 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Safe Hierarchical Model Predictive Control and Planning for Autonomous Systems
Mar 27, 2022
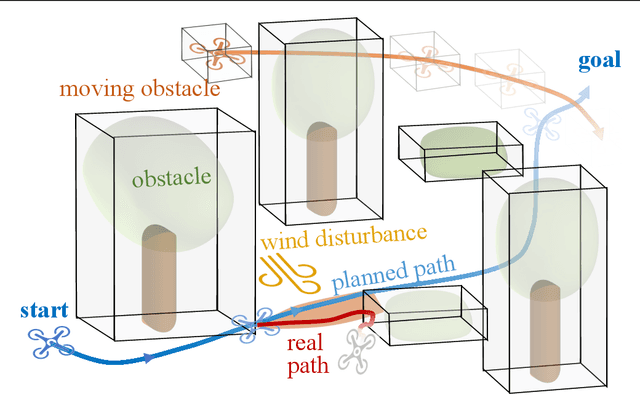
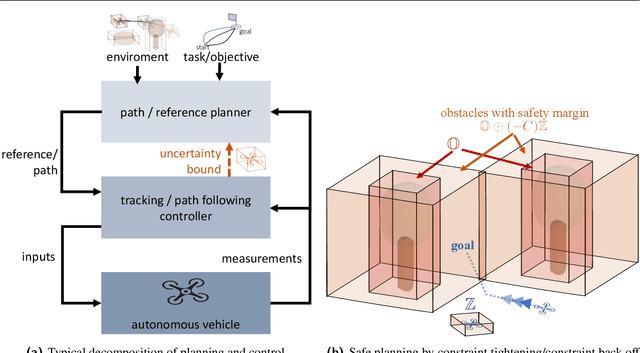
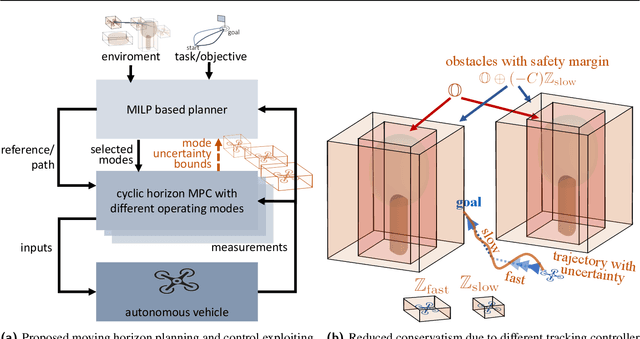
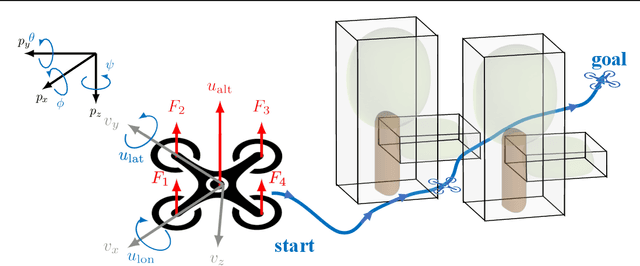
Planning and control for autonomous vehicles usually are hierarchical separated. However, increasing performance demands and operating in highly dynamic environments requires an frequent re-evaluation of the planning and tight integration of control and planning to guarantee safety. We propose an integrated hierarchical predictive control and planning approach to tackle this challenge. Planner and controller are based on the repeated solution of moving horizon optimal control problems. The planner can choose different low-layer controller modes for increased flexibility and performance instead of using a single controller with a large safety margin for collision avoidance under uncertainty. Planning is based on simplified system dynamics and safety, yet flexible operation is ensured by constraint tightening based on a mixed-integer linear programming formulation. A cyclic horizon tube-based model predictive controller guarantees constraint satisfaction for different control modes and disturbances. Examples of such modes are a slow-speed movement with high precision and fast-speed movements with large uncertainty bounds. Allowing for different control modes reduces the conservatism, while the hierarchical decomposition of the problem reduces the computational cost and enables real-time implementation. We derive conditions for recursive feasibility to ensure constraint satisfaction and obstacle avoidance to guarantee safety and ensure compatibility between the layers and modes. Simulation results illustrate the efficiency and applicability of the proposed hierarchical strategy.
Scientometric Review of Artificial Intelligence for Operations & Maintenance of Wind Turbines: The Past, Present and Future
Mar 30, 2022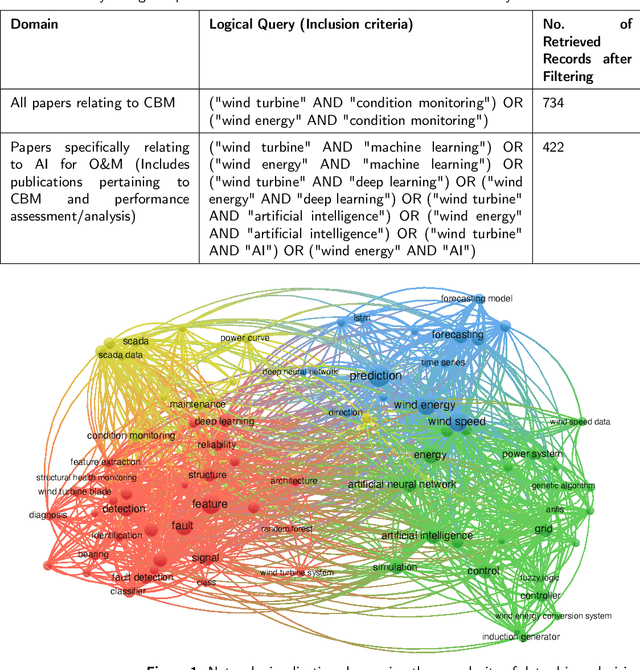
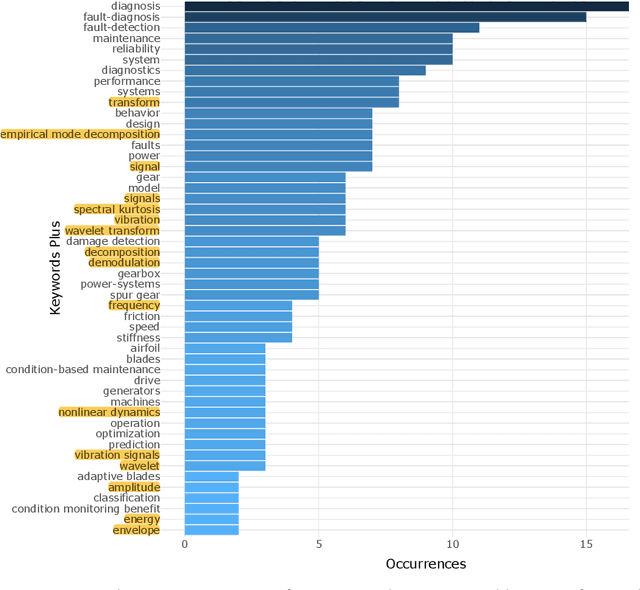
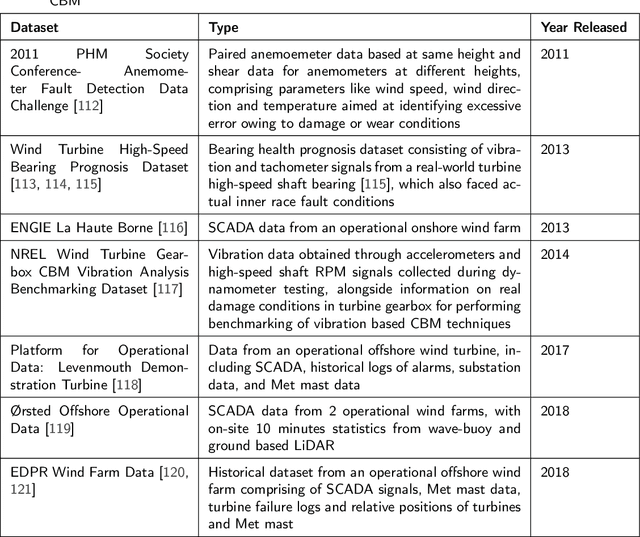
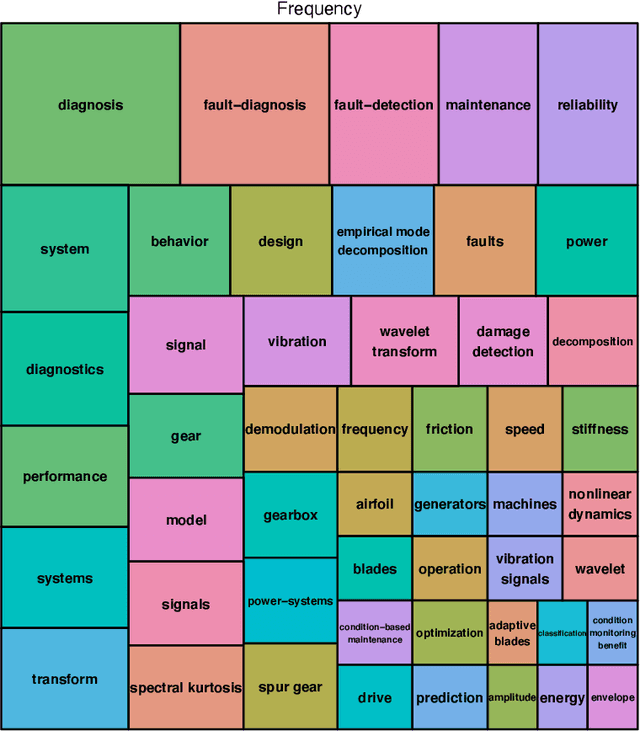
Wind energy has emerged as a highly promising source of renewable energy in recent times. However, wind turbines regularly suffer from operational inconsistencies, leading to significant costs and challenges in operations and maintenance (O&M). Condition-based monitoring (CBM) and performance assessment/analysis of turbines are vital aspects for ensuring efficient O&M planning and cost minimisation. Data-driven decision making techniques have witnessed rapid evolution in the wind industry for such O&M tasks during the last decade, from applying signal processing methods in early 2010 to artificial intelligence (AI) techniques, especially deep learning in 2020. In this article, we utilise statistical computing to present a scientometric review of the conceptual and thematic evolution of AI in the wind energy sector, providing evidence-based insights into present strengths and limitations of data-driven decision making in the wind industry. We provide a perspective into the future and on current key challenges in data availability and quality, lack of transparency in black box-natured AI models, and prevailing issues in deploying models for real-time decision support, along with possible strategies to overcome these problems. We hope that a systematic analysis of the past, present and future of CBM and performance assessment can encourage more organisations to adopt data-driven decision making techniques in O&M towards making wind energy sources more reliable, contributing to the global efforts of tackling climate change.
* This is a preprint version of the accepted manuscript in the Renewable and Sustainable Energy Reviews journal, shared under a CC-BY-NC-ND license. The final published version can be found at: https://doi.org/10.1016/j.rser.2021.111051
Continuous LWE is as Hard as LWE & Applications to Learning Gaussian Mixtures
Apr 06, 2022


We show direct and conceptually simple reductions between the classical learning with errors (LWE) problem and its continuous analog, CLWE (Bruna, Regev, Song and Tang, STOC 2021). This allows us to bring to bear the powerful machinery of LWE-based cryptography to the applications of CLWE. For example, we obtain the hardness of CLWE under the classical worst-case hardness of the gap shortest vector problem. Previously, this was known only under quantum worst-case hardness of lattice problems. More broadly, with our reductions between the two problems, any future developments to LWE will also apply to CLWE and its downstream applications. As a concrete application, we show an improved hardness result for density estimation for mixtures of Gaussians. In this computational problem, given sample access to a mixture of Gaussians, the goal is to output a function that estimates the density function of the mixture. Under the (plausible and widely believed) exponential hardness of the classical LWE problem, we show that Gaussian mixture density estimation in $\mathbb{R}^n$ with roughly $\log n$ Gaussian components given $\mathsf{poly}(n)$ samples requires time quasi-polynomial in $n$. Under the (conservative) polynomial hardness of LWE, we show hardness of density estimation for $n^{\epsilon}$ Gaussians for any constant $\epsilon > 0$, which improves on Bruna, Regev, Song and Tang (STOC 2021), who show hardness for at least $\sqrt{n}$ Gaussians under polynomial (quantum) hardness assumptions. Our key technical tool is a reduction from classical LWE to LWE with $k$-sparse secrets where the multiplicative increase in the noise is only $O(\sqrt{k})$, independent of the ambient dimension $n$.
SympOCnet: Solving optimal control problems with applications to high-dimensional multi-agent path planning problems
Jan 14, 2022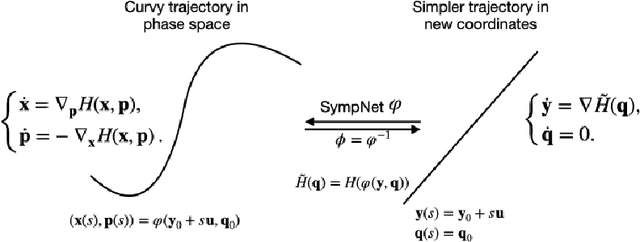
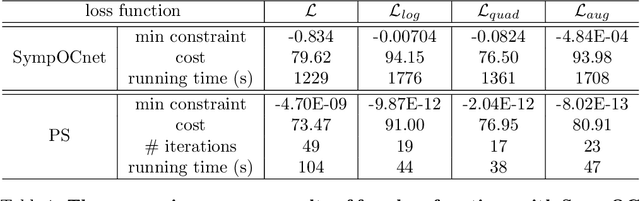
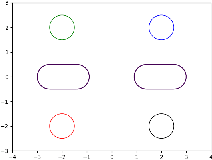

Solving high-dimensional optimal control problems in real-time is an important but challenging problem, with applications to multi-agent path planning problems, which have drawn increased attention given the growing popularity of drones in recent years. In this paper, we propose a novel neural network method called SympOCnet that applies the Symplectic network to solve high-dimensional optimal control problems with state constraints. We present several numerical results on path planning problems in two-dimensional and three-dimensional spaces. Specifically, we demonstrate that our SympOCnet can solve a problem with more than 500 dimensions in 1.5 hours on a single GPU, which shows the effectiveness and efficiency of SympOCnet. The proposed method is scalable and has the potential to solve truly high-dimensional path planning problems in real-time.
Sequence-to-Sequence Knowledge Graph Completion and Question Answering
Mar 19, 2022
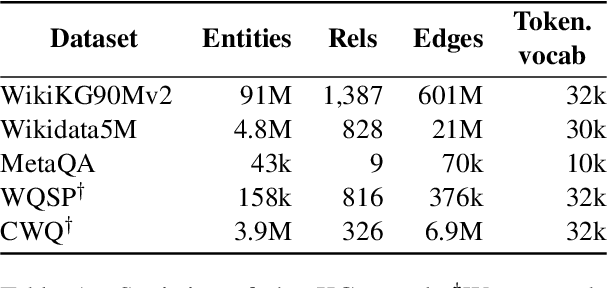
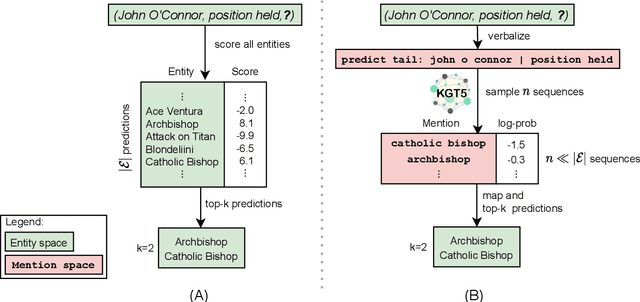
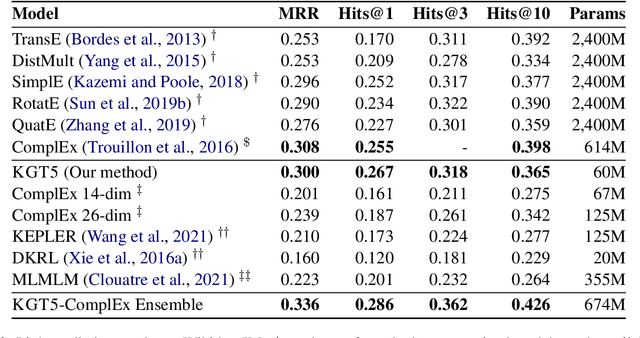
Knowledge graph embedding (KGE) models represent each entity and relation of a knowledge graph (KG) with low-dimensional embedding vectors. These methods have recently been applied to KG link prediction and question answering over incomplete KGs (KGQA). KGEs typically create an embedding for each entity in the graph, which results in large model sizes on real-world graphs with millions of entities. For downstream tasks these atomic entity representations often need to be integrated into a multi stage pipeline, limiting their utility. We show that an off-the-shelf encoder-decoder Transformer model can serve as a scalable and versatile KGE model obtaining state-of-the-art results for KG link prediction and incomplete KG question answering. We achieve this by posing KG link prediction as a sequence-to-sequence task and exchange the triple scoring approach taken by prior KGE methods with autoregressive decoding. Such a simple but powerful method reduces the model size up to 98% compared to conventional KGE models while keeping inference time tractable. After finetuning this model on the task of KGQA over incomplete KGs, our approach outperforms baselines on multiple large-scale datasets without extensive hyperparameter tuning.
Machine Learning Methods in Solving the Boolean Satisfiability Problem
Mar 02, 2022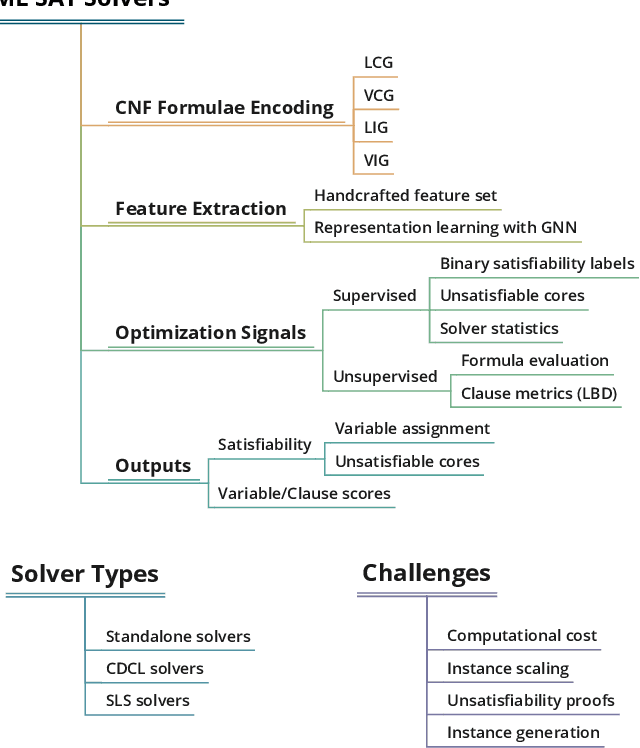
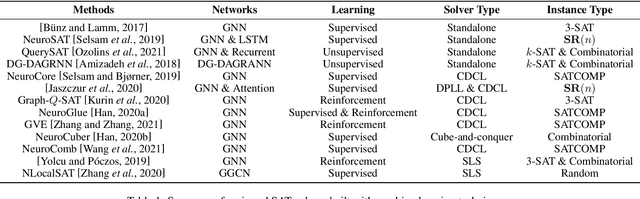
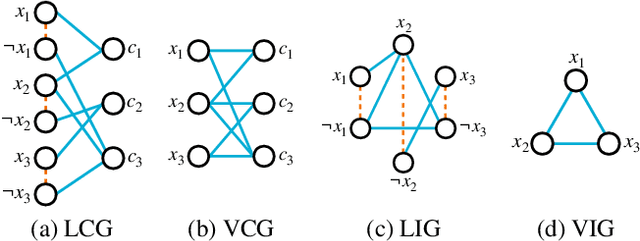
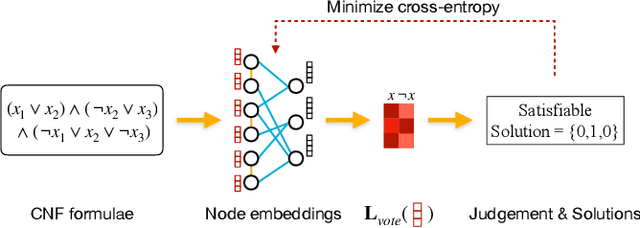
This paper reviews the recent literature on solving the Boolean satisfiability problem (SAT), an archetypal NP-complete problem, with the help of machine learning techniques. Despite the great success of modern SAT solvers to solve large industrial instances, the design of handcrafted heuristics is time-consuming and empirical. Under the circumstances, the flexible and expressive machine learning methods provide a proper alternative to solve this long-standing problem. We examine the evolving ML-SAT solvers from naive classifiers with handcrafted features to the emerging end-to-end SAT solvers such as NeuroSAT, as well as recent progress on combinations of existing CDCL and local search solvers with machine learning methods. Overall, solving SAT with machine learning is a promising yet challenging research topic. We conclude the limitations of current works and suggest possible future directions.
Improving the Accuracy of Global Forecasting Models using Time Series Data Augmentation
Aug 06, 2020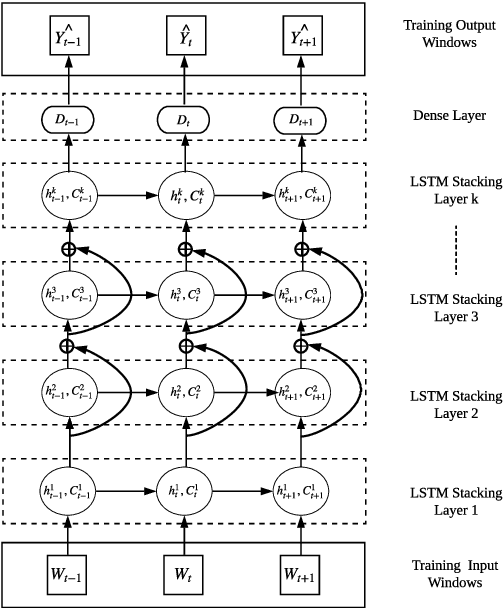
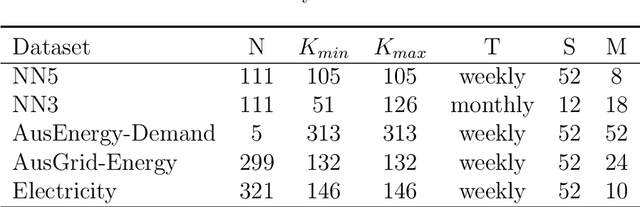
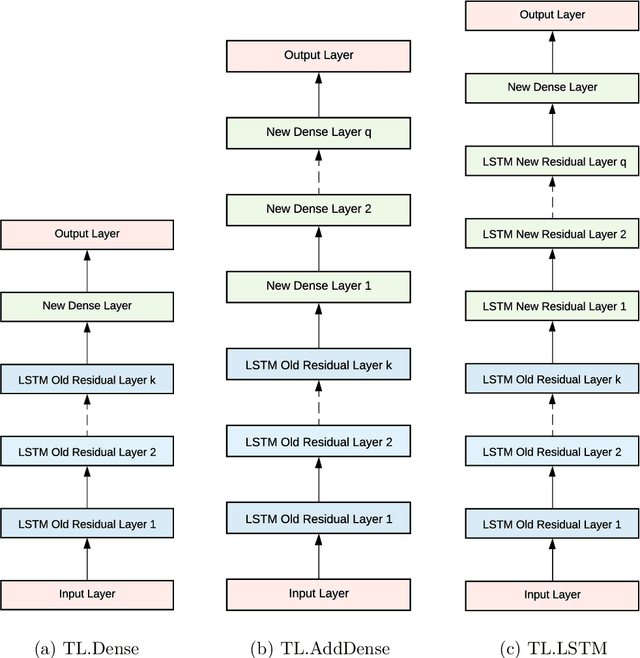
Forecasting models that are trained across sets of many time series, known as Global Forecasting Models (GFM), have shown recently promising results in forecasting competitions and real-world applications, outperforming many state-of-the-art univariate forecasting techniques. In most cases, GFMs are implemented using deep neural networks, and in particular Recurrent Neural Networks (RNN), which require a sufficient amount of time series to estimate their numerous model parameters. However, many time series databases have only a limited number of time series. In this study, we propose a novel, data augmentation based forecasting framework that is capable of improving the baseline accuracy of the GFM models in less data-abundant settings. We use three time series augmentation techniques: GRATIS, moving block bootstrap (MBB), and dynamic time warping barycentric averaging (DBA) to synthetically generate a collection of time series. The knowledge acquired from these augmented time series is then transferred to the original dataset using two different approaches: the pooled approach and the transfer learning approach. When building GFMs, in the pooled approach, we train a model on the augmented time series alongside the original time series dataset, whereas in the transfer learning approach, we adapt a pre-trained model to the new dataset. In our evaluation on competition and real-world time series datasets, our proposed variants can significantly improve the baseline accuracy of GFM models and outperform state-of-the-art univariate forecasting methods.
Deterministic Approximation for Submodular Maximization over a Matroid in Nearly Linear Time
Oct 22, 2020
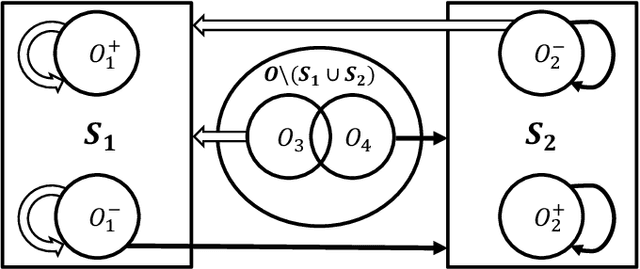
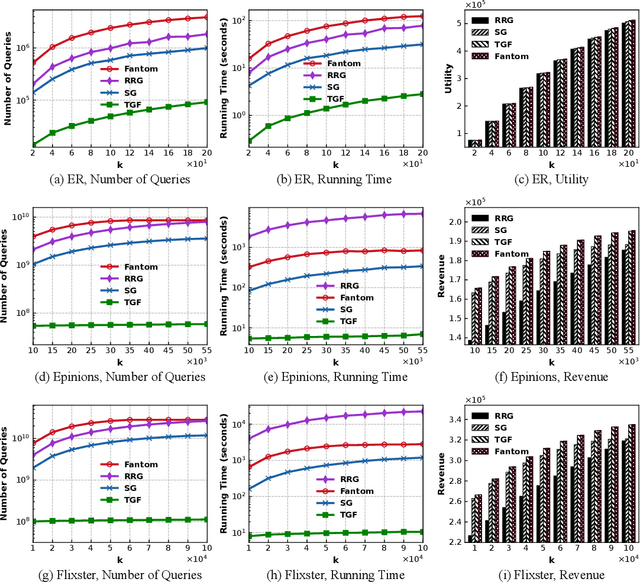
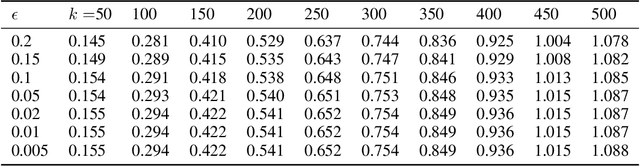
We study the problem of maximizing a non-monotone, non-negative submodular function subject to a matroid constraint. The prior best-known deterministic approximation ratio for this problem is $\frac{1}{4}-\epsilon$ under $\mathcal{O}(({n^4}/{\epsilon})\log n)$ time complexity. We show that this deterministic ratio can be improved to $\frac{1}{4}$ under $\mathcal{O}(nr)$ time complexity, and then present a more practical algorithm dubbed TwinGreedyFast which achieves $\frac{1}{4}-\epsilon$ deterministic ratio in nearly-linear running time of $\mathcal{O}(\frac{n}{\epsilon}\log\frac{r}{\epsilon})$. Our approach is based on a novel algorithmic framework of simultaneously constructing two candidate solution sets through greedy search, which enables us to get improved performance bounds by fully exploiting the properties of independence systems. As a byproduct of this framework, we also show that TwinGreedyFast achieves $\frac{1}{2p+2}-\epsilon$ deterministic ratio under a $p$-set system constraint with the same time complexity. To showcase the practicality of our approach, we empirically evaluated the performance of TwinGreedyFast on two network applications, and observed that it outperforms the state-of-the-art deterministic and randomized algorithms with efficient implementations for our problem.
First Arrival Position in Molecular Communication Via Generator of Diffusion Semigroup
Jan 14, 2022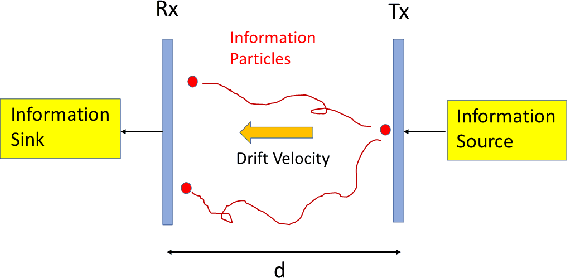
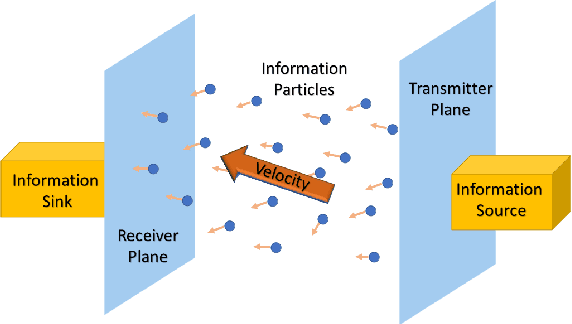
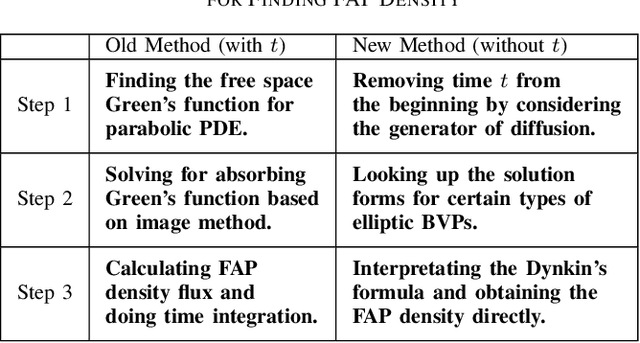
We consider the problem of characterizing the first arrival position (FAP) density in molecular communication (MC) with a diffusion-advection channel that permits a constant drift velocity pointed to arbitrary direction. The advantage of FAP modulation lies in the fact that it could encode more information into higher dimensional spatial variables, compared to other modulation techniques using time or molecule numbers. However, effective methods to characterize the FAP density in a general framework do not exist. In this paper, we devise a methodology that fully resolves the FAP density with planar absorbing receivers in arbitrary dimensions. Our work recovers existing results of FAP in 2D and 3D as special cases. The key insight of our approach is to remove the time dependence of the MC system evolution based on the generator of diffusion semigroups.
Patch-Fool: Are Vision Transformers Always Robust Against Adversarial Perturbations?
Apr 05, 2022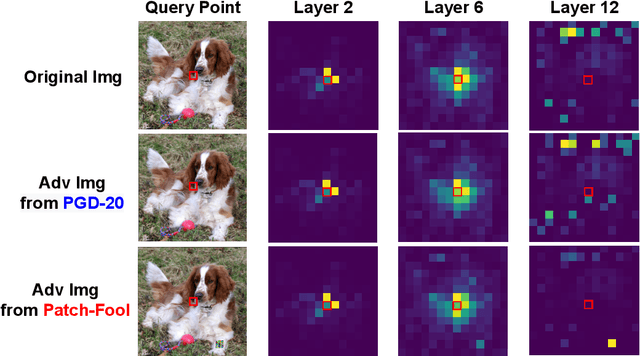
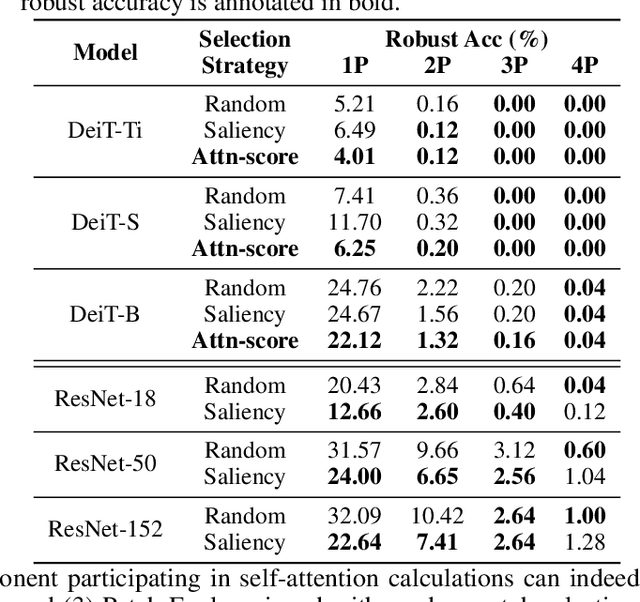
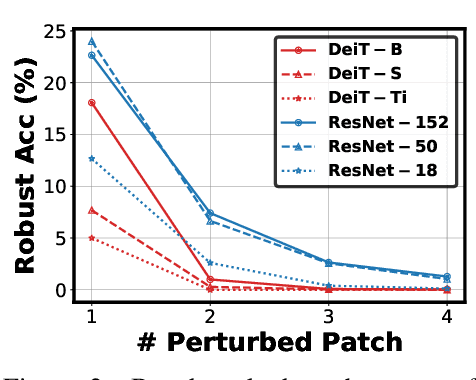
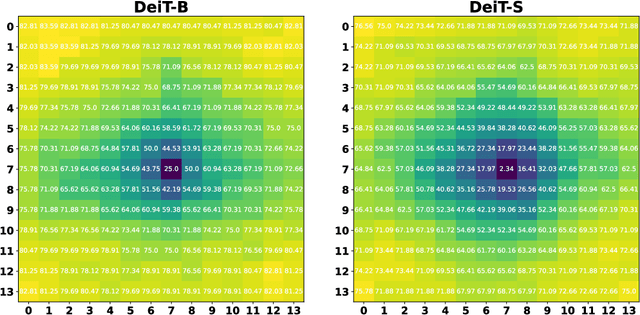
Vision transformers (ViTs) have recently set off a new wave in neural architecture design thanks to their record-breaking performance in various vision tasks. In parallel, to fulfill the goal of deploying ViTs into real-world vision applications, their robustness against potential malicious attacks has gained increasing attention. In particular, recent works show that ViTs are more robust against adversarial attacks as compared with convolutional neural networks (CNNs), and conjecture that this is because ViTs focus more on capturing global interactions among different input/feature patches, leading to their improved robustness to local perturbations imposed by adversarial attacks. In this work, we ask an intriguing question: "Under what kinds of perturbations do ViTs become more vulnerable learners compared to CNNs?" Driven by this question, we first conduct a comprehensive experiment regarding the robustness of both ViTs and CNNs under various existing adversarial attacks to understand the underlying reason favoring their robustness. Based on the drawn insights, we then propose a dedicated attack framework, dubbed Patch-Fool, that fools the self-attention mechanism by attacking its basic component (i.e., a single patch) with a series of attention-aware optimization techniques. Interestingly, our Patch-Fool framework shows for the first time that ViTs are not necessarily more robust than CNNs against adversarial perturbations. In particular, we find that ViTs are more vulnerable learners compared with CNNs against our Patch-Fool attack which is consistent across extensive experiments, and the observations from Sparse/Mild Patch-Fool, two variants of Patch-Fool, indicate an intriguing insight that the perturbation density and strength on each patch seem to be the key factors that influence the robustness ranking between ViTs and CNNs.