 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
StyleHEAT: One-Shot High-Resolution Editable Talking Face Generation via Pre-trained StyleGAN
Mar 17, 2022


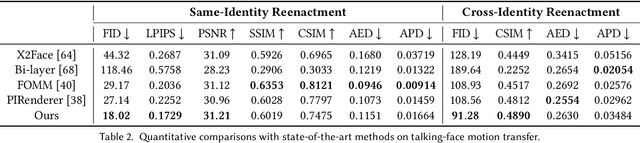
One-shot talking face generation aims at synthesizing a high-quality talking face video from an arbitrary portrait image, driven by a video or an audio segment. One challenging quality factor is the resolution of the output video: higher resolution conveys more details. In this work, we investigate the latent feature space of a pre-trained StyleGAN and discover some excellent spatial transformation properties. Upon the observation, we explore the possibility of using a pre-trained StyleGAN to break through the resolution limit of training datasets. We propose a novel unified framework based on a pre-trained StyleGAN that enables a set of powerful functionalities, i.e., high-resolution video generation, disentangled control by driving video or audio, and flexible face editing. Our framework elevates the resolution of the synthesized talking face to 1024*1024 for the first time, even though the training dataset has a lower resolution. We design a video-based motion generation module and an audio-based one, which can be plugged into the framework either individually or jointly to drive the video generation. The predicted motion is used to transform the latent features of StyleGAN for visual animation. To compensate for the transformation distortion, we propose a calibration network as well as a domain loss to refine the features. Moreover, our framework allows two types of facial editing, i.e., global editing via GAN inversion and intuitive editing based on 3D morphable models. Comprehensive experiments show superior video quality, flexible controllability, and editability over state-of-the-art methods.
A low-rank ensemble Kalman filter for elliptic observations
Mar 10, 2022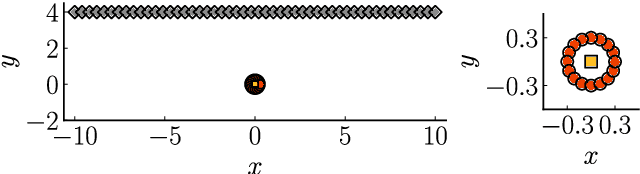
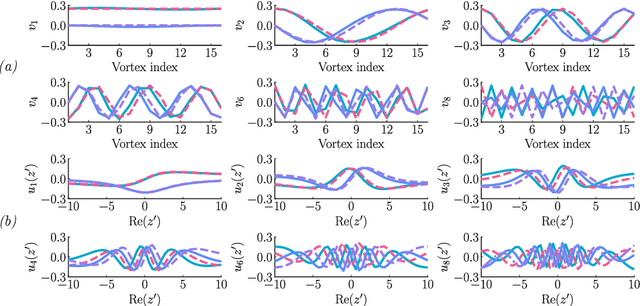
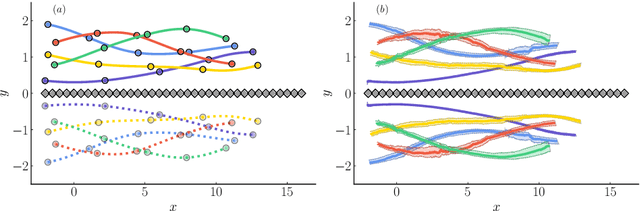
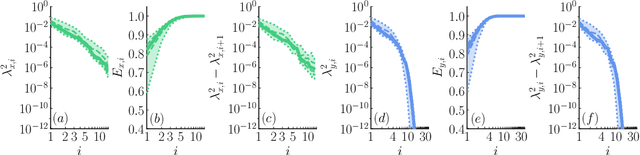
We propose a regularization method for ensemble Kalman filtering (EnKF) with elliptic observation operators. Commonly used EnKF regularization methods suppress state correlations at long distances. For observations described by elliptic partial differential equations, such as the pressure Poisson equation (PPE) in incompressible fluid flows, distance localization cannot be applied, as we cannot disentangle slowly decaying physical interactions from spurious long-range correlations. This is particularly true for the PPE, in which distant vortex elements couple nonlinearly to induce pressure. Instead, these inverse problems have a low effective dimension: low-dimensional projections of the observations strongly inform a low-dimensional subspace of the state space. We derive a low-rank factorization of the Kalman gain based on the spectrum of the Jacobian of the observation operator. The identified eigenvectors generalize the source and target modes of the multipole expansion, independently of the underlying spatial distribution of the problem. Given rapid spectral decay, inference can be performed in the low-dimensional subspace spanned by the dominant eigenvectors. This low-rank EnKF is assessed on dynamical systems with Poisson observation operators, where we seek to estimate the positions and strengths of point singularities over time from potential or pressure observations. We also comment on the broader applicability of this approach to elliptic inverse problems outside the context of filtering.
Finite Sample Analysis of Two-Time-Scale Natural Actor-Critic Algorithm
Jan 26, 2021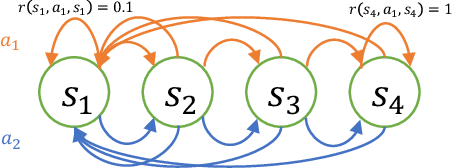
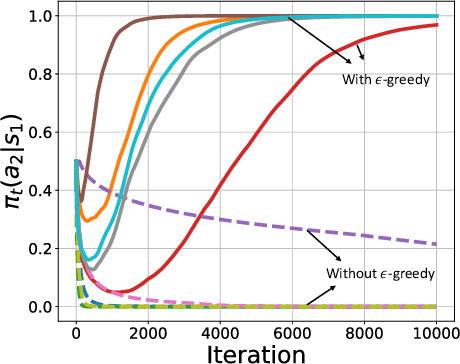
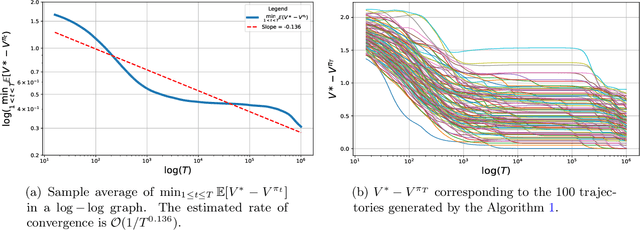
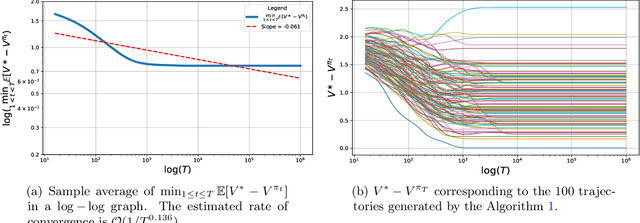
Actor-critic style two-time-scale algorithms are very popular in reinforcement learning, and have seen great empirical success. However, their performance is not completely understood theoretically. In this paper, we characterize the global convergence of an online natural actor-critic algorithm in the tabular setting using a single trajectory. Our analysis applies to very general settings, as we only assume that the underlying Markov chain is ergodic under all policies (the so-called Recurrence assumption). We employ $\epsilon$-greedy sampling in order to ensure enough exploration. For a fixed exploration parameter $\epsilon$, we show that the natural actor critic algorithm is $\mathcal{O}(\frac{1}{\epsilon T^{1/4}}+\epsilon)$ close to the global optimum after $T$ iterations of the algorithm. By carefully diminishing the exploration parameter $\epsilon$ as the iterations proceed, we also show convergence to the global optimum at a rate of $\mathcal{O}(1/T^{1/6})$.
RRL:Regional Rotation Layer in Convolutional Neural Networks
Feb 25, 2022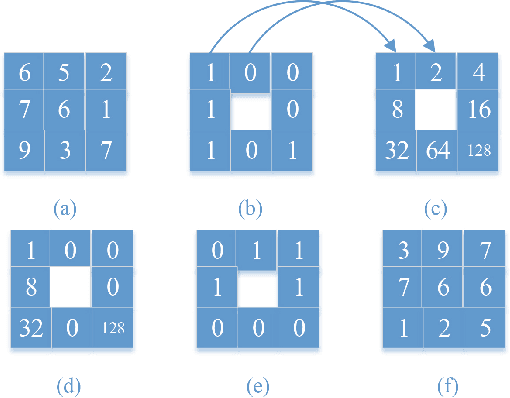
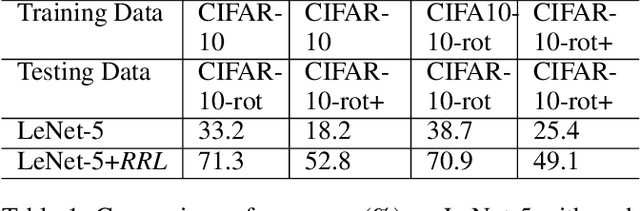
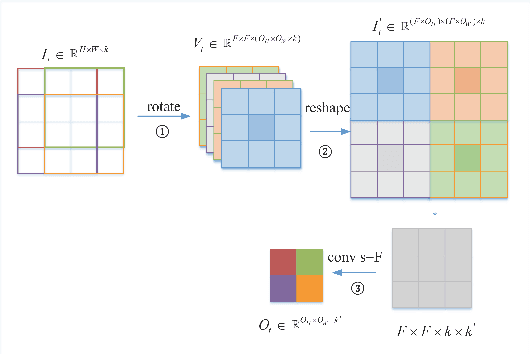
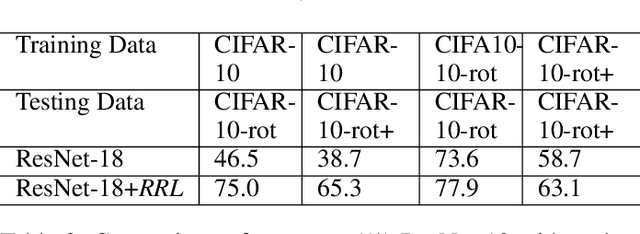
Convolutional Neural Networks (CNNs) perform very well in image classification and object detection in recent years, but even the most advanced models have limited rotation invariance. Known solutions include the enhancement of training data and the increase of rotation invariance by globally merging the rotation equivariant features. These methods either increase the workload of training or increase the number of model parameters. To address this problem, this paper proposes a module that can be inserted into the existing networks, and directly incorporates the rotation invariance into the feature extraction layers of the CNNs. This module does not have learnable parameters and will not increase the complexity of the model. At the same time, only by training the upright data, it can perform well on the rotated testing set. These advantages will be suitable for fields such as biomedicine and astronomy where it is difficult to obtain upright samples or the target has no directionality. Evaluate our module with LeNet-5, ResNet-18 and tiny-yolov3, we get impressive results.
Deep Movement Primitives: toward Breast Cancer Examination Robot
Feb 14, 2022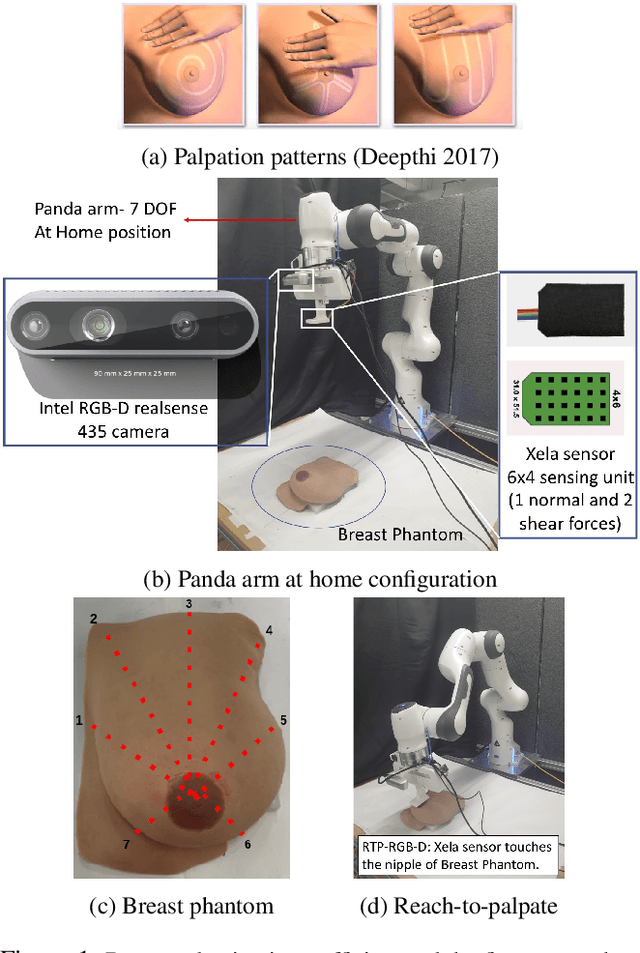
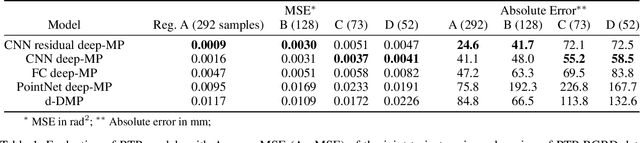
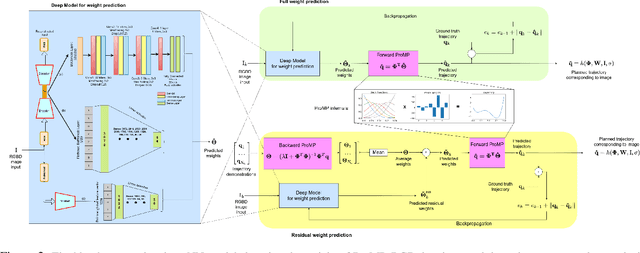
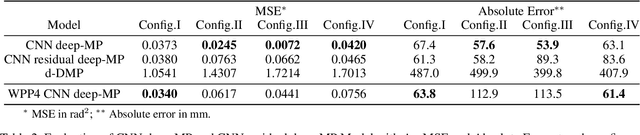
Breast cancer is the most common type of cancer worldwide. A robotic system performing autonomous breast palpation can make a significant impact on the related health sector worldwide. However, robot programming for breast palpating with different geometries is very complex and unsolved. Robot learning from demonstrations (LfD) reduces the programming time and cost. However, the available LfD are lacking the modelling of the manipulation path/trajectory as an explicit function of the visual sensory information. This paper presents a novel approach to manipulation path/trajectory planning called deep Movement Primitives that successfully generates the movements of a manipulator to reach a breast phantom and perform the palpation. We show the effectiveness of our approach by a series of real-robot experiments of reaching and palpating a breast phantom. The experimental results indicate our approach outperforms the state-of-the-art method.
Attention-gated convolutional neural networks for off-resonance correction of spiral real-time MRI
Feb 14, 2021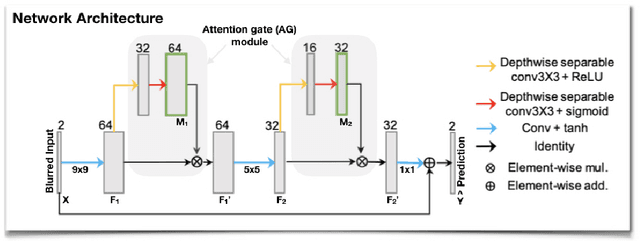
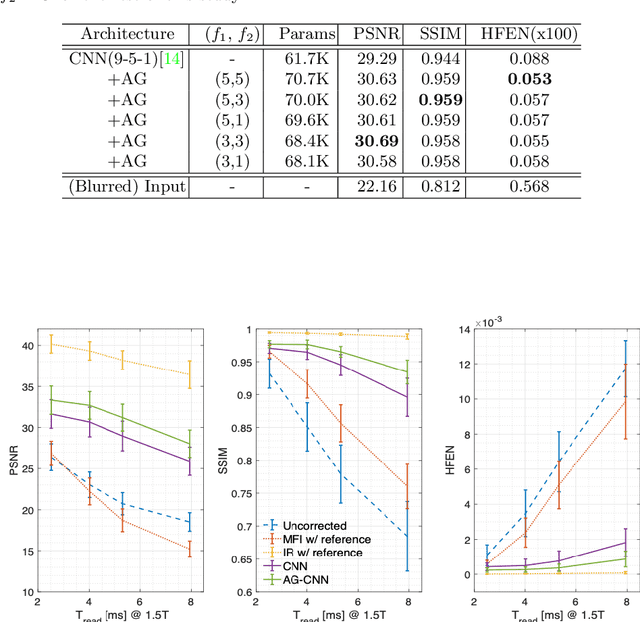

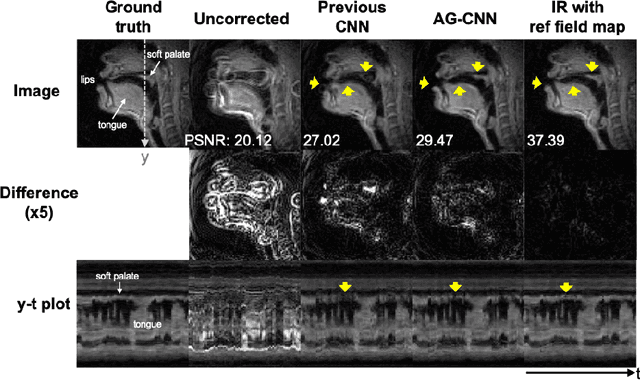
Spiral acquisitions are preferred in real-time MRI because of their efficiency, which has made it possible to capture vocal tract dynamics during natural speech. A fundamental limitation of spirals is blurring and signal loss due to off-resonance, which degrades image quality at air-tissue boundaries. Here, we present a new CNN-based off-resonance correction method that incorporates an attention-gate mechanism. This leverages spatial and channel relationships of filtered outputs and improves the expressiveness of the networks. We demonstrate improved performance with the attention-gate, on 1.5 Tesla spiral speech RT-MRI, compared to existing off-resonance correction methods.
* 8 pages, 4 figures, 1 table
Differential Flatness as a Sufficient Condition to Generate Optimal Trajectories in Real Time
Mar 04, 2021
As robotic systems increase in autonomy, there is a strong need to plan efficient trajectories in real-time. In this paper, we propose an approach to significantly reduce the complexity of solving optimal control problems both numerically and analytically. We exploit the property of differential flatness to show that it is always possible to decouple the forward dynamics of the system's state from the backward dynamics that emerge from the Euler-Lagrange equations. This coupling generally leads to instabilities in numerical approaches; thus, we expect our method to make traditional "shooting" methods a viable choice for optimal trajectory planning in differentially flat systems. To provide intuition for our approach, we also present an illustrative example of generating minimum-thrust trajectories for a quadrotor. Furthermore, we employ quaternions to track the quadrotor's orientation, which, unlike the Euler-angle representation, do not introduce additional singularities into the model.
Model-Based Reconstruction for Collimated Beam Ultrasound Systems
Feb 20, 2022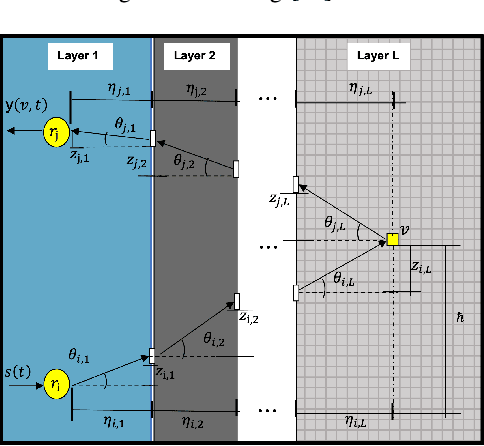
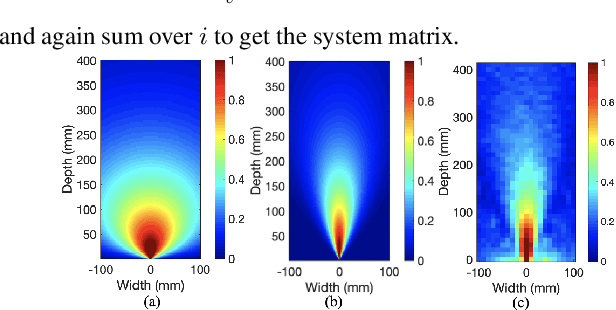
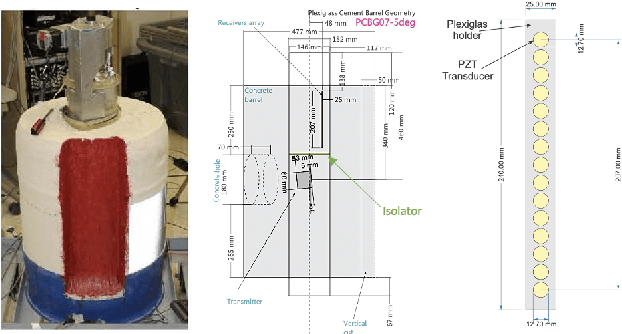
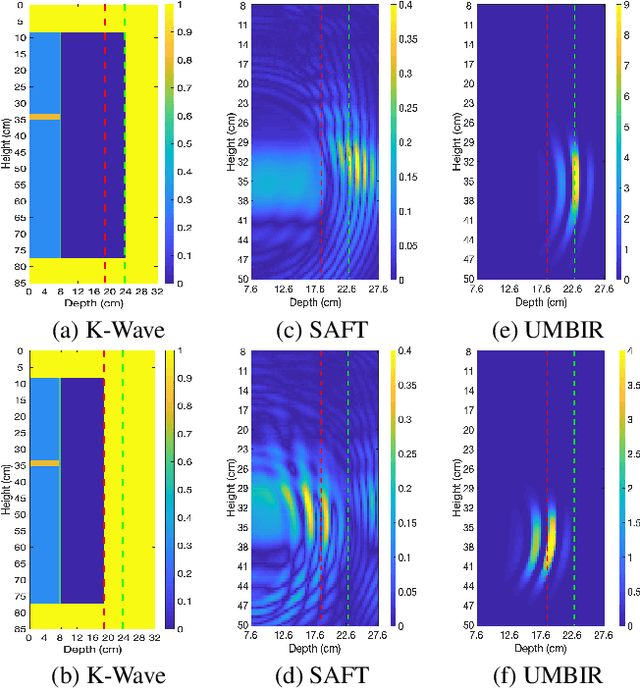
Collimated beam ultrasound systems are a novel technology for imaging inside multi-layered structures such as geothermal wells. Such systems include a transmitter and multiple receivers to capture reflected signals. Common algorithms for ultrasound reconstruction use delay-and-sum (DAS) approaches; these have low computational complexity but produce inaccurate images in the presence of complex structures and specialized geometries such as collimated beams. In this paper, we propose a multi-layer, ultrasonic, model-based iterative reconstruction algorithm designed for collimated beam systems. We introduce a physics-based forward model to accurately account for the propagation of a collimated ultrasonic beam in multi-layer media and describe an efficient implementation using binary search. We model direct arrival signals, detector noise, and a spatially varying image prior, then cast the reconstruction as a maximum a posteriori estimation problem. Using simulated and experimental data we obtain significantly fewer artifacts relative to DAS while running in near real time using commodity compute resources.
Semantic-Aware Collaborative Deep Reinforcement Learning Over Wireless Cellular Networks
Nov 23, 2021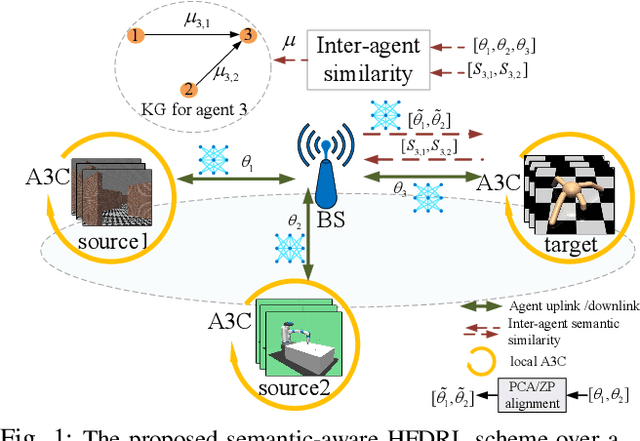
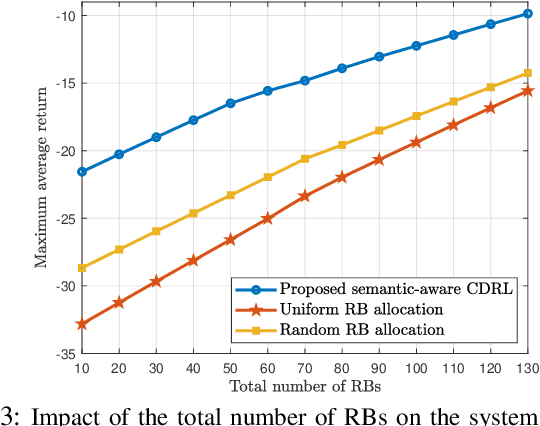
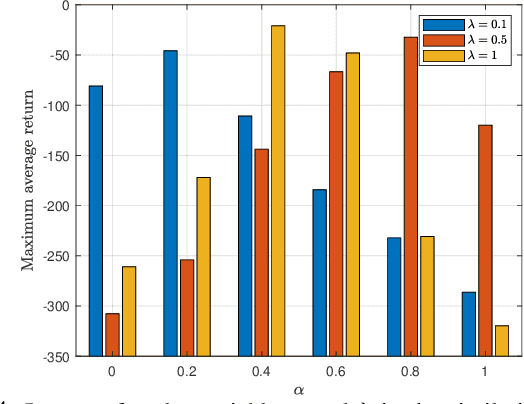
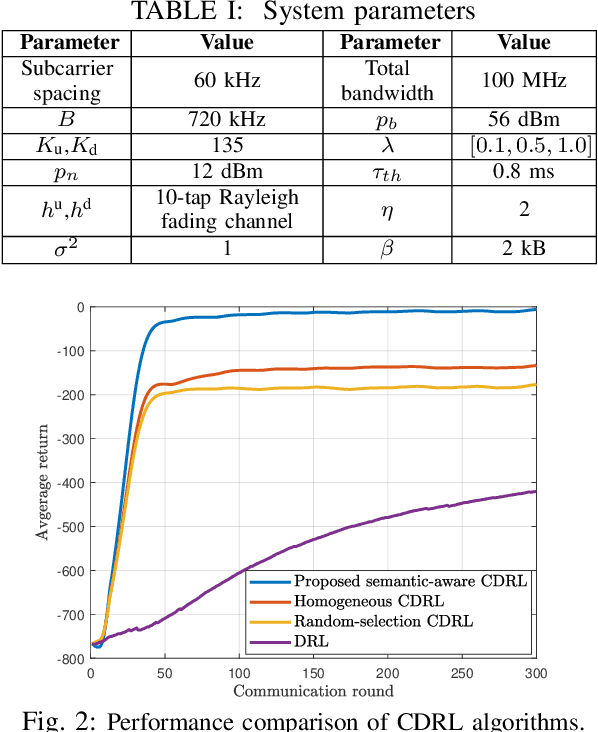
Collaborative deep reinforcement learning (CDRL) algorithms in which multiple agents can coordinate over a wireless network is a promising approach to enable future intelligent and autonomous systems that rely on real-time decision-making in complex dynamic environments. Nonetheless, in practical scenarios, CDRL faces many challenges due to the heterogeneity of agents and their learning tasks, different environments, time constraints of the learning, and resource limitations of wireless networks. To address these challenges, in this paper, a novel semantic-aware CDRL method is proposed to enable a group of heterogeneous untrained agents with semantically-linked DRL tasks to collaborate efficiently across a resource-constrained wireless cellular network. To this end, a new heterogeneous federated DRL (HFDRL) algorithm is proposed to select the best subset of semantically relevant DRL agents for collaboration. The proposed approach then jointly optimizes the training loss and wireless bandwidth allocation for the cooperating selected agents in order to train each agent within the time limit of its real-time task. Simulation results show the superior performance of the proposed algorithm compared to state-of-the-art baselines.
All You Need is LUV: Unsupervised Collection of Labeled Images using Invisible UV Fluorescent Indicators
Mar 13, 2022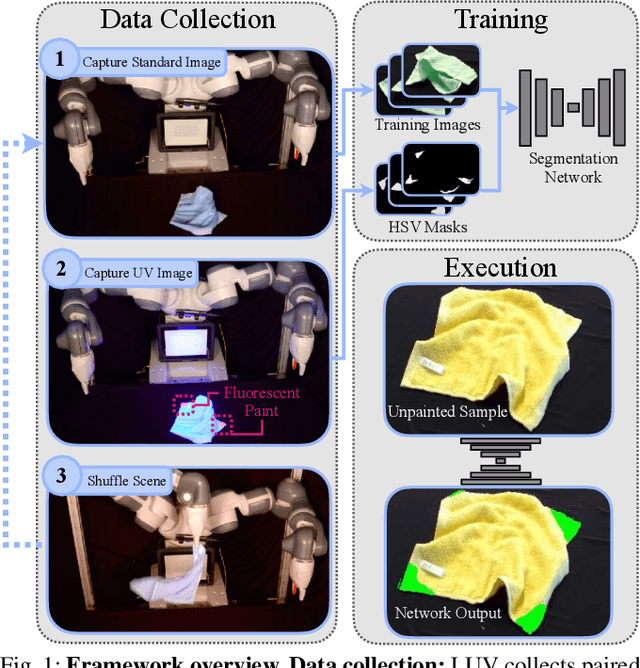



Large-scale semantic image annotation is a significant challenge for learning-based perception systems in robotics. Current approaches often rely on human labelers, which can be expensive, or simulation data, which can visually or physically differ from real data. This paper proposes Labels from UltraViolet (LUV), a novel framework that enables rapid, labeled data collection in real manipulation environments without human labeling. LUV uses transparent, ultraviolet-fluorescent paint with programmable ultraviolet LEDs to collect paired images of a scene in standard lighting and UV lighting to autonomously extract segmentation masks and keypoints via color segmentation. We apply LUV to a suite of diverse robot perception tasks to evaluate its labeling quality, flexibility, and data collection rate. Results suggest that LUV is 180-2500 times faster than a human labeler across the tasks. We show that LUV provides labels consistent with human annotations on unpainted test images. The networks trained on these labels are used to smooth and fold crumpled towels with 83% success rate and achieve 1.7mm position error with respect to human labels on a surgical needle pose estimation task. The low cost of LUV makes it ideal as a lightweight replacement for human labeling systems, with the one-time setup costs at $300 equivalent to the cost of collecting around 200 semantic segmentation labels on Amazon Mechanical Turk. Code, datasets, visualizations, and supplementary material can be found at https://sites.google.com/berkeley.edu/luv