 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Who supervises the supervisor? Model monitoring in production using deep feature embeddings with applications to workpiece inspection
Jan 17, 2022
The automation of condition monitoring and workpiece inspection plays an essential role in maintaining high quality as well as high throughput of the manufacturing process. To this end, the recent rise of developments in machine learning has lead to vast improvements in the area of autonomous process supervision. However, the more complex and powerful these models become, the less transparent and explainable they generally are as well. One of the main challenges is the monitoring of live deployments of these machine learning systems and raising alerts when encountering events that might impact model performance. In particular, supervised classifiers are typically build under the assumption of stationarity in the underlying data distribution. For example, a visual inspection system trained on a set of material surface defects generally does not adapt or even recognize gradual changes in the data distribution - an issue known as "data drift" - such as the emergence of new types of surface defects. This, in turn, may lead to detrimental mispredictions, e.g. samples from new defect classes being classified as non-defective. To this end, it is desirable to provide real-time tracking of a classifier's performance to inform about the putative onset of additional error classes and the necessity for manual intervention with respect to classifier re-training. Here, we propose an unsupervised framework that acts on top of a supervised classification system, thereby harnessing its internal deep feature representations as a proxy to track changes in the data distribution during deployment and, hence, to anticipate classifier performance degradation.
Proactive Query Expansion for Streaming Data Using External Source
Jan 17, 2022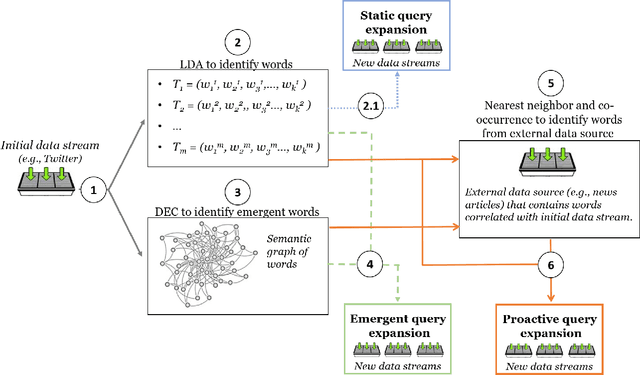
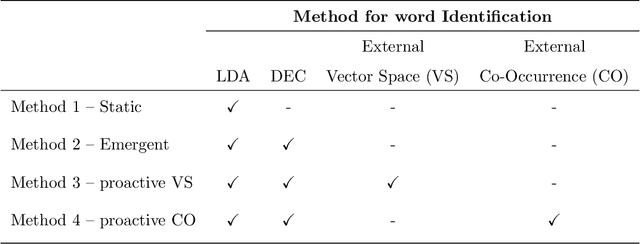

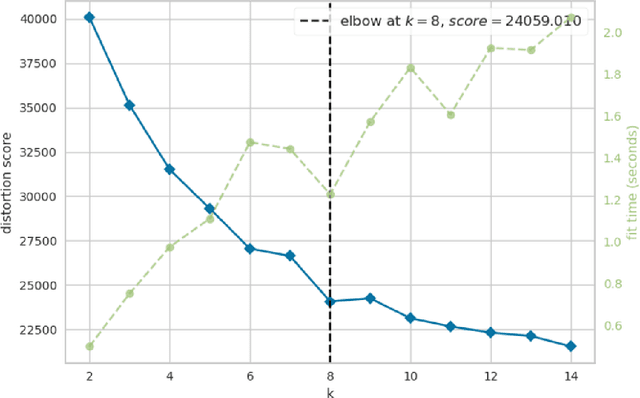
Query expansion is the process of reformulating the original query by adding relevant words. Choosing which terms to add in order to improve the performance of the query expansion methods or to enhance the quality of the retrieved results is an important aspect of any information retrieval system. Adding words that can positively impact the quality of the search query or are informative enough play an important role in returning or gathering relevant documents that cover a certain topic can result in improving the efficiency of the information retrieval system. Typically, query expansion techniques are used to add or substitute words to a given search query to collect relevant data. In this paper, we design and implement a pipeline of automated query expansion. We outline several tools using different methods to expand the query. Our methods depend on targeting emergent events in streaming data over time and finding the hidden topics from targeted documents using probabilistic topic models. We employ Dynamic Eigenvector Centrality to trigger the emergent events, and the Latent Dirichlet Allocation to discover the topics. Also, we use an external data source as a secondary stream to supplement the primary stream with relevant words and expand the query using the words from both primary and secondary streams. An experimental study is performed on Twitter data (primary stream) related to the events that happened during protests in Baltimore in 2015. The quality of the retrieved results was measured using a quality indicator of the streaming data: tweets count, hashtag count, and hashtag clustering.
Fast Learning of MNL Model from General Partial Rankings with Application to Network Formation Modeling
Dec 31, 2021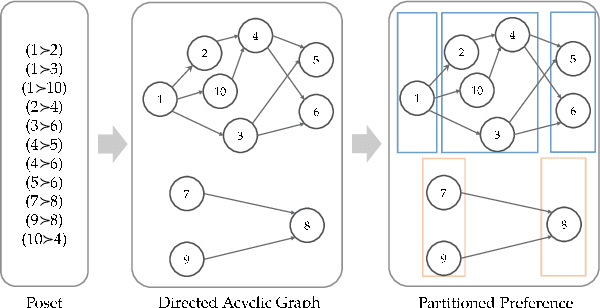
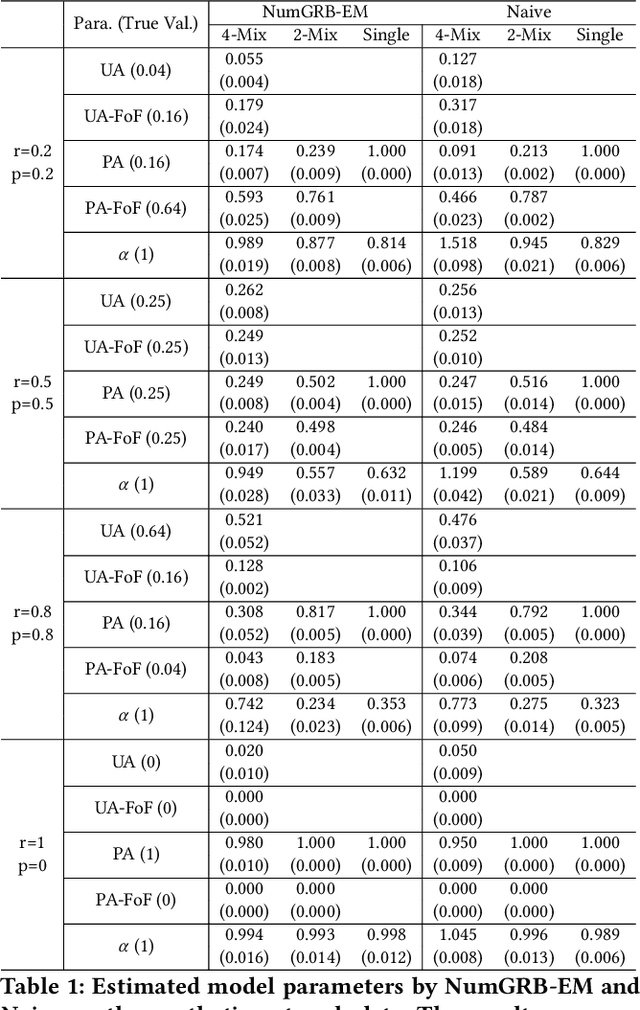
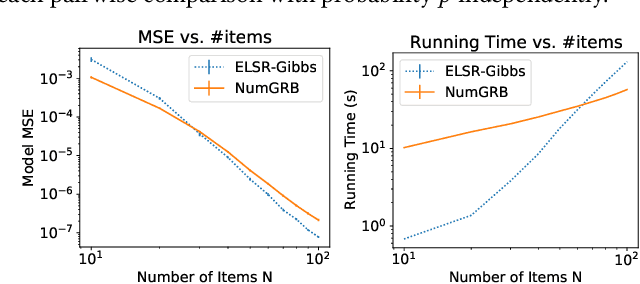
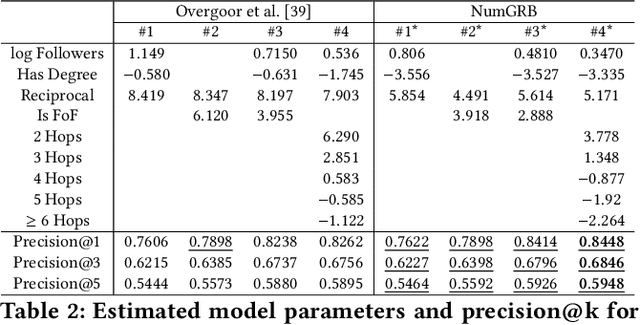
Multinomial Logit (MNL) is one of the most popular discrete choice models and has been widely used to model ranking data. However, there is a long-standing technical challenge of learning MNL from many real-world ranking data: exact calculation of the MNL likelihood of \emph{partial rankings} is generally intractable. In this work, we develop a scalable method for approximating the MNL likelihood of general partial rankings in polynomial time complexity. We also extend the proposed method to learn mixture of MNL. We demonstrate that the proposed methods are particularly helpful for applications to choice-based network formation modeling, where the formation of new edges in a network is viewed as individuals making choices of their friends over a candidate set. The problem of learning mixture of MNL models from partial rankings naturally arises in such applications. And the proposed methods can be used to learn MNL models from network data without the strong assumption that temporal orders of all the edge formation are available. We conduct experiments on both synthetic and real-world network data to demonstrate that the proposed methods achieve more accurate parameter estimation and better fitness of data compared to conventional methods.
Contextual Bandits for Advertising Campaigns: A Diffusion-Model Independent Approach (Extended Version)
Jan 13, 2022
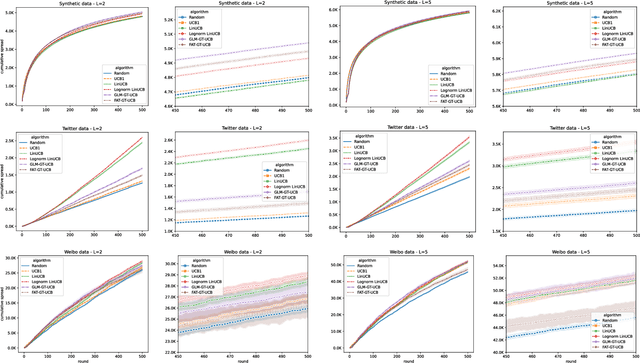
Motivated by scenarios of information diffusion and advertising in social media, we study an influence maximization problem in which little is assumed to be known about the diffusion network or about the model that determines how information may propagate. In such a highly uncertain environment, one can focus on multi-round diffusion campaigns, with the objective to maximize the number of distinct users that are influenced or activated, starting from a known base of few influential nodes. During a campaign, spread seeds are selected sequentially at consecutive rounds, and feedback is collected in the form of the activated nodes at each round. A round's impact (reward) is then quantified as the number of newly activated nodes. Overall, one must maximize the campaign's total spread, as the sum of rounds' rewards. In this setting, an explore-exploit approach could be used to learn the key underlying diffusion parameters, while running the campaign. We describe and compare two methods of contextual multi-armed bandits, with upper-confidence bounds on the remaining potential of influencers, one using a generalized linear model and the Good-Turing estimator for remaining potential (GLM-GT-UCB), and another one that directly adapts the LinUCB algorithm to our setting (LogNorm-LinUCB). We show that they outperform baseline methods using state-of-the-art ideas, on synthetic and real-world data, while at the same time exhibiting different and complementary behavior, depending on the scenarios in which they are deployed.
Learning-Based MIMO Channel Estimation under Spectrum Efficient Pilot Allocation and Feedback
Jan 13, 2022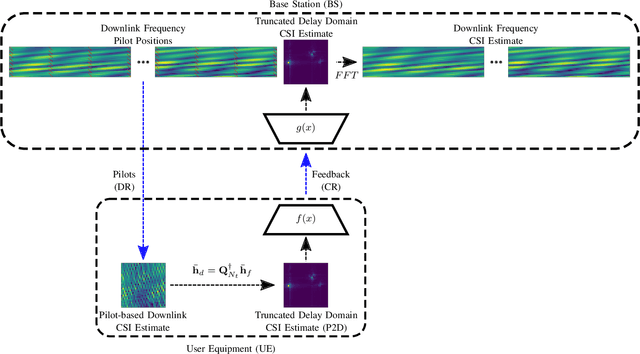
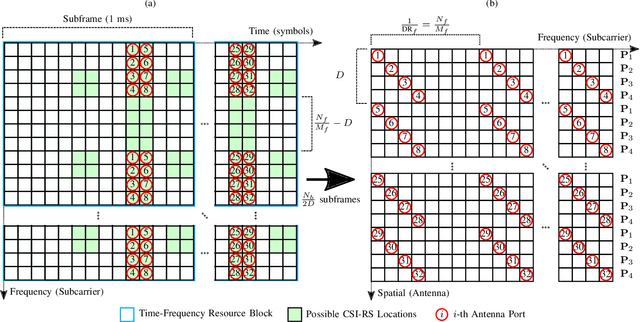
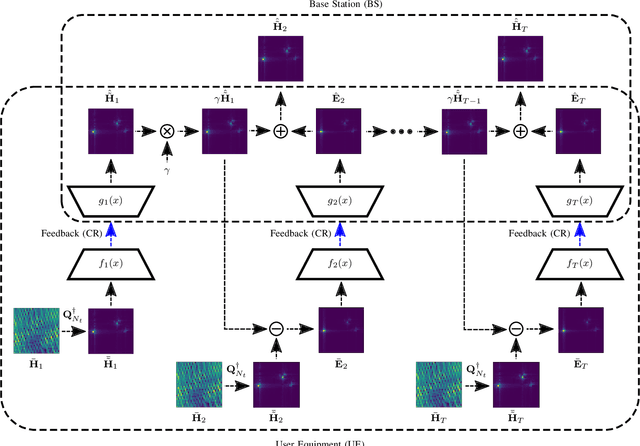
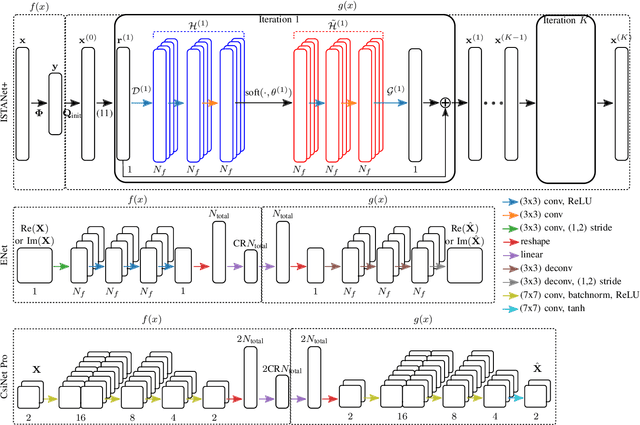
Wireless links using massive MIMO transceivers are vital for next generation wireless communications networks networks. Precoding in Massive MIMO transmission requires accurate downlink channel state information (CSI). Many recent works have effectively applied deep learning (DL) to jointly train UE-side compression networks for delay domain CSI and a BS-side decoding scheme. Vitally, these works assume that the full delay domain CSI is available at the UE, but in reality, the UE must estimate the delay domain based on a limited number of frequency domain pilots. In this work, we propose a linear pilot-to-delay (P2D) estimator that transforms sparse frequency pilots to the truncated delay CSI. We show that the P2D estimator is accurate under frequency downsampling, and we demonstrate that the P2D estimate can be effectively utilized with existing autoencoder-based CSI estimation networks. In addition to accounting for pilot-based estimates of downlink CSI, we apply unrolled optimization networks to emulate iterative solutions to compressed sensing (CS), and we demonstrate better estimation performance than prior autoencoder-based DL networks. Finally, we investigate the efficacy of trainable CS networks for in a differential encoding network for time-varying CSI estimation, and we propose a new network, MarkovNet-ISTA-ENet, comprised of both a CS network for initial CSI estimation and multiple autoencoders to estimate the error terms. We demonstrate that this heterogeneous network has better asymptotic performance than networks comprised of only one type of network.
Reachable Sets for Safe, Real-Time Manipulator Trajectory Design
Feb 05, 2020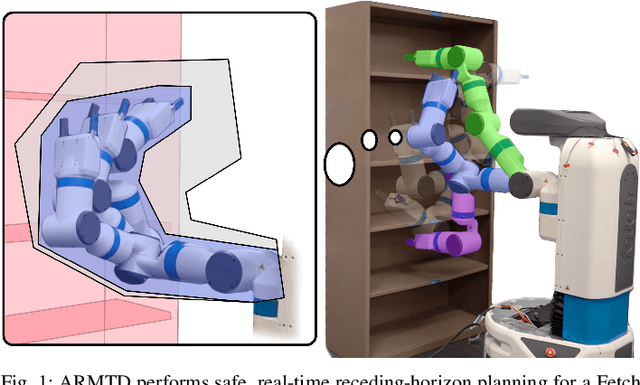
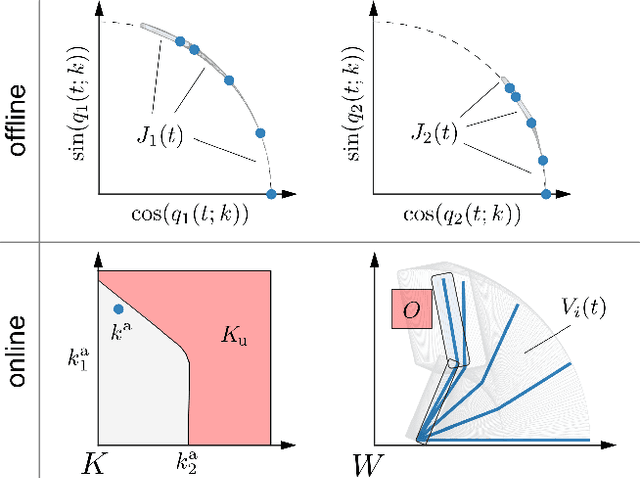
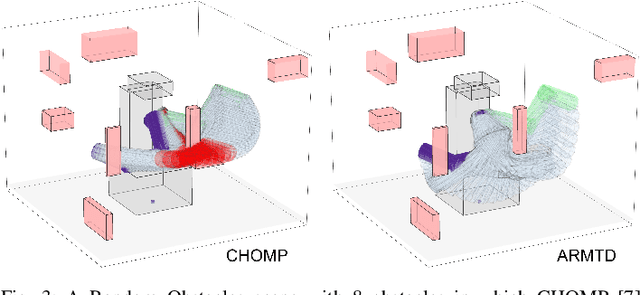
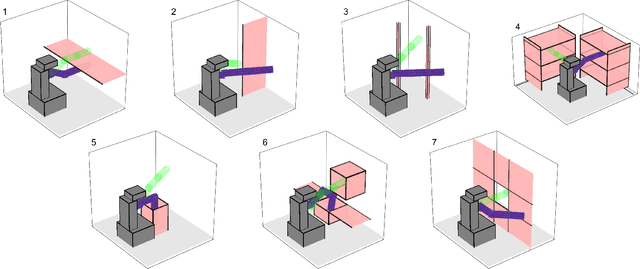
For robotic arms to operate in arbitrary environments, especially near people, it is critical to certify the safety of their motion planning algorithms. However, there is often a trade-off between safety and real-time performance; one can either carefully design safe plans, or rapidly generate potentially-unsafe plans. This work presents a receding-horizon, real-time trajectory planner with safety guarantees, called ARMTD (Autonomous Reachability-based Manipulator Trajectory Design). The method first computes (offline) a reachable set of parameterized trajectories for each joint of an arm. Each trajectory includes a fail-safe maneuver (braking to a stop). At runtime, in each receding-horizon planning iteration, ARMTD constructs a reachable set of the entire arm in workspace and intersects it with obstacles to generate sub-differentiable and provably-conservative collision-avoidance constraints on the trajectory parameters. ARMTD then performs trajectory optimization for an arbitrary cost function on the parameters, subject to these constraints. On a 6 degree-of-freedom arm, ARMTD outperforms CHOMP in simulation and completes a variety of real-time planning tasks on hardware, all without collisions.
Benchmarking deep inverse models over time, and the neural-adjoint method
Oct 12, 2020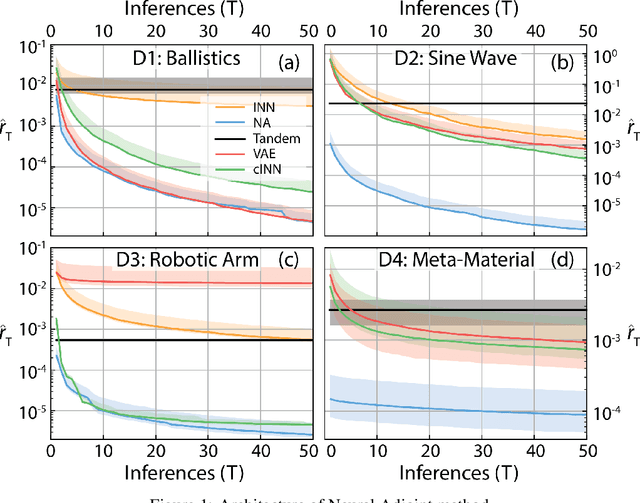

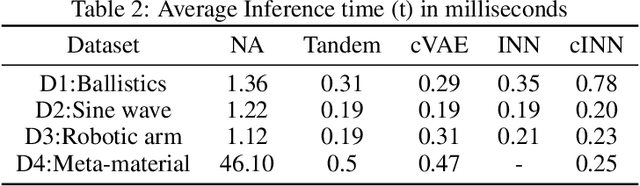
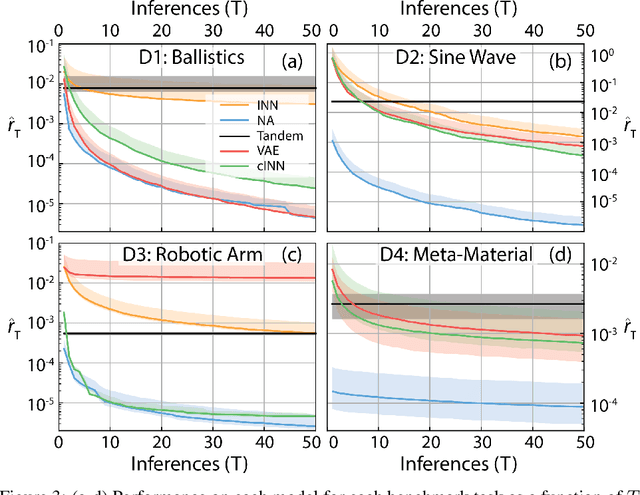
We consider the task of solving generic inverse problems, where one wishes to determine the hidden parameters of a natural system that will give rise to a particular set of measurements. Recently many new approaches based upon deep learning have arisen generating impressive results. We conceptualize these models as different schemes for efficiently, but randomly, exploring the space of possible inverse solutions. As a result, the accuracy of each approach should be evaluated as a function of time rather than a single estimated solution, as is often done now. Using this metric, we compare several state-of-the-art inverse modeling approaches on four benchmark tasks: two existing tasks, one simple task for visualization and one new task from metamaterial design. Finally, inspired by our conception of the inverse problem, we explore a solution that uses a deep learning model to approximate the forward model, and then uses backpropagation to search for good inverse solutions. This approach, termed the neural-adjoint, achieves the best performance in many scenarios.
Inferring Individual Level Causal Models from Graph-based Relational Time Series
Jan 16, 2020
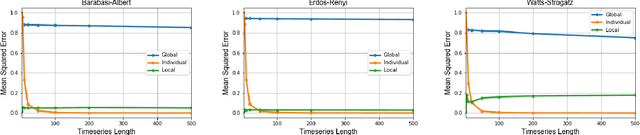
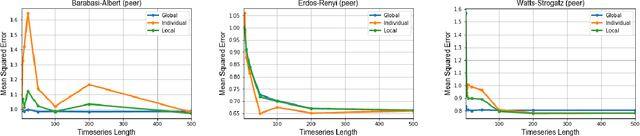
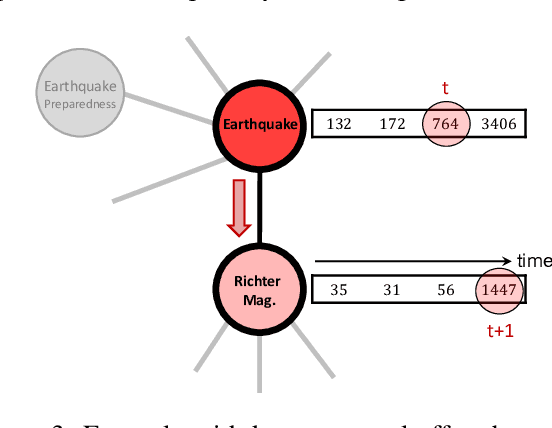
In this work, we formalize the problem of causal inference over graph-based relational time-series data where each node in the graph has one or more time-series associated to it. We propose causal inference models for this problem that leverage both the graph topology and time-series to accurately estimate local causal effects of nodes. Furthermore, the relational time-series causal inference models are able to estimate local effects for individual nodes by exploiting local node-centric temporal dependencies and topological/structural dependencies. We show that simpler causal models that do not consider the graph topology are recovered as special cases of the proposed relational time-series causal inference model. We describe the conditions under which the resulting estimate can be used to estimate a causal effect, and describe how the Durbin-Wu-Hausman test of specification can be used to test for the consistency of the proposed estimator from data. Empirically, we demonstrate the effectiveness of the causal inference models on both synthetic data with known ground-truth and a large-scale observational relational time-series data set collected from Wikipedia.
Chaining Value Functions for Off-Policy Learning
Jan 17, 2022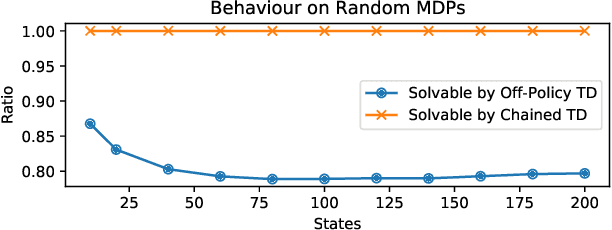
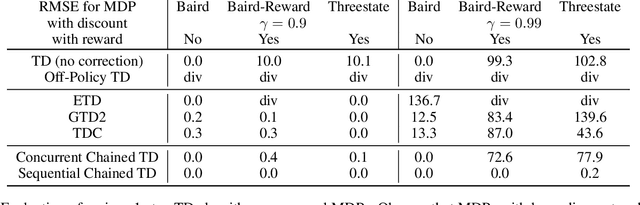
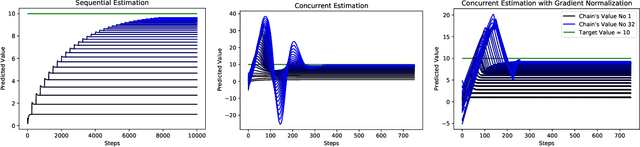
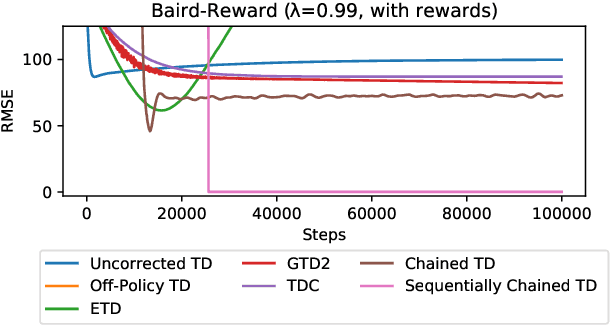
To accumulate knowledge and improve its policy of behaviour, a reinforcement learning agent can learn `off-policy' about policies that differ from the policy used to generate its experience. This is important to learn counterfactuals, or because the experience was generated out of its own control. However, off-policy learning is non-trivial, and standard reinforcement-learning algorithms can be unstable and divergent. In this paper we discuss a novel family of off-policy prediction algorithms which are convergent by construction. The idea is to first learn on-policy about the data-generating behaviour, and then bootstrap an off-policy value estimate on this on-policy estimate, thereby constructing a value estimate that is partially off-policy. This process can be repeated to build a chain of value functions, each time bootstrapping a new estimate on the previous estimate in the chain. Each step in the chain is stable and hence the complete algorithm is guaranteed to be stable. Under mild conditions this comes arbitrarily close to the off-policy TD solution when we increase the length of the chain. Hence it can compute the solution even in cases where off-policy TD diverges. We prove that the proposed scheme is convergent and corresponds to an iterative decomposition of the inverse key matrix. Furthermore it can be interpreted as estimating a novel objective -- that we call a `k-step expedition' -- of following the target policy for finitely many steps before continuing indefinitely with the behaviour policy. Empirically we evaluate the idea on challenging MDPs such as Baird's counter example and observe favourable results.
A Multi-Resolution Front-End for End-to-End Speech Anti-Spoofing
Oct 11, 2021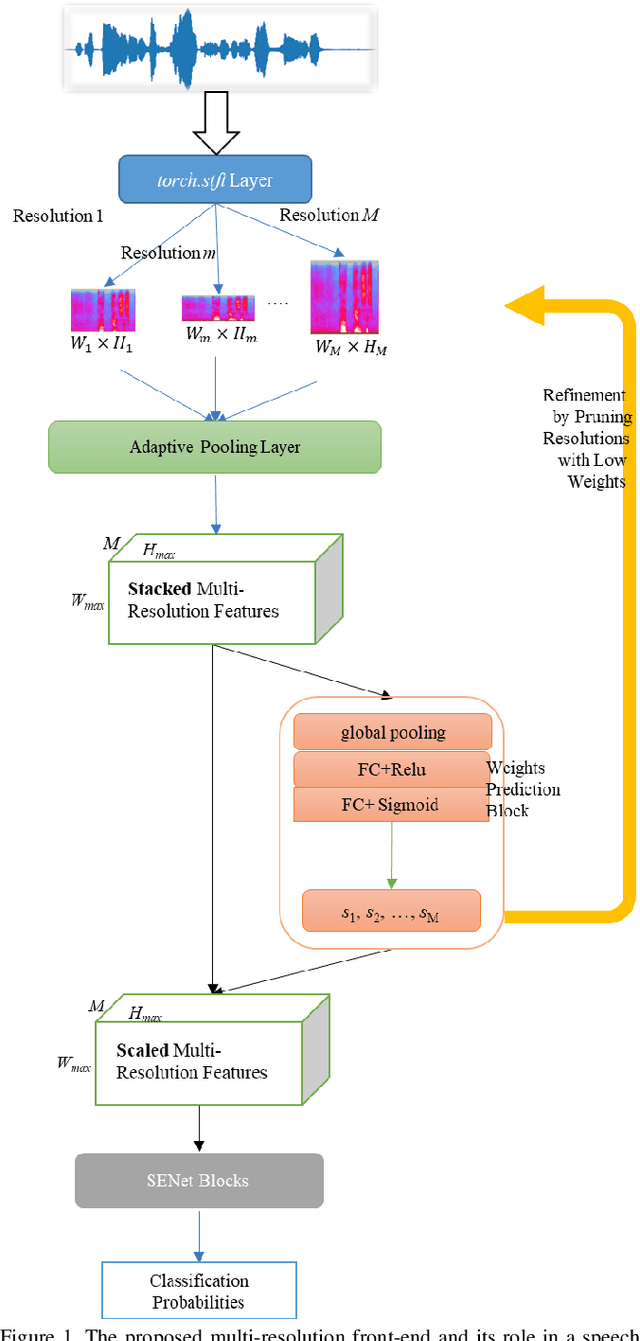
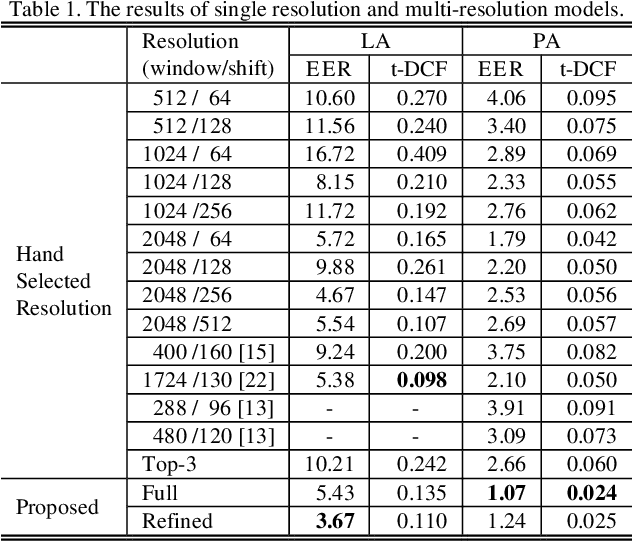
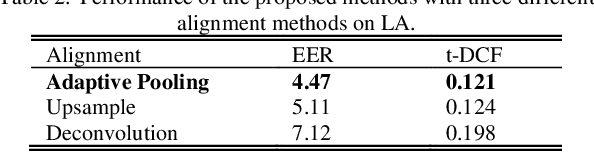
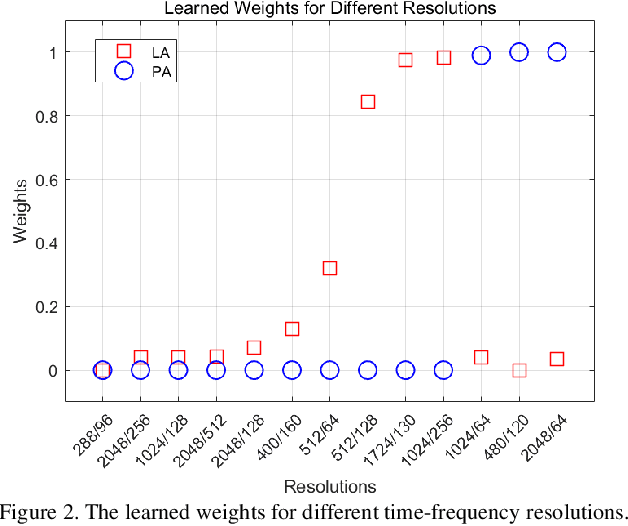
The choice of an optimal time-frequency resolution is usually a difficult but important step in tasks involving speech signal classification, e.g., speech anti-spoofing. The variations of the performance with different choices of timefrequency resolutions can be as large as those with different model architectures, which makes it difficult to judge what the improvement actually comes from when a new network architecture is invented and introduced as the classifier. In this paper, we propose a multi-resolution front-end for feature extraction in an end-to-end classification framework. Optimal weighted combinations of multiple time-frequency resolutions will be learned automatically given the objective of a classification task. Features extracted with different time-frequency resolutions are weighted and concatenated as inputs to the successive networks, where the weights are predicted by a learnable neural network inspired by the weighting block in squeeze-and-excitation networks (SENet). Furthermore, the refinement of the chosen timefrequency resolutions is investigated by pruning the ones with relatively low importance, which reduces the complexity and size of the model. The proposed method is evaluated on the tasks of speech anti-spoofing in ASVSpoof 2019 and its superiority has been justified by comparing with similar baselines.