 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data-driven method for real-time prediction and uncertainty quantification of fatigue failure under stochastic loading using artificial neural networks and Gaussian process regression
Mar 11, 2021
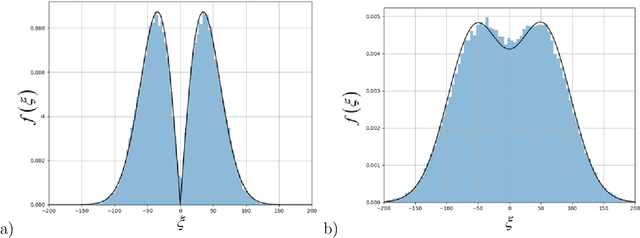

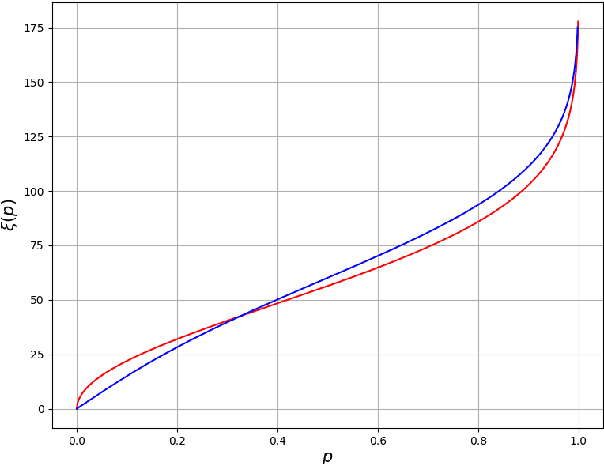

Various engineering systems such as naval and aerial vehicles, offshore structures, and mechanical components of motorized systems, are exposed to fatigue failures due to stochastic loadings. Methods for early failure prediction are essential for engineering, military, and civil applications. In addition to the prediction of time to failure (TtF), uncertainty quantification (UQ) is of major importance for real-time decision-making purposes. Usually, time domain or frequency domain methods are used for fatigue prediction, such as rainflow counting and Miner's rule or Dirlik's method. However, those methods suffer from over-simplistic modeling and inaccurate failure predictions under stochastic loadings. During the last years, several data-driven models were suggested for offline fatigue failure. However, most of them are not capable of both accurate real-time fatigue prediction and UQ. In the current work, a probabilistic data-driven model is introduced. A hybrid architecture of a fully-connected artificial neural network (FC-ANN) and Gaussian process regression (GPR) is proposed to ensure enhanced predictive abilities and simultaneous UQ of the predicted TtF. The real-time prediction and UQ performances of the suggested model are validated using both synthetic and experimental data. This novel hybrid method is fully data-driven and extends the forecasting capabilities of existing time-domain and machine learning-based methods for fatigue prediction. It paves the way towards the development of a preventive system that provides real-time safety and operational instructions and insights for structural health monitoring (SHM) purposes, allowing prevention of environmental damage, and loss of human lives.
Globally Optimal Spectrum- and Energy-Efficient Beamforming for Rate Splitting Multiple Access
Apr 01, 2022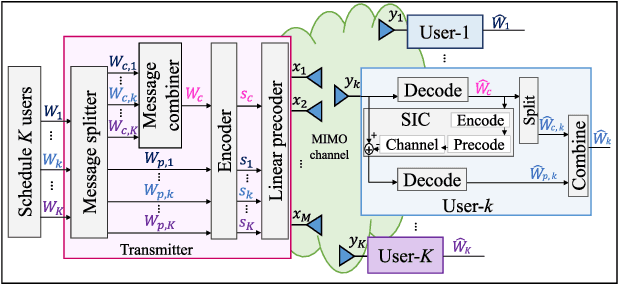
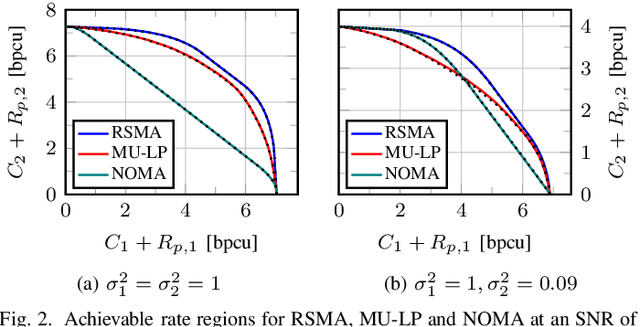
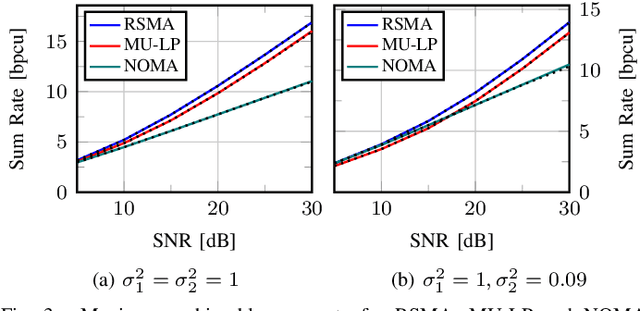
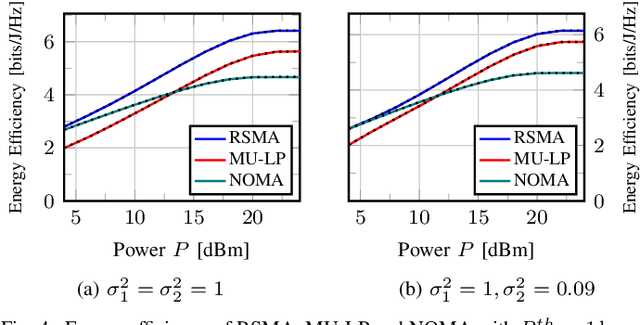
Rate splitting multiple access (RSMA) is a promising non-orthogonal transmission strategy for next-generation wireless networks. It has been shown to outperform existing multiple access schemes in terms of spectral and energy efficiency when suboptimal beamforming schemes are employed. In this work, we fill the gap between suboptimal and truly optimal beamforming schemes and conclusively establish the superior spectral and energy efficiency of RSMA. To this end, we propose a successive incumbent transcending (SIT) branch and bound (BB) algorithm to find globally optimal beamforming solutions that maximize the weighted sum rate or energy efficiency of RSMA in Gaussian multiple-input single-output (MISO) broadcast channels. Numerical results show that RSMA exhibits an explicit globally optimal spectral and energy efficiency gain over conventional multi-user linear precoding (MU-LP) and power-domain non-orthogonal multiple access (NOMA). Compared to existing globally optimal beamforming algorithms for MU-LP, the proposed SIT BB not only improves the numerical stability but also achieves faster convergence. Moreover, for the first time, we show that the spectral/energy efficiency of RSMA achieved by suboptimal beamforming schemes (including weighted minimum mean squared error (WMMSE) and successive convex approximation) almost coincides with the corresponding globally optimal performance, making it a valid choice for performance comparisons. The globally optimal results provided in this work are imperative to the ongoing research on RSMA as they serve as benchmarks for existing suboptimal beamforming strategies and those to be developed in multi-antenna broadcast channels.
Oscillatory Neural Network as Hetero-Associative Memory for Image Edge Detection
Feb 25, 2022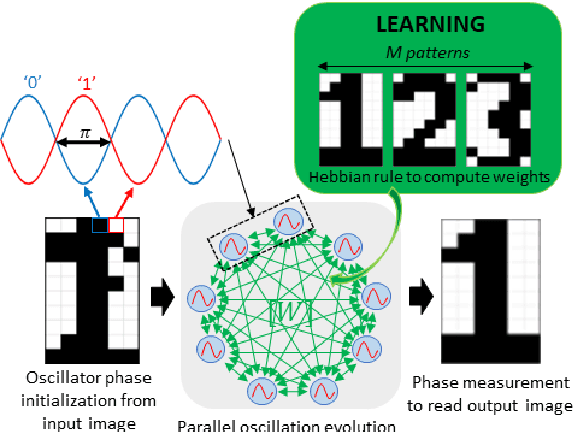

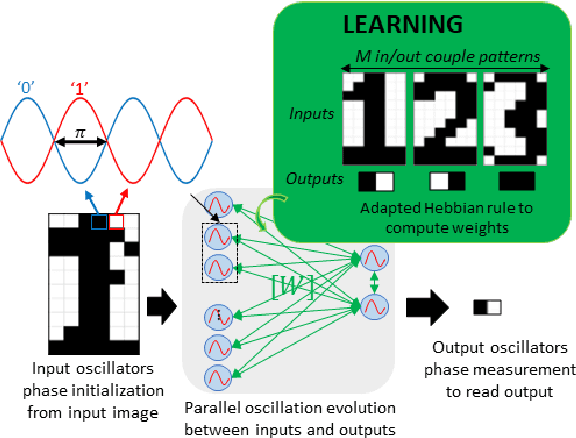
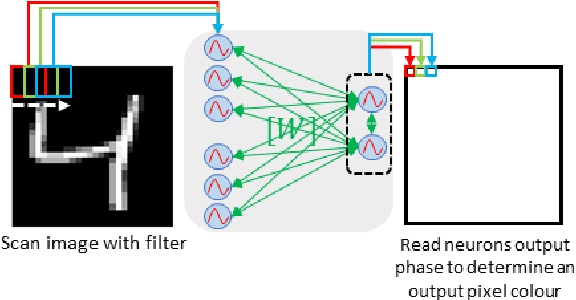
The increasing amount of data to be processed on edge devices, such as cameras, has motivated Artificial Intelligence (AI) integration at the edge. Typical image processing methods performed at the edge, such as feature extraction or edge detection, use convolutional filters that are energy, computation, and memory hungry algorithms. But edge devices and cameras have scarce computational resources, bandwidth, and power and are limited due to privacy constraints to send data over to the cloud. Thus, there is a need to process image data at the edge. Over the years, this need has incited a lot of interest in implementing neuromorphic computing at the edge. Neuromorphic systems aim to emulate the biological neural functions to achieve energy-efficient computing. Recently, Oscillatory Neural Networks (ONN) present a novel brain-inspired computing approach by emulating brain oscillations to perform autoassociative memory types of applications. To speed up image edge detection and reduce its power consumption, we perform an in-depth investigation with ONNs. We propose a novel image processing method by using ONNs as a hetero-associative memory (HAM) for image edge detection. We simulate our ONN-HAM solution using first, a Matlab emulator, and then a fully digital ONN design. We show results on gray scale square evaluation maps, also on black and white and gray scale 28x28 MNIST images and finally on black and white 512x512 standard test images. We compare our solution with standard edge detection filters such as Sobel and Canny. Finally, using the fully digital design simulation results, we report on timing and resource characteristics, and evaluate its feasibility for real-time image processing applications. Our digital ONN-HAM solution can process images with up to 120x120 pixels (166 MHz system frequency) respecting real-time camera constraints. This work is the first to explore ONNs as hetero-associative memory for image processing applications.
CARCA: Context and Attribute-Aware Next-Item Recommendation via Cross-Attention
Apr 04, 2022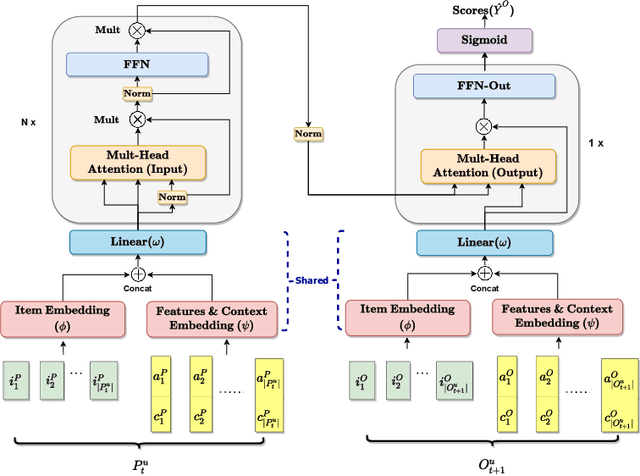
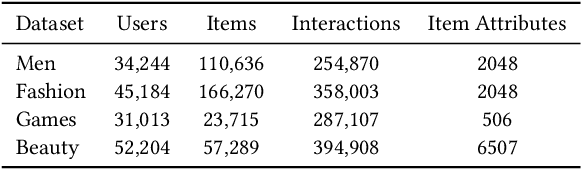
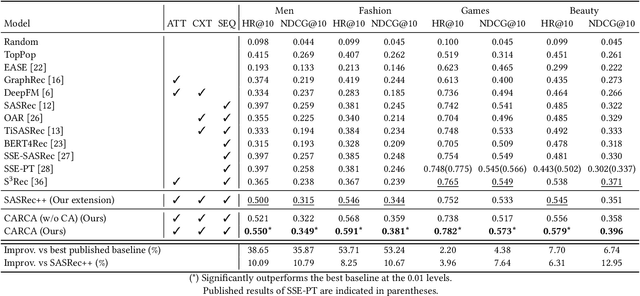
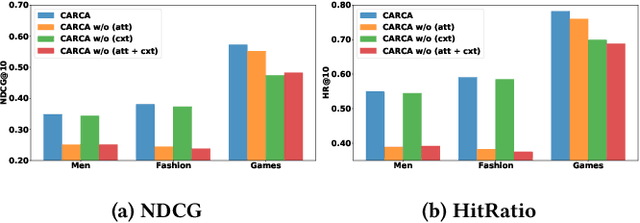
In sparse recommender settings, users' context and item attributes play a crucial role in deciding which items to recommend next. Despite that, recent works in sequential and time-aware recommendations usually either ignore both aspects or only consider one of them, limiting their predictive performance. In this paper, we address these limitations by proposing a context and attribute-aware recommender model (CARCA) that can capture the dynamic nature of the user profiles in terms of contextual features and item attributes via dedicated multi-head self-attention blocks that extract profile-level features and predicting item scores. Also, unlike many of the current state-of-the-art sequential item recommendation approaches that use a simple dot-product between the most recent item's latent features and the target items embeddings for scoring, CARCA uses cross-attention between all profile items and the target items to predict their final scores. This cross-attention allows CARCA to harness the correlation between old and recent items in the user profile and their influence on deciding which item to recommend next. Experiments on four real-world recommender system datasets show that the proposed model significantly outperforms all state-of-the-art models in the task of item recommendation and achieving improvements of up to 53% in Normalized Discounted Cumulative Gain (NDCG) and Hit-Ratio. Results also show that CARCA outperformed several state-of-the-art dedicated image-based recommender systems by merely utilizing image attributes extracted from a pre-trained ResNet50 in a black-box fashion.
High-Dimensional Sparse Bayesian Learning without Covariance Matrices
Feb 25, 2022
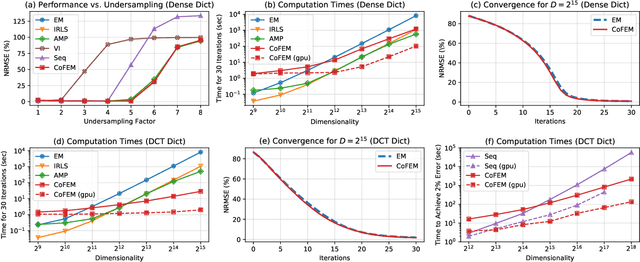
Sparse Bayesian learning (SBL) is a powerful framework for tackling the sparse coding problem. However, the most popular inference algorithms for SBL become too expensive for high-dimensional settings, due to the need to store and compute a large covariance matrix. We introduce a new inference scheme that avoids explicit construction of the covariance matrix by solving multiple linear systems in parallel to obtain the posterior moments for SBL. Our approach couples a little-known diagonal estimation result from numerical linear algebra with the conjugate gradient algorithm. On several simulations, our method scales better than existing approaches in computation time and memory, especially for structured dictionaries capable of fast matrix-vector multiplication.
* 5 pages
Toxic Comments Hunter : Score Severity of Toxic Comments
Feb 15, 2022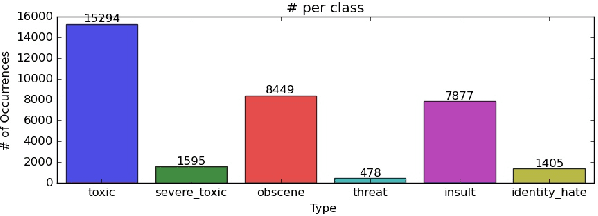
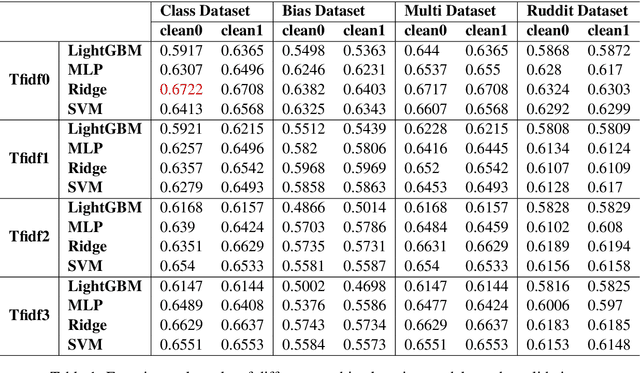

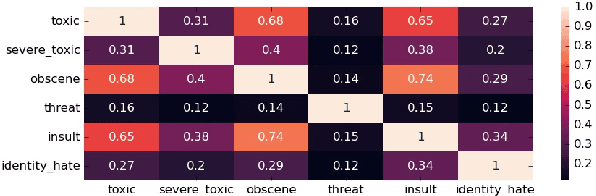
The detection and identification of toxic comments are conducive to creating a civilized and harmonious Internet environment. In this experiment, we collected various data sets related to toxic comments. Because of the characteristics of comment data, we perform data cleaning and feature extraction operations on it from different angles to obtain different toxic comment training sets. In terms of model construction, we used the training set to train the models based on TFIDF and finetuned the Bert model separately. Finally, we encapsulated the code into software to score toxic comments in real-time.
Linearization and Identification of Multiple-Attractors Dynamical System through Laplacian Eigenmaps
Feb 18, 2022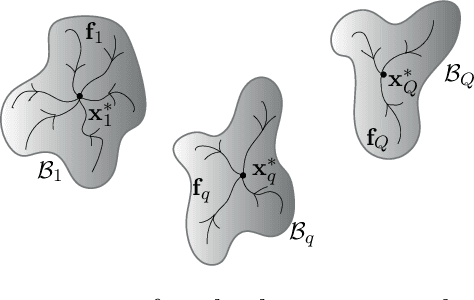
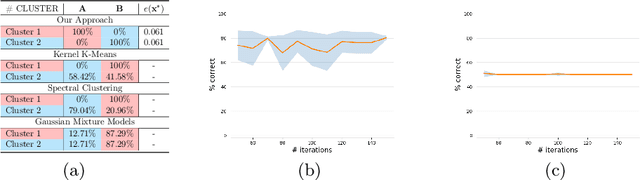
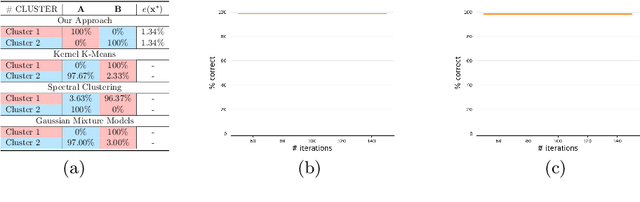
Dynamical Systems (DS) are fundamental to the modeling and understanding of time evolving phenomena, and find application in physics, biology and control. As determining an analytical description of the dynamics is often difficult, data-driven approaches are preferred for identifying and controlling nonlinear DS with multiple equilibrium points. Identification of such DS has been treated largely as a supervised learning problem. Instead, we focus on a unsupervised learning scenario where we know neither the number nor the type of dynamics. We propose a Graph-based spectral clustering method that takes advantage of a velocity-augmented kernel to connect data-points belonging to the same dynamics, while preserving the natural temporal evolution. We study the eigenvectors and eigenvalues of the Graph Laplacian and show that they form a set of orthogonal embedding spaces, one for each sub-dynamics. We prove that there always exist a set of 2-dimensional embedding spaces in which the sub-dynamics are linear, and n-dimensional embedding where they are quasi-linear. We compare the clustering performance of our algorithm to Kernel K-Means, Spectral Clustering and Gaussian Mixtures and show that, even when these algorithms are provided with the true number of sub-dynamics, they fail to cluster them correctly. We learn a diffeomorphism from the Laplacian embedding space to the original space and show that the Laplacian embedding leads to good reconstruction accuracy and a faster training time through an exponential decaying loss, compared to the state of the art diffeomorphism-based approaches.
Deep AutoAugment
Mar 11, 2022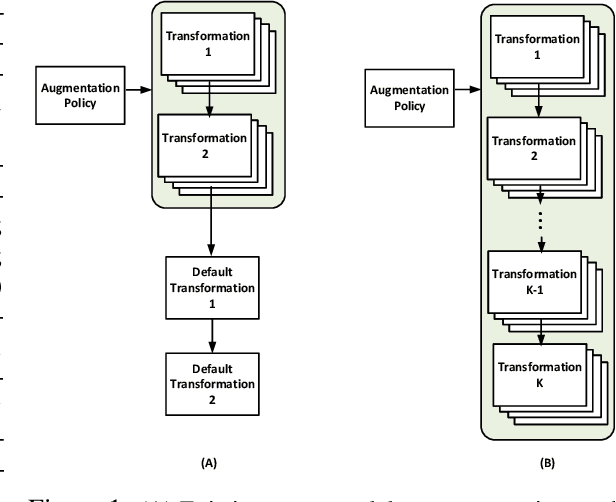


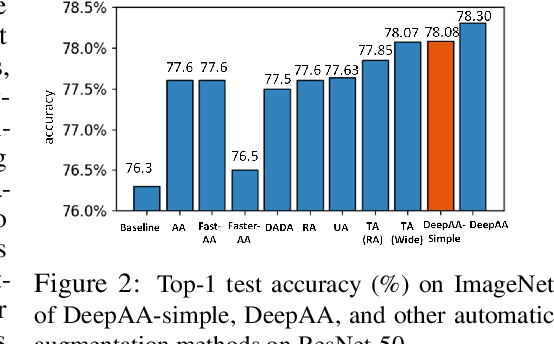
While recent automated data augmentation methods lead to state-of-the-art results, their design spaces and the derived data augmentation strategies still incorporate strong human priors. In this work, instead of fixing a set of hand-picked default augmentations alongside the searched data augmentations, we propose a fully automated approach for data augmentation search named Deep AutoAugment (DeepAA). DeepAA progressively builds a multi-layer data augmentation pipeline from scratch by stacking augmentation layers one at a time until reaching convergence. For each augmentation layer, the policy is optimized to maximize the cosine similarity between the gradients of the original and augmented data along the direction with low variance. Our experiments show that even without default augmentations, we can learn an augmentation policy that achieves strong performance with that of previous works. Extensive ablation studies show that the regularized gradient matching is an effective search method for data augmentation policies. Our code is available at: https://github.com/MSU-MLSys-Lab/DeepAA .
Neuromorphic Data Augmentation for Training Spiking Neural Networks
Mar 11, 2022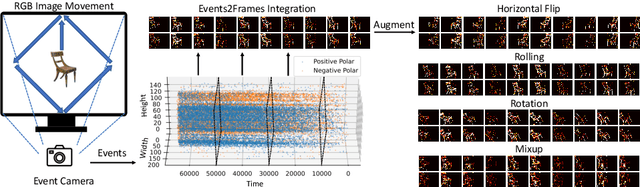
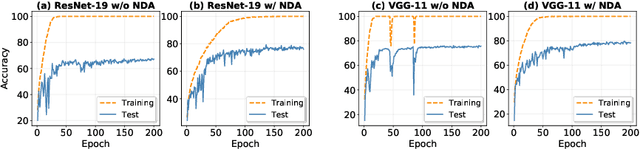

Developing neuromorphic intelligence on event-based datasets with spiking neural networks (SNNs) has recently attracted much research attention. However, the limited size of event-based datasets makes SNNs prone to overfitting and unstable convergence. This issue remains unexplored by previous academic works. In an effort to minimize this generalization gap, we propose neuromorphic data augmentation (NDA), a family of geometric augmentations specifically designed for event-based datasets with the goal of significantly stabilizing the SNN training and reducing the generalization gap between training and test performance. The proposed method is simple and compatible with existing SNN training pipelines. Using the proposed augmentation, for the first time, we demonstrate the feasibility of unsupervised contrastive learning for SNNs. We conduct comprehensive experiments on prevailing neuromorphic vision benchmarks and show that NDA yields substantial improvements over previous state-of-the-art results. For example, NDA-based SNN achieves accuracy gain on CIFAR10-DVS and N-Caltech 101 by 10.1% and 13.7%, respectively.
Training Fully Connected Neural Networks is $\exists\mathbb{R}$-Complete
Apr 04, 2022

We consider the algorithmic problem of finding the optimal weights and biases for a two-layer fully connected neural network to fit a given set of data points. This problem is known as empirical risk minimization in the machine learning community. We show that the problem is $\exists\mathbb{R}$-complete. This complexity class can be defined as the set of algorithmic problems that are polynomial-time equivalent to finding real roots of a polynomial with integer coefficients. Our results hold even if the following restrictions are all added simultaneously. $\bullet$ There are exactly two output neurons. $\bullet$ There are exactly two input neurons. $\bullet$ The data has only 13 different labels. $\bullet$ The number of hidden neurons is a constant fraction of the number of data points. $\bullet$ The target training error is zero. $\bullet$ The ReLU activation function is used. This shows that even very simple networks are difficult to train. The result offers an explanation (though far from a complete understanding) on why only gradient descent is widely successful in training neural networks in practice. We generalize a recent result by Abrahamsen, Kleist and Miltzow [NeurIPS 2021]. This result falls into a recent line of research that tries to unveil that a series of central algorithmic problems from widely different areas of computer science and mathematics are $\exists\mathbb{R}$-complete: This includes the art gallery problem [JACM/STOC 2018], geometric packing [FOCS 2020], covering polygons with convex polygons [FOCS 2021], and continuous constraint satisfaction problems [FOCS 2021].