 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Small Batch Sizes Improve Training of Low-Resource Neural MT
Mar 20, 2022
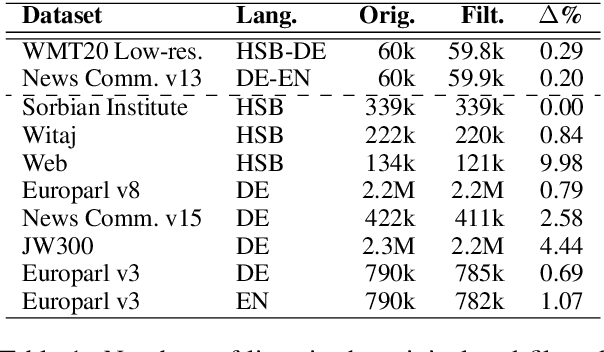
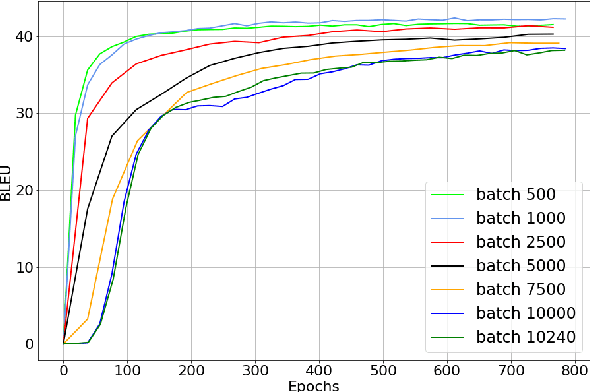
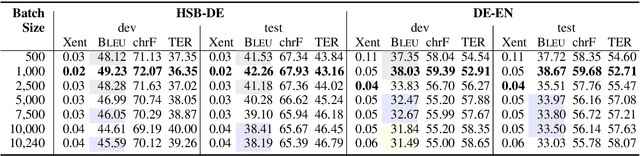

We study the role of an essential hyper-parameter that governs the training of Transformers for neural machine translation in a low-resource setting: the batch size. Using theoretical insights and experimental evidence, we argue against the widespread belief that batch size should be set as large as allowed by the memory of the GPUs. We show that in a low-resource setting, a smaller batch size leads to higher scores in a shorter training time, and argue that this is due to better regularization of the gradients during training.
Change-point Detection and Segmentation of Discrete Data using Bayesian Context Trees
Mar 08, 2022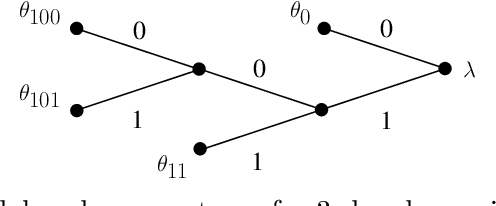
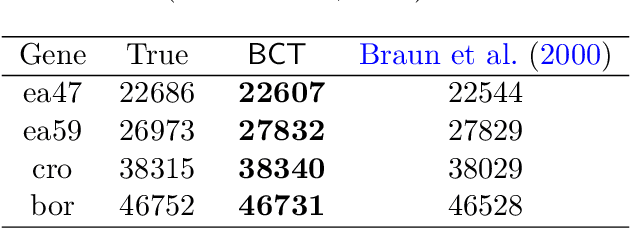
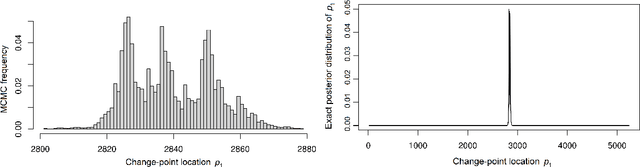
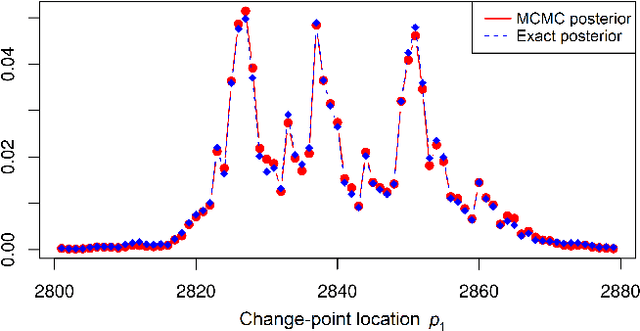
A new Bayesian modelling framework is introduced for piece-wise homogeneous variable-memory Markov chains, along with a collection of effective algorithmic tools for change-point detection and segmentation of discrete time series. Building on the recently introduced Bayesian Context Trees (BCT) framework, the distributions of different segments in a discrete time series are described as variable-memory Markov chains. Inference for the presence and location of change-points is then performed via Markov chain Monte Carlo sampling. The key observation that facilitates effective sampling is that, using one of the BCT algorithms, the prior predictive likelihood of the data can be computed exactly, integrating out all the models and parameters in each segment. This makes it possible to sample directly from the posterior distribution of the number and location of the change-points, leading to accurate estimates and providing a natural quantitative measure of uncertainty in the results. Estimates of the actual model in each segment can also be obtained, at essentially no additional computational cost. Results on both simulated and real-world data indicate that the proposed methodology performs better than or as well as state-of-the-art techniques.
Detecting GAN-generated Images by Orthogonal Training of Multiple CNNs
Mar 04, 2022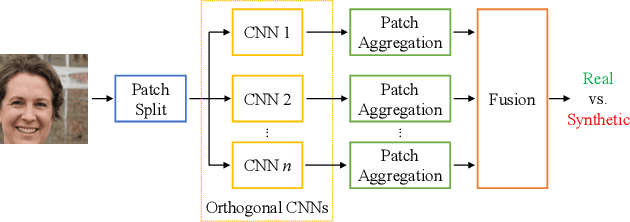
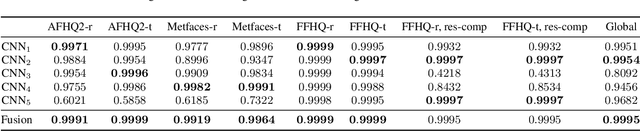
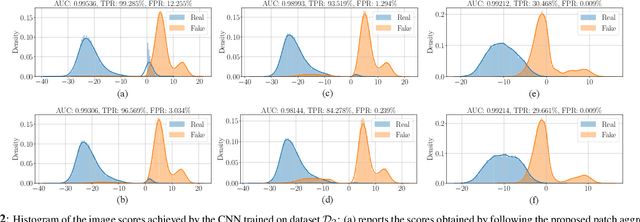
In the last few years, we have witnessed the rise of a series of deep learning methods to generate synthetic images that look extremely realistic. These techniques prove useful in the movie industry and for artistic purposes. However, they also prove dangerous if used to spread fake news or to generate fake online accounts. For this reason, detecting if an image is an actual photograph or has been synthetically generated is becoming an urgent necessity. This paper proposes a detector of synthetic images based on an ensemble of Convolutional Neural Networks (CNNs). We consider the problem of detecting images generated with techniques not available at training time. This is a common scenario, given that new image generators are published more and more frequently. To solve this issue, we leverage two main ideas: (i) CNNs should provide orthogonal results to better contribute to the ensemble; (ii) original images are better defined than synthetic ones, thus they should be better trusted at testing time. Experiments show that pursuing these two ideas improves the detector accuracy on NVIDIA's newly generated StyleGAN3 images, never used in training.
New approach to MPI program execution time prediction
Jul 30, 2020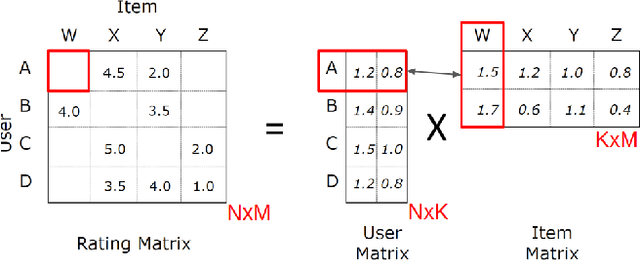
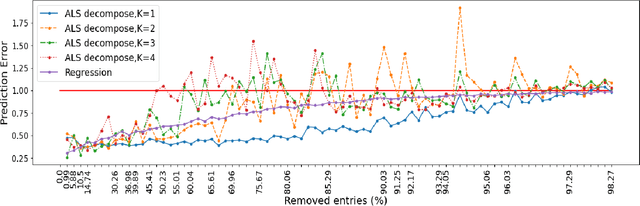
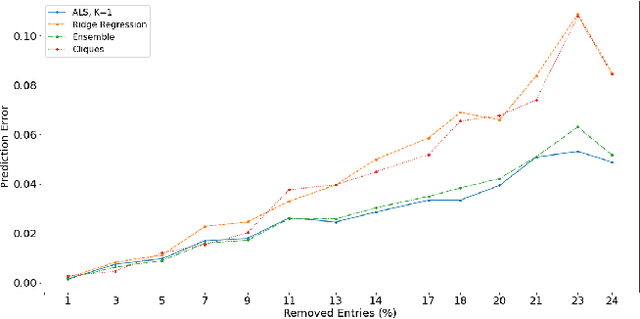
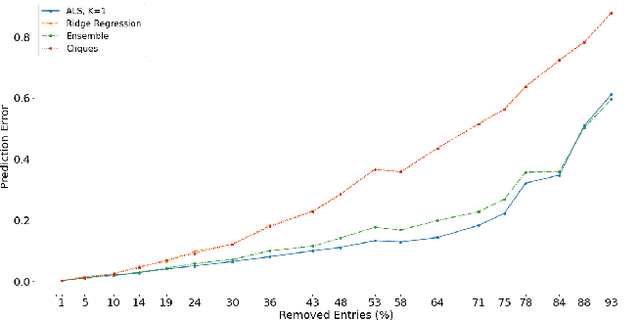
The problem of MPI programs execution time prediction on a certain set of computer installations is considered. This problem emerges with orchestration and provisioning a virtual infrastructure in a cloud computing environment over a heterogeneous network of computer installations: supercomputers or clusters of servers (e.g. mini data centers). One of the key criteria for the effectiveness of the cloud computing environment is the time staying by the program inside the environment. This time consists of the waiting time in the queue and the execution time on the selected physical computer installation, to which the computational resource of the virtual infrastructure is dynamically mapped. One of the components of this problem is the estimation of the MPI programs execution time on a certain set of computer installations. This is necessary to determine a proper choice of order and place for program execution. The article proposes two new approaches to the program execution time prediction problem. The first one is based on computer installations grouping based on the Pearson correlation coefficient. The second one is based on vector representations of computer installations and MPI programs, so-called embeddings. The embedding technique is actively used in recommendation systems, such as for goods (Amazon), for articles (Arxiv.org), for videos (YouTube, Netflix). The article shows how the embeddings technique helps to predict the execution time of a MPI program on a certain set of computer installations.
Locate This, Not That: Class-Conditioned Sound Event DOA Estimation
Mar 08, 2022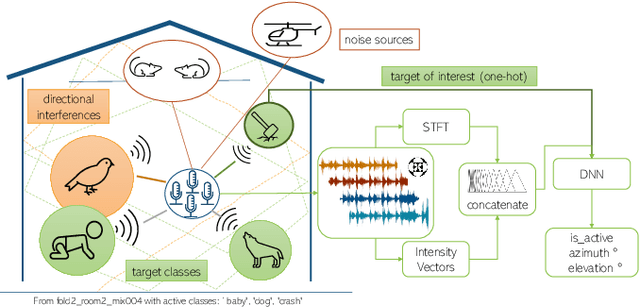
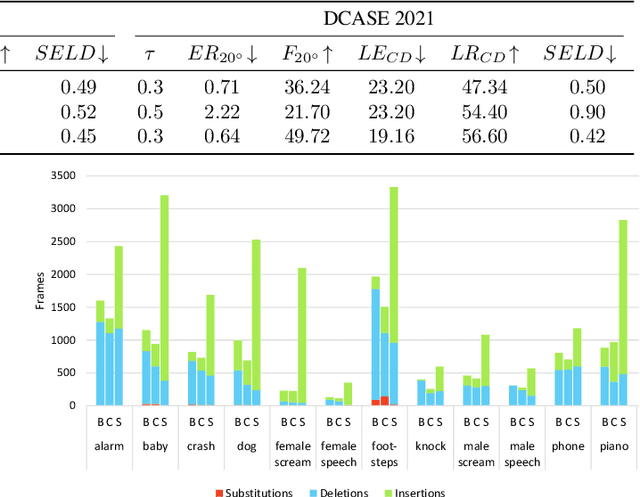
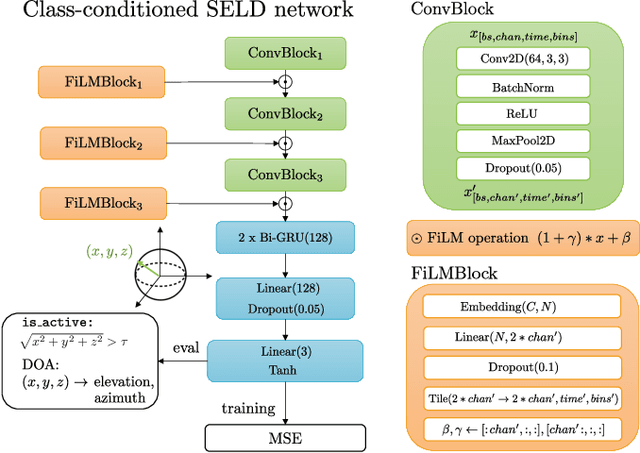
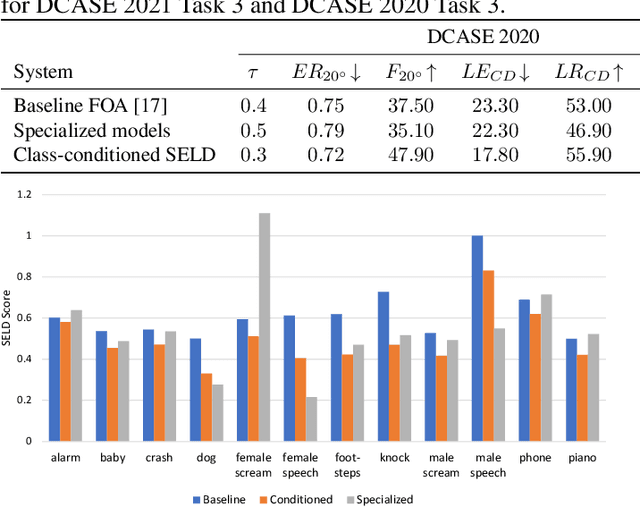
Existing systems for sound event localization and detection (SELD) typically operate by estimating a source location for all classes at every time instant. In this paper, we propose an alternative class-conditioned SELD model for situations where we may not be interested in localizing all classes all of the time. This class-conditioned SELD model takes as input the spatial and spectral features from the sound file, and also a one-hot vector indicating the class we are currently interested in localizing. We inject the conditioning information at several points in our model using feature-wise linear modulation (FiLM) layers. Through experiments on the DCASE 2020 Task 3 dataset, we show that the proposed class-conditioned SELD model performs better in terms of common SELD metrics than the baseline model that locates all classes simultaneously, and also outperforms specialist models that are trained to locate only a single class of interest. We also evaluate performance on the DCASE 2021 Task 3 dataset, which includes directional interference (sound events from classes we are not interested in localizing) and notice especially strong improvement from the class-conditioned model.
tvopt: A Python Framework for Time-Varying Optimization
Nov 12, 2020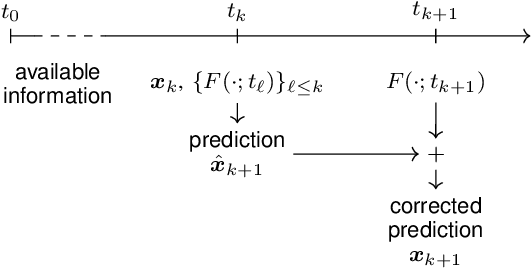
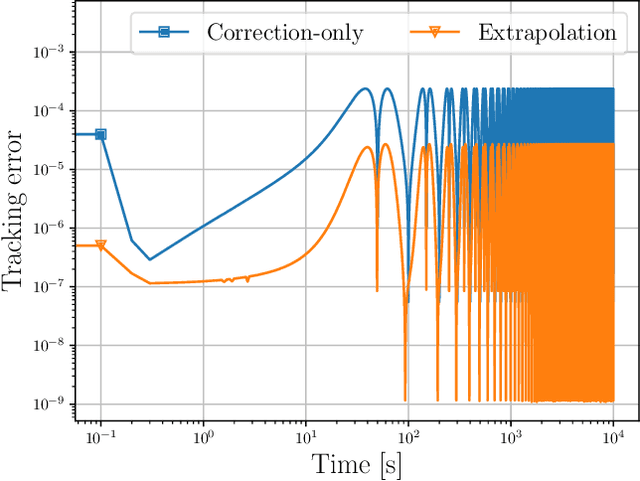
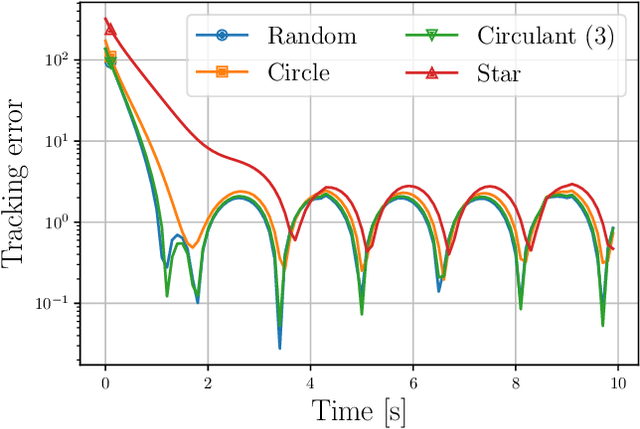
This paper introduces tvopt, a Python framework for prototyping and benchmarking time-varying (or online) optimization algorithms. The paper first describes the theoretical approach that informed the development of tvopt. Then it discusses the different components of the framework and their use for modeling and solving time-varying optimization problems. In particular, tvopt provides functionalities for defining both centralized and distributed online problems, and a collection of built-in algorithms to solve them, for example gradient-based methods, ADMM and other splitting methods. Moreover, the framework implements prediction strategies to improve the accuracy of the online solvers. The paper then proposes some numerical results on a benchmark problem and discusses their implementation using tvopt. The code for tvopt is available at https://github.com/nicola-bastianello/tvopt.
Scheduling Real-time Deep Learning Services as Imprecise Computations
Nov 02, 2020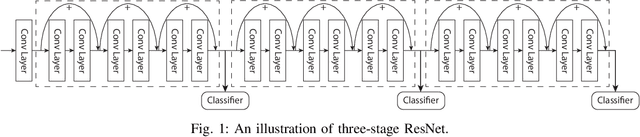
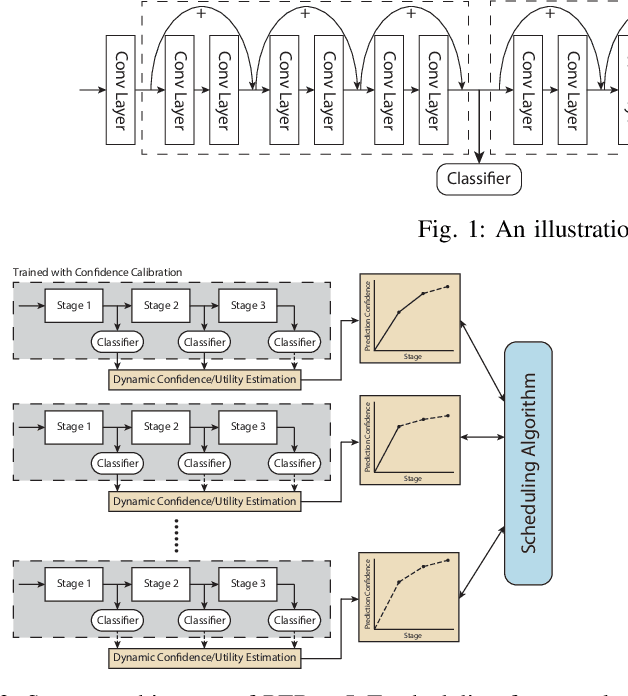
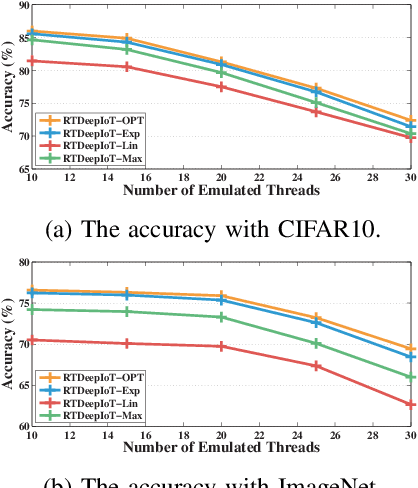
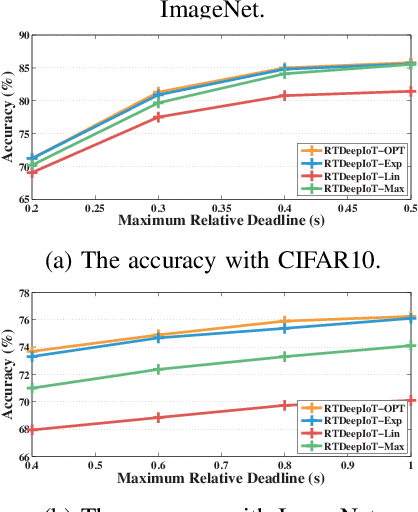
The paper presents an efficient real-time scheduling algorithm for intelligent real-time edge services, defined as those that perform machine intelligence tasks, such as voice recognition, LIDAR processing, or machine vision, on behalf of local embedded devices that are themselves unable to support extensive computations. The work contributes to a recent direction in real-time computing that develops scheduling algorithms for machine intelligence tasks with anytime prediction. We show that deep neural network workflows can be cast as imprecise computations, each with a mandatory part and (several) optional parts whose execution utility depends on input data. The goal of the real-time scheduler is to maximize the average accuracy of deep neural network outputs while meeting task deadlines, thanks to opportunistic shedding of the least necessary optional parts. The work is motivated by the proliferation of increasingly ubiquitous but resource-constrained embedded devices (for applications ranging from autonomous cars to the Internet of Things) and the desire to develop services that endow them with intelligence. Experiments on recent GPU hardware and a state of the art deep neural network for machine vision illustrate that our scheme can increase the overall accuracy by 10%-20% while incurring (nearly) no deadline misses.
Automatic calibration of time of flight based non-line-of-sight reconstruction
May 21, 2021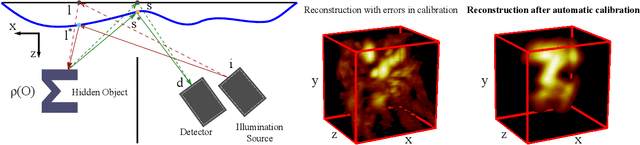

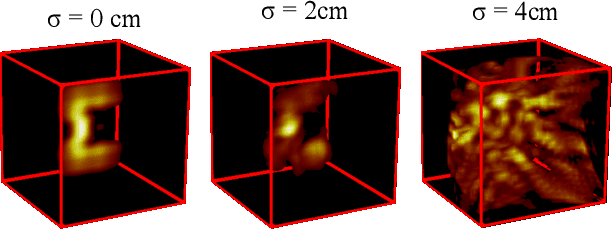

Time of flight based Non-line-of-sight (NLOS) imaging approaches require precise calibration of illumination and detector positions on the visible scene to produce reasonable results. If this calibration error is sufficiently high, reconstruction can fail entirely without any indication to the user. In this work, we highlight the necessity of building autocalibration into NLOS reconstruction in order to handle mis-calibration. We propose a forward model of NLOS measurements that is differentiable with respect to both, the hidden scene albedo, and virtual illumination and detector positions. With only a mean squared error loss and no regularization, our model enables joint reconstruction and recovery of calibration parameters by minimizing the measurement residual using gradient descent. We demonstrate our method is able to produce robust reconstructions using simulated and real data where the calibration error applied causes other state of the art algorithms to fail.
Deep Learning-enabled Detection and Classification of Bacterial Colonies using a Thin Film Transistor (TFT) Image Sensor
May 07, 2022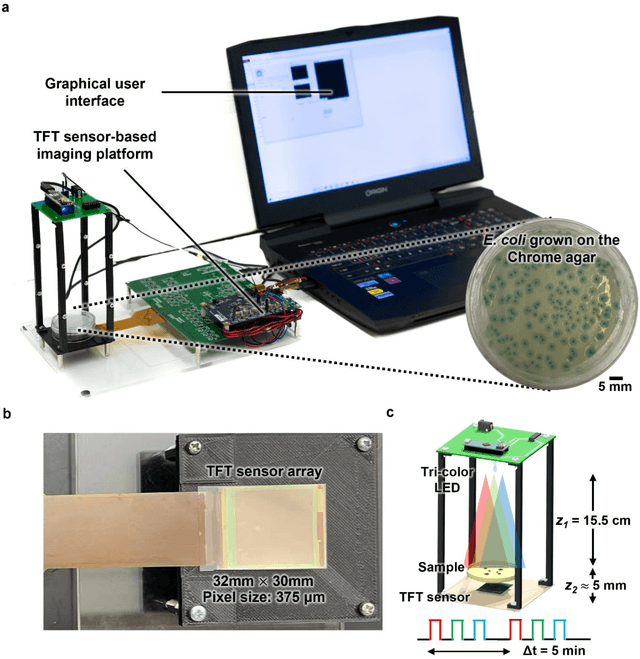
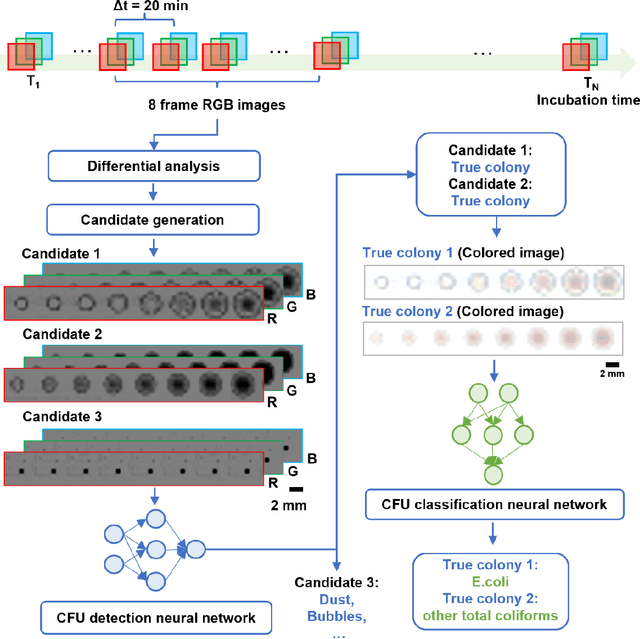

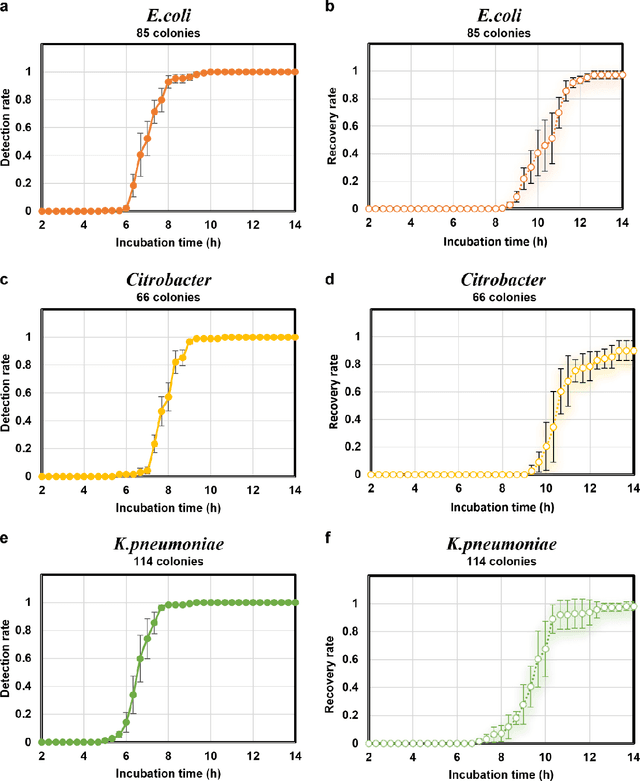
Early detection and identification of pathogenic bacteria such as Escherichia coli (E. coli) is an essential task for public health. The conventional culture-based methods for bacterial colony detection usually take >24 hours to get the final read-out. Here, we demonstrate a bacterial colony-forming-unit (CFU) detection system exploiting a thin-film-transistor (TFT)-based image sensor array that saves ~12 hours compared to the Environmental Protection Agency (EPA)-approved methods. To demonstrate the efficacy of this CFU detection system, a lensfree imaging modality was built using the TFT image sensor with a sample field-of-view of ~10 cm^2. Time-lapse images of bacterial colonies cultured on chromogenic agar plates were automatically collected at 5-minute intervals. Two deep neural networks were used to detect and count the growing colonies and identify their species. When blindly tested with 265 colonies of E. coli and other coliform bacteria (i.e., Citrobacter and Klebsiella pneumoniae), our system reached an average CFU detection rate of 97.3% at 9 hours of incubation and an average recovery rate of 91.6% at ~12 hours. This TFT-based sensor can be applied to various microbiological detection methods. Due to the large scalability, ultra-large field-of-view, and low cost of the TFT-based image sensors, this platform can be integrated with each agar plate to be tested and disposed of after the automated CFU count. The imaging field-of-view of this platform can be cost-effectively increased to >100 cm^2 to provide a massive throughput for CFU detection using, e.g., roll-to-roll manufacturing of TFTs as used in the flexible display industry.
Global Outliers Detection in Wireless Sensor Networks: A Novel Approach Integrating Time-Series Analysis, Entropy, and Random Forest-based Classification
Jul 21, 2021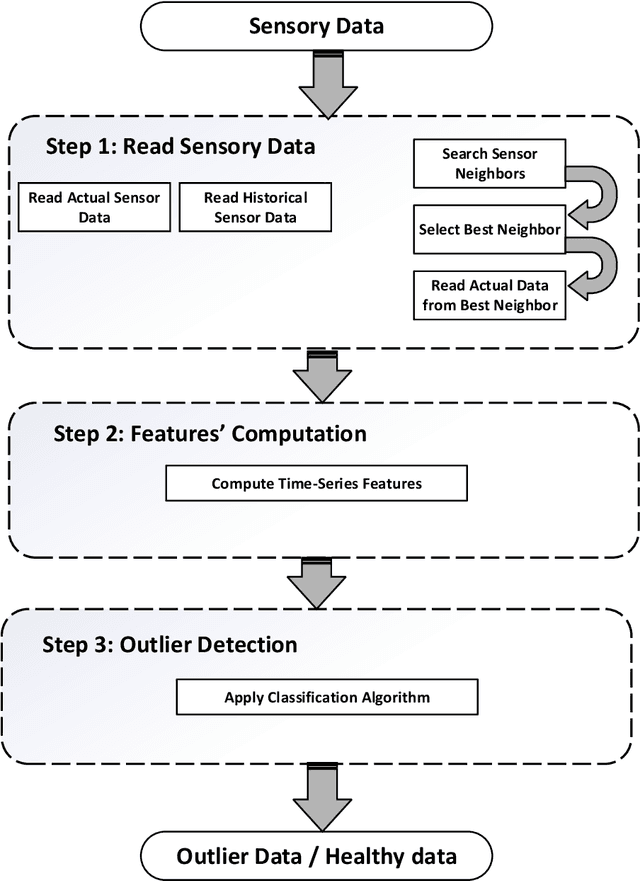
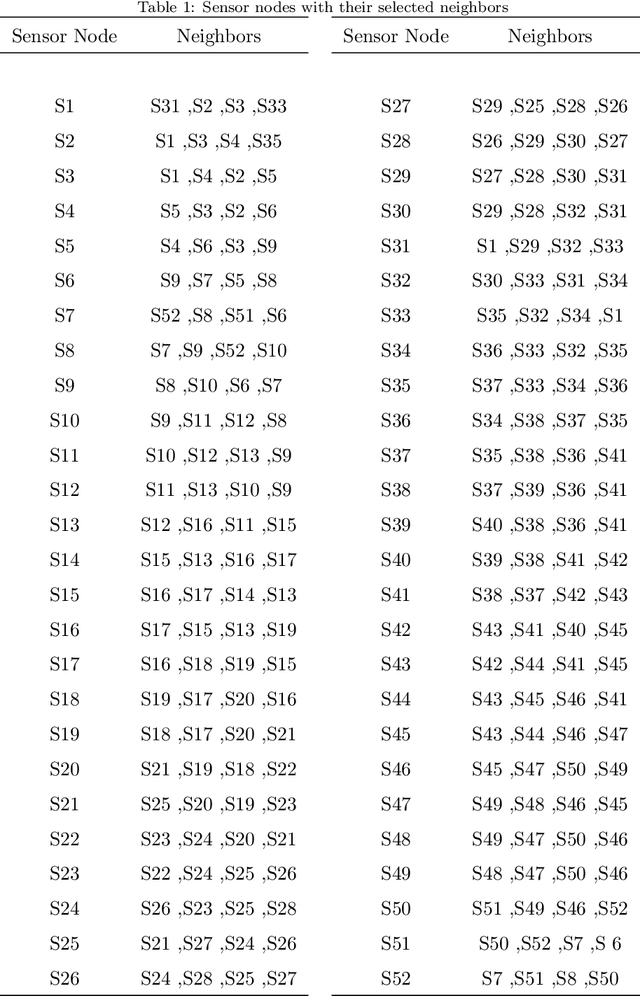
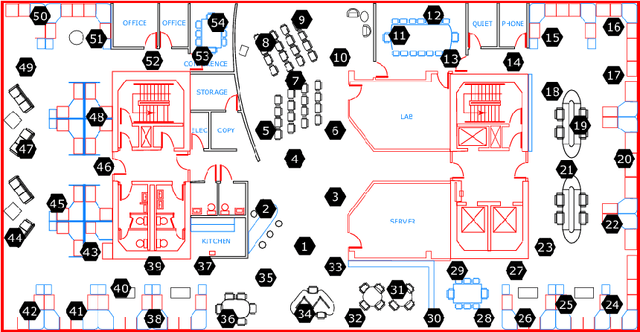
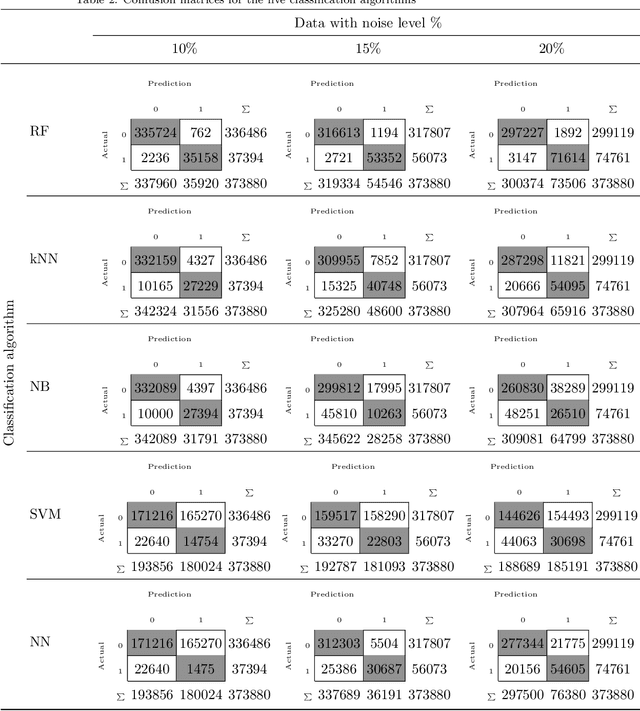
Wireless Sensor Networks (WSNs) have recently attracted greater attention worldwide due to their practicality in monitoring, communicating, and reporting specific physical phenomena. The data collected by WSNs is often inaccurate as a result of unavoidable environmental factors, which may include noise, signal weakness, or intrusion attacks depending on the specific situation. Sending high-noise data has negative effects not just on data accuracy and network reliability, but also regarding the decision-making processes in the base station. Anomaly detection, or outlier detection, is the process of detecting noisy data amidst the contexts thus described. The literature contains relatively few noise detection techniques in the context of WSNs, particularly for outlier-detection algorithms applying time series analysis, which considers the effective neighbors to ensure a global-collaborative detection. Hence, the research presented in this paper is intended to design and implement a global outlier-detection approach, which allows us to find and select appropriate neighbors to ensure an adaptive collaborative detection based on time-series analysis and entropy techniques. The proposed approach applies a random forest algorithm for identifying the best results. To measure the effectiveness and efficiency of the proposed approach, a comprehensive and real scenario provided by the Intel Berkeley Research lab has been simulated. Noisy data have been injected into the collected data randomly. The results obtained from the experiment then conducted experimentation demonstrate that our approach can detect anomalies with up to 99% accuracy.