 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Understanding the input-output relationship of neural networks in the time series forecasting radon levels at Canfranc Underground Laboratory
Feb 05, 2021
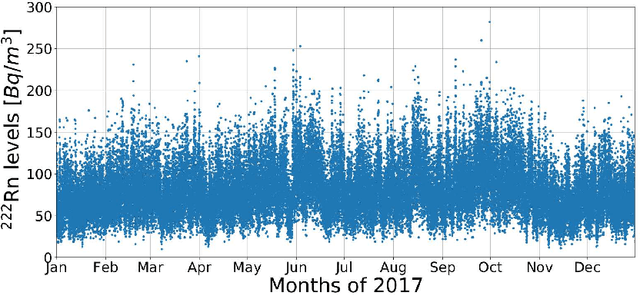
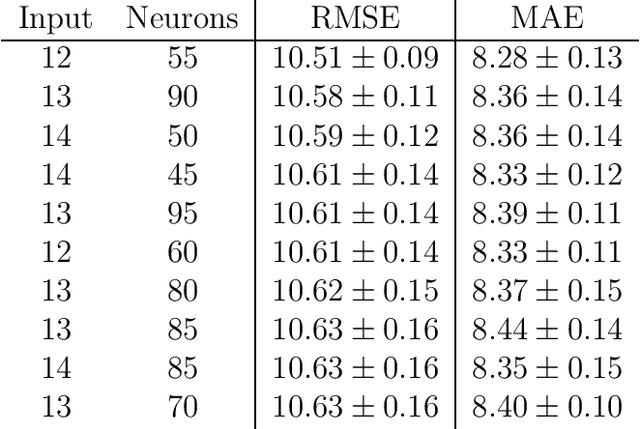
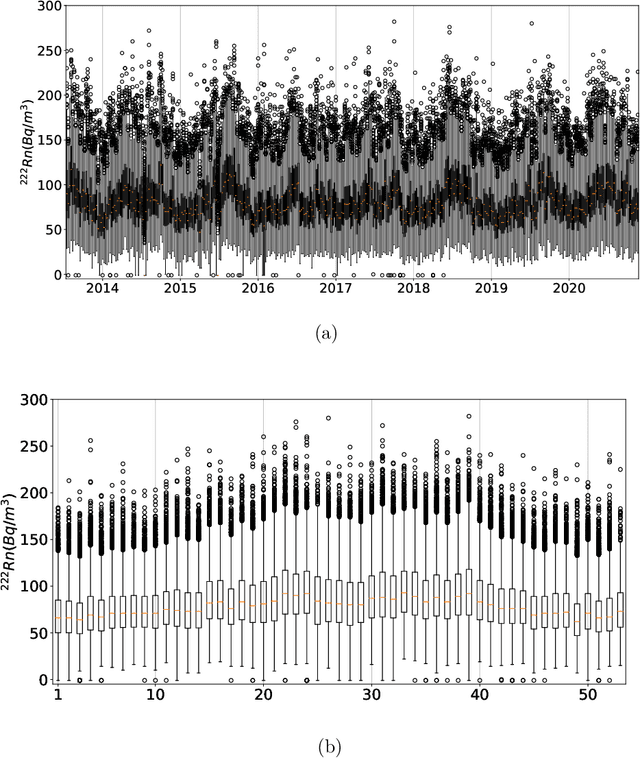
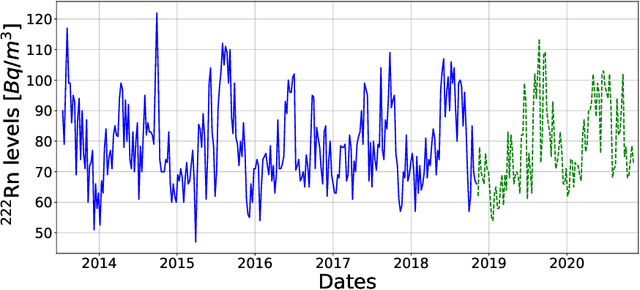
Underground physics experiments such as dark matter direct detection need to keep control of the background contribution. Hosting these experiments in underground facilities helps to minimize certain background sources such as the cosmic rays. One of the largest remaining background sources is the radon emanated from the rocks enclosing the research facility. The radon particles could be deposited inside the detectors when they are opened to perform the maintenance operations. Therefore, forecasting the radon levels is a crucial task in an attempt to schedule the maintenance operations when radon level is minimum. In the past, deep learning models have been implemented to forecast the radon time series at the Canfranc Underground Laboratory (LSC), in Spain, with satisfactory results. When forecasting time series, the past values of the time series are taken as input variables. The present work focuses on understanding the relative contribution of these input variables to the predictions generated by neural networks. The results allow us to understand how the predictions of the time series depend on the input variables. These results may be used to build better predictors in the future.
Edge Network-Assisted Real-Time Object Detection Framework for Autonomous Driving
Aug 17, 2020
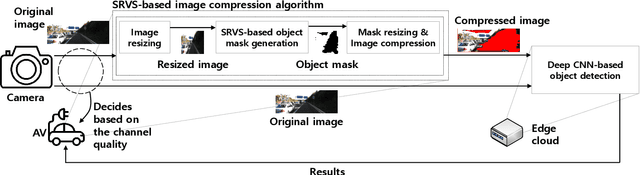
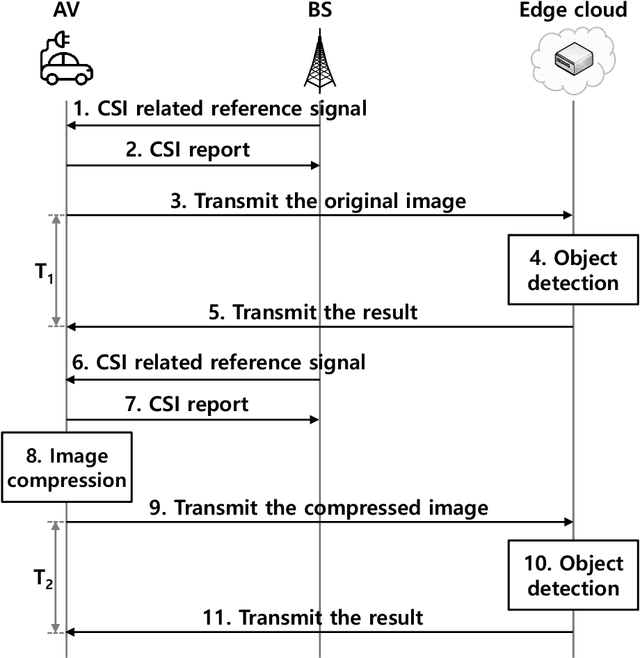
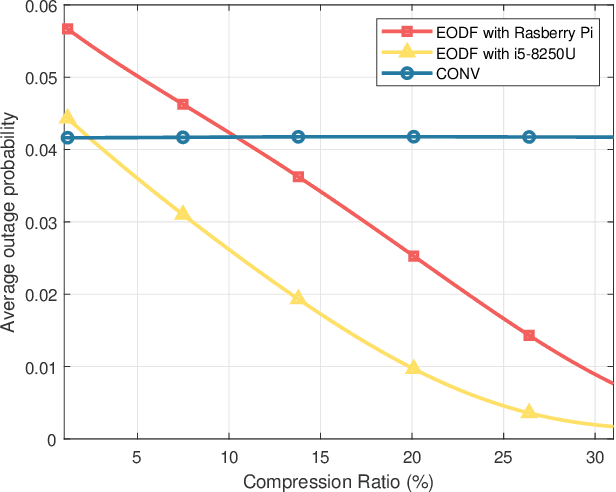
Autonomous vehicles (AVs) can achieve the desired results within a short duration by offloading tasks even requiring high computational power (e.g., object detection (OD)) to edge clouds. However, although edge clouds are exploited, real-time OD cannot always be guaranteed due to dynamic channel quality. To mitigate this problem, we propose an edge network-assisted real-time OD framework~(EODF). In an EODF, AVs extract the region of interests~(RoIs) of the captured image when the channel quality is not sufficiently good for supporting real-time OD. Then, AVs compress the image data on the basis of the RoIs and transmit the compressed one to the edge cloud. In so doing, real-time OD can be achieved owing to the reduced transmission latency. To verify the feasibility of our framework, we evaluate the probability that the results of OD are not received within the inter-frame duration (i.e., outage probability) and their accuracy. From the evaluation, we demonstrate that the proposed EODF provides the results to AVs in real-time and achieves satisfactory accuracy.
Space-Time Crop & Attend: Improving Cross-modal Video Representation Learning
Mar 18, 2021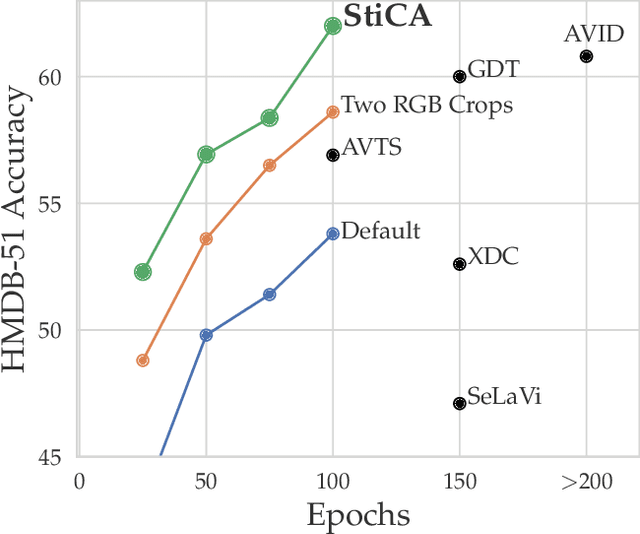
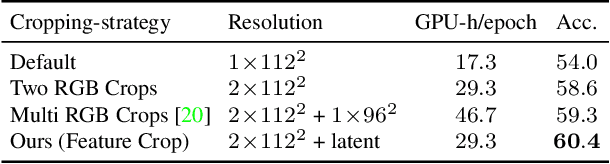
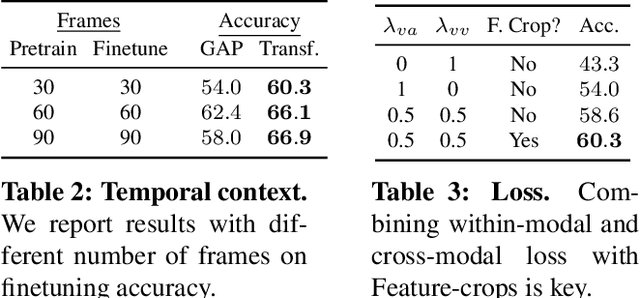
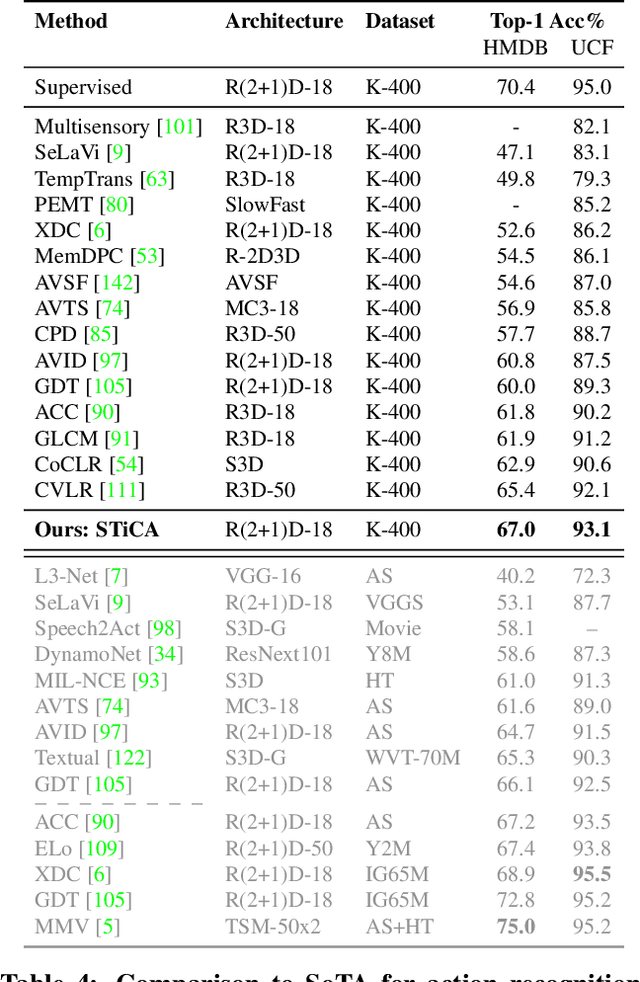
The quality of the image representations obtained from self-supervised learning depends strongly on the type of data augmentations used in the learning formulation. Recent papers have ported these methods from still images to videos and found that leveraging both audio and video signals yields strong gains; however, they did not find that spatial augmentations such as cropping, which are very important for still images, work as well for videos. In this paper, we improve these formulations in two ways unique to the spatio-temporal aspect of videos. First, for space, we show that spatial augmentations such as cropping do work well for videos too, but that previous implementations, due to the high processing and memory cost, could not do this at a scale sufficient for it to work well. To address this issue, we first introduce Feature Crop, a method to simulate such augmentations much more efficiently directly in feature space. Second, we show that as opposed to naive average pooling, the use of transformer-based attention improves performance significantly, and is well suited for processing feature crops. Combining both of our discoveries into a new method, Space-time Crop & Attend (STiCA) we achieve state-of-the-art performance across multiple video-representation learning benchmarks. In particular, we achieve new state-of-the-art accuracies of 67.0% on HMDB-51 and 93.1% on UCF-101 when pre-training on Kinetics-400.
End-to-End Learning to Grasp from Object Point Clouds
Mar 10, 2022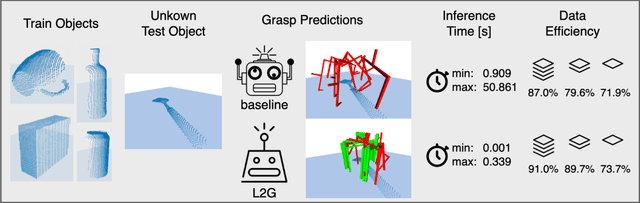
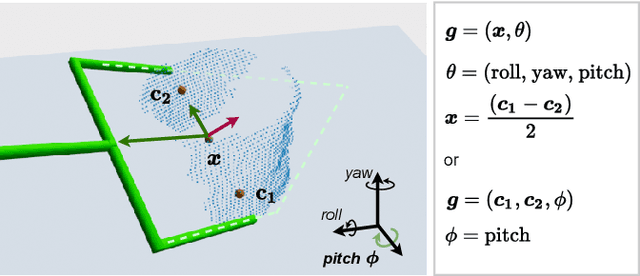
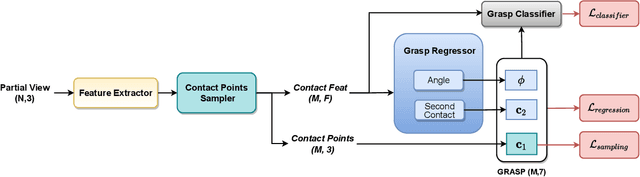
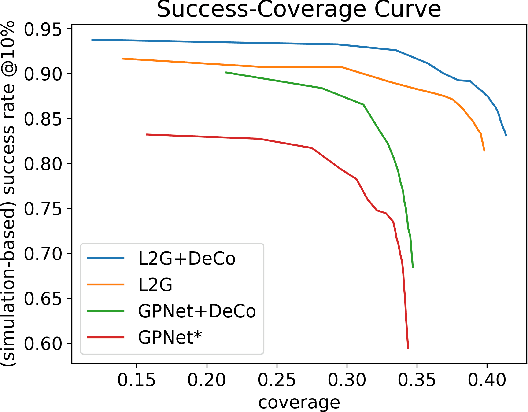
The ability to grasp objects is an essential skill that enables many robotic manipulation tasks. Recent works have studied point cloud-based methods for object grasping by starting from simulated datasets and have shown promising performance in real-world scenarios. Nevertheless, many of them still strongly rely on ad-hoc geometric heuristics to generate grasp candidates, which fail to generalize to objects with significantly different shapes with respect to those observed during training. Moreover, these methods are generally inefficient with respect to the number of training samples and the time needed during deployment. In this paper, we propose an end-to-end learning solution to generate 6-DOF parallel-jaw grasps starting from the partial view of the object. Our Learning to Grasp (L2G) method takes as input object point clouds and is guided by a principled multi-task optimization objective that generates a diverse set of grasps combining contact point sampling, grasp regression, and grasp evaluation. With a thorough experimental analysis, we show the effectiveness of the proposed method as well as its robustness and generalization abilities.
Geodesic Quantum Walks
Feb 22, 2022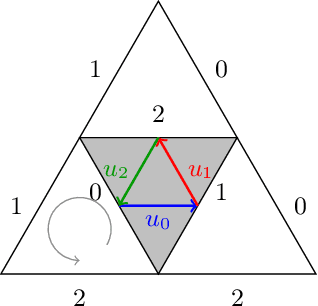
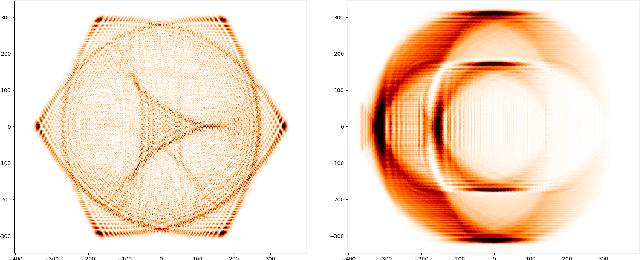
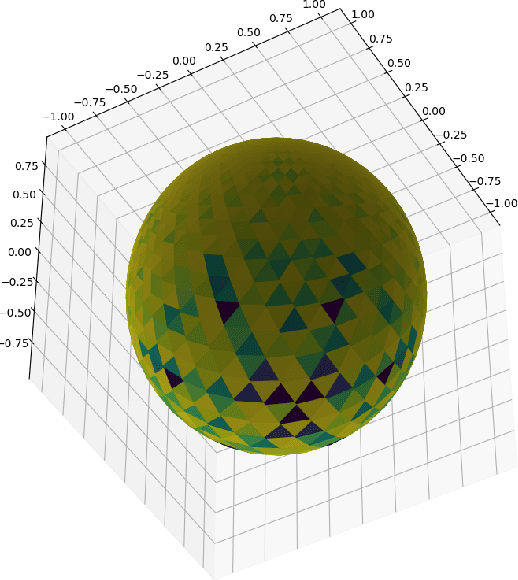
We propose a new family of discrete-spacetime quantum walks capable to propagate on any arbitrary triangulations. Moreover we also extend and generalize the duality principle introduced by one of the authors, linking continuous local deformations of a given triangulation and the inhomogeneity of the local unitaries that guide the quantum walker. We proved that in the formal continuous limit, in both space and time, this new family of quantum walks converges to the (1+2)D massless Dirac equation on curved manifolds. We believe that this result has relevance in both modelling/simulating quantum transport on discrete curved structures, such as fullerene molecules or dynamical causal triangulation, and in addressing fast and efficient optimization problems in the context of the curved space optimization methods.
Change Detection of Markov Kernels with Unknown Post Change Kernel using Maximum Mean Discrepancy
Jan 27, 2022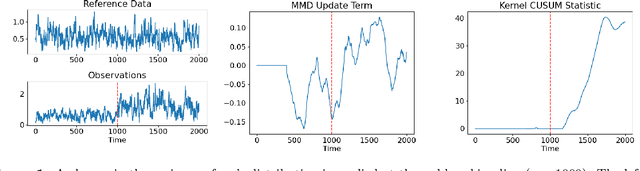
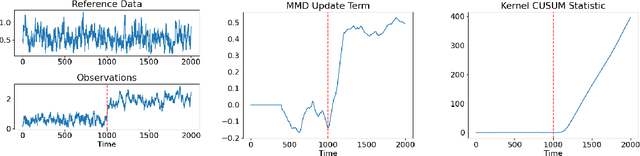
In this paper, we develop a new change detection algorithm for detecting a change in the Markov kernel over a metric space in which the post-change kernel is unknown. Under the assumption that the pre- and post-change Markov kernel is geometrically ergodic, we derive an upper bound on the mean delay and a lower bound on the mean time between false alarms.
Probabilistic Data Association for Semantic SLAM at Scale
Feb 25, 2022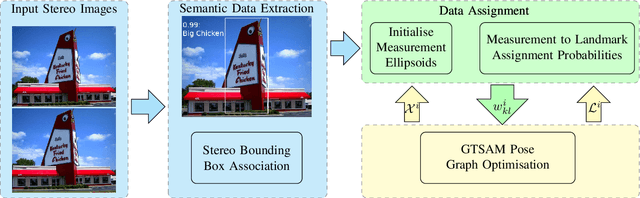
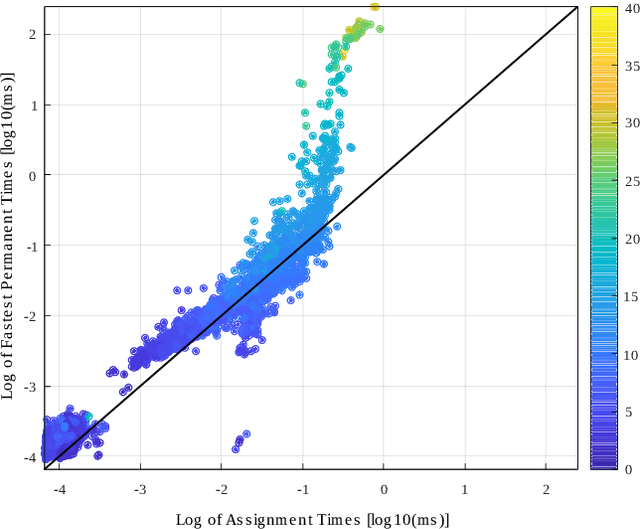
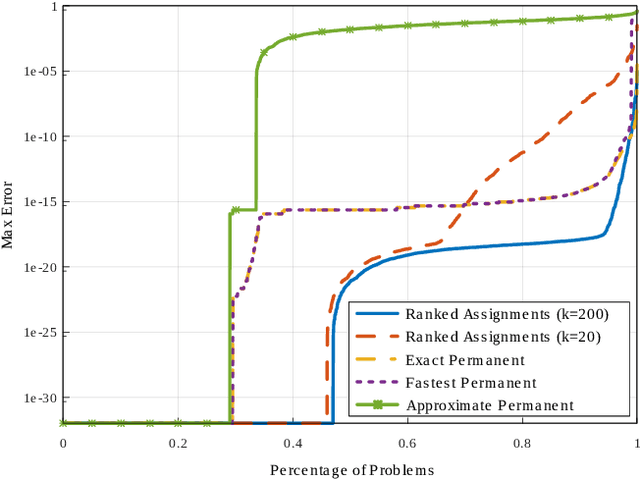
With advances in image processing and machine learning, it is now feasible to incorporate semantic information into the problem of simultaneous localisation and mapping (SLAM). Previously, SLAM was carried out using lower level geometric features (points, lines, and planes) which are often view-point dependent and error prone in visually repetitive environments. Semantic information can improve the ability to recognise previously visited locations, as well as maintain sparser maps for long term SLAM applications. However, SLAM in repetitive environments has the critical problem of assigning measurements to the landmarks which generated them. In this paper, we use k-best assignment enumeration to compute marginal assignment probabilities for each measurement landmark pair, in real time. We present numerical studies on the KITTI dataset to demonstrate the effectiveness and speed of the proposed framework.
Near-optimality for infinite-horizon restless bandits with many arms
Mar 29, 2022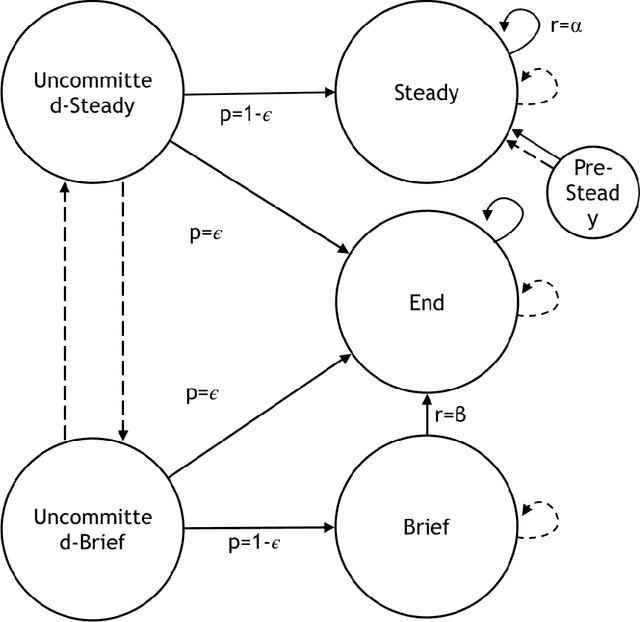
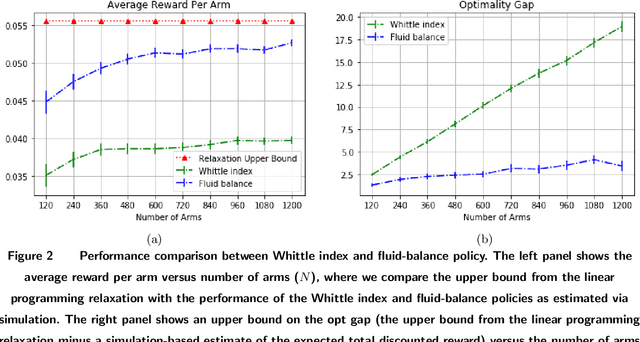
Restless bandits are an important class of problems with applications in recommender systems, active learning, revenue management and other areas. We consider infinite-horizon discounted restless bandits with many arms where a fixed proportion of arms may be pulled in each period and where arms share a finite state space. Although an average-case-optimal policy can be computed via stochastic dynamic programming, the computation required grows exponentially with the number of arms $N$. Thus, it is important to find scalable policies that can be computed efficiently for large $N$ and that are near optimal in this regime, in the sense that the optimality gap (i.e. the loss of expected performance against an optimal policy) per arm vanishes for large $N$. However, the most popular approach, the Whittle index, requires a hard-to-verify indexability condition to be well-defined and another hard-to-verify condition to guarantee a $o(N)$ optimality gap. We present a method resolving these difficulties. By replacing a global Lagrange multiplier used by the Whittle index with a sequence of Lagrangian multipliers, one per time period up to a finite truncation point, we derive a class of policies, called fluid-balance policies, that have a $O(\sqrt{N})$ optimality gap. Unlike the Whittle index, fluid-balance policies do not require indexability to be well-defined and their $O(\sqrt{N})$ optimality gap bound holds universally without sufficient conditions. We also demonstrate empirically that fluid-balance policies provide state-of-the-art performance on specific problems.
Impact of Information Flow Topology on Safety of Tightly-coupled Connected and Automated Vehicle Platoons Utilizing Stochastic Control
Mar 29, 2022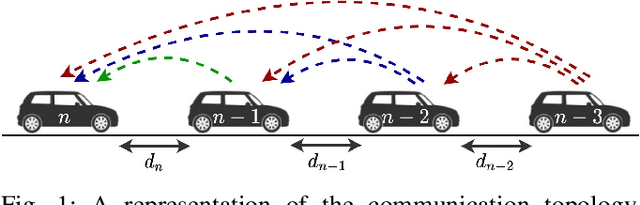
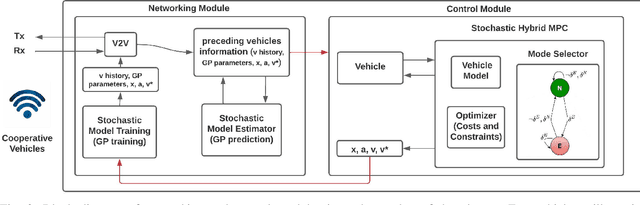
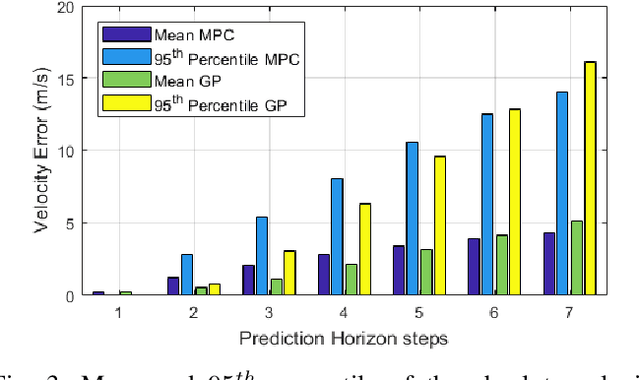
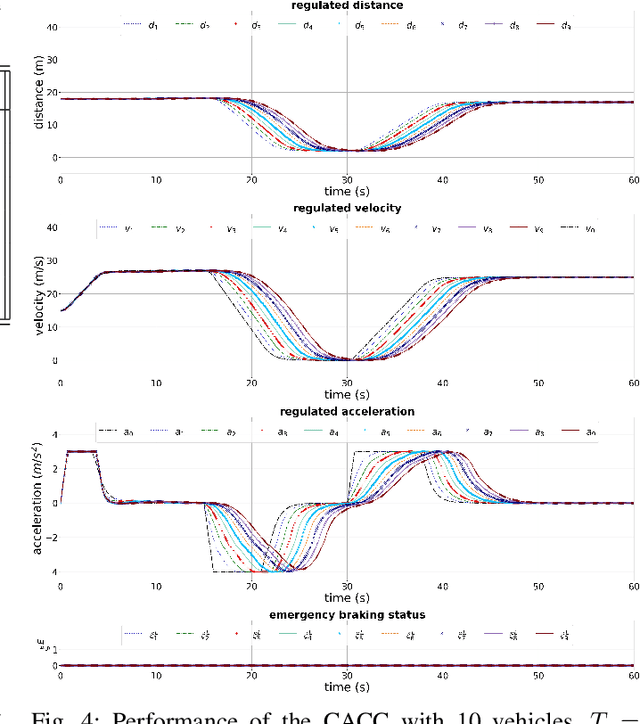
Cooperative driving, enabled by Vehicle-to-Everything (V2X) communication, is expected to significantly contribute to the transportation system's safety and efficiency. Cooperative Adaptive Cruise Control (CACC), a major cooperative driving application, has been the subject of many studies in recent years. The primary motivation behind using CACC is to reduce traffic congestion and improve traffic flow, traffic throughput, and highway capacity. Since the information flow between cooperative vehicles can significantly affect the dynamics of a platoon, the design and performance of control components are tightly dependent on the communication component performance. In addition, the choice of Information Flow Topology (IFT) can affect certain platoons properties such as stability and scalability. Although cooperative vehicles perception can be expanded to multiple predecessors information by using V2X communication, the communication technologies still suffer from scalability issues. Therefore, cooperative vehicles are required to predict each other's behavior to compensate for the effects of non-ideal communication. The notion of Model-Based Communication (MBC) was proposed to enhance cooperative vehicles perception under non-ideal communication by introducing a new flexible content structure for broadcasting joint vehicles dynamic/drivers behavior models. By utilizing a non-parametric (Bayesian) modeling scheme, i.e., Gaussian Process Regression (GPR), and the MBC concept, this paper develops a discrete hybrid stochastic model predictive control approach and examines the impact of communication losses and different information flow topologies on the performance and safety of the platoon. The results demonstrate an improvement in response time and safety using more vehicles information, validating the potential of cooperation to attenuate disturbances and improve traffic flow and safety.
FisherMatch: Semi-Supervised Rotation Regression via Entropy-based Filtering
Mar 29, 2022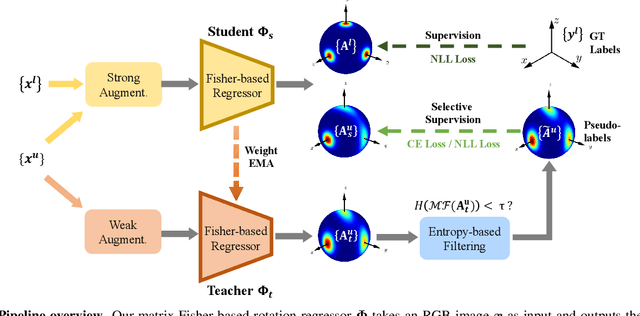
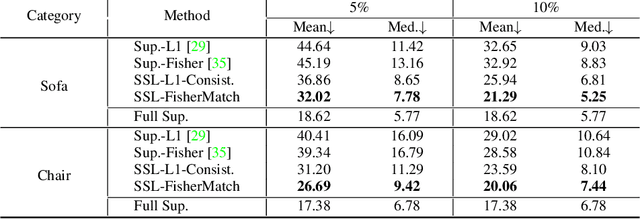
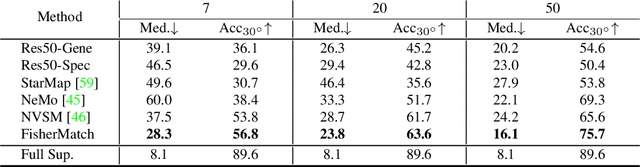
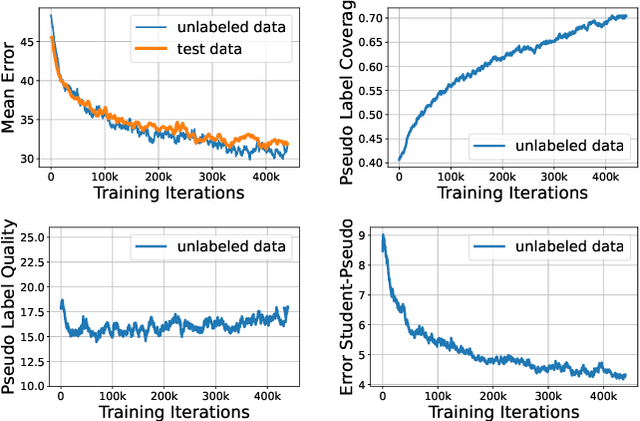
Estimating the 3DoF rotation from a single RGB image is an important yet challenging problem. Recent works achieve good performance relying on a large amount of expensive-to-obtain labeled data. To reduce the amount of supervision, we for the first time propose a general framework, FisherMatch, for semi-supervised rotation regression, without assuming any domain-specific knowledge or paired data. Inspired by the popular semi-supervised approach, FixMatch, we propose to leverage pseudo label filtering to facilitate the information flow from labeled data to unlabeled data in a teacher-student mutual learning framework. However, incorporating the pseudo label filtering mechanism into semi-supervised rotation regression is highly non-trivial, mainly due to the lack of a reliable confidence measure for rotation prediction. In this work, we propose to leverage matrix Fisher distribution to build a probabilistic model of rotation and devise a matrix Fisher-based regressor for jointly predicting rotation along with its prediction uncertainty. We then propose to use the entropy of the predicted distribution as a confidence measure, which enables us to perform pseudo label filtering for rotation regression. For supervising such distribution-like pseudo labels, we further investigate the problem of how to enforce loss between two matrix Fisher distributions. Our extensive experiments show that our method can work well even under very low labeled data ratios on different benchmarks, achieving significant and consistent performance improvement over supervised learning and other semi-supervised learning baselines. Our project page is at https://yd-yin.github.io/FisherMatch.