 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multichannel Speech Separation with Narrow-band Conformer
Apr 09, 2022
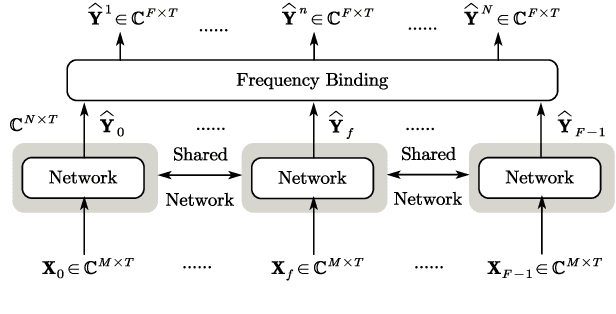
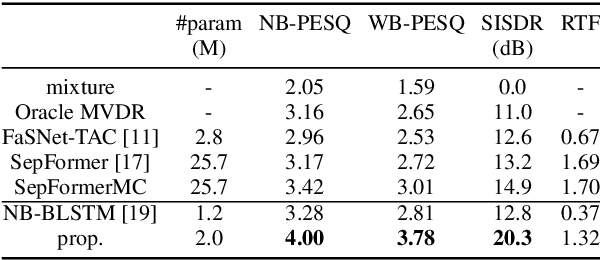
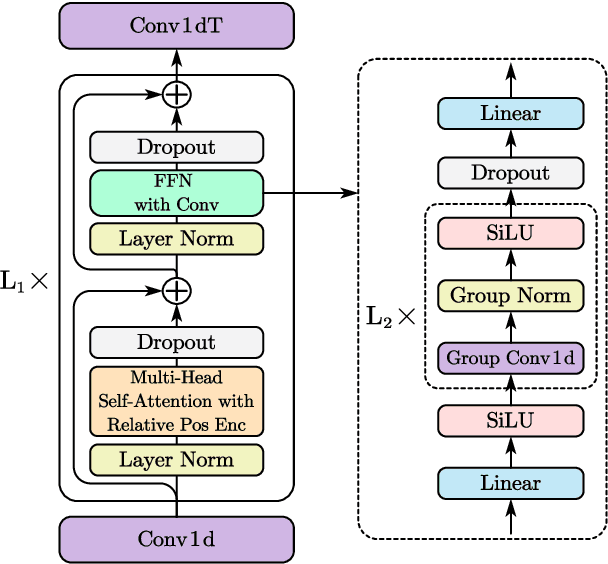
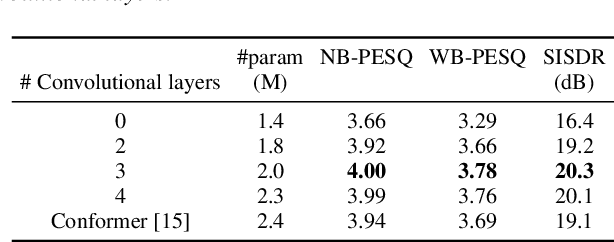
This work proposes a multichannel speech separation method with narrow-band Conformer (named NBC). The network is trained to learn to automatically exploit narrow-band speech separation information, such as spatial vector clustering of multiple speakers. Specifically, in the short-time Fourier transform (STFT) domain, the network processes each frequency independently, and is shared by all frequencies. For one frequency, the network inputs the STFT coefficients of multichannel mixture signals, and predicts the STFT coefficients of separated speech signals. Clustering of spatial vectors shares a similar principle with the self-attention mechanism in the sense of computing the similarity of vectors and then aggregating similar vectors. Therefore, Conformer would be especially suitable for the present problem. Experiments show that the proposed narrow-band Conformer achieves better speech separation performance than other state-of-the-art methods by a large margin.
MILES: Visual BERT Pre-training with Injected Language Semantics for Video-text Retrieval
Apr 26, 2022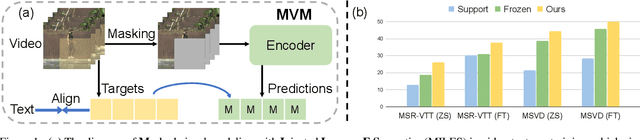
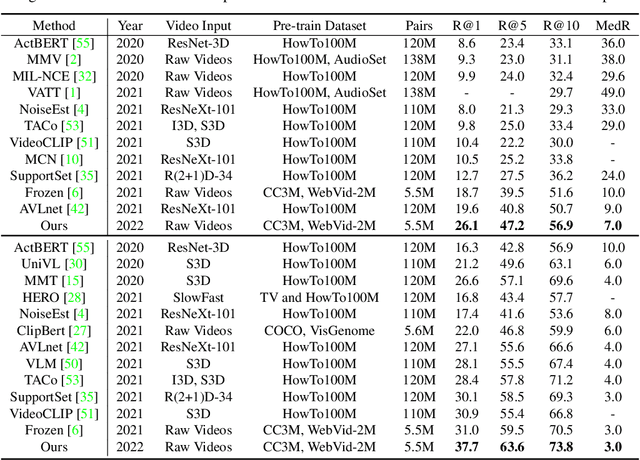
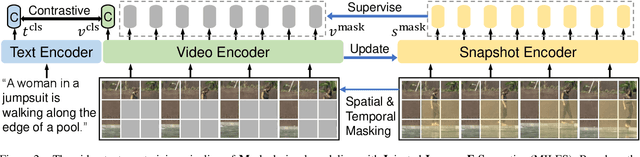
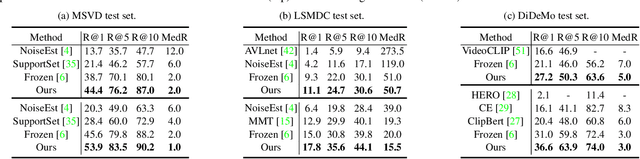
Dominant pre-training work for video-text retrieval mainly adopt the "dual-encoder" architectures to enable efficient retrieval, where two separate encoders are used to contrast global video and text representations, but ignore detailed local semantics. The recent success of image BERT pre-training with masked visual modeling that promotes the learning of local visual context, motivates a possible solution to address the above limitation. In this work, we for the first time investigate masked visual modeling in video-text pre-training with the "dual-encoder" architecture. We perform Masked visual modeling with Injected LanguagE Semantics (MILES) by employing an extra snapshot video encoder as an evolving "tokenizer" to produce reconstruction targets for masked video patch prediction. Given the corrupted video, the video encoder is trained to recover text-aligned features of the masked patches via reasoning with the visible regions along the spatial and temporal dimensions, which enhances the discriminativeness of local visual features and the fine-grained cross-modality alignment. Our method outperforms state-of-the-art methods for text-to-video retrieval on four datasets with both zero-shot and fine-tune evaluation protocols. Our approach also surpasses the baseline models significantly on zero-shot action recognition, which can be cast as video-to-text retrieval.
A novel evolutionary-based neuro-fuzzy task scheduling approach to jointly optimize the main design challenges of heterogeneous MPSoCs
Mar 14, 2022

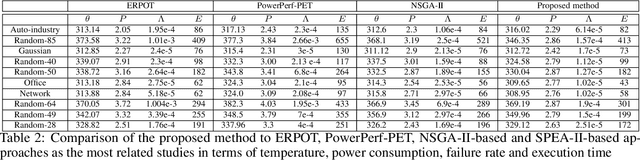
In this paper, an online task scheduling and mapping method based on a fuzzy neural network (FNN) learned by an evolutionary multi-objective algorithm (NSGA-II) to jointly optimize the main design challenges of heterogeneous MPSoCs is proposed. In this approach, first, the FNN parameters are trained using an NSGA-II-based optimization engine by considering the main design challenges of MPSoCs including temperature, power consumption, failure rate, and execution time on a training dataset consisting of different application graphs of various sizes. Next, the trained FNN is employed as an online task scheduler to jointly optimize the main design challenges in heterogeneous MPSoCs. Due to the uncertainty in sensor measurements and the difference between computational models and reality, applying the fuzzy neural network is advantageous in online scheduling procedures. The performance of the method is compared with some previous heuristic, meta-heuristic, and rule-based approaches in several experiments. Based on these experiments our proposed method outperforms the related studies in optimizing all design criteria. Its improvement over related heuristic and meta-heuristic approaches are estimated 10.58% in temperature, 9.22% in power consumption, 39.14% in failure rate, and 12.06% in execution time, averagely. Moreover, considering the interpretable nature of the FNN, the frequently fired extracted fuzzy rules of the proposed approach are demonstrated.
An Online Approach to Solve the Dynamic Vehicle Routing Problem with Stochastic Trip Requests for Paratransit Services
Mar 31, 2022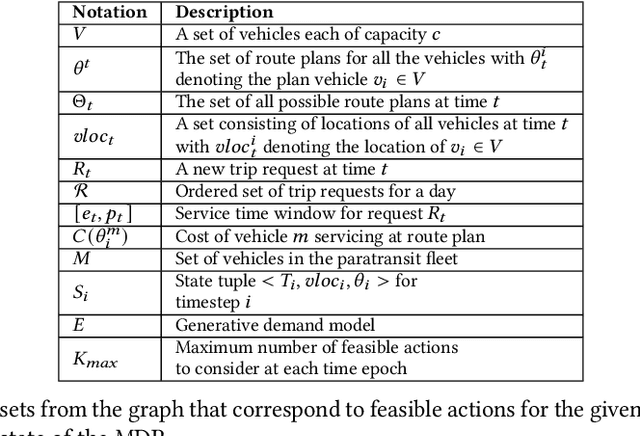
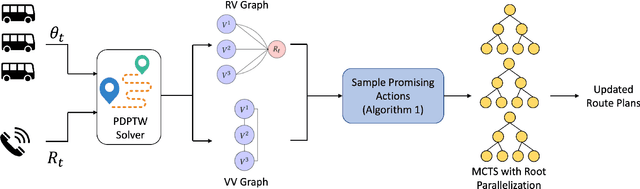
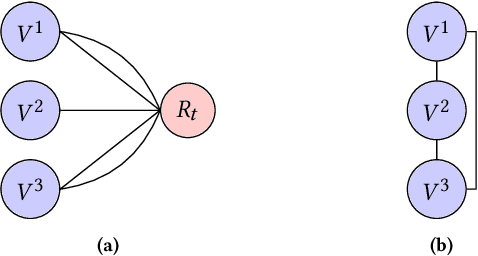
Many transit agencies operating paratransit and microtransit services have to respond to trip requests that arrive in real-time, which entails solving hard combinatorial and sequential decision-making problems under uncertainty. To avoid decisions that lead to significant inefficiency in the long term, vehicles should be allocated to requests by optimizing a non-myopic utility function or by batching requests together and optimizing a myopic utility function. While the former approach is typically offline, the latter can be performed online. We point out two major issues with such approaches when applied to paratransit services in practice. First, it is difficult to batch paratransit requests together as they are temporally sparse. Second, the environment in which transit agencies operate changes dynamically (e.g., traffic conditions), causing estimates that are learned offline to become stale. To address these challenges, we propose a fully online approach to solve the dynamic vehicle routing problem (DVRP) with time windows and stochastic trip requests that is robust to changing environmental dynamics by construction. We focus on scenarios where requests are relatively sparse - our problem is motivated by applications to paratransit services. We formulate DVRP as a Markov decision process and use Monte Carlo tree search to evaluate actions for any given state. Accounting for stochastic requests while optimizing a non-myopic utility function is computationally challenging; indeed, the action space for such a problem is intractably large in practice. To tackle the large action space, we leverage the structure of the problem to design heuristics that can sample promising actions for the tree search. Our experiments using real-world data from our partner agency show that the proposed approach outperforms existing state-of-the-art approaches both in terms of performance and robustness.
UniTE -- The Best of Both Worlds: Unifying Function-Fitting and Aggregation-Based Approaches to Travel Time and Travel Speed Estimation
Apr 27, 2021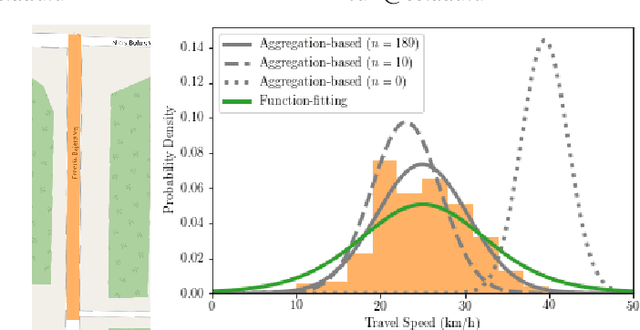
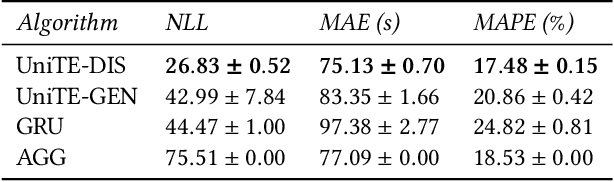
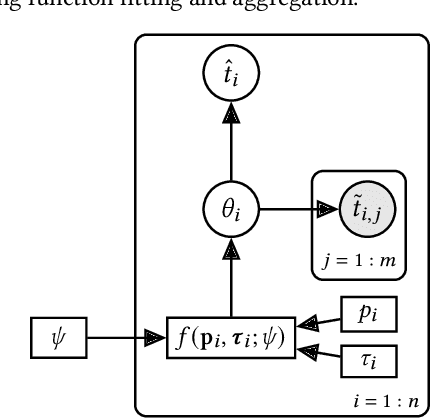
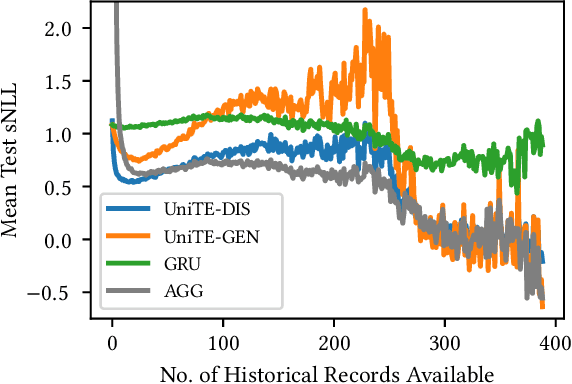
Travel time or speed estimation are part of many intelligent transportation applications. Existing estimation approaches rely on either function fitting or aggregation and represent different trade-offs between generalizability and accuracy. Function-fitting approaches learn functions that map feature vectors of, e.g., routes, to travel time or speed estimates, which enables generalization to unseen routes. However, mapping functions are imperfect and offer poor accuracy in practice. Aggregation-based approaches instead form estimates by aggregating historical data, e.g., traversal data for routes. This enables very high accuracy given sufficient data. However, they rely on simplistic heuristics when insufficient data is available, yielding poor generalizability. We present a Unifying approach to Travel time and speed Estimation (UniTE) that combines function-fitting and aggregation-based approaches into a unified framework that aims to achieve the generalizability of function-fitting approaches and the accuracy of aggregation-based approaches. An empirical study finds that an instance of UniTE can improve the accuracies of travel speed distribution and travel time estimation by $40-64\%$ and $3-23\%$, respectively, compared to using function fitting or aggregation alone
Progressive Distillation for Fast Sampling of Diffusion Models
Feb 01, 2022

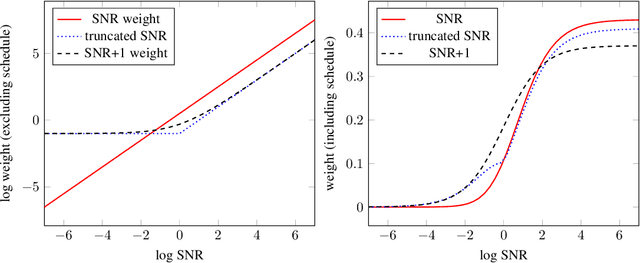
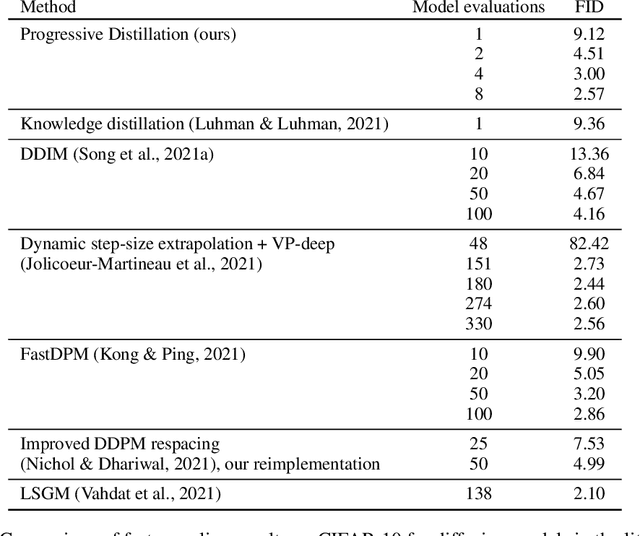
Diffusion models have recently shown great promise for generative modeling, outperforming GANs on perceptual quality and autoregressive models at density estimation. A remaining downside is their slow sampling time: generating high quality samples takes many hundreds or thousands of model evaluations. Here we make two contributions to help eliminate this downside: First, we present new parameterizations of diffusion models that provide increased stability when using few sampling steps. Second, we present a method to distill a trained deterministic diffusion sampler, using many steps, into a new diffusion model that takes half as many sampling steps. We then keep progressively applying this distillation procedure to our model, halving the number of required sampling steps each time. On standard image generation benchmarks like CIFAR-10, ImageNet, and LSUN, we start out with state-of-the-art samplers taking as many as 8192 steps, and are able to distill down to models taking as few as 4 steps without losing much perceptual quality; achieving, for example, a FID of 3.0 on CIFAR-10 in 4 steps. Finally, we show that the full progressive distillation procedure does not take more time than it takes to train the original model, thus representing an efficient solution for generative modeling using diffusion at both train and test time.
Open vs Closed-ended questions in attitudinal surveys -- comparing, combining, and interpreting using natural language processing
May 03, 2022
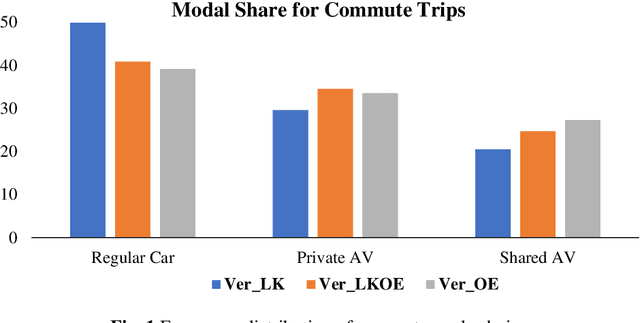
To improve the traveling experience, researchers have been analyzing the role of attitudes in travel behavior modeling. Although most researchers use closed-ended surveys, the appropriate method to measure attitudes is debatable. Topic Modeling could significantly reduce the time to extract information from open-ended responses and eliminate subjective bias, thereby alleviating analyst concerns. Our research uses Topic Modeling to extract information from open-ended questions and compare its performance with closed-ended responses. Furthermore, some respondents might prefer answering questions using their preferred questionnaire type. So, we propose a modeling framework that allows respondents to use their preferred questionnaire type to answer the survey and enable analysts to use the modeling frameworks of their choice to predict behavior. We demonstrate this using a dataset collected from the USA that measures the intention to use Autonomous Vehicles for commute trips. Respondents were presented with alternative questionnaire versions (open- and closed- ended). Since our objective was also to compare the performance of alternative questionnaire versions, the survey was designed to eliminate influences resulting from statements, behavioral framework, and the choice experiment. Results indicate the suitability of using Topic Modeling to extract information from open-ended responses; however, the models estimated using the closed-ended questions perform better compared to them. Besides, the proposed model performs better compared to the models used currently. Furthermore, our proposed framework will allow respondents to choose the questionnaire type to answer, which could be particularly beneficial to them when using voice-based surveys.
AutoMLBench: A Comprehensive Experimental Evaluation of Automated Machine Learning Frameworks
Apr 18, 2022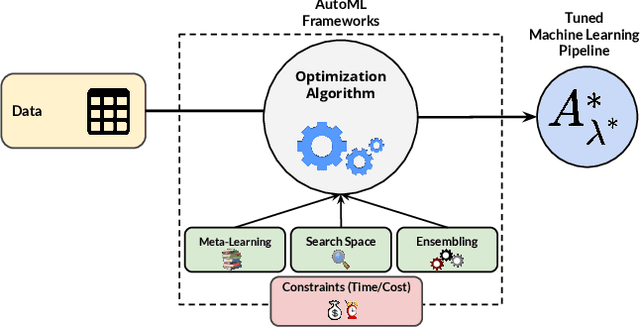
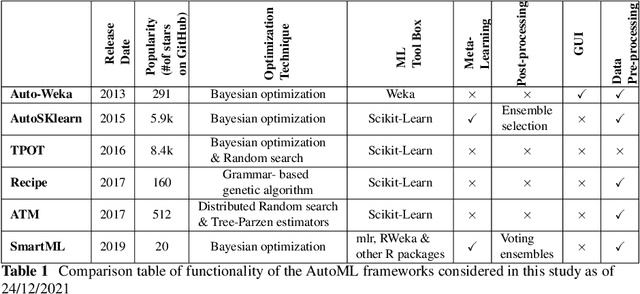
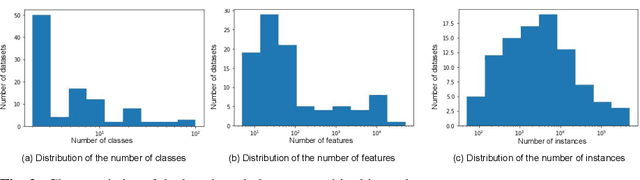
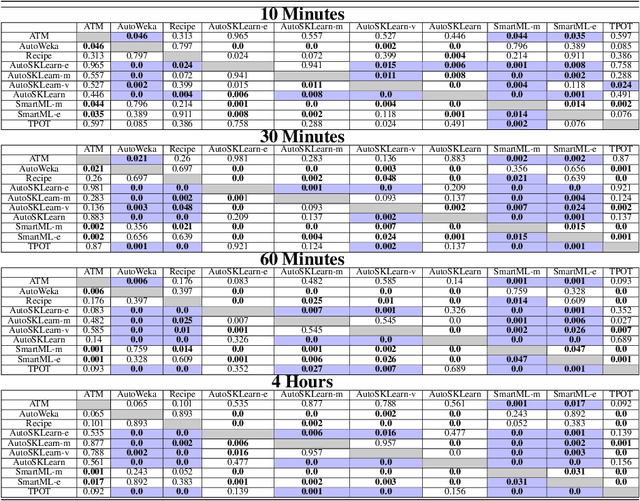
Nowadays, machine learning is playing a crucial role in harnessing the power of the massive amounts of data that we are currently producing every day in our digital world. With the booming demand for machine learning applications, it has been recognized that the number of knowledgeable data scientists can not scale with the growing data volumes and application needs in our digital world. In response to this demand, several automated machine learning (AutoML) techniques and frameworks have been developed to fill the gap of human expertise by automating the process of building machine learning pipelines. In this study, we present a comprehensive evaluation and comparison of the performance characteristics of six popular AutoML frameworks, namely, Auto-Weka, AutoSKlearn, TPOT, Recipe, ATM, and SmartML across 100 data sets from established AutoML benchmark suites. Our experimental evaluation considers different aspects for its comparison including the performance impact of several design decisions including time budget, size of search space, meta-learning, and ensemble construction. The results of our study reveal various interesting insights that can significantly guide and impact the design of AutoML frameworks.
Combining Time-Dependent Force Perturbations in Robot-Assisted Surgery Training
May 09, 2021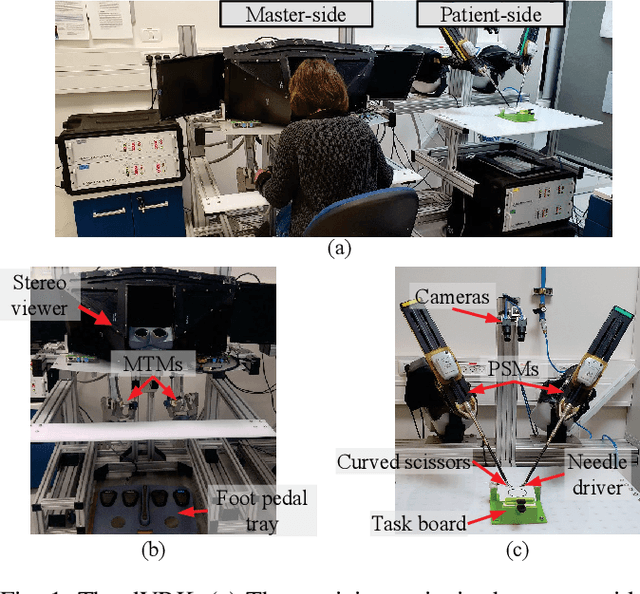
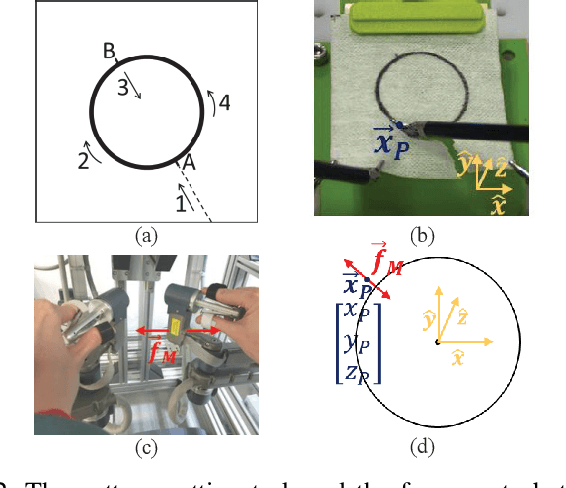
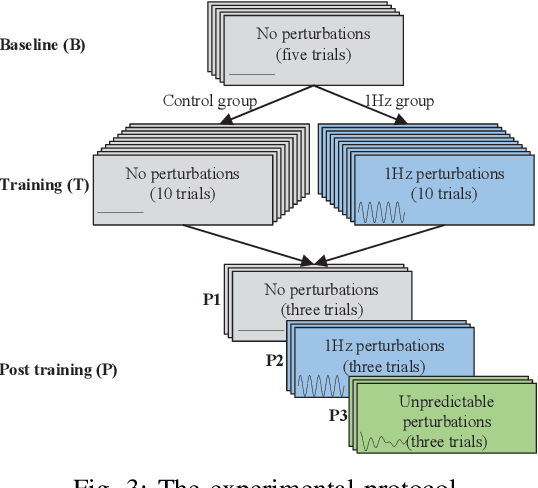

Teleoperated robot-assisted minimally-invasive surgery (RAMIS) offers many advantages over open surgery. However, there are still no guidelines for training skills in RAMIS. Motor learning theories have the potential to improve the design of RAMIS training but they are based on simple movements that do not resemble the complex movements required in surgery. To fill this gap, we designed an experiment to investigate the effect of time-dependent force perturbations on the learning of a pattern-cutting surgical task. Thirty participants took part in the experiment: (1) a control group that trained without perturbations, and (2) a 1Hz group that trained with 1Hz periodic force perturbations that pushed each participant's hand inwards and outwards in the radial direction. We monitored their learning using four objective metrics and found that participants in the 1Hz group learned how to overcome the perturbations and improved their performances during training without impairing their performances after the perturbations were removed. Our results present an important step toward understanding the effect of adding perturbations to RAMIS training protocols and improving RAMIS training for the benefit of surgeons and patients.
Time-Series Imputation with Wasserstein Interpolation for Optimal Look-Ahead-Bias and Variance Tradeoff
Feb 25, 2021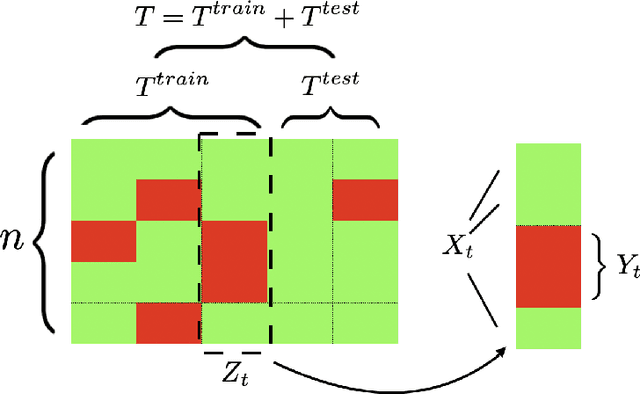
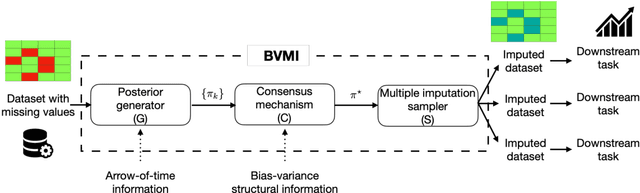
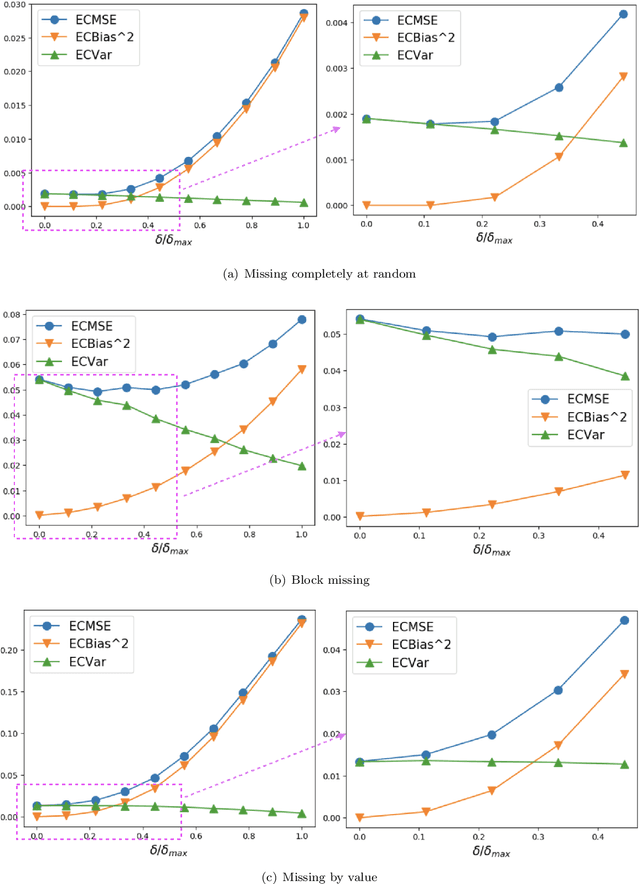
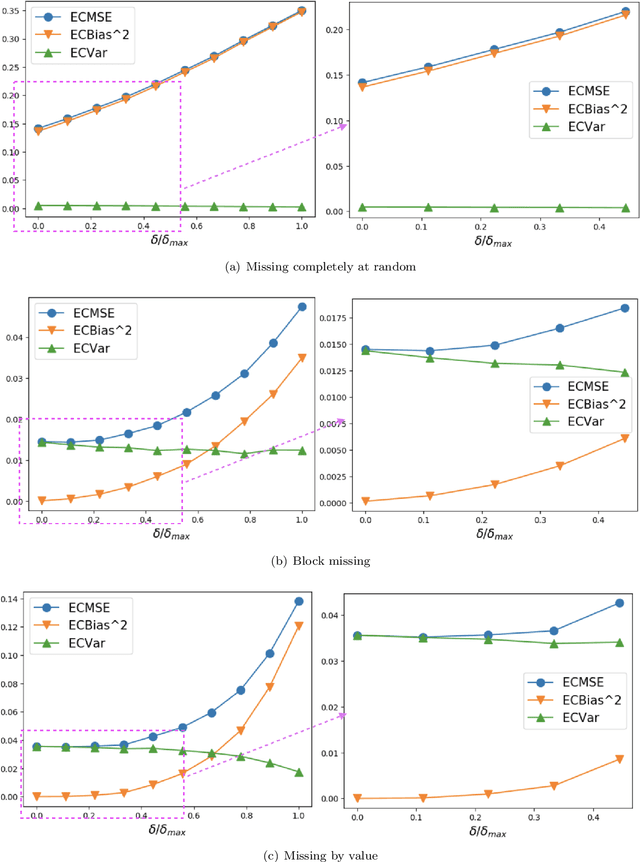
Missing time-series data is a prevalent practical problem. Imputation methods in time-series data often are applied to the full panel data with the purpose of training a model for a downstream out-of-sample task. For example, in finance, imputation of missing returns may be applied prior to training a portfolio optimization model. Unfortunately, this practice may result in a look-ahead-bias in the future performance on the downstream task. There is an inherent trade-off between the look-ahead-bias of using the full data set for imputation and the larger variance in the imputation from using only the training data. By connecting layers of information revealed in time, we propose a Bayesian posterior consensus distribution which optimally controls the variance and look-ahead-bias trade-off in the imputation. We demonstrate the benefit of our methodology both in synthetic and real financial data.