 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Computational Complexity of Counting Linear Regions in ReLU Neural Networks
May 22, 2025An established measure of the expressive power of a given ReLU neural network is the number of linear regions into which it partitions the input space. There exist many different, non-equivalent definitions of what a linear region actually is. We systematically assess which papers use which definitions and discuss how they relate to each other. We then analyze the computational complexity of counting the number of such regions for the various definitions. Generally, this turns out to be an intractable problem. We prove NP- and #P-hardness results already for networks with one hidden layer and strong hardness of approximation results for two or more hidden layers. Finally, on the algorithmic side, we demonstrate that counting linear regions can at least be achieved in polynomial space for some common definitions.
Better Neural Network Expressivity: Subdividing the Simplex
May 20, 2025This work studies the expressivity of ReLU neural networks with a focus on their depth. A sequence of previous works showed that $\lceil \log_2(n+1) \rceil$ hidden layers are sufficient to compute all continuous piecewise linear (CPWL) functions on $\mathbb{R}^n$. Hertrich, Basu, Di Summa, and Skutella (NeurIPS'21) conjectured that this result is optimal in the sense that there are CPWL functions on $\mathbb{R}^n$, like the maximum function, that require this depth. We disprove the conjecture and show that $\lceil\log_3(n-1)\rceil+1$ hidden layers are sufficient to compute all CPWL functions on $\mathbb{R}^n$. A key step in the proof is that ReLU neural networks with two hidden layers can exactly represent the maximum function of five inputs. More generally, we show that $\lceil\log_3(n-2)\rceil+1$ hidden layers are sufficient to compute the maximum of $n\geq 4$ numbers. Our constructions almost match the $\lceil\log_3(n)\rceil$ lower bound of Averkov, Hojny, and Merkert (ICLR'25) in the special case of ReLU networks with weights that are decimal fractions. The constructions have a geometric interpretation via polyhedral subdivisions of the simplex into ``easier'' polytopes.
On the Depth of Monotone ReLU Neural Networks and ICNNs
May 09, 2025



We study two models of ReLU neural networks: monotone networks (ReLU$^+$) and input convex neural networks (ICNN). Our focus is on expressivity, mostly in terms of depth, and we prove the following lower bounds. For the maximum function MAX$_n$ computing the maximum of $n$ real numbers, we show that ReLU$^+$ networks cannot compute MAX$_n$, or even approximate it. We prove a sharp $n$ lower bound on the ICNN depth complexity of MAX$_n$. We also prove depth separations between ReLU networks and ICNNs; for every $k$, there is a depth-2 ReLU network of size $O(k^2)$ that cannot be simulated by a depth-$k$ ICNN. The proofs are based on deep connections between neural networks and polyhedral geometry, and also use isoperimetric properties of triangulations.
Depth-Bounds for Neural Networks via the Braid Arrangement
Feb 13, 2025We contribute towards resolving the open question of how many hidden layers are required in ReLU networks for exactly representing all continuous and piecewise linear functions on $\mathbb{R}^d$. While the question has been resolved in special cases, the best known lower bound in general is still 2. We focus on neural networks that are compatible with certain polyhedral complexes, more precisely with the braid fan. For such neural networks, we prove a non-constant lower bound of $\Omega(\log\log d)$ hidden layers required to exactly represent the maximum of $d$ numbers. Additionally, under our assumption, we provide a combinatorial proof that 3 hidden layers are necessary to compute the maximum of 5 numbers; this had only been verified with an excessive computation so far. Finally, we show that a natural generalization of the best known upper bound to maxout networks is not tight, by demonstrating that a rank-3 maxout layer followed by a rank-2 maxout layer is sufficient to represent the maximum of 7 numbers.
Neural Networks and (Virtual) Extended Formulations
Nov 05, 2024Neural networks with piecewise linear activation functions, such as rectified linear units (ReLU) or maxout, are among the most fundamental models in modern machine learning. We make a step towards proving lower bounds on the size of such neural networks by linking their representative capabilities to the notion of the extension complexity $\mathrm{xc}(P)$ of a polytope $P$, a well-studied quantity in combinatorial optimization and polyhedral geometry. To this end, we propose the notion of virtual extension complexity $\mathrm{vxc}(P)=\min\{\mathrm{xc}(Q)+\mathrm{xc}(R)\mid P+Q=R\}$. This generalizes $\mathrm{xc}(P)$ and describes the number of inequalities needed to represent the linear optimization problem over $P$ as a difference of two linear programs. We prove that $\mathrm{vxc}(P)$ is a lower bound on the size of a neural network that optimizes over $P$. While it remains open to derive strong lower bounds on virtual extension complexity, we show that powerful results on the ordinary extension complexity can be converted into lower bounds for monotone neural networks, that is, neural networks with only nonnegative weights. Furthermore, we show that one can efficiently optimize over a polytope $P$ using a small virtual extended formulation. We therefore believe that virtual extension complexity deserves to be studied independently from neural networks, just like the ordinary extension complexity. As a first step in this direction, we derive an example showing that extension complexity can go down under Minkowski sum.
Decomposition Polyhedra of Piecewise Linear Functions
Oct 07, 2024



In this paper we contribute to the frequently studied question of how to decompose a continuous piecewise linear (CPWL) function into a difference of two convex CPWL functions. Every CPWL function has infinitely many such decompositions, but for applications in optimization and neural network theory, it is crucial to find decompositions with as few linear pieces as possible. This is a highly challenging problem, as we further demonstrate by disproving a recently proposed approach by Tran and Wang [Minimal representations of tropical rational functions. Algebraic Statistics, 15(1):27-59, 2024]. To make the problem more tractable, we propose to fix an underlying polyhedral complex determining the possible locus of nonlinearity. Under this assumption, we prove that the set of decompositions forms a polyhedron that arises as intersection of two translated cones. We prove that irreducible decompositions correspond to the bounded faces of this polyhedron and minimal solutions must be vertices. We then identify cases with a unique minimal decomposition, and illustrate how our insights have consequences in the theory of submodular functions. Finally, we improve upon previous constructions of neural networks for a given convex CPWL function and apply our framework to obtain results in the nonconvex case.
Mode Connectivity in Auction Design
May 18, 2023Optimal auction design is a fundamental problem in algorithmic game theory. This problem is notoriously difficult already in very simple settings. Recent work in differentiable economics showed that neural networks can efficiently learn known optimal auction mechanisms and discover interesting new ones. In an attempt to theoretically justify their empirical success, we focus on one of the first such networks, RochetNet, and a generalized version for affine maximizer auctions. We prove that they satisfy mode connectivity, i.e., locally optimal solutions are connected by a simple, piecewise linear path such that every solution on the path is almost as good as one of the two local optima. Mode connectivity has been recently investigated as an intriguing empirical and theoretically justifiable property of neural networks used for prediction problems. Our results give the first such analysis in the context of differentiable economics, where neural networks are used directly for solving non-convex optimization problems.
Training Neural Networks is NP-Hard in Fixed Dimension
Mar 29, 2023We study the parameterized complexity of training two-layer neural networks with respect to the dimension of the input data and the number of hidden neurons, considering ReLU and linear threshold activation functions. Albeit the computational complexity of these problems has been studied numerous times in recent years, several questions are still open. We answer questions by Arora et al. [ICLR '18] and Khalife and Basu [IPCO '22] showing that both problems are NP-hard for two dimensions, which excludes any polynomial-time algorithm for constant dimension. We also answer a question by Froese et al. [JAIR '22] proving W[1]-hardness for four ReLUs (or two linear threshold neurons) with zero training error. Finally, in the ReLU case, we show fixed-parameter tractability for the combined parameter number of dimensions and number of ReLUs if the network is assumed to compute a convex map. Our results settle the complexity status regarding these parameters almost completely.
Lower Bounds on the Depth of Integral ReLU Neural Networks via Lattice Polytopes
Feb 24, 2023We prove that the set of functions representable by ReLU neural networks with integer weights strictly increases with the network depth while allowing arbitrary width. More precisely, we show that $\lceil\log_2(n)\rceil$ hidden layers are indeed necessary to compute the maximum of $n$ numbers, matching known upper bounds. Our results are based on the known duality between neural networks and Newton polytopes via tropical geometry. The integrality assumption implies that these Newton polytopes are lattice polytopes. Then, our depth lower bounds follow from a parity argument on the normalized volume of faces of such polytopes.
Training Fully Connected Neural Networks is $\exists\mathbb{R}$-Complete
Apr 04, 2022

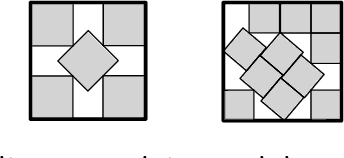
We consider the algorithmic problem of finding the optimal weights and biases for a two-layer fully connected neural network to fit a given set of data points. This problem is known as empirical risk minimization in the machine learning community. We show that the problem is $\exists\mathbb{R}$-complete. This complexity class can be defined as the set of algorithmic problems that are polynomial-time equivalent to finding real roots of a polynomial with integer coefficients. Our results hold even if the following restrictions are all added simultaneously. $\bullet$ There are exactly two output neurons. $\bullet$ There are exactly two input neurons. $\bullet$ The data has only 13 different labels. $\bullet$ The number of hidden neurons is a constant fraction of the number of data points. $\bullet$ The target training error is zero. $\bullet$ The ReLU activation function is used. This shows that even very simple networks are difficult to train. The result offers an explanation (though far from a complete understanding) on why only gradient descent is widely successful in training neural networks in practice. We generalize a recent result by Abrahamsen, Kleist and Miltzow [NeurIPS 2021]. This result falls into a recent line of research that tries to unveil that a series of central algorithmic problems from widely different areas of computer science and mathematics are $\exists\mathbb{R}$-complete: This includes the art gallery problem [JACM/STOC 2018], geometric packing [FOCS 2020], covering polygons with convex polygons [FOCS 2021], and continuous constraint satisfaction problems [FOCS 2021].