 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TURF: A Two-factor, Universal, Robust, Fast Distribution Learning Algorithm
Feb 15, 2022

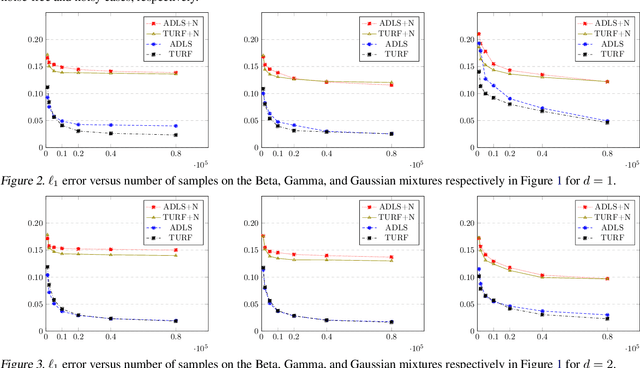
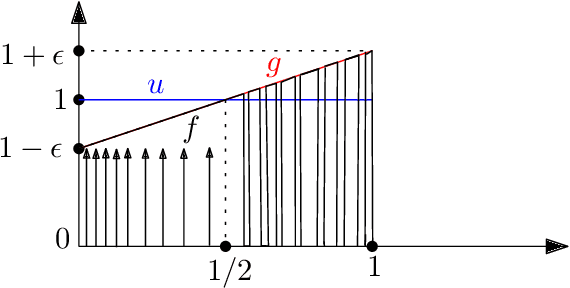
Approximating distributions from their samples is a canonical statistical-learning problem. One of its most powerful and successful modalities approximates every distribution to an $\ell_1$ distance essentially at most a constant times larger than its closest $t$-piece degree-$d$ polynomial, where $t\ge1$ and $d\ge0$. Letting $c_{t,d}$ denote the smallest such factor, clearly $c_{1,0}=1$, and it can be shown that $c_{t,d}\ge 2$ for all other $t$ and $d$. Yet current computationally efficient algorithms show only $c_{t,1}\le 2.25$ and the bound rises quickly to $c_{t,d}\le 3$ for $d\ge 9$. We derive a near-linear-time and essentially sample-optimal estimator that establishes $c_{t,d}=2$ for all $(t,d)\ne(1,0)$. Additionally, for many practical distributions, the lowest approximation distance is achieved by polynomials with vastly varying number of pieces. We provide a method that estimates this number near-optimally, hence helps approach the best possible approximation. Experiments combining the two techniques confirm improved performance over existing methodologies.
Survey of Machine Learning Based Intrusion Detection Methods for Internet of Medical Things
Feb 19, 2022

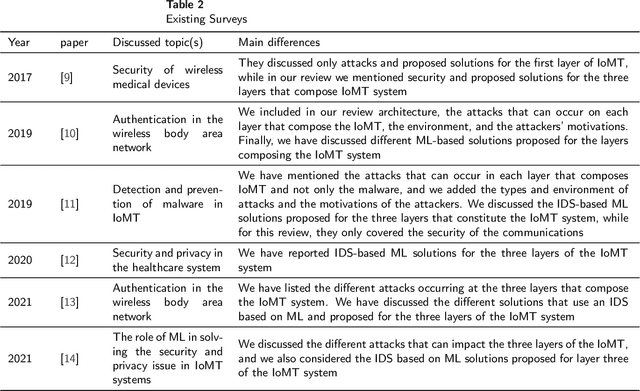
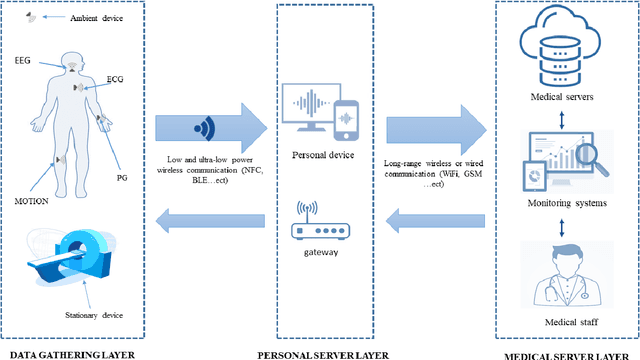
Internet of Medical Things (IoMT) represents an application of the Internet of Things, where health professionals perform remote analysis of physiological data collected using sensors that are associated with patients, allowing real-time and permanent monitoring of the patient's health condition and the detection of possible diseases at an early stage. However, the use of wireless communication for data transfer exposes this data to cyberattacks, and the sensitive and private nature of this data may represent a prime interest for attackers. The use of traditional security methods on equipment that is limited in terms of storage and computing capacity is ineffective. In this context, we have performed a comprehensive survey to investigate the use of the intrusion detection system based on machine learning (ML) for IoMT security. We presented the generic three-layer architecture of IoMT, the security requirement of IoMT security. We review the various threats that can affect IoMT security and identify the advantage, disadvantages, methods, and datasets used in each solution based on ML. Then we provide some challenges and limitations of applying ML on each layer of IoMT, which can serve as direction for future study.
The Pareto Frontier of Instance-Dependent Guarantees in Multi-Player Multi-Armed Bandits with no Communication
Feb 19, 2022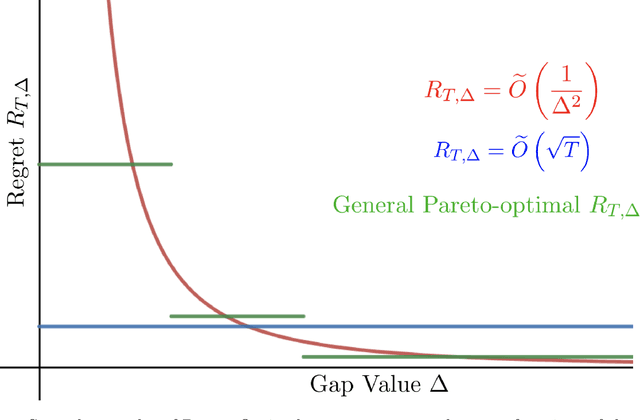
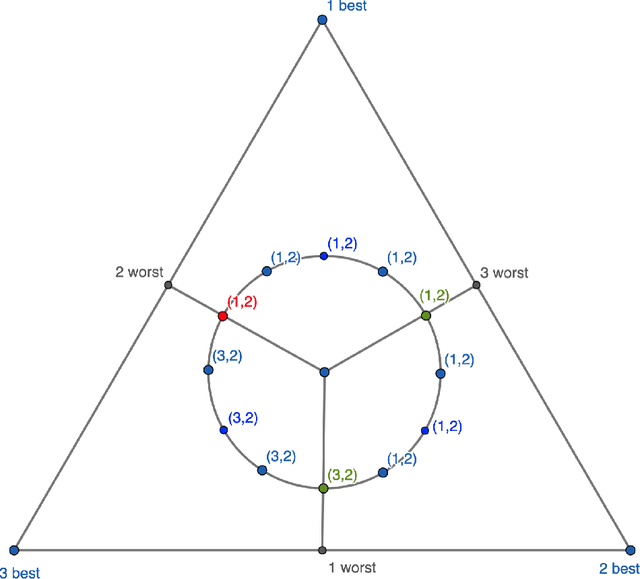
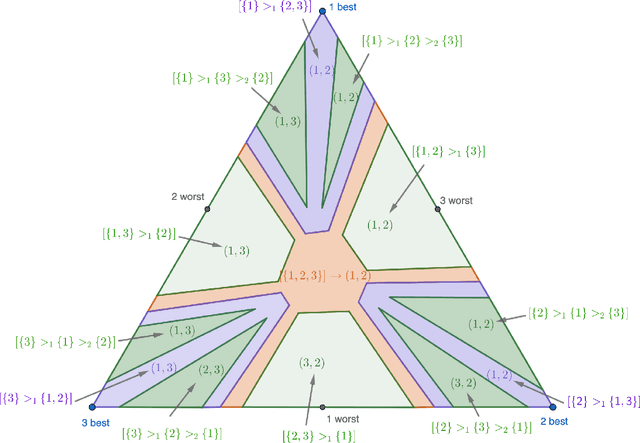
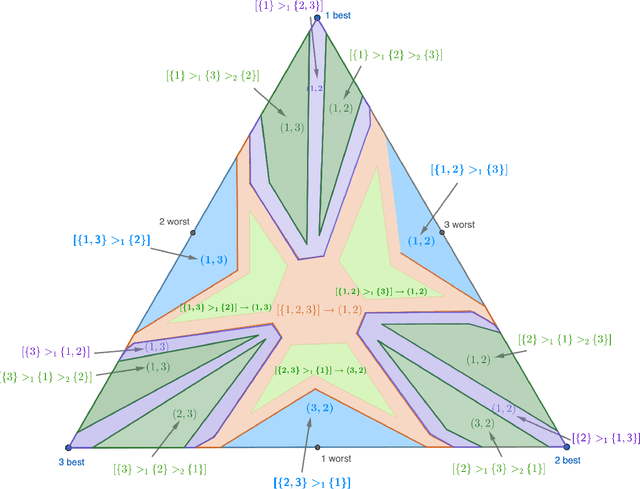
We study the stochastic multi-player multi-armed bandit problem. In this problem, $m$ players cooperate to maximize their total reward from $K > m$ arms. However the players cannot communicate and are penalized (e.g. receive no reward) if they pull the same arm at the same time. We ask whether it is possible to obtain optimal instance-dependent regret $\tilde{O}(1/\Delta)$ where $\Delta$ is the gap between the $m$-th and $m+1$-st best arms. Such guarantees were recently achieved in a model allowing the players to implicitly communicate through intentional collisions. We show that with no communication at all, such guarantees are, surprisingly, not achievable. In fact, obtaining the optimal $\tilde{O}(1/\Delta)$ regret for some regimes of $\Delta$ necessarily implies strictly sub-optimal regret in other regimes. Our main result is a complete characterization of the Pareto optimal instance-dependent trade-offs that are possible with no communication. Our algorithm generalizes that of Bubeck, Budzinski, and the second author and enjoys the same strong no-collision property, while our lower bound is based on a topological obstruction and holds even under full information.
Bilateral Deep Reinforcement Learning Approach for Better-than-human Car Following Model
Mar 03, 2022
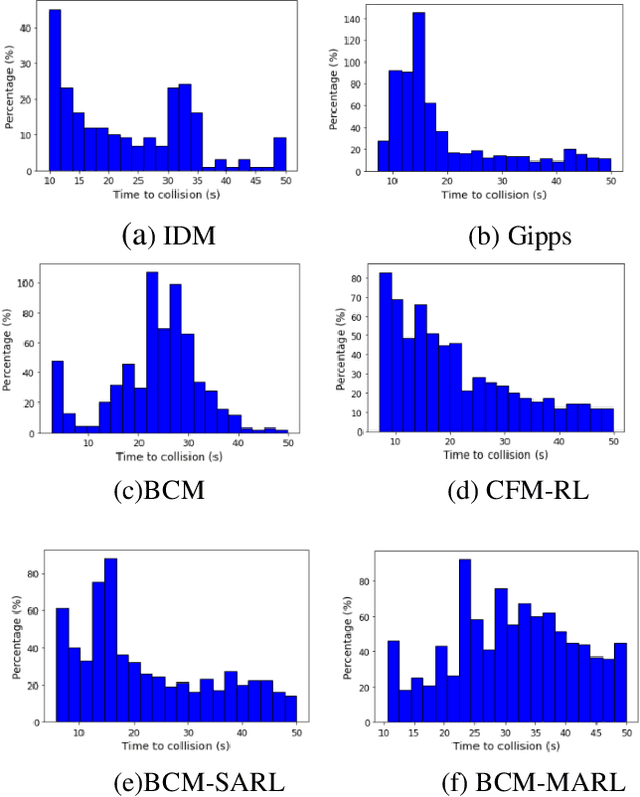
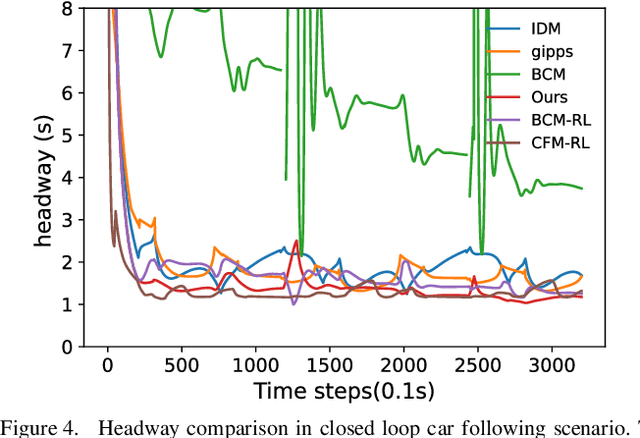
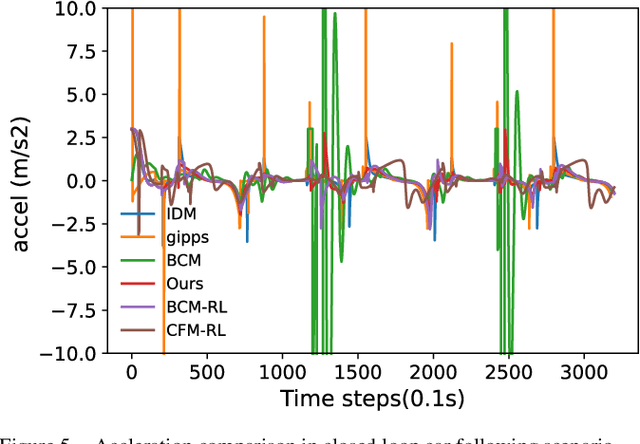
In the coming years and decades, autonomous vehicles (AVs) will become increasingly prevalent, offering new opportunities for safer and more convenient travel and potentially smarter traffic control methods exploiting automation and connectivity. Car following is a prime function in autonomous driving. Car following based on reinforcement learning has received attention in recent years with the goal of learning and achieving performance levels comparable to humans. However, most existing RL methods model car following as a unilateral problem, sensing only the vehicle ahead. Recent literature, however, Wang and Horn [16] has shown that bilateral car following that considers the vehicle ahead and the vehicle behind exhibits better system stability. In this paper we hypothesize that this bilateral car following can be learned using RL, while learning other goals such as efficiency maximisation, jerk minimization, and safety rewards leading to a learned model that outperforms human driving. We propose and introduce a Deep Reinforcement Learning (DRL) framework for car following control by integrating bilateral information into both state and reward function based on the bilateral control model (BCM) for car following control. Furthermore, we use a decentralized multi-agent reinforcement learning framework to generate the corresponding control action for each agent. Our simulation results demonstrate that our learned policy is better than the human driving policy in terms of (a) inter-vehicle headways, (b) average speed, (c) jerk, (d) Time to Collision (TTC) and (e) string stability.
Phase diagram of Stochastic Gradient Descent in high-dimensional two-layer neural networks
Feb 01, 2022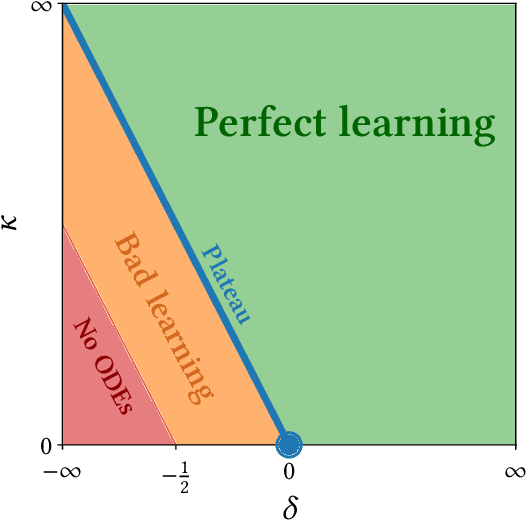
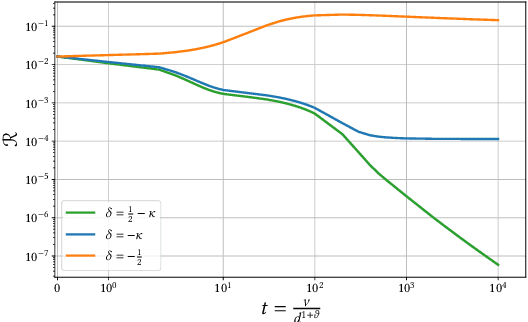
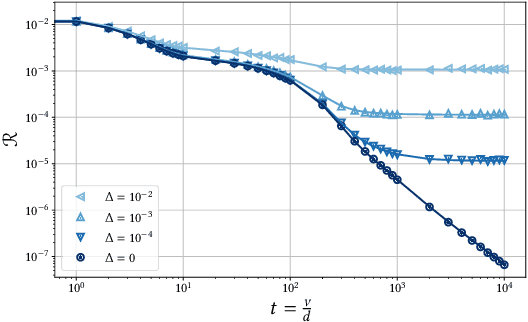
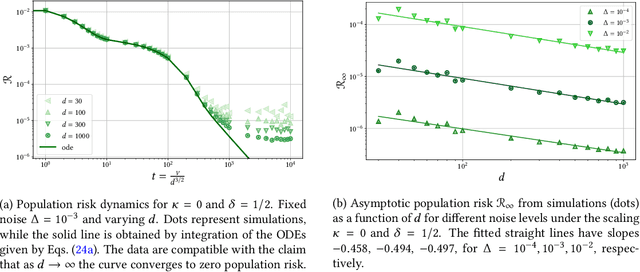
Despite the non-convex optimization landscape, over-parametrized shallow networks are able to achieve global convergence under gradient descent. The picture can be radically different for narrow networks, which tend to get stuck in badly-generalizing local minima. Here we investigate the cross-over between these two regimes in the high-dimensional setting, and in particular investigate the connection between the so-called mean-field/hydrodynamic regime and the seminal approach of Saad & Solla. Focusing on the case of Gaussian data, we study the interplay between the learning rate, the time scale, and the number of hidden units in the high-dimensional dynamics of stochastic gradient descent (SGD). Our work builds on a deterministic description of SGD in high-dimensions from statistical physics, which we extend and for which we provide rigorous convergence rates.
Communicating Robot Conventions through Shared Autonomy
Mar 03, 2022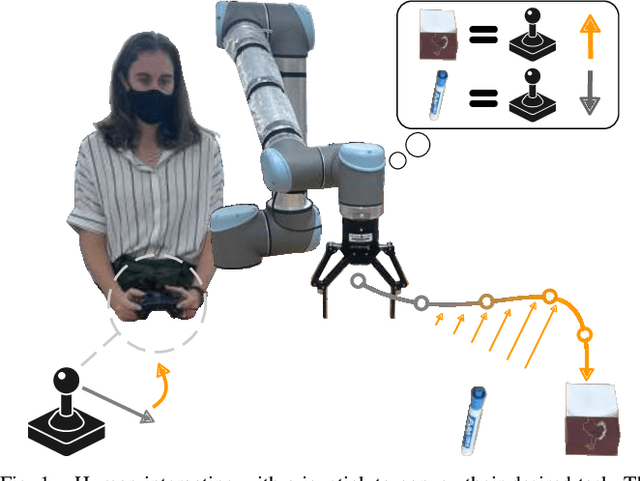

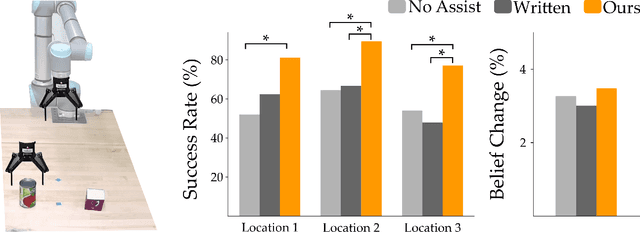
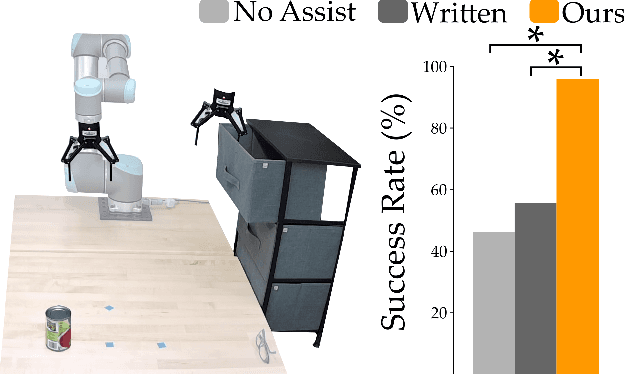
When humans control robot arms these robots often need to infer the human's desired task. Prior research on assistive teleoperation and shared autonomy explores how robots can determine the desired task based on the human's joystick inputs. In order to perform this inference the robot relies on an internal mapping between joystick inputs and discrete tasks: e.g., pressing the joystick left indicates that the human wants a plate, while pressing the joystick right indicates a cup. This approach works well after the human understands how the robot interprets their inputs -- but inexperienced users still have to learn these mappings through trial and error! Here we recognize that the robot's mapping between tasks and inputs is a convention. There are multiple, equally efficient conventions that the robot could use: rather than passively waiting for the human, we introduce a shared autonomy approach where the robot actively reveals its chosen convention. Across repeated interactions the robot intervenes and exaggerates the arm's motion to demonstrate more efficient inputs while also assisting for the current task. We compare this approach to a state-of-the-art baseline -- where users must identify the convention by themselves -- as well as written instructions. Our user study results indicate that modifying the robot's behavior to reveal its convention outperforms the baselines and reduces the amount of time that humans spend controlling the robot. See videos of our user study here: https://youtu.be/jROTVOp469I
A Visual Analytics Framework for Reviewing Multivariate Time-Series Data with Dimensionality Reduction
Aug 02, 2020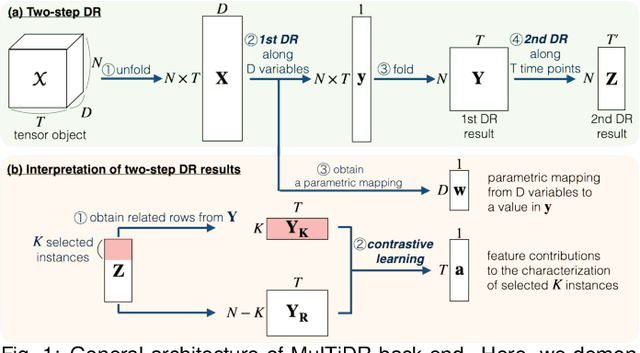
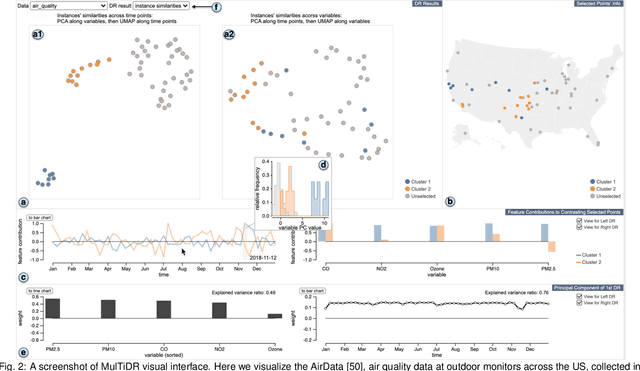
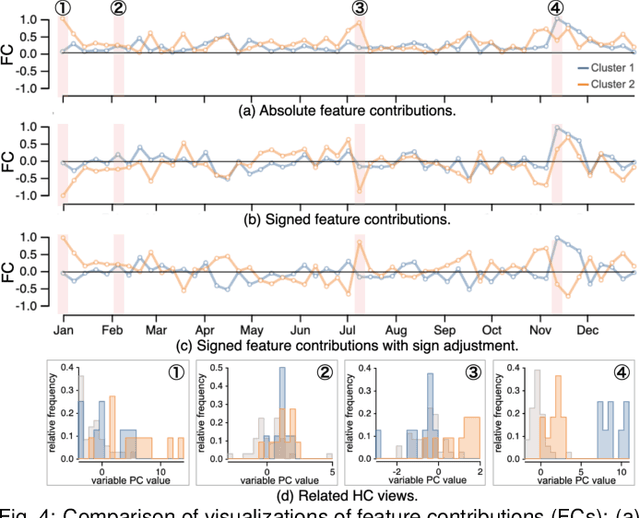
Data-driven problem solving in many real-world applications involves analysis of time-dependent multivariate data, for which dimensionality reduction (DR) methods are often used to uncover the intrinsic structure and features of the data. However, DR is usually applied to a subset of data that is either single-time-point multivariate or univariate time-series, resulting in the need to manually examine and correlate the DR results out of different data subsets. When the number of dimensions is large either in terms of the number of time points or attributes, this manual task becomes too tedious and infeasible. In this paper, we present MulTiDR, a new DR framework that enables processing of time-dependent multivariate data as a whole to provide a comprehensive overview of the data. With the framework, we employ DR in two steps. When treating the instances, time points, and attributes of the data as a 3D array, the first DR step reduces the three axes of the array to two, and the second DR step visualizes the data in a lower-dimensional space. In addition, by coupling with a contrastive learning method and interactive visualizations, our framework enhances analysts' ability to interpret DR results. We demonstrate the effectiveness of our framework with four case studies using real-world datasets.
Dynamical Dorfman Testing with Quarantine
Jan 18, 2022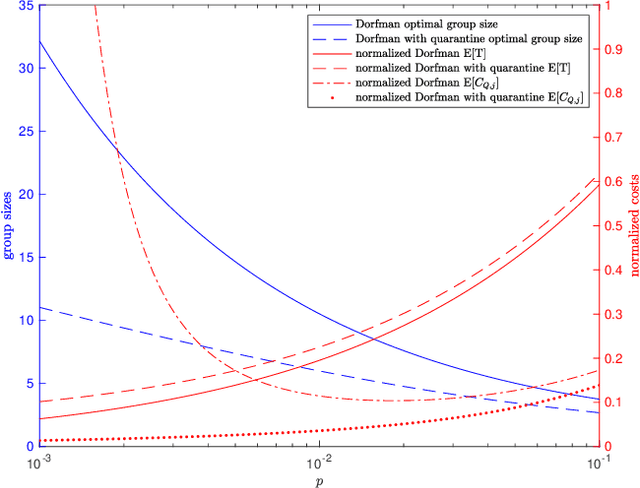
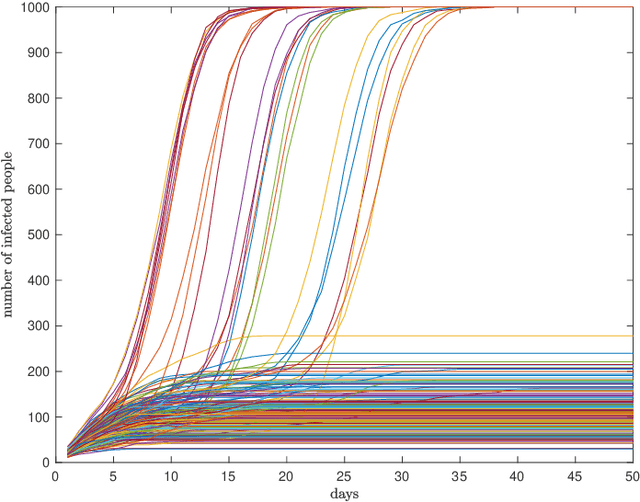
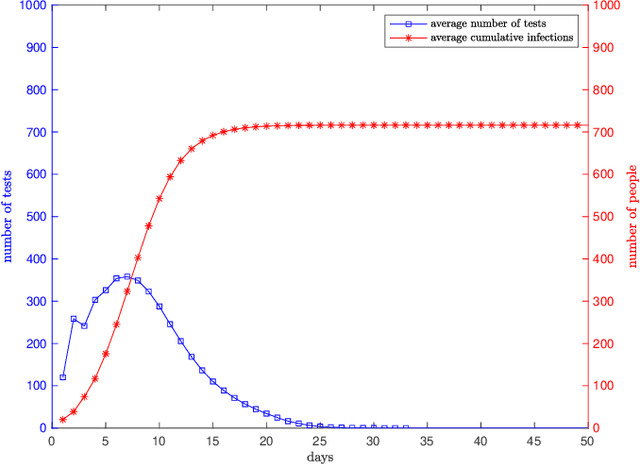
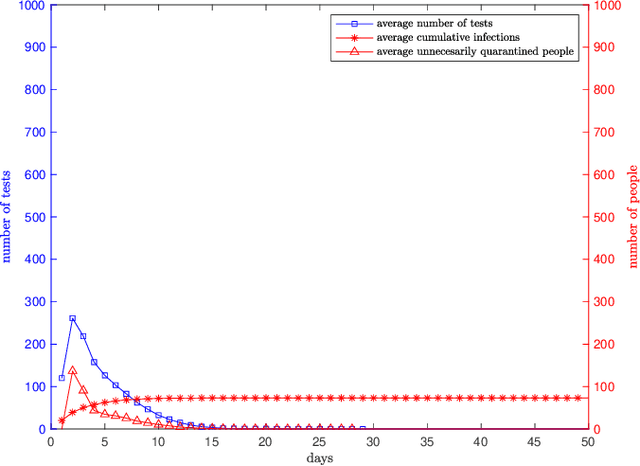
We consider dynamical group testing problem with a community structure. With a discrete-time SIR (susceptible, infectious, recovered) model, we use Dorfman's two-step group testing approach to identify infections, and step in whenever necessary to inhibit infection spread via quarantines. We analyze the trade-off between quarantine and test costs as well as disease spread. For the special dynamical i.i.d. model, we show that the optimal first stage Dorfman group size differs in dynamic and static cases. We compare the performance of the proposed dynamic two-stage Dorfman testing with state-of-the-art non-adaptive group testing method in dynamic settings.
Label Dependent Attention Model for Disease Risk Prediction Using Multimodal Electronic Health Records
Jan 18, 2022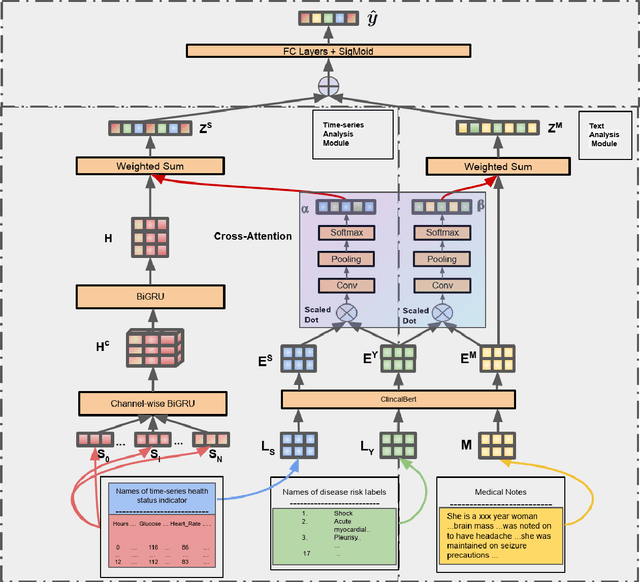
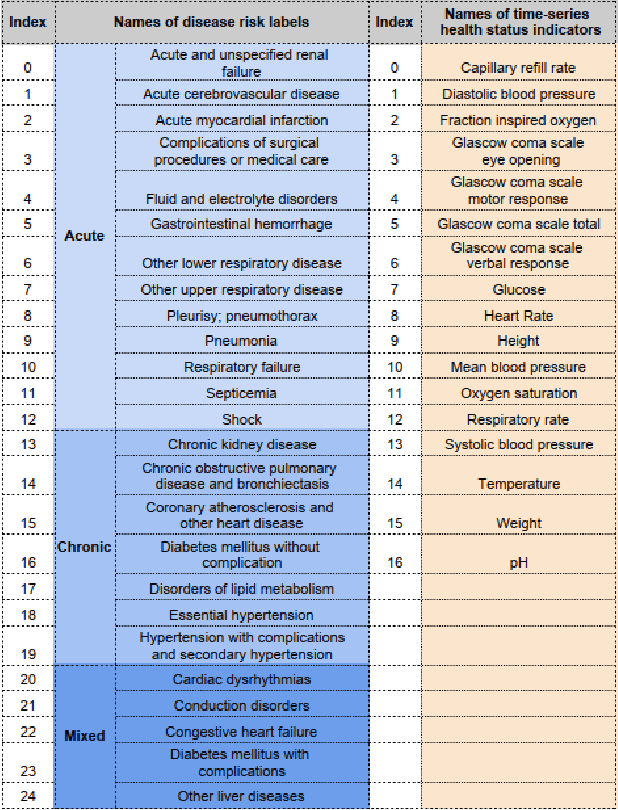

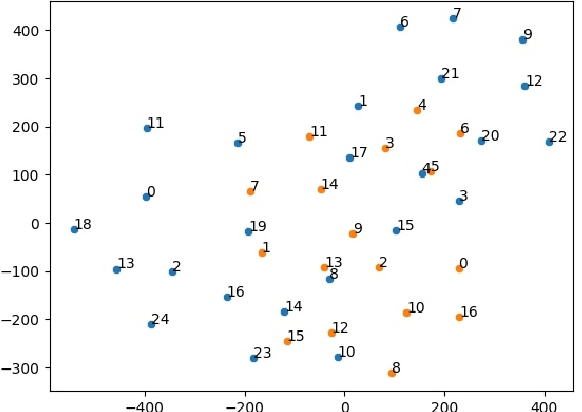
Disease risk prediction has attracted increasing attention in the field of modern healthcare, especially with the latest advances in artificial intelligence (AI). Electronic health records (EHRs), which contain heterogeneous patient information, are widely used in disease risk prediction tasks. One challenge of applying AI models for risk prediction lies in generating interpretable evidence to support the prediction results while retaining the prediction ability. In order to address this problem, we propose the method of jointly embedding words and labels whereby attention modules learn the weights of words from medical notes according to their relevance to the names of risk prediction labels. This approach boosts interpretability by employing an attention mechanism and including the names of prediction tasks in the model. However, its application is only limited to the handling of textual inputs such as medical notes. In this paper, we propose a label dependent attention model LDAM to 1) improve the interpretability by exploiting Clinical-BERT (a biomedical language model pre-trained on a large clinical corpus) to encode biomedically meaningful features and labels jointly; 2) extend the idea of joint embedding to the processing of time-series data, and develop a multi-modal learning framework for integrating heterogeneous information from medical notes and time-series health status indicators. To demonstrate our method, we apply LDAM to the MIMIC-III dataset to predict different disease risks. We evaluate our method both quantitatively and qualitatively. Specifically, the predictive power of LDAM will be shown, and case studies will be carried out to illustrate its interpretability.
PanoNet: Real-time Panoptic Segmentation through Position-Sensitive Feature Embedding
Aug 01, 2020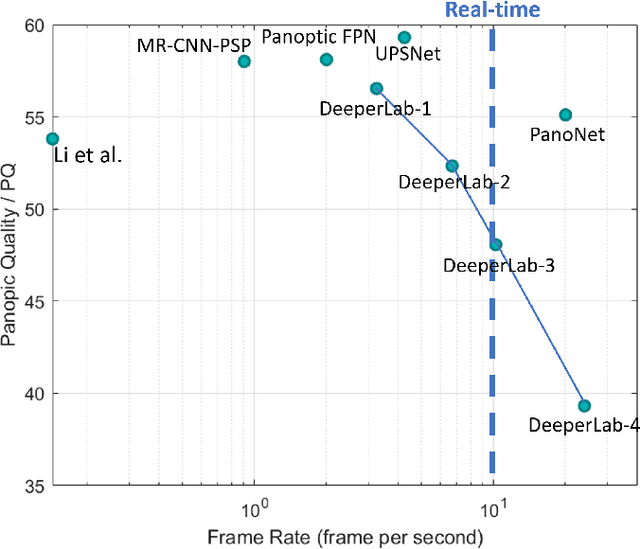
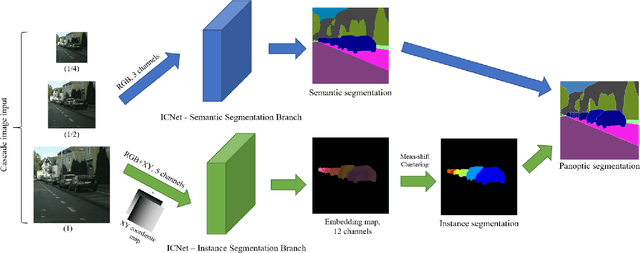


We propose a simple, fast, and flexible framework to generate simultaneously semantic and instance masks for panoptic segmentation. Our method, called PanoNet, incorporates a clean and natural structure design that tackles the problem purely as a segmentation task without the time-consuming detection process. We also introduce position-sensitive embedding for instance grouping by accounting for both object's appearance and its spatial location. Overall, PanoNet yields high panoptic quality results of high-resolution Cityscapes images in real-time, significantly faster than all other methods with comparable performance. Our approach well satisfies the practical speed and memory requirement for many applications like autonomous driving and augmented reality.