 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Typography-MNIST (TMNIST): an MNIST-Style Image Dataset to Categorize Glyphs and Font-Styles
Feb 12, 2022
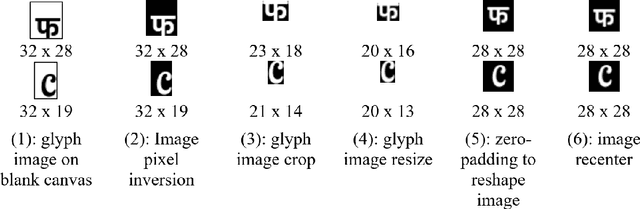
We present Typography-MNIST (TMNIST), a dataset comprising of 565,292 MNIST-style grayscale images representing 1,812 unique glyphs in varied styles of 1,355 Google-fonts. The glyph-list contains common characters from over 150 of the modern and historical language scripts with symbol sets, and each font-style represents varying subsets of the total unique glyphs. The dataset has been developed as part of the CognitiveType project which aims to develop eye-tracking tools for real-time mapping of type to cognition and to create computational tools that allow for the easy design of typefaces with cognitive properties such as readability. The dataset and scripts to generate MNIST-style images for glyphs in different font styles are freely available at https://github.com/aiskunks/CognitiveType.
Real-time object detection method based on improved YOLOv4-tiny
Nov 09, 2020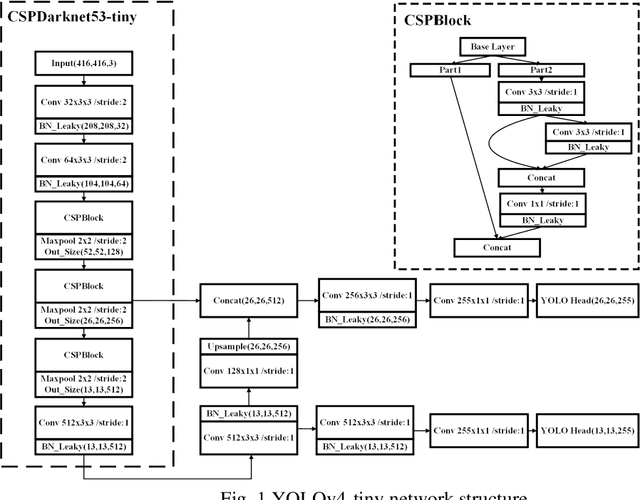
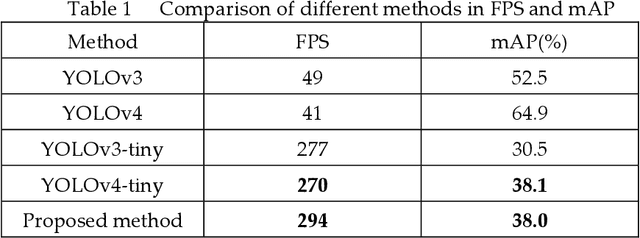
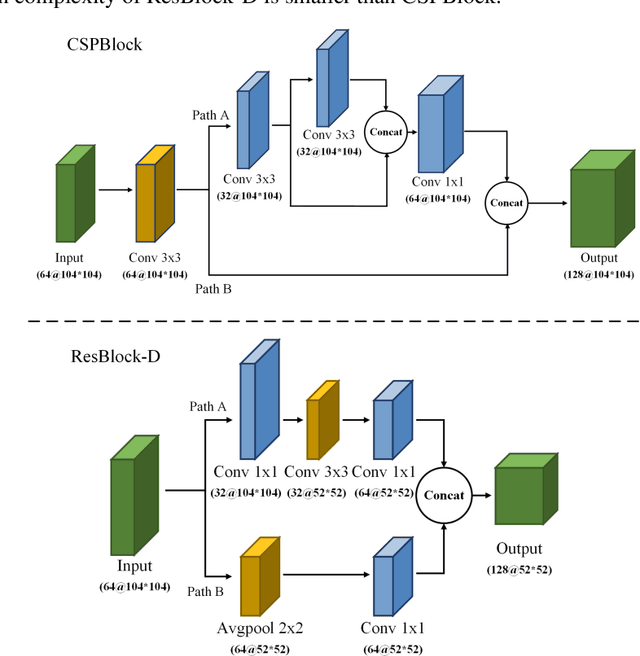
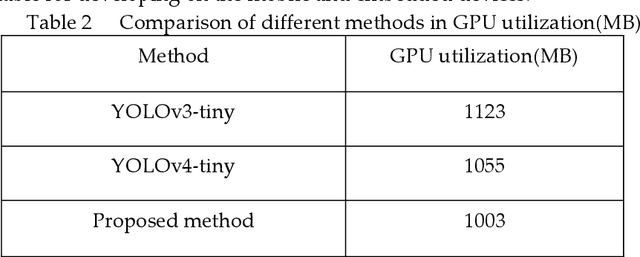
The "You only look once v4"(YOLOv4) is one type of object detection methods in deep learning. YOLOv4-tiny is proposed based on YOLOv4 to simple the network structure and reduce parameters, which makes it be suitable for developing on the mobile and embedded devices. To improve the real-time of object detection, a fast object detection method is proposed based on YOLOv4-tiny. It firstly uses two ResBlock-D modules in ResNet-D network instead of two CSPBlock modules in Yolov4-tiny, which reduces the computation complexity. Secondly, it designs an auxiliary residual network block to extract more feature information of object to reduce detection error. In the design of auxiliary network, two consecutive 3x3 convolutions are used to obtain 5x5 receptive fields to extract global features, and channel attention and spatial attention are also used to extract more effective information. In the end, it merges the auxiliary network and backbone network to construct the whole network structure of improved YOLOv4-tiny. Simulation results show that the proposed method has faster object detection than YOLOv4-tiny and YOLOv3-tiny, and almost the same mean value of average precision as the YOLOv4-tiny. It is more suitable for real-time object detection.
Temporal-MPI: Enabling Multi-Plane Images for Dynamic Scene Modelling via Temporal Basis Learning
Nov 20, 2021
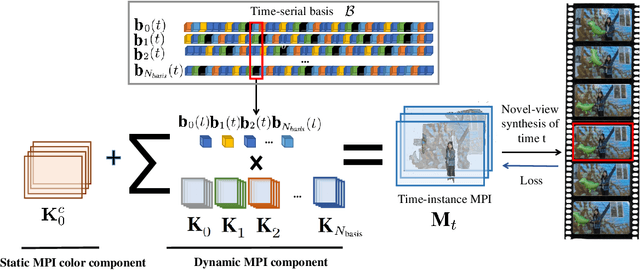

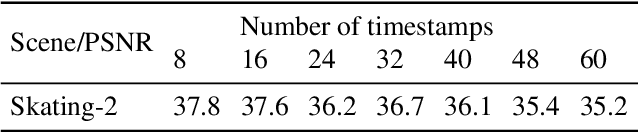
Novel view synthesis of static scenes has achieved remarkable advancements in producing photo-realistic results. However, key challenges remain for immersive rendering for dynamic contents. For example, one of the seminal image-based rendering frameworks, the multi-plane image (MPI) produces high novel-view synthesis quality for static scenes but faces difficulty in modeling dynamic parts. In addition, modeling dynamic variations through MPI may require huge storage space and long inference time, which hinders its application in real-time scenarios. In this paper, we propose a novel Temporal-MPI representation which is able to encode the rich 3D and dynamic variation information throughout the entire video as compact temporal basis. Novel-views at arbitrary time-instance will be able to be rendered real-time with high visual quality due to the highly compact and expressive latent basis and the coefficients jointly learned. We show that given comparable memory consumption, our proposed Temporal-MPI framework is able to generate a time-instance MPI with only 0.002 seconds, which is up to 3000 times faster, with 3dB higher average view-synthesis PSNR as compared with other state-of-the-art dynamic scene modelling frameworks.
Unsupervised Pre-Training on Patient Population Graphs for Patient-Level Predictions
Mar 23, 2022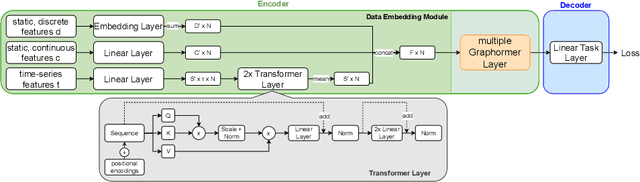

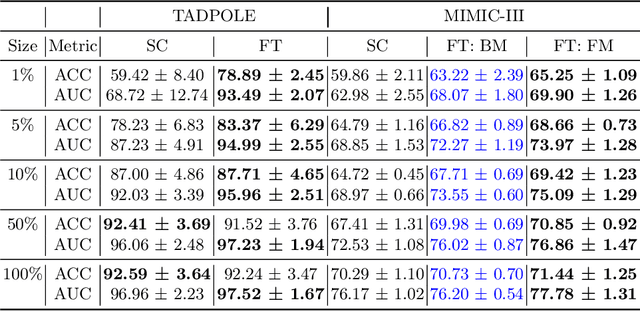
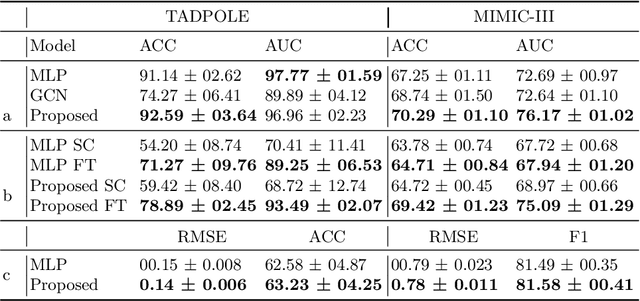
Pre-training has shown success in different areas of machine learning, such as Computer Vision (CV), Natural Language Processing (NLP) and medical imaging. However, it has not been fully explored for clinical data analysis. Even though an immense amount of Electronic Health Record (EHR) data is recorded, data and labels can be scarce if the data is collected in small hospitals or deals with rare diseases. In such scenarios, pre-training on a larger set of EHR data could improve the model performance. In this paper, we apply unsupervised pre-training to heterogeneous, multi-modal EHR data for patient outcome prediction. To model this data, we leverage graph deep learning over population graphs. We first design a network architecture based on graph transformer designed to handle various input feature types occurring in EHR data, like continuous, discrete, and time-series features, allowing better multi-modal data fusion. Further, we design pre-training methods based on masked imputation to pre-train our network before fine-tuning on different end tasks. Pre-training is done in a fully unsupervised fashion, which lays the groundwork for pre-training on large public datasets with different tasks and similar modalities in the future. We test our method on two medical datasets of patient records, TADPOLE and MIMIC-III, including imaging and non-imaging features and different prediction tasks. We find that our proposed graph based pre-training method helps in modeling the data at a population level and further improves performance on the fine tuning tasks in terms of AUC on average by 4.15% for MIMIC and 7.64% for TADPOLE.
Real Time Face Recognition Using Convoluted Neural Networks
Oct 09, 2020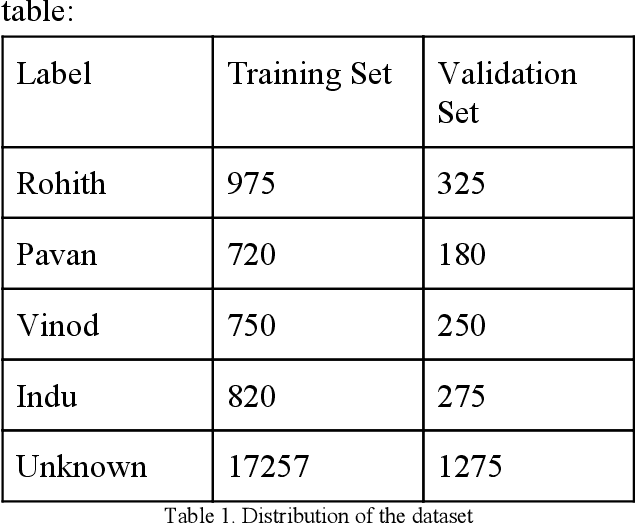
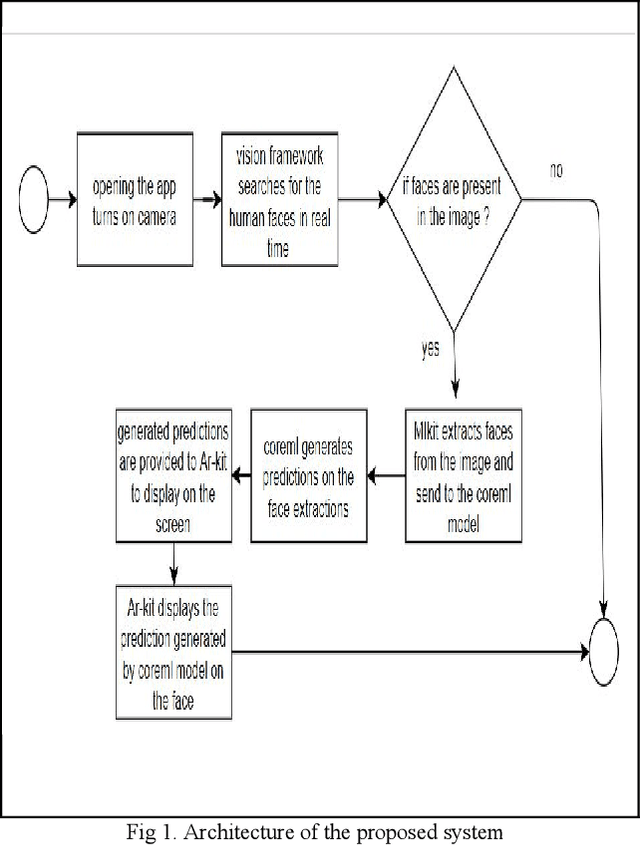
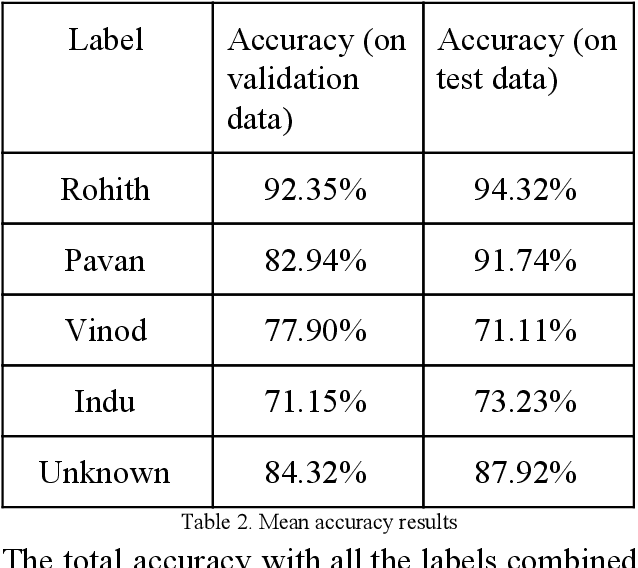

Face Recognition is one of the process of identifying people using their face, it has various applications like authentication systems, surveillance systems and law enforcement. Convolutional Neural Networks are proved to be best for facial recognition. Detecting faces using core-ml api and processing the extracted face through a coreML model, which is trained to recognize specific persons. The creation of dataset is done by converting face videos of the persons to be recognized into Hundreds of images of person, which is further used for training and validation of the model to provide accurate real-time results.
Software Engineering Event Modeling using Relative Time in Temporal Knowledge Graphs
Jul 02, 2020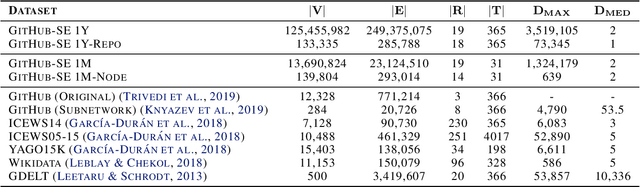
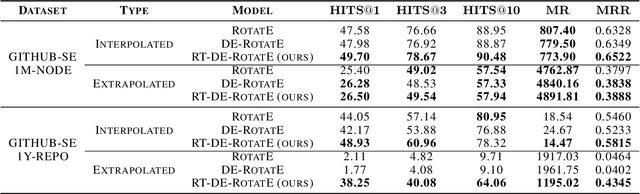
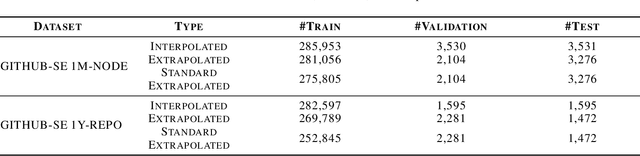
We present a multi-relational temporal Knowledge Graph based on the daily interactions between artifacts in GitHub, one of the largest social coding platforms. Such representation enables posing many user-activity and project management questions as link prediction and time queries over the knowledge graph. In particular, we introduce two new datasets for i) interpolated time-conditioned link prediction and ii) extrapolated time-conditioned link/time prediction queries, each with distinguished properties. Our experiments on these datasets highlight the potential of adapting knowledge graphs to answer broad software engineering questions. Meanwhile, it also reveals the unsatisfactory performance of existing temporal models on extrapolated queries and time prediction queries in general. To overcome these shortcomings, we introduce an extension to current temporal models using relative temporal information with regards to past events.
CodeReviewer: Pre-Training for Automating Code Review Activities
Mar 17, 2022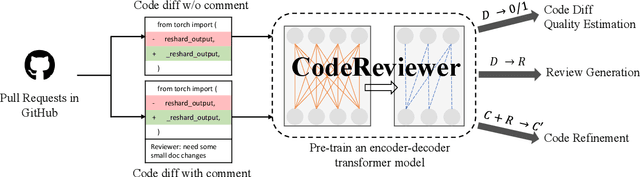

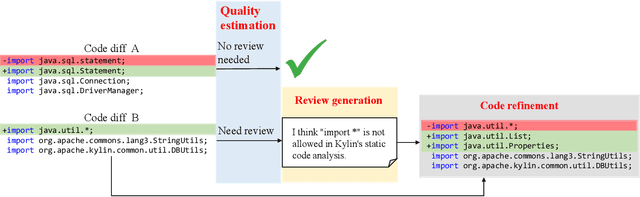
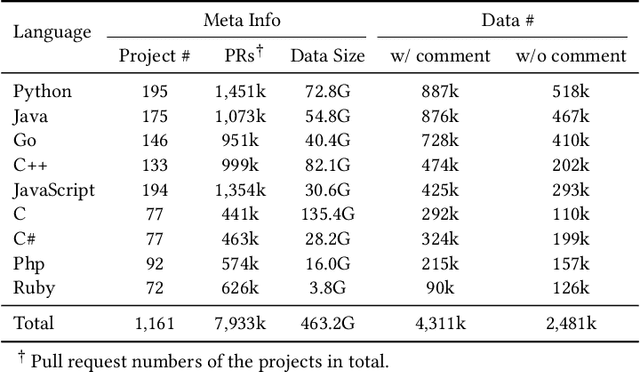
Code review is an essential part to software development lifecycle since it aims at guaranteeing the quality of codes. Modern code review activities necessitate developers viewing, understanding and even running the programs to assess logic, functionality, latency, style and other factors. It turns out that developers have to spend far too much time reviewing the code of their peers. Accordingly, it is in significant demand to automate the code review process. In this research, we focus on utilizing pre-training techniques for the tasks in the code review scenario. We collect a large-scale dataset of real world code changes and code reviews from open-source projects in nine of the most popular programming languages. To better understand code diffs and reviews, we propose CodeReviewer, a pre-trained model that utilizes four pre-training tasks tailored specifically for the code review senario. To evaluate our model, we focus on three key tasks related to code review activities, including code change quality estimation, review comment generation and code refinement. Furthermore, we establish a high-quality benchmark dataset based on our collected data for these three tasks and conduct comprehensive experiments on it. The experimental results demonstrate that our model outperforms the previous state-of-the-art pre-training approaches in all tasks. Further analysis show that our proposed pre-training tasks and the multilingual pre-training dataset benefit the model on the understanding of code changes and reviews.
MAMRL: Exploiting Multi-agent Meta Reinforcement Learning in WAN Traffic Engineering
Nov 30, 2021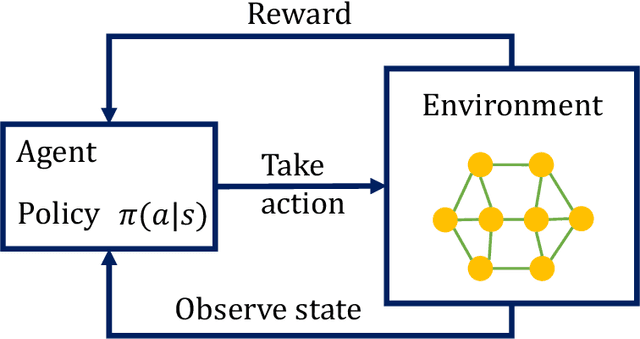

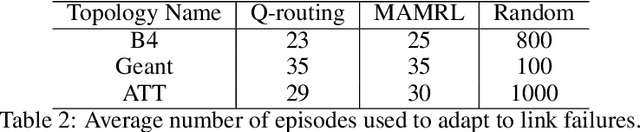
Traffic optimization challenges, such as load balancing, flow scheduling, and improving packet delivery time, are difficult online decision-making problems in wide area networks (WAN). Complex heuristics are needed for instance to find optimal paths that improve packet delivery time and minimize interruptions which may be caused by link failures or congestion. The recent success of reinforcement learning (RL) algorithms can provide useful solutions to build better robust systems that learn from experience in model-free settings. In this work, we consider a path optimization problem, specifically for packet routing, in large complex networks. We develop and evaluate a model-free approach, applying multi-agent meta reinforcement learning (MAMRL) that can determine the next-hop of each packet to get it delivered to its destination with minimum time overall. Specifically, we propose to leverage and compare deep policy optimization RL algorithms for enabling distributed model-free control in communication networks and present a novel meta-learning-based framework, MAMRL, for enabling quick adaptation to topology changes. To evaluate the proposed framework, we simulate with various WAN topologies. Our extensive packet-level simulation results show that compared to classical shortest path and traditional reinforcement learning approaches, MAMRL significantly reduces the average packet delivery time even when network demand increases; and compared to a non-meta deep policy optimization algorithm, our results show the reduction of packet loss in much fewer episodes when link failures occur while offering comparable average packet delivery time.
MFA: TDNN with Multi-scale Frequency-channel Attention for Text-independent Speaker Verification with Short Utterances
Feb 15, 2022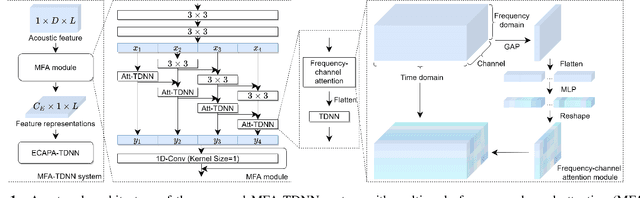
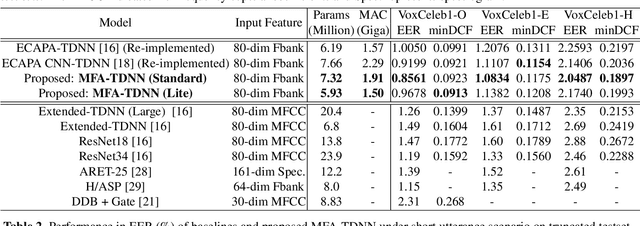
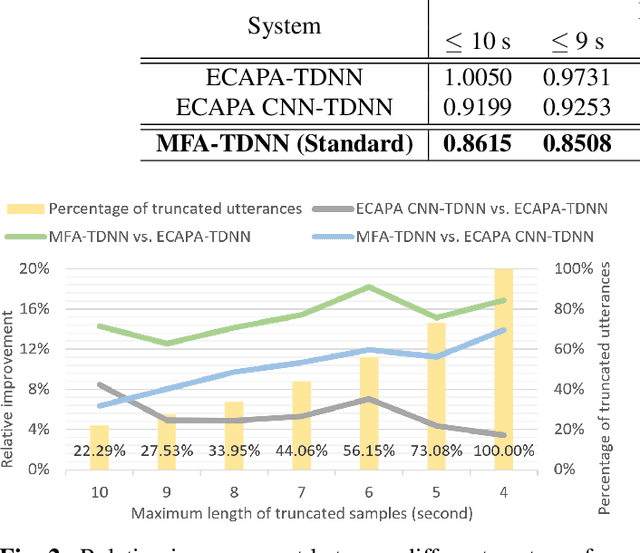
The time delay neural network (TDNN) represents one of the state-of-the-art of neural solutions to text-independent speaker verification. However, they require a large number of filters to capture the speaker characteristics at any local frequency region. In addition, the performance of such systems may degrade under short utterance scenarios. To address these issues, we propose a multi-scale frequency-channel attention (MFA), where we characterize speakers at different scales through a novel dual-path design which consists of a convolutional neural network and TDNN. We evaluate the proposed MFA on the VoxCeleb database and observe that the proposed framework with MFA can achieve state-of-the-art performance while reducing parameters and computation complexity. Further, the MFA mechanism is found to be effective for speaker verification with short test utterances.
Joint Learning of Salient Object Detection, Depth Estimation and Contour Extraction
Mar 09, 2022



Benefiting from color independence, illumination invariance and location discrimination attributed by the depth map, it can provide important supplemental information for extracting salient objects in complex environments. However, high-quality depth sensors are expensive and can not be widely applied. While general depth sensors produce the noisy and sparse depth information, which brings the depth-based networks with irreversible interference. In this paper, we propose a novel multi-task and multi-modal filtered transformer (MMFT) network for RGB-D salient object detection (SOD). Specifically, we unify three complementary tasks: depth estimation, salient object detection and contour estimation. The multi-task mechanism promotes the model to learn the task-aware features from the auxiliary tasks. In this way, the depth information can be completed and purified. Moreover, we introduce a multi-modal filtered transformer (MFT) module, which equips with three modality-specific filters to generate the transformer-enhanced feature for each modality. The proposed model works in a depth-free style during the testing phase. Experiments show that it not only significantly surpasses the depth-based RGB-D SOD methods on multiple datasets, but also precisely predicts a high-quality depth map and salient contour at the same time. And, the resulted depth map can help existing RGB-D SOD methods obtain significant performance gain.