 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Wind power predictions from nowcasts to 4-hour forecasts: a learning approach with variable selection
Apr 20, 2022

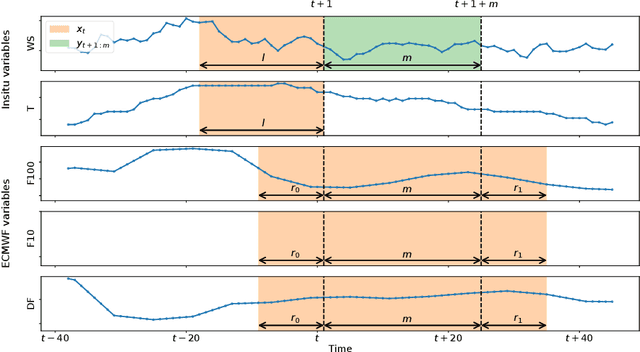
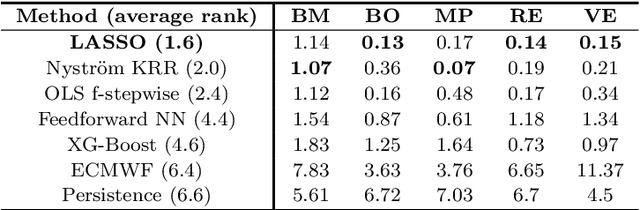
We study the prediction of short term wind speed and wind power (every 10 minutes up to 4 hours ahead). Accurate forecasts for those quantities are crucial to mitigate the negative effects of wind farms' intermittent production on energy systems and markets. For those time scales, outputs of numerical weather prediction models are usually overlooked even though they should provide valuable information on higher scales dynamics. In this work, we combine those outputs with local observations using machine learning. So as to make the results usable for practitioners, we focus on simple and well known methods which can handle a high volume of data. We study first variable selection through two simple techniques, a linear one and a nonlinear one. Then we exploit those results to forecast wind speed and wind power still with an emphasis on linear models versus nonlinear ones. For the wind power prediction, we also compare the indirect approach (wind speed predictions passed through a power curve) and the indirect one (directly predict wind power).
OutCast: Outdoor Single-image Relighting with Cast Shadows
Apr 20, 2022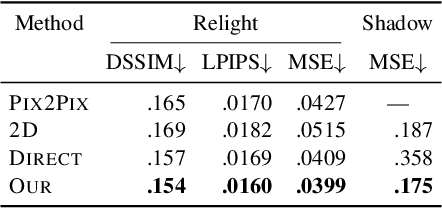
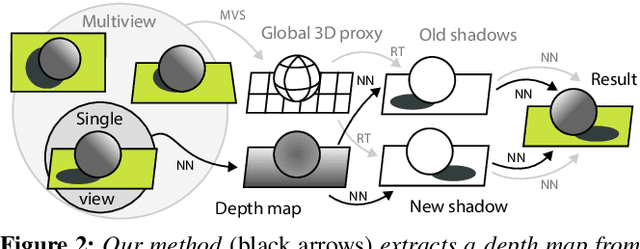
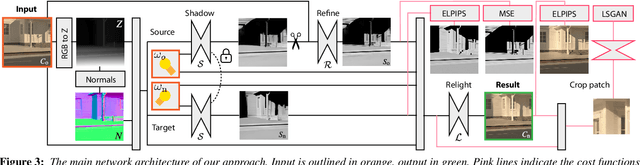
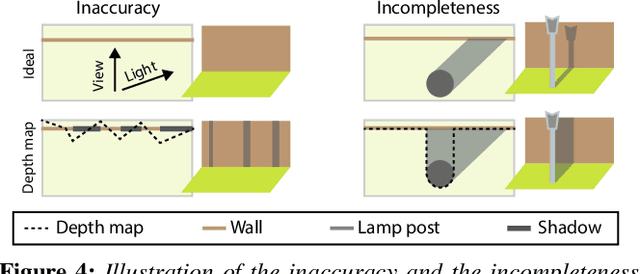
We propose a relighting method for outdoor images. Our method mainly focuses on predicting cast shadows in arbitrary novel lighting directions from a single image while also accounting for shading and global effects such the sun light color and clouds. Previous solutions for this problem rely on reconstructing occluder geometry, e.g. using multi-view stereo, which requires many images of the scene. Instead, in this work we make use of a noisy off-the-shelf single-image depth map estimation as a source of geometry. Whilst this can be a good guide for some lighting effects, the resulting depth map quality is insufficient for directly ray-tracing the shadows. Addressing this, we propose a learned image space ray-marching layer that converts the approximate depth map into a deep 3D representation that is fused into occlusion queries using a learned traversal. Our proposed method achieves, for the first time, state-of-the-art relighting results, with only a single image as input. For supplementary material visit our project page at: https://dgriffiths.uk/outcast.
Federated Learning in Multi-Center Critical Care Research: A Systematic Case Study using the eICU Database
Apr 20, 2022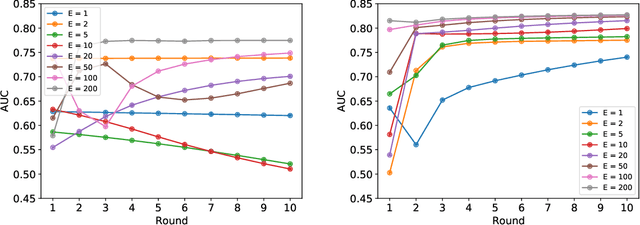
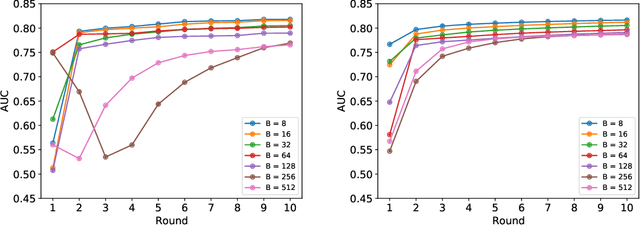
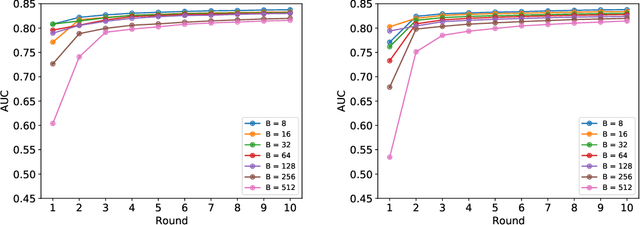
Federated learning (FL) has been proposed as a method to train a model on different units without exchanging data. This offers great opportunities in the healthcare sector, where large datasets are available but cannot be shared to ensure patient privacy. We systematically investigate the effectiveness of FL on the publicly available eICU dataset for predicting the survival of each ICU stay. We employ Federated Averaging as the main practical algorithm for FL and show how its performance changes by altering three key hyper-parameters, taking into account that clients can significantly vary in size. We find that in many settings, a large number of local training epochs improves the performance while at the same time reducing communication costs. Furthermore, we outline in which settings it is possible to have only a low number of hospitals participating in each federated update round. When many hospitals with low patient counts are involved, the effect of overfitting can be avoided by decreasing the batchsize. This study thus contributes toward identifying suitable settings for running distributed algorithms such as FL on clinical datasets.
Unbiased Estimation of the Gradient of the Log-Likelihood for a Class of Continuous-Time State-Space Models
May 24, 2021
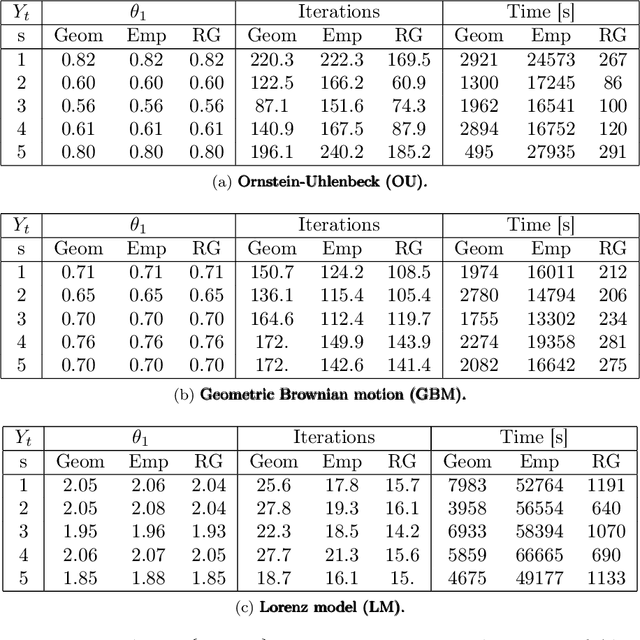
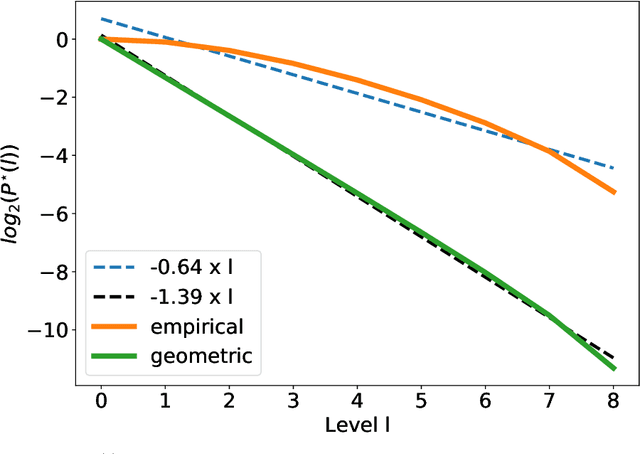
In this paper, we consider static parameter estimation for a class of continuous-time state-space models. Our goal is to obtain an unbiased estimate of the gradient of the log-likelihood (score function), which is an estimate that is unbiased even if the stochastic processes involved in the model must be discretized in time. To achieve this goal, we apply a \emph{doubly randomized scheme} (see, e.g.,~\cite{ub_mcmc, ub_grad}), that involves a novel coupled conditional particle filter (CCPF) on the second level of randomization \cite{jacob2}. Our novel estimate helps facilitate the application of gradient-based estimation algorithms, such as stochastic-gradient Langevin descent. We illustrate our methodology in the context of stochastic gradient descent (SGD) in several numerical examples and compare with the Rhee \& Glynn estimator \cite{rhee,vihola}.
A Quadratic Programming Approach to Manipulation in Real-Time Using Modular Robots
Apr 06, 2021
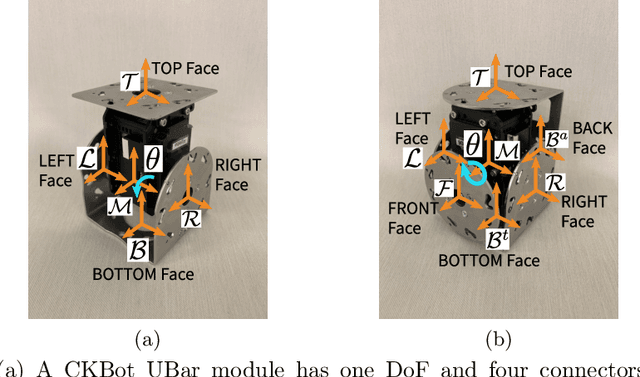
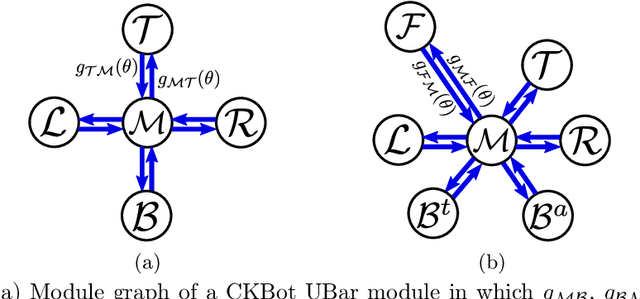

Motion planning in high-dimensional space is a challenging task. In order to perform dexterous manipulation in an unstructured environment, a robot with many degrees of freedom is usually necessary, which also complicates its motion planning problem. Real-time control brings about more difficulties in which robots have to maintain the stability while moving towards the target. Redundant systems are common in modular robots that consist of multiple modules and are able to transformed into different configurations with respect to different needs. Different from robots with fixed geometry or configurations, the kinematics model of a modular robotic system can alter as the robot reconfigures itself, and developing a generic control and motion planning approach for such systems is difficult, especially when multiple motion goals are coupled. A new manipulation planning framework is developed in this paper. The problem is formulated as a sequential linearly constrained quadratic program (QP) that can be solved efficiently. Some constraints can be incorporated into this QP, including a novel way to approximate environment obstacles. This solution can be used directly for real-time applications or as an off-line planning tool, and it is validated and demonstrated on the CKBot and SMORES-EP modular robot platforms.
Revisiting Multi-Scale Feature Fusion for Semantic Segmentation
Mar 23, 2022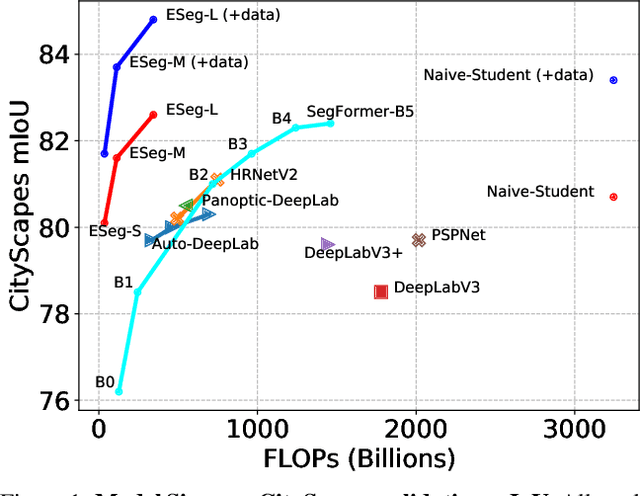

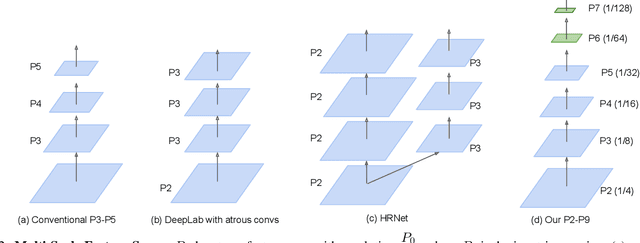
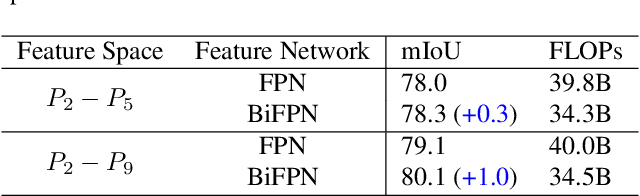
It is commonly believed that high internal resolution combined with expensive operations (e.g. atrous convolutions) are necessary for accurate semantic segmentation, resulting in slow speed and large memory usage. In this paper, we question this belief and demonstrate that neither high internal resolution nor atrous convolutions are necessary. Our intuition is that although segmentation is a dense per-pixel prediction task, the semantics of each pixel often depend on both nearby neighbors and far-away context; therefore, a more powerful multi-scale feature fusion network plays a critical role. Following this intuition, we revisit the conventional multi-scale feature space (typically capped at P5) and extend it to a much richer space, up to P9, where the smallest features are only 1/512 of the input size and thus have very large receptive fields. To process such a rich feature space, we leverage the recent BiFPN to fuse the multi-scale features. Based on these insights, we develop a simplified segmentation model, named ESeg, which has neither high internal resolution nor expensive atrous convolutions. Perhaps surprisingly, our simple method can achieve better accuracy with faster speed than prior art across multiple datasets. In real-time settings, ESeg-Lite-S achieves 76.0% mIoU on CityScapes [12] at 189 FPS, outperforming FasterSeg [9] (73.1% mIoU at 170 FPS). Our ESeg-Lite-L runs at 79 FPS and achieves 80.1% mIoU, largely closing the gap between real-time and high-performance segmentation models.
GRAND+: Scalable Graph Random Neural Networks
Mar 12, 2022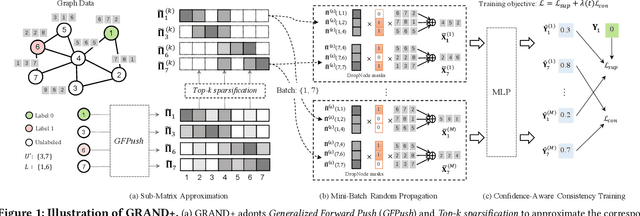
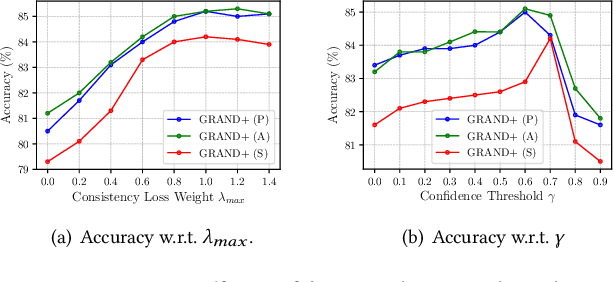
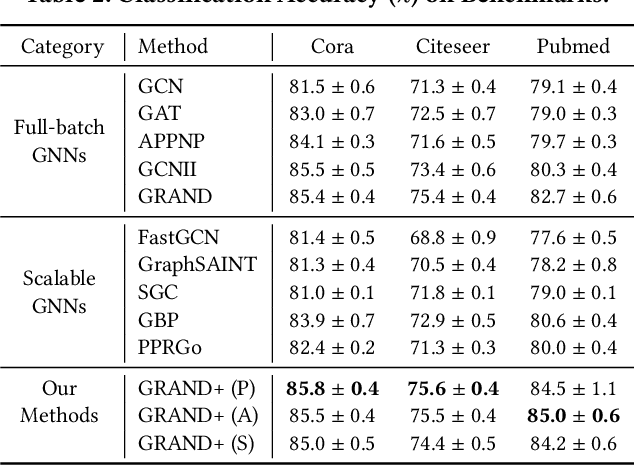
Graph neural networks (GNNs) have been widely adopted for semi-supervised learning on graphs. A recent study shows that the graph random neural network (GRAND) model can generate state-of-the-art performance for this problem. However, it is difficult for GRAND to handle large-scale graphs since its effectiveness relies on computationally expensive data augmentation procedures. In this work, we present a scalable and high-performance GNN framework GRAND+ for semi-supervised graph learning. To address the above issue, we develop a generalized forward push (GFPush) algorithm in GRAND+ to pre-compute a general propagation matrix and employ it to perform graph data augmentation in a mini-batch manner. We show that both the low time and space complexities of GFPush enable GRAND+ to efficiently scale to large graphs. Furthermore, we introduce a confidence-aware consistency loss into the model optimization of GRAND+, facilitating GRAND+'s generalization superiority. We conduct extensive experiments on seven public datasets of different sizes. The results demonstrate that GRAND+ 1) is able to scale to large graphs and costs less running time than existing scalable GNNs, and 2) can offer consistent accuracy improvements over both full-batch and scalable GNNs across all datasets.
Measuring the False Sense of Security
Apr 10, 2022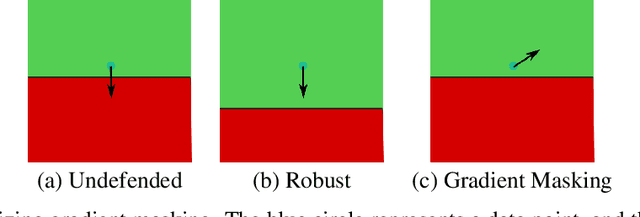
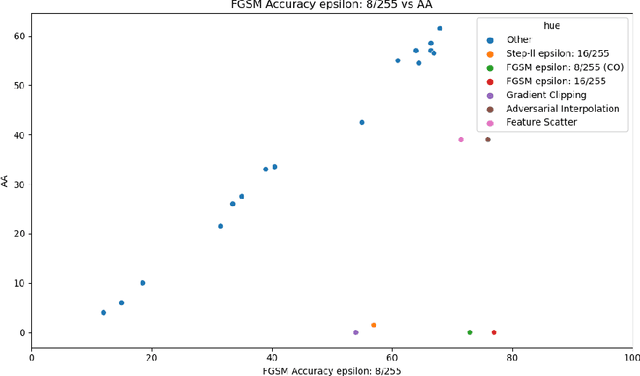
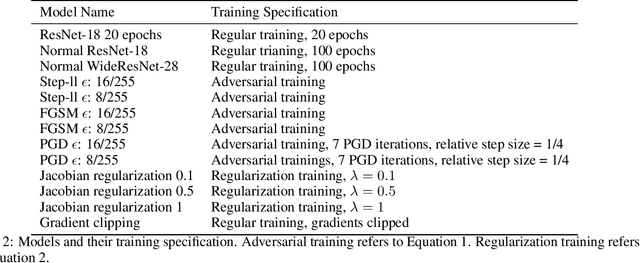
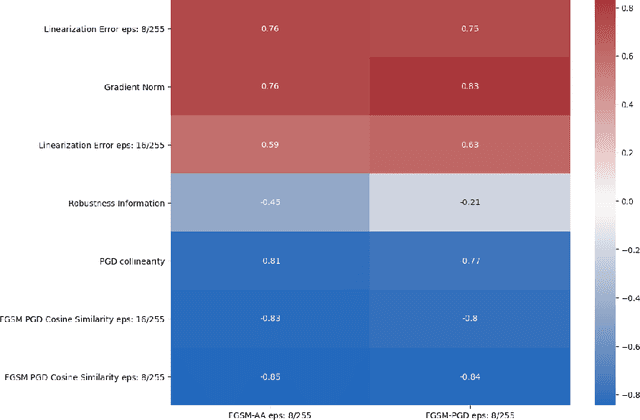
Recently, several papers have demonstrated how widespread gradient masking is amongst proposed adversarial defenses. Defenses that rely on this phenomenon are considered failed, and can easily be broken. Despite this, there has been little investigation into ways of measuring the phenomenon of gradient masking and enabling comparisons of its extent amongst different networks. In this work, we investigate gradient masking under the lens of its mensurability, departing from the idea that it is a binary phenomenon. We propose and motivate several metrics for it, performing extensive empirical tests on defenses suspected of exhibiting different degrees of gradient masking. These are computationally cheaper than strong attacks, enable comparisons between models, and do not require the large time investment of tailor-made attacks for specific models. Our results reveal metrics that are successful in measuring the extent of gradient masking across different networks
Exact methods and lower bounds for the Oven Scheduling Problem
Mar 23, 2022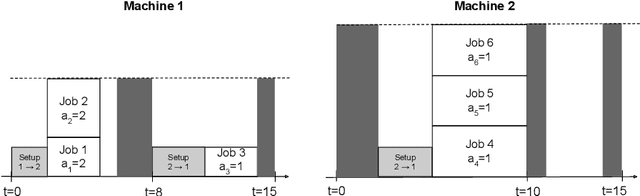
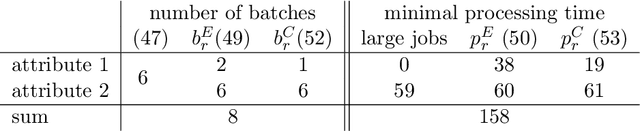
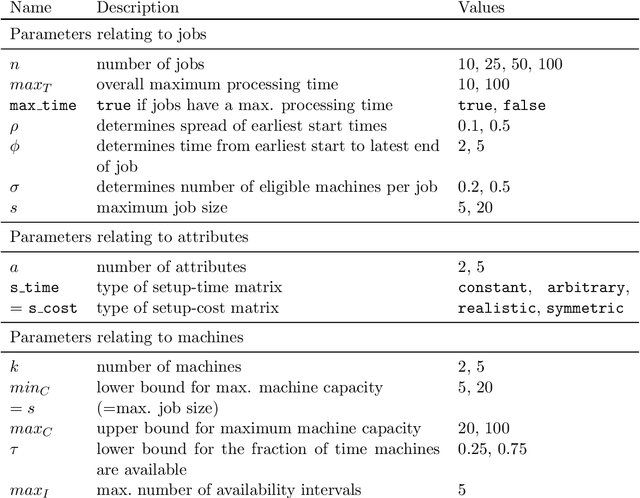
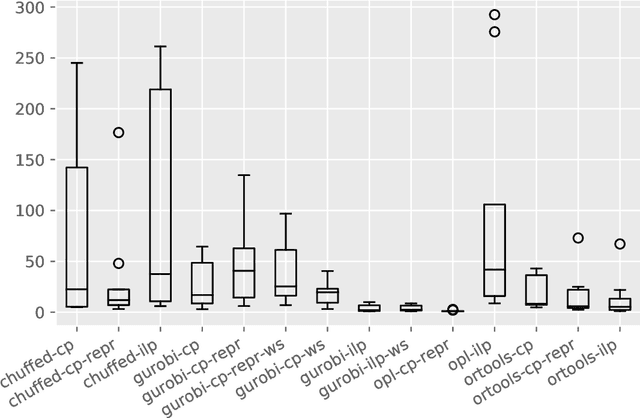
The Oven Scheduling Problem (OSP) is a new parallel batch scheduling problem that arises in the area of electronic component manufacturing. Jobs need to be scheduled to one of several ovens and may be processed simultaneously in one batch if they have compatible requirements. The scheduling of jobs must respect several constraints concerning eligibility and availability of ovens, release dates of jobs, setup times between batches as well as oven capacities. Running the ovens is highly energy-intensive and thus the main objective, besides finishing jobs on time, is to minimize the cumulative batch processing time across all ovens. This objective distinguishes the OSP from other batch processing problems which typically minimize objectives related to makespan, tardiness or lateness. We propose to solve this NP-hard scheduling problem via constraint programming (CP) and integer linear programming (ILP) and present corresponding models. For an experimental evaluation, we introduce a multi-parameter random instance generator to provide a diverse set of problem instances. Using state-of-the-art solvers, we evaluate the quality and compare the performance of our CP- and ILP-models. We show that our models can find feasible solutions for instances of realistic size, many of those being provably optimal or nearly optimal solutions. Finally, we derive theoretical lower bounds on the solution cost of feasible solutions to the OSP; these can be computed within a few seconds. We show that these lower bounds are competitive with those derived by state-of-the-art solvers.
Online Motion Style Transfer for Interactive Character Control
Mar 30, 2022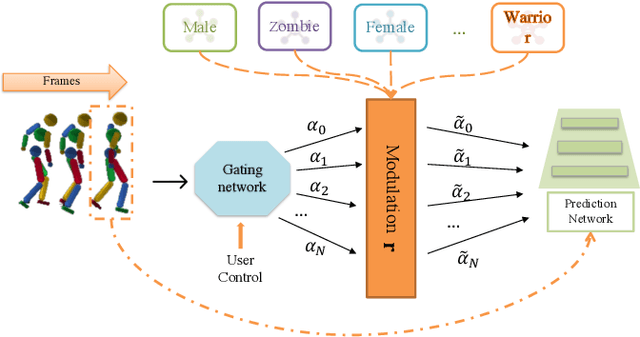
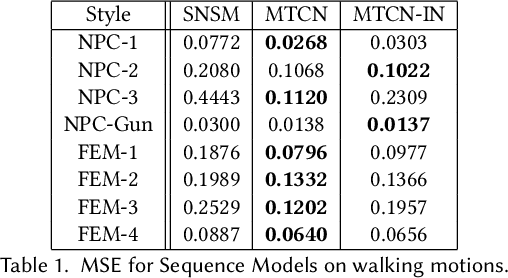
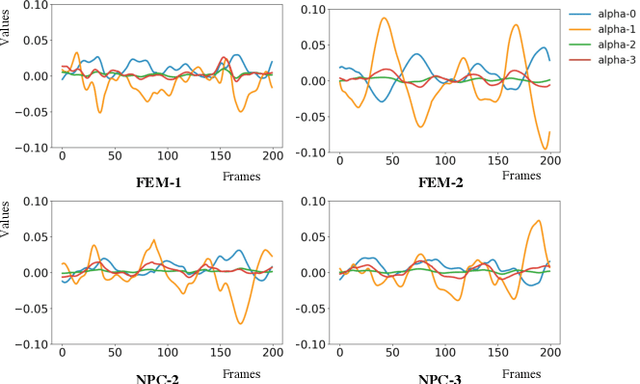
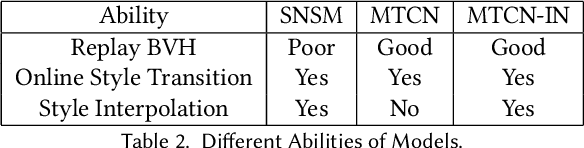
Motion style transfer is highly desired for motion generation systems for gaming. Compared to its offline counterpart, the research on online motion style transfer under interactive control is limited. In this work, we propose an end-to-end neural network that can generate motions with different styles and transfer motion styles in real-time under user control. Our approach eliminates the use of handcrafted phase features, and could be easily trained and directly deployed in game systems. In the experiment part, we evaluate our approach from three aspects that are essential for industrial game design: accuracy, flexibility, and variety, and our model performs a satisfying result.