 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluence Maximization via Graph Neural Bandits
Jun 18, 2024



We consider a ubiquitous scenario in the study of Influence Maximization (IM), in which there is limited knowledge about the topology of the diffusion network. We set the IM problem in a multi-round diffusion campaign, aiming to maximize the number of distinct users that are influenced. Leveraging the capability of bandit algorithms to effectively balance the objectives of exploration and exploitation, as well as the expressivity of neural networks, our study explores the application of neural bandit algorithms to the IM problem. We propose the framework IM-GNB (Influence Maximization with Graph Neural Bandits), where we provide an estimate of the users' probabilities of being influenced by influencers (also known as diffusion seeds). This initial estimate forms the basis for constructing both an exploitation graph and an exploration one. Subsequently, IM-GNB handles the exploration-exploitation tradeoff, by selecting seed nodes in real-time using Graph Convolutional Networks (GCN), in which the pre-estimated graphs are employed to refine the influencers' estimated rewards in each contextual setting. Through extensive experiments on two large real-world datasets, we demonstrate the effectiveness of IM-GNB compared with other baseline methods, significantly improving the spread outcome of such diffusion campaigns, when the underlying network is unknown.
Predicting Cascading Failures with a Hyperparametric Diffusion Model
Jun 12, 2024



In this paper, we study cascading failures in power grids through the lens of information diffusion models. Similar to the spread of rumors or influence in an online social network, it has been observed that failures (outages) in a power grid can spread contagiously, driven by viral spread mechanisms. We employ a stochastic diffusion model that is Markovian (memoryless) and local (the activation of one node, i.e., transmission line, can only be caused by its neighbors). Our model integrates viral diffusion principles with physics-based concepts, by correlating the diffusion weights (contagion probabilities between transmission lines) with the hyperparametric Information Cascades (IC) model. We show that this diffusion model can be learned from traces of cascading failures, enabling accurate modeling and prediction of failure propagation. This approach facilitates actionable information through well-understood and efficient graph analysis methods and graph diffusion simulations. Furthermore, by leveraging the hyperparametric model, we can predict diffusion and mitigate the risks of cascading failures even in unseen grid configurations, whereas existing methods falter due to a lack of training data. Extensive experiments based on a benchmark power grid and simulations therein show that our approach effectively captures the failure diffusion phenomena and guides decisions to strengthen the grid, reducing the risk of large-scale cascading failures. Additionally, we characterize our model's sample complexity, improving upon the existing bound.
Scalable Continuous-time Diffusion Framework for Network Inference and Influence Estimation
Mar 05, 2024



The study of continuous-time information diffusion has been an important area of research for many applications in recent years. When only the diffusion traces (cascades) are accessible, cascade-based network inference and influence estimation are two essential problems to explore. Alas, existing methods exhibit limited capability to infer and process networks with more than a few thousand nodes, suffering from scalability issues. In this paper, we view the diffusion process as a continuous-time dynamical system, based on which we establish a continuous-time diffusion model. Subsequently, we instantiate the model to a scalable and effective framework (FIM) to approximate the diffusion propagation from available cascades, thereby inferring the underlying network structure. Furthermore, we undertake an analysis of the approximation error of FIM for network inference. To achieve the desired scalability for influence estimation, we devise an advanced sampling technique and significantly boost the efficiency. We also quantify the effect of the approximation error on influence estimation theoretically. Experimental results showcase the effectiveness and superior scalability of FIM on network inference and influence estimation.
Influence Maximization with Fairness at Scale (Extended Version)
Jun 06, 2023



In this paper, we revisit the problem of influence maximization with fairness, which aims to select k influential nodes to maximise the spread of information in a network, while ensuring that selected sensitive user attributes are fairly affected, i.e., are proportionally similar between the original network and the affected users. Recent studies on this problem focused only on extremely small networks, hence the challenge remains on how to achieve a scalable solution, applicable to networks with millions or billions of nodes. We propose an approach that is based on learning node representations for fair spread from diffusion cascades, instead of the social connectivity s.t. we can deal with very large graphs. We propose two data-driven approaches: (a) fairness-based participant sampling (FPS), and (b) fairness as context (FAC). Spread related user features, such as the probability of diffusing information to others, are derived from the historical information cascades, using a deep neural network. The extracted features are then used in selecting influencers that maximize the influence spread, while being also fair with respect to the chosen sensitive attributes. In FPS, fairness and cascade length information are considered independently in the decision-making process, while FAC considers these information facets jointly and considers correlations between them. The proposed algorithms are generic and represent the first policy-driven solutions that can be applied to arbitrary sets of sensitive attributes at scale. We evaluate the performance of our solutions on a real-world public dataset (Sina Weibo) and on a hybrid real-synthethic dataset (Digg), which exhibit all the facets that we exploit, namely diffusion network, diffusion traces, and user profiles. These experiments show that our methods outperform the state-the-art solutions in terms of spread, fairness, and scalability.
IGNiteR: News Recommendation in Microblogging Applications (Extended Version)
Oct 04, 2022
News recommendation is one of the most challenging tasks in recommender systems, mainly due to the ephemeral relevance of news to users. As social media, and particularly microblogging applications like Twitter or Weibo, gains popularity as platforms for news dissemination, personalized news recommendation in this context becomes a significant challenge. We revisit news recommendation in the microblogging scenario, by taking into consideration social interactions and observations tracing how the information that is up for recommendation spreads in an underlying network. We propose a deep-learning based approach that is diffusion and influence-aware, called Influence-Graph News Recommender (IGNiteR). It is a content-based deep recommendation model that jointly exploits all the data facets that may impact adoption decisions, namely semantics, diffusion-related features pertaining to local and global influence among users, temporal attractiveness, and timeliness, as well as dynamic user preferences. To represent the news, a multi-level attention-based encoder is used to reveal the different interests of users. This news encoder relies on a CNN for the news content and on an attentive LSTM for the diffusion traces. For the latter, by exploiting previously observed news diffusions (cascades) in the microblogging medium, users are mapped to a latent space that captures potential influence on others or susceptibility of being influenced for news adoptions. Similarly, a time-sensitive user encoder enables us to capture the dynamic preferences of users with an attention-based bidirectional LSTM. We perform extensive experiments on two real-world datasets, showing that IGNiteR outperforms the state-of-the-art deep-learning based news recommendation methods.
Contextual Bandits for Advertising Campaigns: A Diffusion-Model Independent Approach (Extended Version)
Jan 13, 2022
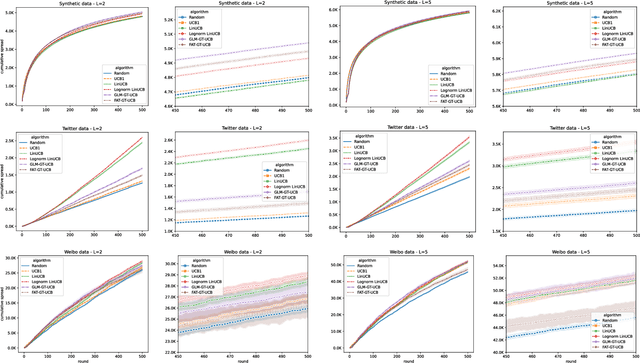
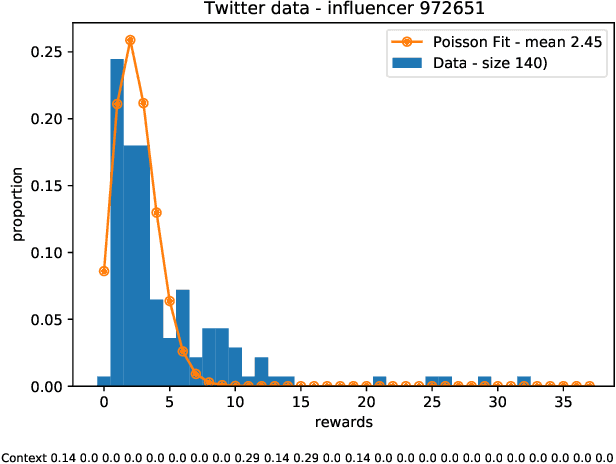
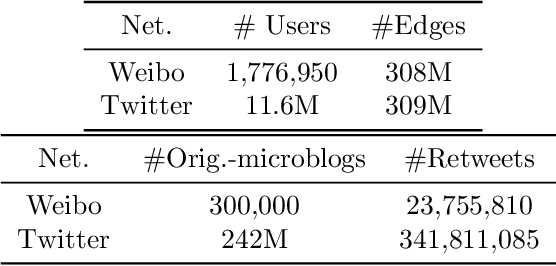
Motivated by scenarios of information diffusion and advertising in social media, we study an influence maximization problem in which little is assumed to be known about the diffusion network or about the model that determines how information may propagate. In such a highly uncertain environment, one can focus on multi-round diffusion campaigns, with the objective to maximize the number of distinct users that are influenced or activated, starting from a known base of few influential nodes. During a campaign, spread seeds are selected sequentially at consecutive rounds, and feedback is collected in the form of the activated nodes at each round. A round's impact (reward) is then quantified as the number of newly activated nodes. Overall, one must maximize the campaign's total spread, as the sum of rounds' rewards. In this setting, an explore-exploit approach could be used to learn the key underlying diffusion parameters, while running the campaign. We describe and compare two methods of contextual multi-armed bandits, with upper-confidence bounds on the remaining potential of influencers, one using a generalized linear model and the Good-Turing estimator for remaining potential (GLM-GT-UCB), and another one that directly adapts the LinUCB algorithm to our setting (LogNorm-LinUCB). We show that they outperform baseline methods using state-of-the-art ideas, on synthetic and real-world data, while at the same time exhibiting different and complementary behavior, depending on the scenarios in which they are deployed.
Bandits Under The Influence (Extended Version)
Sep 21, 2020
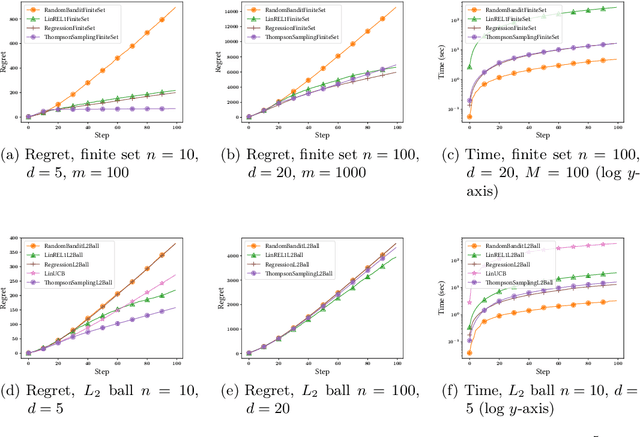

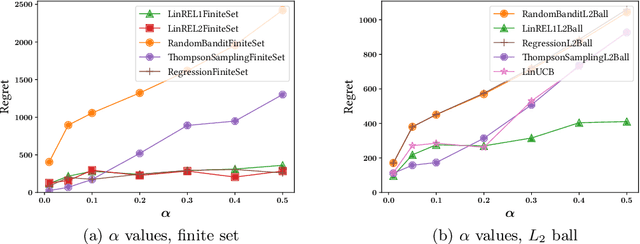
Recommender systems should adapt to user interests as the latter evolve. A prevalent cause for the evolution of user interests is the influence of their social circle. In general, when the interests are not known, online algorithms that explore the recommendation space while also exploiting observed preferences are preferable. We present online recommendation algorithms rooted in the linear multi-armed bandit literature. Our bandit algorithms are tailored precisely to recommendation scenarios where user interests evolve under social influence. In particular, we show that our adaptations of the classic LinREL and Thompson Sampling algorithms maintain the same asymptotic regret bounds as in the non-social case. We validate our approach experimentally using both synthetic and real datasets.