterparts on irregularly-sampled data.
On the Effectiveness of Neural Ensembles for Image Classification with Small Datasets
Nov 29, 2021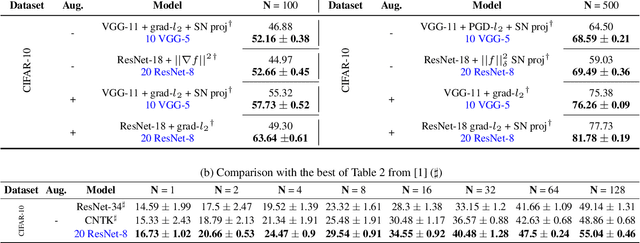
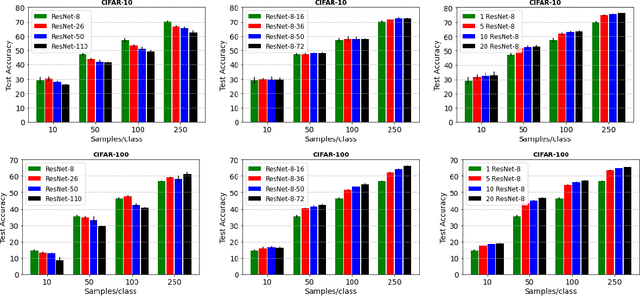
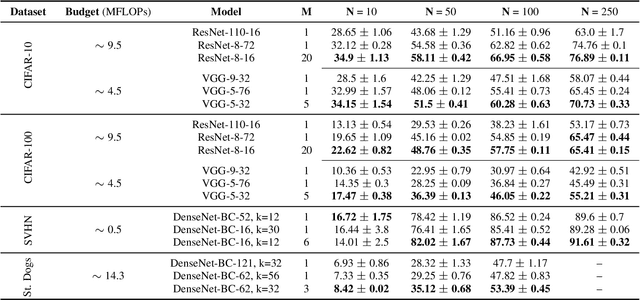
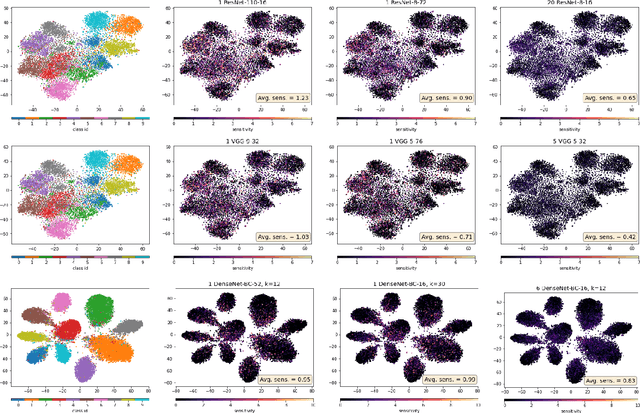
Deep neural networks represent the gold standard for image classification. However, they usually need large amounts of data to reach superior performance. In this work, we focus on image classification problems with a few labeled examples per class and improve data efficiency by using an ensemble of relatively small networks. For the first time, our work broadly studies the existing concept of neural ensembling in domains with small data, through extensive validation using popular datasets and architectures. We compare ensembles of networks to their deeper or wider single competitors given a total fixed computational budget. We show that ensembling relatively shallow networks is a simple yet effective technique that is generally better than current state-of-the-art approaches for learning from small datasets. Finally, we present our interpretation according to which neural ensembles are more sample efficient because they learn simpler functions.
Algorithms for Adaptive Experiments that Trade-off Statistical Analysis with Reward: Combining Uniform Random Assignment and Reward Maximization
Dec 21, 2021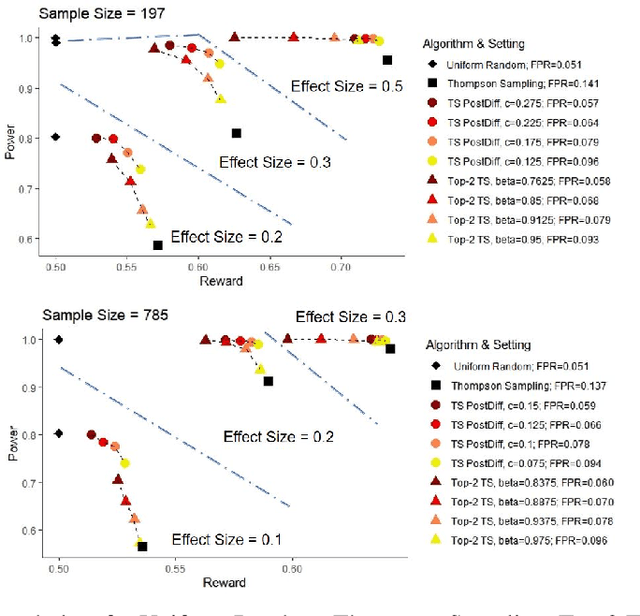
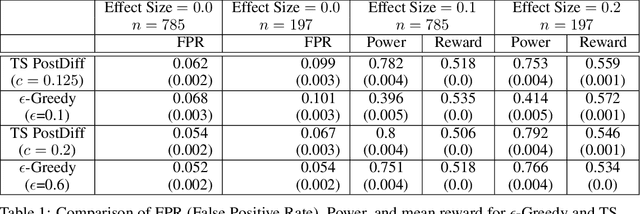
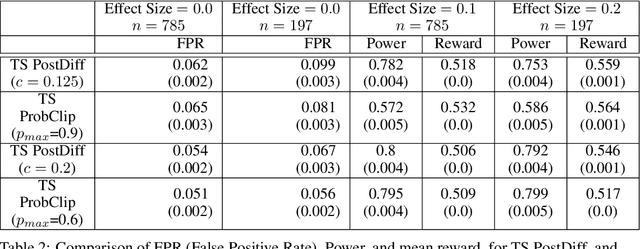
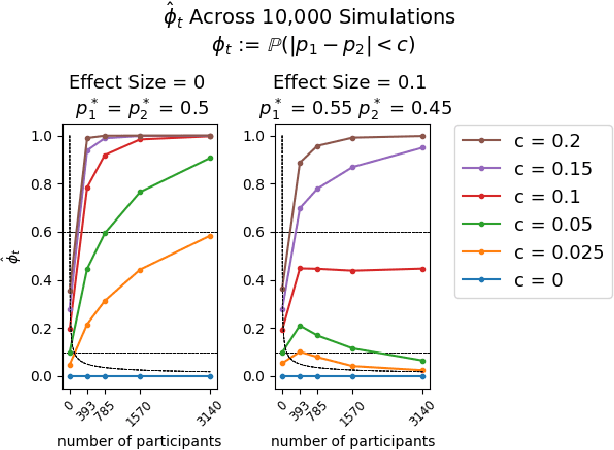
Multi-armed bandit algorithms like Thompson Sampling can be used to conduct adaptive experiments, in which maximizing reward means that data is used to progressively assign more participants to more effective arms. Such assignment strategies increase the risk of statistical hypothesis tests identifying a difference between arms when there is not one, and failing to conclude there is a difference in arms when there truly is one. We present simulations for 2-arm experiments that explore two algorithms that combine the benefits of uniform randomization for statistical analysis, with the benefits of reward maximization achieved by Thompson Sampling (TS). First, Top-Two Thompson Sampling adds a fixed amount of uniform random allocation (UR) spread evenly over time. Second, a novel heuristic algorithm, called TS PostDiff (Posterior Probability of Difference). TS PostDiff takes a Bayesian approach to mixing TS and UR: the probability a participant is assigned using UR allocation is the posterior probability that the difference between two arms is `small' (below a certain threshold), allowing for more UR exploration when there is little or no reward to be gained. We find that TS PostDiff method performs well across multiple effect sizes, and thus does not require tuning based on a guess for the true effect size.