 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time series classification for varying length series
Oct 10, 2019
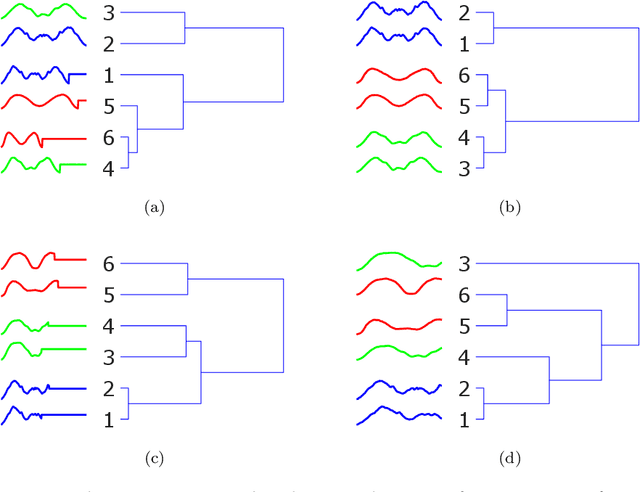
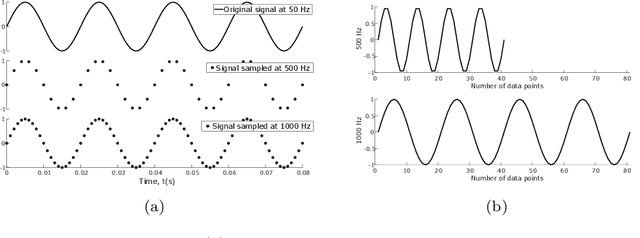
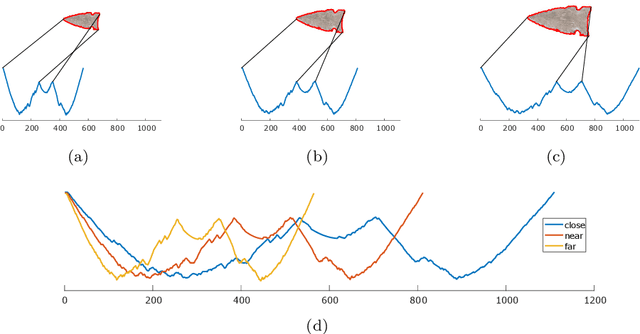
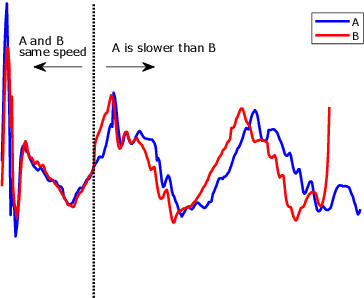
Research into time series classification has tended to focus on the case of series of uniform length. However, it is common for real-world time series data to have unequal lengths. Differing time series lengths may arise from a number of fundamentally different mechanisms. In this work, we identify and evaluate two classes of such mechanisms -- variations in sampling rate relative to the relevant signal and variations between the start and end points of one time series relative to one another. We investigate how time series generated by each of these classes of mechanism are best addressed for time series classification. We perform extensive experiments and provide practical recommendations on how variations in length should be handled in time series classification.
Network-based link prediction of scientific concepts -- a Science4Cast competition entry
Jan 18, 2022We report on a model built to predict links in a complex network of scientific concepts, in the context of the Science4Cast 2021 competition. We show that the network heavily favours linking nodes of high degree, indicating that new scientific connections are primarily made between popular concepts, which constitutes the main feature of our model. Besides this notion of popularity, we use a measure of similarity between nodes quantified by a normalized count of their common neighbours to improve the model. Finally, we show that the model can be further improved by considering a time-weighted adjacency matrix with both older and newer links having higher impact in the predictions, representing rooted concepts and state of the art research, respectively.
* Keywords: Link Prediction, Complex Networks, Semantic Network
Deep Learning for Reaction-Diffusion Glioma Growth Modelling: Towards a Fully Personalised Model?
Nov 26, 2021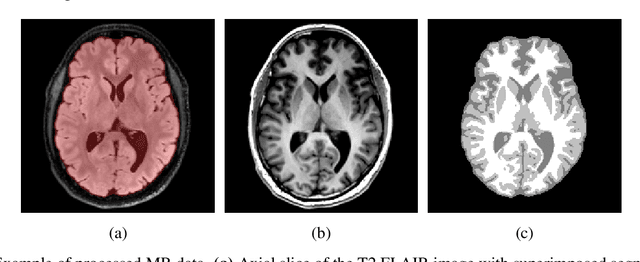
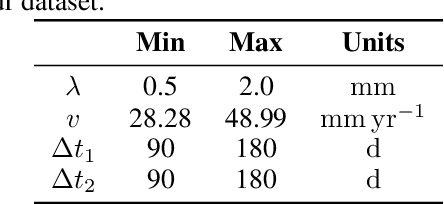
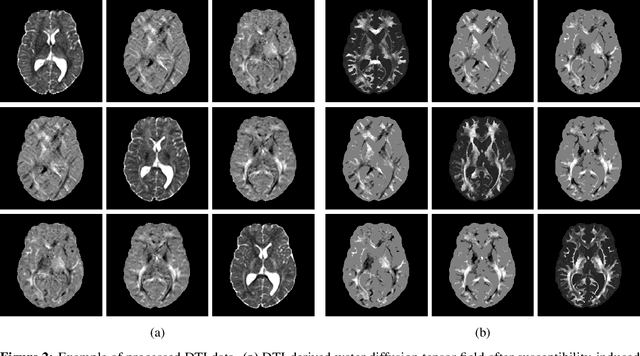

Reaction-diffusion models have been proposed for decades to capture the growth of gliomas, the most common primary brain tumours. However, severe limitations regarding the estimation of the initial conditions and parameter values of such models have restrained their clinical use as a personalised tool. In this work, we investigate the ability of deep convolutional neural networks (DCNNs) to address the pitfalls commonly encountered in the field. Based on 1,200 synthetic tumours grown over real brain geometries derived from magnetic resonance (MR) data of 6 healthy subjects, we demonstrate the ability of DCNNs to reconstruct a whole tumour cell density distribution from only two imaging contours at a single time point. With an additional imaging contour extracted at a prior time point, we also demonstrate the ability of DCNNs to accurately estimate the individual diffusivity and proliferation parameters of the model. From this knowledge, the spatio-temporal evolution of the tumour cell density distribution at later time points can ultimately be precisely captured using the model. We finally show the applicability of our approach to MR data of a real glioblastoma patient. This approach may open the perspective of a clinical application of reaction-diffusion growth models for tumour prognosis and treatment planning.
Mining On Alzheimer's Diseases Related Knowledge Graph to Identity Potential AD-related Semantic Triples for Drug Repurposing
Feb 17, 2022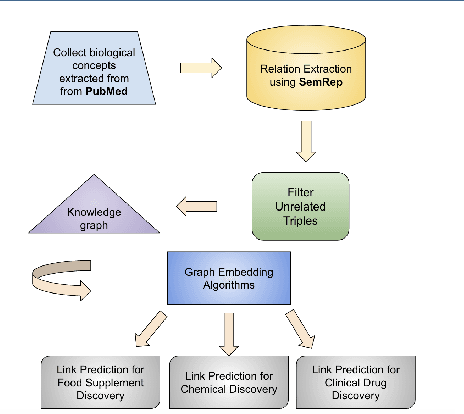

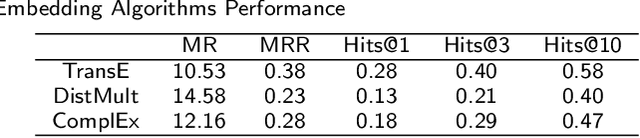
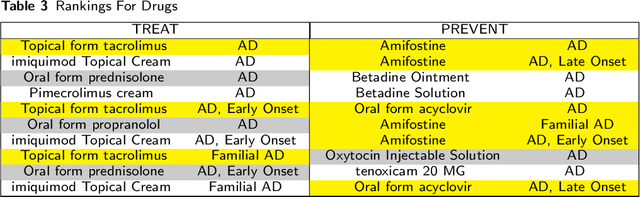
To date, there are no effective treatments for most neurodegenerative diseases. Knowledge graphs can provide comprehensive and semantic representation for heterogeneous data, and have been successfully leveraged in many biomedical applications including drug repurposing. Our objective is to construct a knowledge graph from literature to study relations between Alzheimer's disease (AD) and chemicals, drugs and dietary supplements in order to identify opportunities to prevent or delay neurodegenerative progression. We collected biomedical annotations and extracted their relations using SemRep via SemMedDB. We used both a BERT-based classifier and rule-based methods during data preprocessing to exclude noise while preserving most AD-related semantic triples. The 1,672,110 filtered triples were used to train with knowledge graph completion algorithms (i.e., TransE, DistMult, and ComplEx) to predict candidates that might be helpful for AD treatment or prevention. Among three knowledge graph completion models, TransE outperformed the other two (MR = 13.45, Hits@1 = 0.306). We leveraged the time-slicing technique to further evaluate the prediction results. We found supporting evidence for most highly ranked candidates predicted by our model which indicates that our approach can inform reliable new knowledge. This paper shows that our graph mining model can predict reliable new relationships between AD and other entities (i.e., dietary supplements, chemicals, and drugs). The knowledge graph constructed can facilitate data-driven knowledge discoveries and the generation of novel hypotheses.
Non-Coherent MIMO-OFDM Uplink empowered by the Spatial Diversity in Reflecting Surfaces
Feb 04, 2022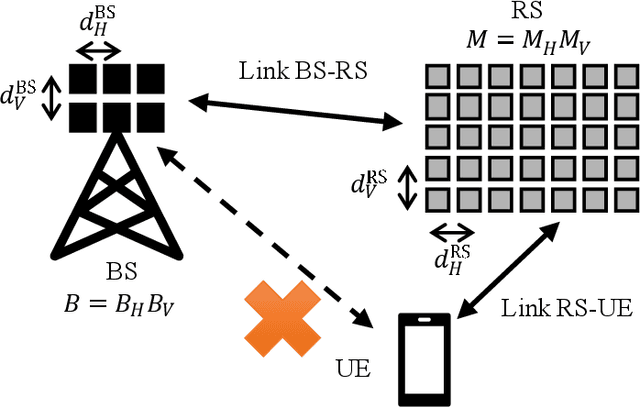
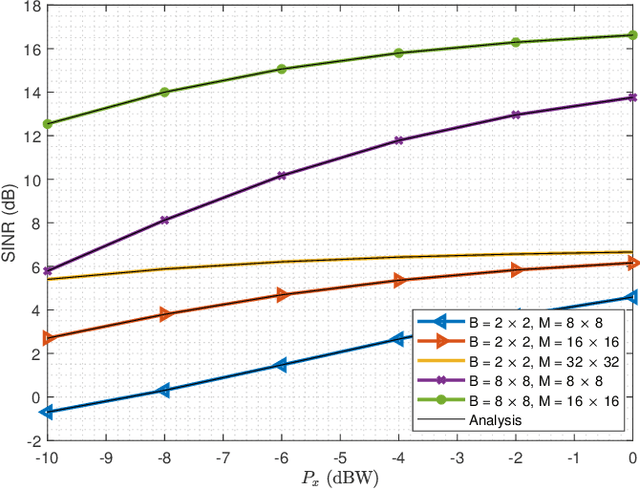
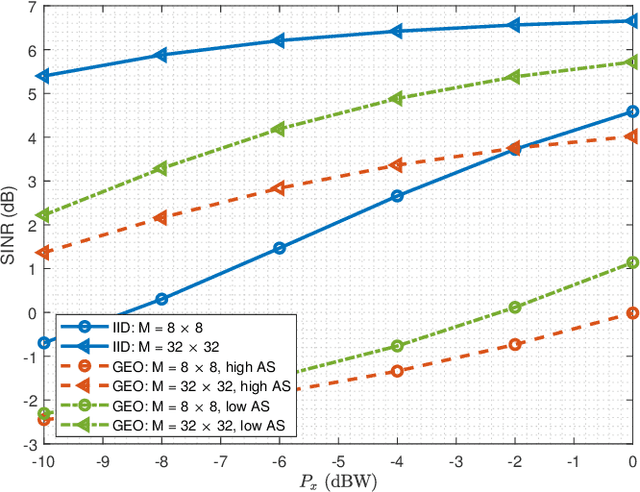
Reflecting Surfaces (RSs) are being lately envisioned as an energy efficient solution capable of enhancing the signal coverage in cases where obstacles block the direct communication from Base Stations (BSs), especially at high frequency bands due to attenuation loss increase. In the current literature, wireless communications via RSs are exclusively based on traditional coherent demodulation, which necessitates the estimation of accurate Channel State Information (CSI). However, this requirement results in an increased overhead, especially in time-varying channels, which reduces the resources that can be used for data communication. In this paper, we consider the uplink between a single-antenna user and a multi-antenna BS and present a novel RS-empowered Orthogonal Frequency Division Multiplexing (OFDM) communication system based on the differential phase shift keying, which is suitable for high noise and/or mobility scenarios. As a benchmark, analytical expressions for the Signal-to-Interference and Noise Ratio (SINR) of the proposed system are presented. Our extensive simulation results verify the accuracy of the presented analysis and showcase the performance and superiority of the proposed system over coherent demodulation.
A multi-reconstruction study of breast density estimation using Deep Learning
Feb 17, 2022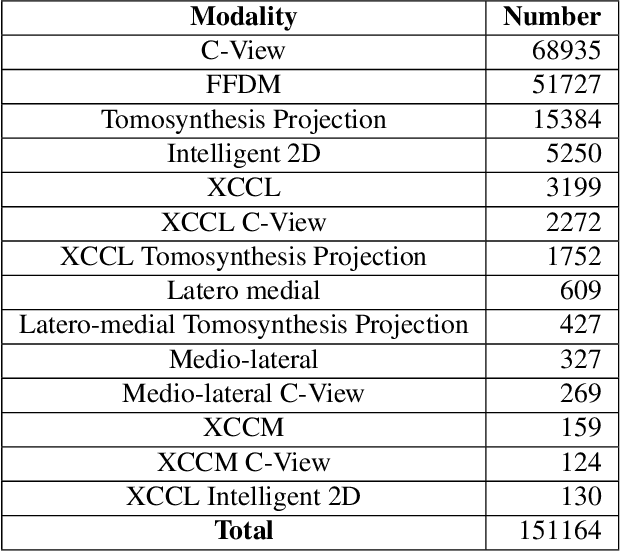
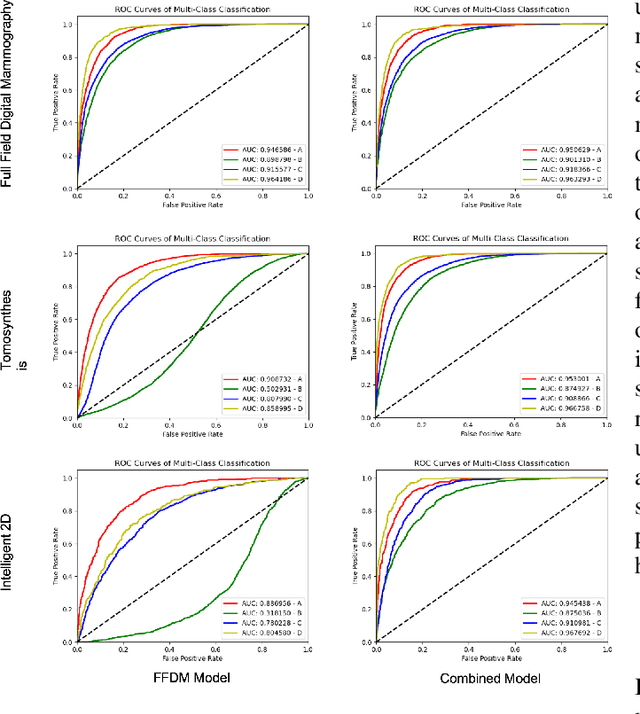
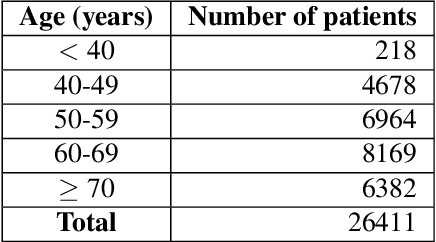
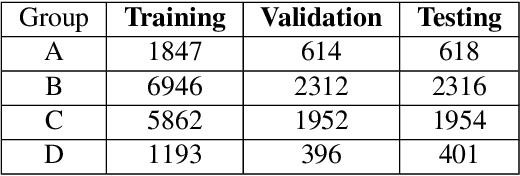
Breast density estimation is one of the key tasks in recognizing individuals predisposed to breast cancer. It is often challenging because of low contrast and fluctuations in mammograms' fatty tissue background. Most of the time, the breast density is estimated manually where a radiologist assigns one of the four density categories decided by the Breast Imaging and Reporting Data Systems (BI-RADS). There have been efforts in the direction of automating a breast density classification pipeline. Breast density estimation is one of the key tasks performed during a screening exam. Dense breasts are more susceptible to breast cancer. The density estimation is challenging because of low contrast and fluctuations in mammograms' fatty tissue background. Traditional mammograms are being replaced by tomosynthesis and its other low radiation dose variants (for example Hologic' Intelligent 2D and C-View). Because of the low-dose requirement, increasingly more screening centers are favoring the Intelligent 2D view and C-View. Deep-learning studies for breast density estimation use only a single modality for training a neural network. However, doing so restricts the number of images in the dataset. In this paper, we show that a neural network trained on all the modalities at once performs better than a neural network trained on any single modality. We discuss these results using the area under the receiver operator characteristics curves.
Efficient Policy Space Response Oracles
Feb 09, 2022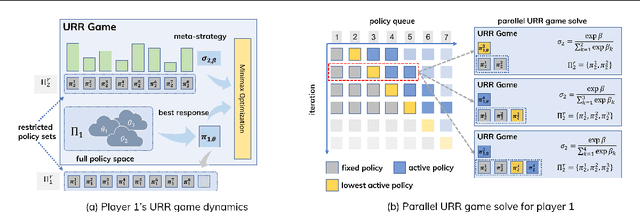
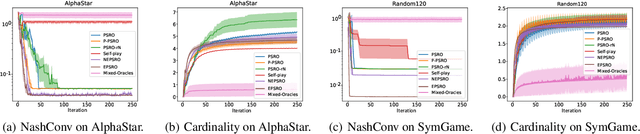
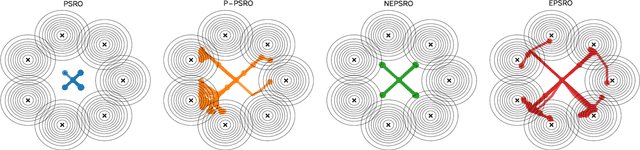
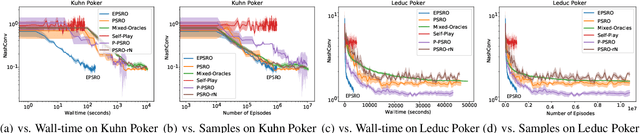
Policy Space Response Oracle method (PSRO) provides a general solution to Nash equilibrium in two-player zero-sum games but suffers from two problems: (1) the computation inefficiency due to consistently evaluating current populations by simulations; and (2) the exploration inefficiency due to learning best responses against a fixed meta-strategy at each iteration. In this work, we propose Efficient PSRO (EPSRO) that largely improves the efficiency of the above two steps. Central to our development is the newly-introduced subroutine of minimax optimization on unrestricted-restricted (URR) games. By solving URR at each step, one can evaluate the current game and compute the best response in one forward pass with no need for game simulations. Theoretically, we prove that the solution procedures of EPSRO offer a monotonic improvement on exploitability. Moreover, a desirable property of EPSRO is that it is parallelizable, this allows for efficient exploration in the policy space that induces behavioral diversity. We test EPSRO on three classes of games and report a 50x speedup in wall-time, 10x data efficiency, and similar exploitability as existing PSRO methods on Kuhn and Leduc Poker games.
Parametric t-Stochastic Neighbor Embedding With Quantum Neural Network
Feb 09, 2022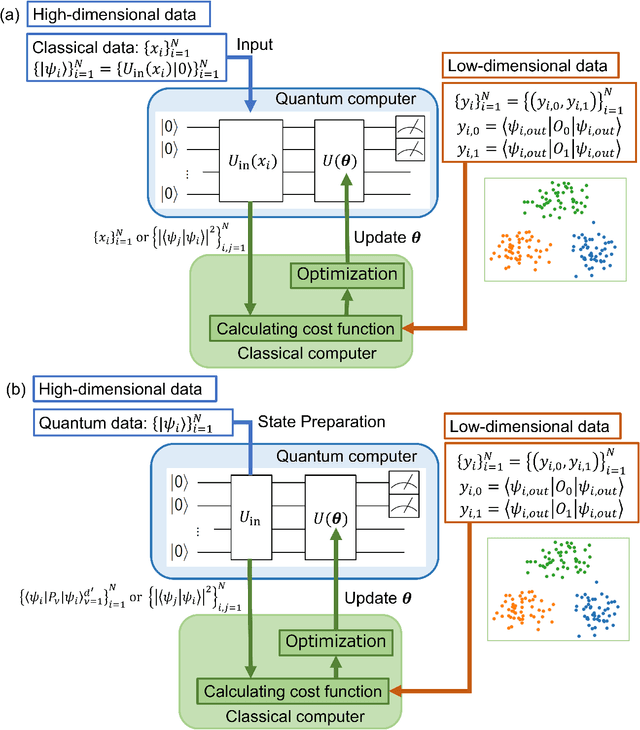
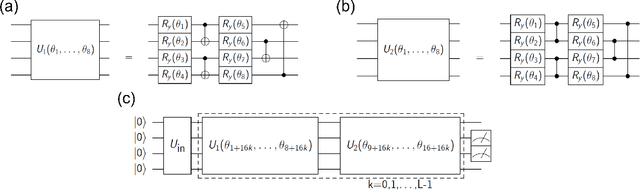
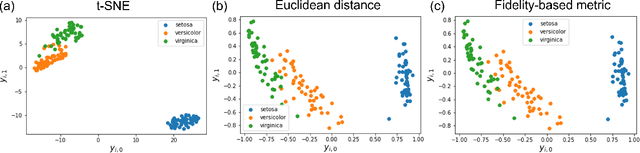
t-Stochastic Neighbor Embedding (t-SNE) is a non-parametric data visualization method in classical machine learning. It maps the data from the high-dimensional space into a low-dimensional space, especially a two-dimensional plane, while maintaining the relationship, or similarities, between the surrounding points. In t-SNE, the initial position of the low-dimensional data is randomly determined, and the visualization is achieved by moving the low-dimensional data to minimize a cost function. Its variant called parametric t-SNE uses neural networks for this mapping. In this paper, we propose to use quantum neural networks for parametric t-SNE to reflect the characteristics of high-dimensional quantum data on low-dimensional data. We use fidelity-based metrics instead of Euclidean distance in calculating high-dimensional data similarity. We visualize both classical (Iris dataset) and quantum (time-depending Hamiltonian dynamics) data for classification tasks. Since this method allows us to represent a quantum dataset in a higher dimensional Hilbert space by a quantum dataset in a lower dimension while keeping their similarity, the proposed method can also be used to compress quantum data for further quantum machine learning.
Variational Neural Temporal Point Process
Feb 17, 2022A temporal point process is a stochastic process that predicts which type of events is likely to happen and when the event will occur given a history of a sequence of events. There are various examples of occurrence dynamics in the daily life, and it is important to train the temporal dynamics and solve two different prediction problems, time and type predictions. Especially, deep neural network based models have outperformed the statistical models, such as Hawkes processes and Poisson processes. However, many existing approaches overfit to specific events, instead of learning and predicting various event types. Therefore, such approaches could not cope with the modified relationships between events and fail to predict the intensity functions of temporal point processes very well. In this paper, to solve these problems, we propose a variational neural temporal point process (VNTPP). We introduce the inference and the generative networks, and train a distribution of latent variable to deal with stochastic property on deep neural network. The intensity functions are computed using the distribution of latent variable so that we can predict event types and the arrival times of the events more accurately. We empirically demonstrate that our model can generalize the representations of various event types. Moreover, we show quantitatively and qualitatively that our model outperforms other deep neural network based models and statistical processes on synthetic and real-world datasets.
Neural Dual Contouring
Feb 04, 2022
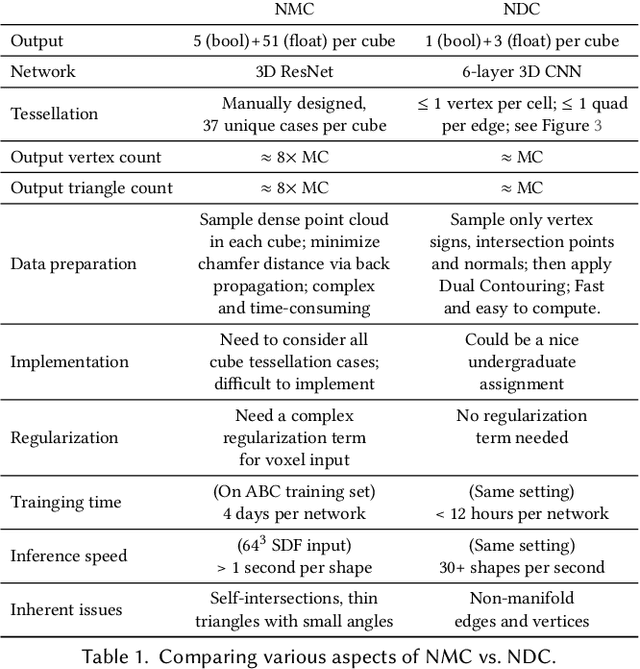
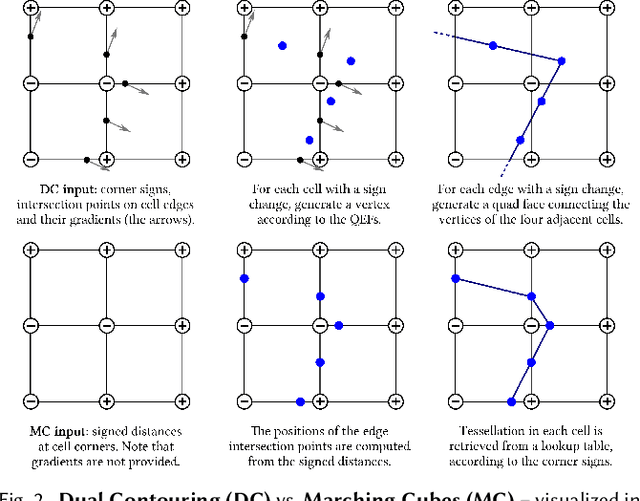
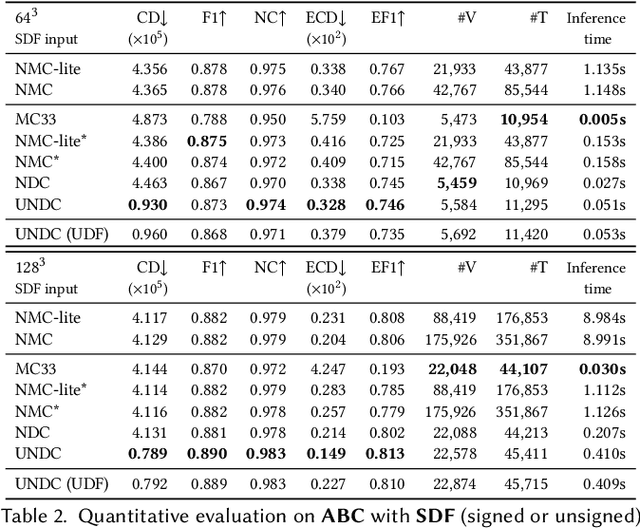
We introduce neural dual contouring (NDC), a new data-driven approach to mesh reconstruction based on dual contouring (DC). Like traditional DC, it produces exactly one vertex per grid cell and one quad for each grid edge intersection, a natural and efficient structure for reproducing sharp features. However, rather than computing vertex locations and edge crossings with hand-crafted functions that depend directly on difficult-to-obtain surface gradients, NDC uses a neural network to predict them. As a result, NDC can be trained to produce meshes from signed or unsigned distance fields, binary voxel grids, or point clouds (with or without normals); and it can produce open surfaces in cases where the input represents a sheet or partial surface. During experiments with five prominent datasets, we find that NDC, when trained on one of the datasets, generalizes well to the others. Furthermore, NDC provides better surface reconstruction accuracy, feature preservation, output complexity, triangle quality, and inference time in comparison to previous learned (e.g., neural marching cubes, convolutional occupancy networks) and traditional (e.g., Poisson) methods.