 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tripartite Perspective on GraphRAG
Apr 28, 2025Large Language Models (LLMs) have shown remarkable capabilities across various domains, yet they struggle with knowledge-intensive tasks in areas that demand factual accuracy, e.g. industrial automation and healthcare. Key limitations include their tendency to hallucinate, lack of source traceability (provenance), and challenges in timely knowledge updates. Combining language models with knowledge graphs (GraphRAG) offers promising avenues for overcoming these deficits. However, a major challenge lies in creating such a knowledge graph in the first place. Here, we propose a novel approach that combines LLMs with a tripartite knowledge graph representation, which is constructed by connecting complex, domain-specific objects via a curated ontology of corresponding, domain-specific concepts to relevant sections within chunks of text through a concept-anchored pre-analysis of source documents starting from an initial lexical graph. As a consequence, our Tripartite-GraphRAG approach implements: i) a concept-specific, information-preserving pre-compression of textual chunks; ii) allows for the formation of a concept-specific relevance estimation of embedding similarities grounded in statistics; and iii) avoids common challenges w.r.t. continuous extendability, such as the need for entity resolution and deduplication. By applying a transformation to the knowledge graph, we formulate LLM prompt creation as an unsupervised node classification problem, drawing on ideas from Markov Random Fields. We evaluate our approach on a healthcare use case, involving multi-faceted analyses of patient anamneses given a set of medical concepts as well as clinical literature. Experiments indicate that it can optimize information density, coverage, and arrangement of LLM prompts while reducing their lengths, which may lead to reduced costs and more consistent and reliable LLM outputs.
ICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024


This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.
Artificial Intelligence based tool wear and defect prediction for special purpose milling machinery using low-cost acceleration sensor retrofits
Feb 07, 2022Milling machines form an integral part of many industrial processing chains. As a consequence, several machine learning based approaches for tool wear detection have been proposed in recent years, yet these methods mostly deal with standard milling machines, while machinery designed for more specialized tasks has gained only limited attention so far. This paper demonstrates the application of an acceleration sensor to allow for convenient condition monitoring of such a special purpose machine, i.e. round seam milling machine. We examine a variety of conditions including blade wear and blade breakage as well as improper machine mounting or insufficient transmission belt tension. In addition, we presents different approaches to supervised failure recognition with limited amounts of training data. Hence, aside theoretical insights, our analysis is of high, practical importance, since retrofitting older machines with acceleration sensors and an on-edge classification setup comes at low cost and effort, yet provides valuable insights into the state of the machine and tools in particular and the production process in general.
Who supervises the supervisor? Model monitoring in production using deep feature embeddings with applications to workpiece inspection
Jan 17, 2022The automation of condition monitoring and workpiece inspection plays an essential role in maintaining high quality as well as high throughput of the manufacturing process. To this end, the recent rise of developments in machine learning has lead to vast improvements in the area of autonomous process supervision. However, the more complex and powerful these models become, the less transparent and explainable they generally are as well. One of the main challenges is the monitoring of live deployments of these machine learning systems and raising alerts when encountering events that might impact model performance. In particular, supervised classifiers are typically build under the assumption of stationarity in the underlying data distribution. For example, a visual inspection system trained on a set of material surface defects generally does not adapt or even recognize gradual changes in the data distribution - an issue known as "data drift" - such as the emergence of new types of surface defects. This, in turn, may lead to detrimental mispredictions, e.g. samples from new defect classes being classified as non-defective. To this end, it is desirable to provide real-time tracking of a classifier's performance to inform about the putative onset of additional error classes and the necessity for manual intervention with respect to classifier re-training. Here, we propose an unsupervised framework that acts on top of a supervised classification system, thereby harnessing its internal deep feature representations as a proxy to track changes in the data distribution during deployment and, hence, to anticipate classifier performance degradation.
Learning Theory and Support Vector Machines - a primer
Feb 12, 2019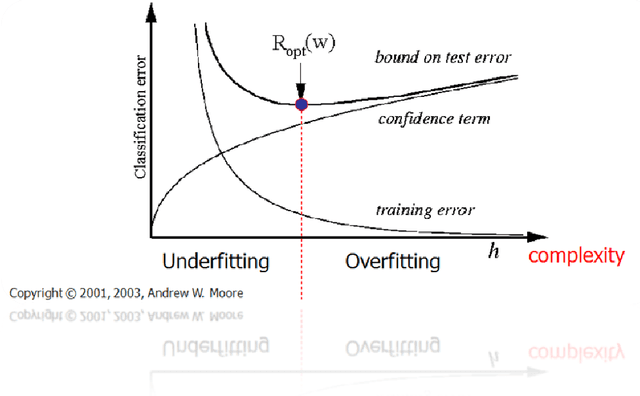
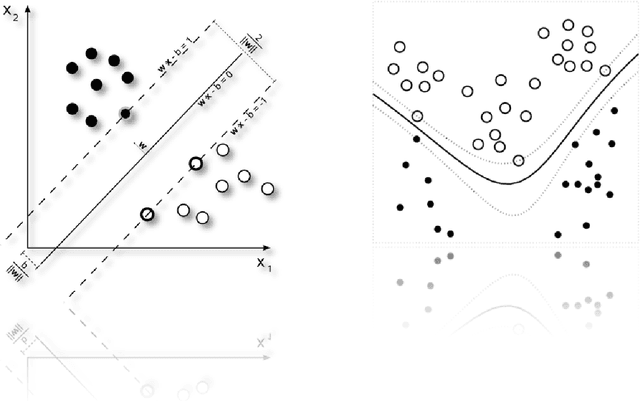
The main goal of statistical learning theory is to provide a fundamental framework for the problem of decision making and model construction based on sets of data. Here, we present a brief introduction to the fundamentals of statistical learning theory, in particular the difference between empirical and structural risk minimization, including one of its most prominent implementations, i.e. the Support Vector Machine.