 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Interpretable Real-Time Win Prediction for Honor of Kings, a Popular Mobile MOBA Esport
Aug 14, 2020
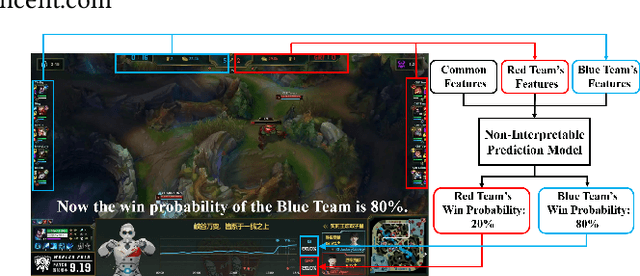

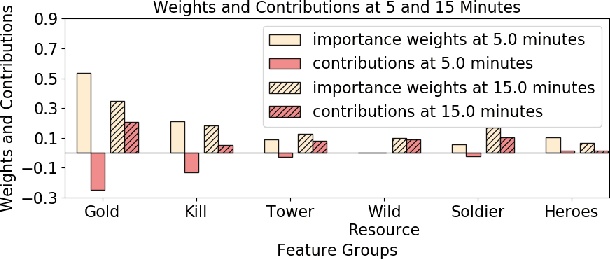
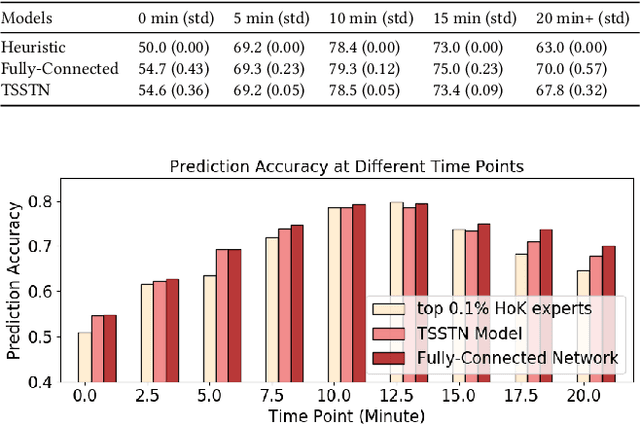
With the rapid prevalence and explosive development of MOBA esports (Multiplayer Online Battle Arena electronic sports), many research efforts have been devoted to automatically predicting the game results (win predictions). While this task has great potential in various applications such as esports live streaming and game commentator AI systems, previous studies suffer from two major limitations: 1) insufficient real-time input features and high-quality training data; 2) non-interpretable inference processes of the black-box prediction models. To mitigate these issues, we collect and release a large-scale dataset that contains real-time game records with rich input features of the popular MOBA game Honor of Kings. For interpretable predictions, we propose a Two-Stage Spatial-Temporal Network (TSSTN) that can not only provide accurate real-time win predictions but also attribute the ultimate prediction results to the contributions of different features for interpretability. Experiment results and applications in real-world live streaming scenarios show that the proposed TSSTN model is effective both in prediction accuracy and interpretability.
It's FLAN time! Summing feature-wise latent representations for interpretability
Jun 18, 2021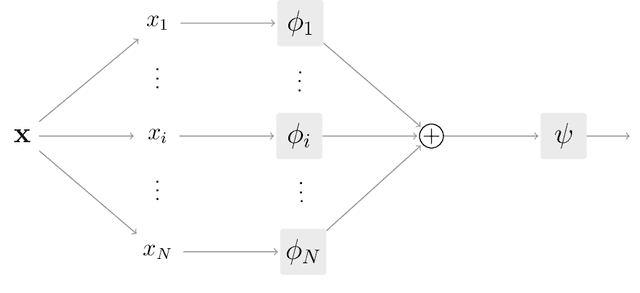
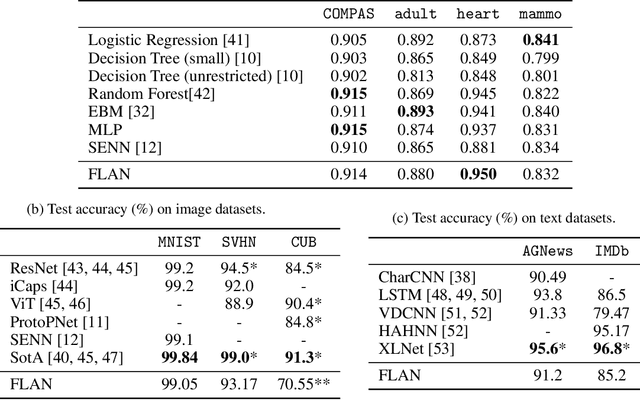
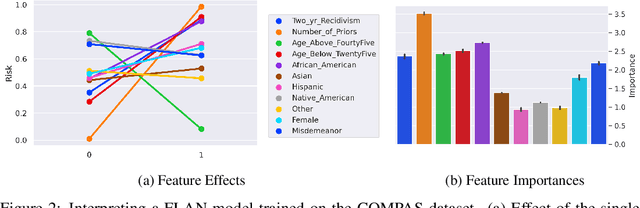
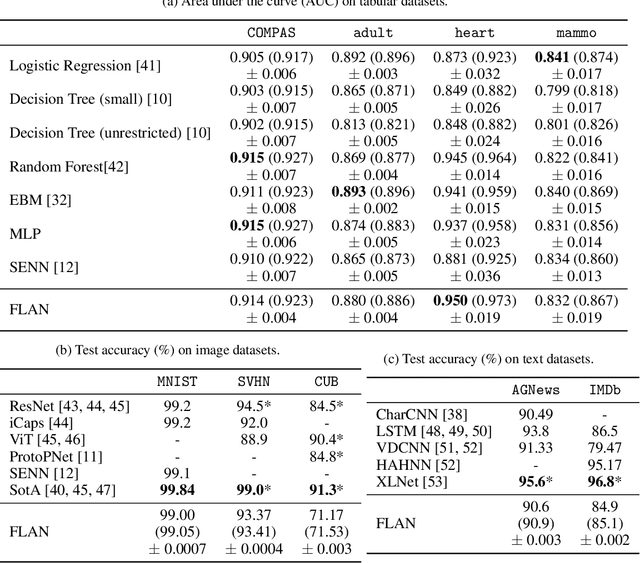
Interpretability has become a necessary feature for machine learning models deployed in critical scenarios, e.g. legal systems, healthcare. In these situations, algorithmic decisions may have (potentially negative) long-lasting effects on the end-user affected by the decision. In many cases, the representational power of deep learning models is not needed, therefore simple and interpretable models (e.g. linear models) should be preferred. However, in high-dimensional and/or complex domains (e.g. computer vision), the universal approximation capabilities of neural networks is required. Inspired by linear models and the Kolmogorov-Arnol representation theorem, we propose a novel class of structurally-constrained neural networks, which we call FLANs (Feature-wise Latent Additive Networks). Crucially, FLANs process each input feature separately, computing for each of them a representation in a common latent space. These feature-wise latent representations are then simply summed, and the aggregated representation is used for prediction. These constraints (which are at the core of the interpretability of linear models) allow an user to estimate the effect of each individual feature independently from the others, enhancing interpretability. In a set of experiments across different domains, we show how without compromising excessively the test performance, the structural constraints proposed in FLANs indeed increase the interpretability of deep learning models.
A Letter on Convergence of In-Parameter-Linear Nonlinear Neural Architectures with Gradient Learnings
Nov 25, 2021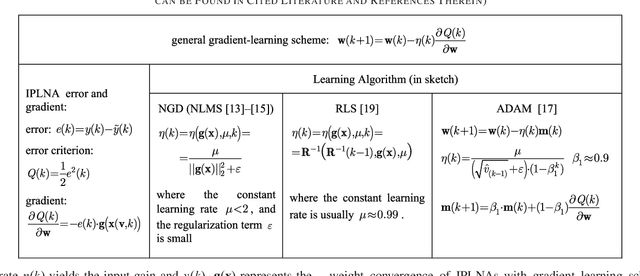
This letter summarizes and proves the concept of bounded-input bounded-state (BIBS) stability for weight convergence of a broad family of in-parameter-linear nonlinear neural architectures as it generally applies to a broad family of incremental gradient learning algorithms. A practical BIBS convergence condition results from the derived proofs for every individual learning point or batches for real-time applications.
L2-norm Ensemble Regression with Ocean Feature Weights by Analyzed Images for Flood Inflow Forecast
Dec 06, 2021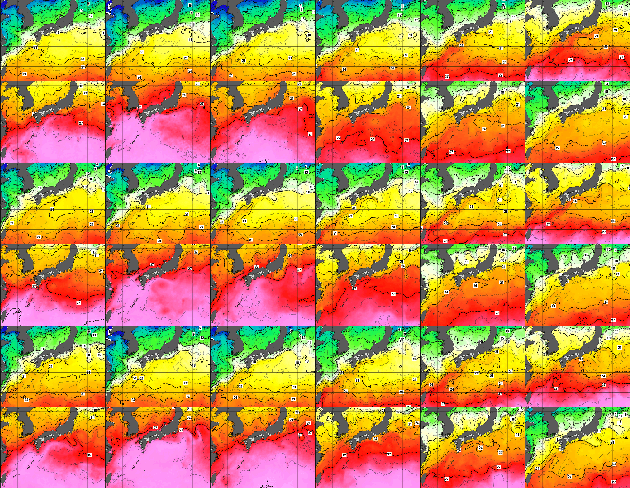

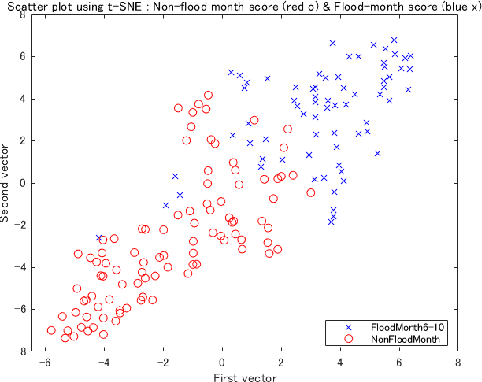

It is important to forecast dam inflow for flood damage mitigation. The hydrograph provides critical information such as the start time, peak level, and volume. Particularly, dam management requires a 6-h lead time of the dam inflow forecast based on a future hydrograph. The authors propose novel target inflow weights to create an ocean feature vector extracted from the analyzed images of the sea surface. We extracted 4,096 elements of the dimension vector in the fc6 layer of the pre-trained VGG16 network. Subsequently, we reduced it to three dimensions of t-SNE. Furthermore, we created the principal component of the sea temperature weights using PCA. We found that these weights contribute to the stability of predictor importance by numerical experiments. As base regression models, we calibrate the least squares with kernel expansion, the quantile random forest minimized out-of bag error, and the support vector regression with a polynomial kernel. When we compute the predictor importance, we visualize the stability of each variable importance introduced by our proposed weights, compared with other results without weights. We apply our method to a dam at Kanto region in Japan and focus on the trained term from 2007 to 2018, with a limited flood term from June to October. We test the accuracy over the 2019 flood term. Finally, we present the applied results and further statistical learning for unknown flood forecast.
Time Series Forecasting Using LSTM Networks: A Symbolic Approach
Mar 12, 2020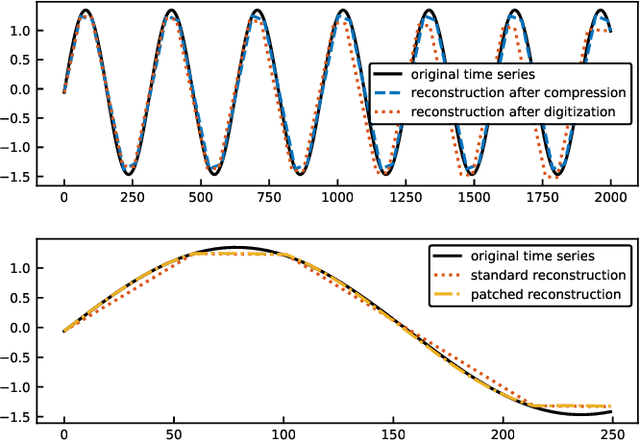
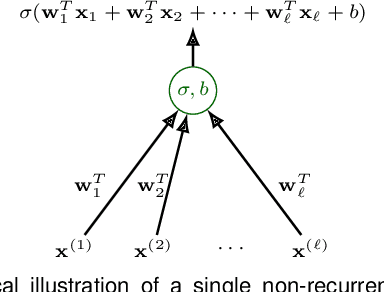
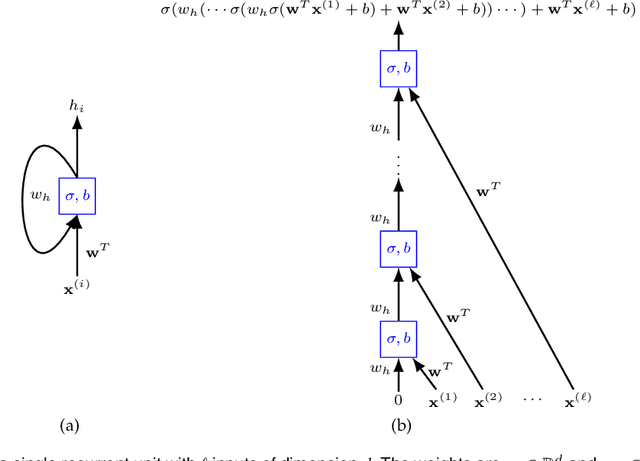
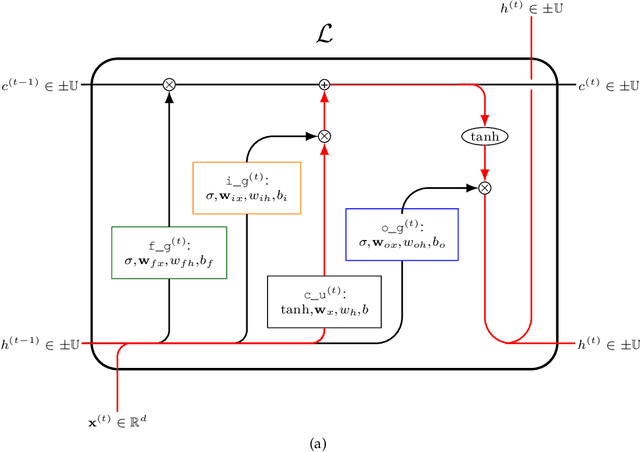
Machine learning methods trained on raw numerical time series data exhibit fundamental limitations such as a high sensitivity to the hyper parameters and even to the initialization of random weights. A combination of a recurrent neural network with a dimension-reducing symbolic representation is proposed and applied for the purpose of time series forecasting. It is shown that the symbolic representation can help to alleviate some of the aforementioned problems and, in addition, might allow for faster training without sacrificing the forecast performance.
Bayesian nonparametric shared multi-sequence time series segmentation
Jan 27, 2020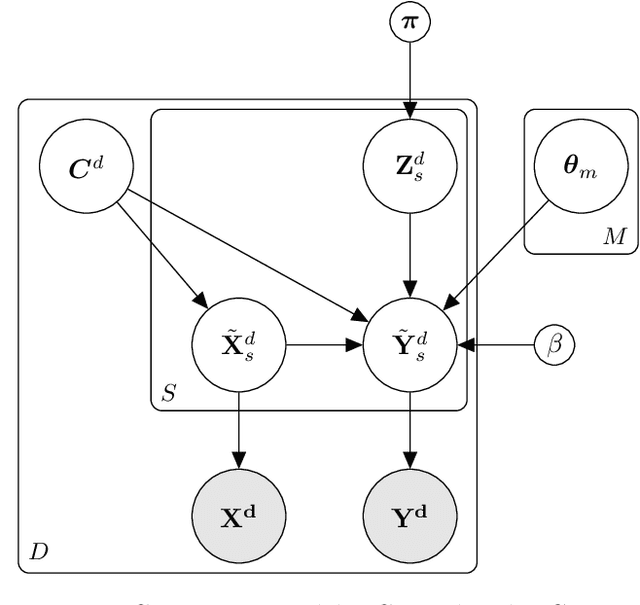
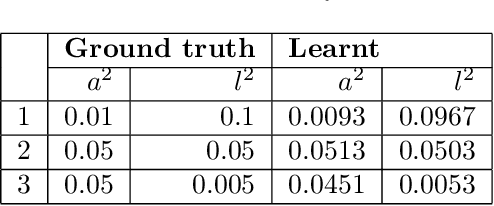
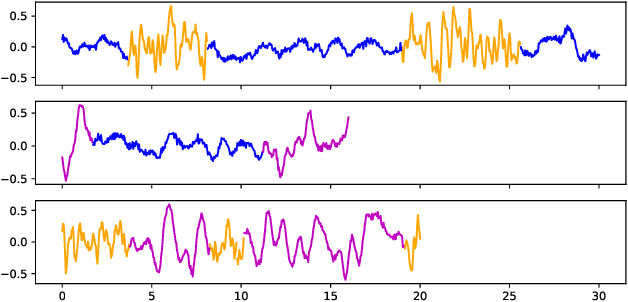
In this paper, we introduce a method for segmenting time series data using tools from Bayesian nonparametrics. We consider the task of temporal segmentation of a set of time series data into representative stationary segments. We use Gaussian process (GP) priors to impose our knowledge about the characteristics of the underlying stationary segments, and use a nonparametric distribution to partition the sequences into such segments, formulated in terms of a prior distribution on segment length. Given the segmentation, the model can be viewed as a variant of a Gaussian mixture model where the mixture components are described using the covariance function of a GP. We demonstrate the effectiveness of our model on synthetic data as well as on real time-series data of heartbeats where the task is to segment the indicative types of beats and to classify the heartbeat recordings into classes that correspond to healthy and abnormal heart sounds.
Stereo Magnification with Multi-Layer Images
Jan 13, 2022
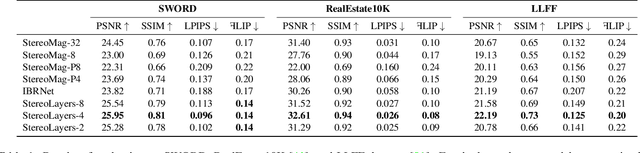

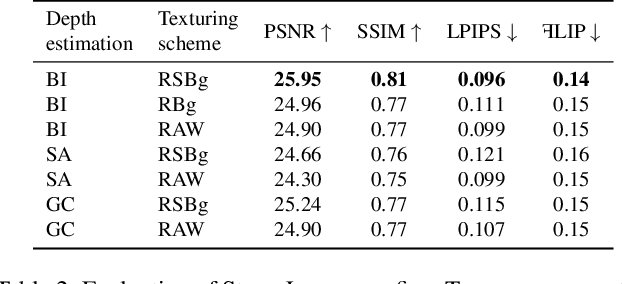
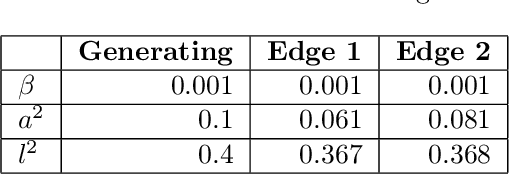
Representing scenes with multiple semi-transparent colored layers has been a popular and successful choice for real-time novel view synthesis. Existing approaches infer colors and transparency values over regularly-spaced layers of planar or spherical shape. In this work, we introduce a new view synthesis approach based on multiple semi-transparent layers with scene-adapted geometry. Our approach infers such representations from stereo pairs in two stages. The first stage infers the geometry of a small number of data-adaptive layers from a given pair of views. The second stage infers the color and the transparency values for these layers producing the final representation for novel view synthesis. Importantly, both stages are connected through a differentiable renderer and are trained in an end-to-end manner. In the experiments, we demonstrate the advantage of the proposed approach over the use of regularly-spaced layers with no adaptation to scene geometry. Despite being orders of magnitude faster during rendering, our approach also outperforms a recently proposed IBRNet system based on implicit geometry representation. See results at https://samsunglabs.github.io/StereoLayers .
Free-breathing motion compensated 4D (3D+respiration) T2-weighted turbo spin-echo MRI for body imaging
Feb 07, 2022Purpose: To develop and evaluate a free-breathing respiratory motion compensated 4D (3D+respiration) $T_2$-weighted turbo spin echo sequence with application to radiology and MR-guided radiotherapy. Methods: k-space data are continuously acquired using a rewound Cartesian acquisition with spiral profile ordering (rCASPR) to provide matching contrast to the conventional linear phase encode ordering and to sort data into multiple respiratory phases. Low-resolution respiratory-correlated 4D images were reconstructed with compressed sensing and used to estimate non-rigid deformation vector fields, which were subsequently used for a motion compensated image reconstruction. rCASPR sampling was compared to linear and CASPR sampling in terms of point-spread-function (PSF) and image contrast with in silico, phantom and in vivo experiments. Reconstruction parameters for low-resolution 4D-MRI (spatial resolution and temporal regularization) were determined using a grid search. The proposed motion compensated rCASPR was evaluated in eight healthy volunteers and compared to free-breathing scans with linear sampling. Image quality was compared based on visual inspection and quantitatively by means of the gradient entropy. Results: rCASPR provided a superior PSF (similar in ky and narrower in kz) and showed no considerable differences in images contrast compared to linear sampling. The optimal 4D-MRI reconstruction parameters were spatial resolution=$4.5 mm^3$ and $\lambda_t=10^{-4}$. The groupwise average gradient entropy was 22.31 for linear, 22.20 for rCASPR, 22.14 for soft-gated rCASPR and 22.02 for motion compensated rCASPR. Conclusion: The proposed motion compensated rCASPR enables high quality free-breathing T2-TSE with minimal changes in image contrast and scan time. The proposed method therefore enables direct transfer of clinically used 3D TSE sequences to free-breathing.
Power Control for Multigroup Multicast Cell-Free Massive MIMO Downlink
Jan 13, 2022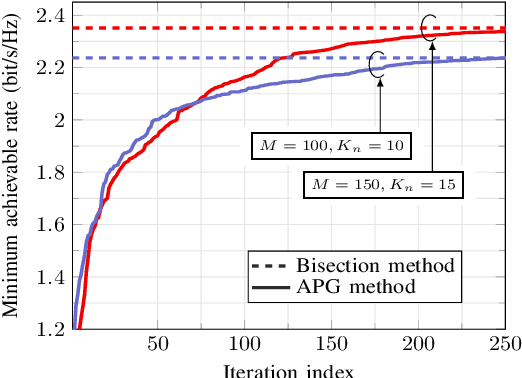
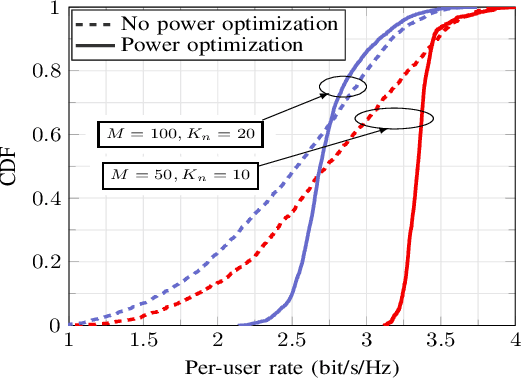
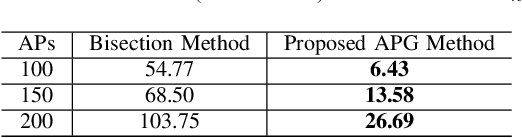
We consider a multigroup multicast cell-free multiple-input multiple-output (MIMO) downlink system with short-term power constraints. In particular, the normalized conjugate beamforming scheme is adopted at each access point (AP) to keep the downlink power strictly under the power budget regardless of small scale fading. In the considered scenario, APs multicast signals to multiple groups of users whereby users in the same group receive the same message. Under this setup, we are interested in maximizing the minimum achievable rate of all groups, commonly known as the max-min fairness problem, which has not been studied before in this context. To solve the considered problem, we first present a bisection method which in fact has been widely used in previous studies for cell-free massive MIMO, and then propose an accelerated projected gradient (APG) method. We show that the proposed APG method outperforms the bisection method requiring lesser run time while still achieving the same objective value. Moreover, the considered power control scheme provides significantly improved performance and more fairness among the users compared to the equal power allocation scheme.
Hybrid Imitation Learning for Real-Time Service Restoration in Resilient Distribution Systems
Nov 29, 2020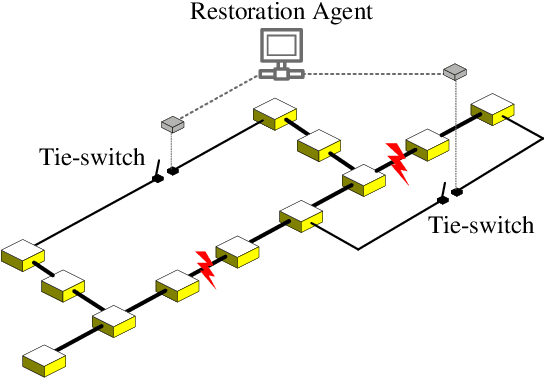
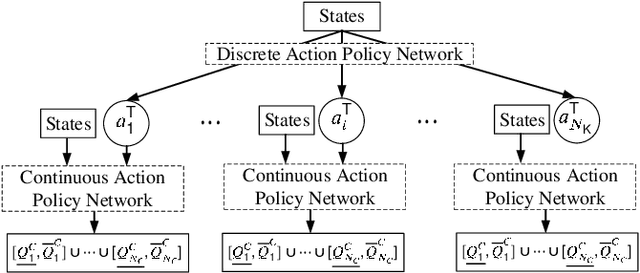
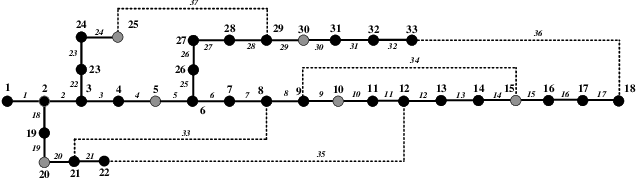
Self-healing capability is one of the most critical factors for a resilient distribution system, which requires intelligent agents to automatically perform restorative actions online, including network reconfiguration and reactive power dispatch. These agents should be equipped with a predesigned decision policy to meet real-time requirements and handle highly complex $N-k$ scenarios. The disturbance randomness hampers the application of exploration-dominant algorithms like traditional reinforcement learning (RL), and the agent training problem under $N-k$ scenarios has not been thoroughly solved. In this paper, we propose the imitation learning (IL) framework to train such policies, where the agent will interact with an expert to learn its optimal policy, and therefore significantly improve the training efficiency compared with the RL methods. To handle tie-line operations and reactive power dispatch simultaneously, we design a hybrid policy network for such a discrete-continuous hybrid action space. We employ the 33-node system under $N-k$ disturbances to verify the proposed framework.