 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semi-WTC: A Practical Semi-supervised Framework for Attack Categorization through Weight-Task Consistency
May 19, 2022
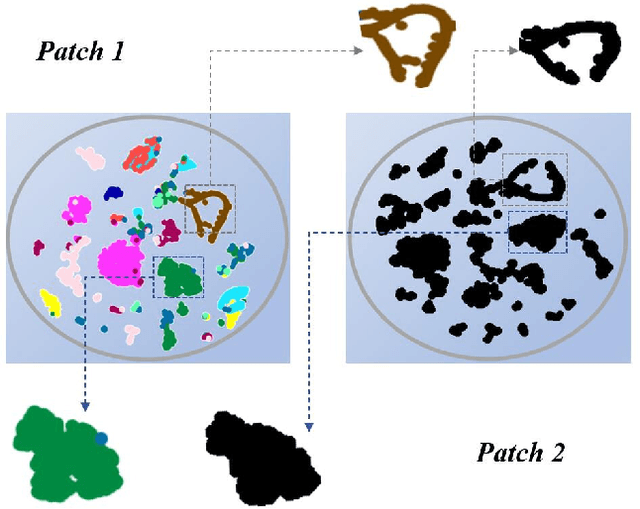

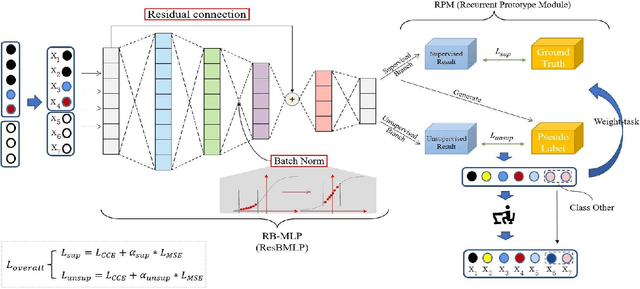
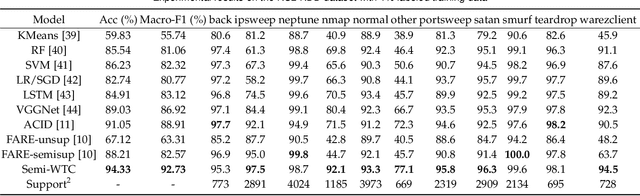
Supervised learning has been widely used for attack detection, which requires large amounts of high-quality data and labels. However, the data is often imbalanced and sufficient annotations are difficult to obtain. Moreover, these supervised models are subject to real-world deployment issues, such as defending against unseen artificial attacks. We propose a semi-supervised fine-grained attack categorization framework consisting of an encoder and a two-branch structure to integrate information from labeled and unlabeled data to tackle these practical challenges. This framework can be generalized to different supervised models. The multilayer perceptron with residual connection and batch normalization is used as the encoder to extract features and reduce the complexity. The Recurrent Prototype Module (RPM) is proposed to train the encoder effectively in a semi-supervised manner. To alleviate the problem of data imbalance, we introduce the Weight-Task Consistency (WTC) into the iterative process of RPM by assigning larger weights to classes with fewer samples in the loss function. In addition, to cope with new attacks in real-world deployment, we further propose an Active Adaption Resampling (AAR) method, which can better discover the distribution of the unseen sample data and adapt the parameters of the encoder. Experimental results show that our model outperforms the state-of-the-art semi-supervised attack detection methods with a general 5% improvement in classification accuracy and a 90% reduction in training time.
Long-term Visual Map Sparsification with Heterogeneous GNN
Mar 29, 2022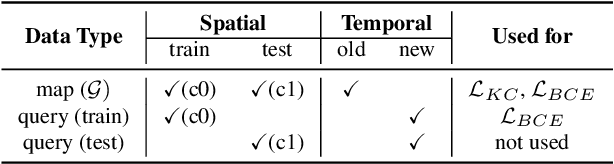
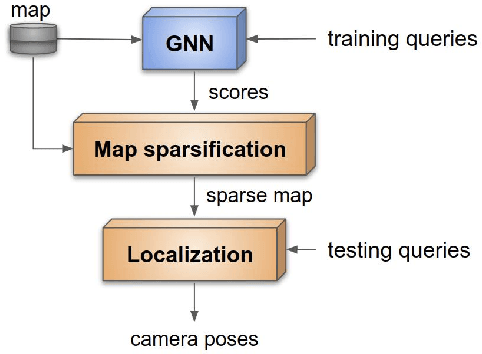
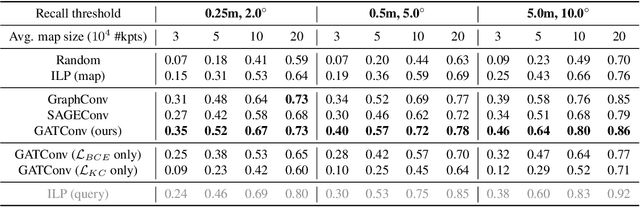
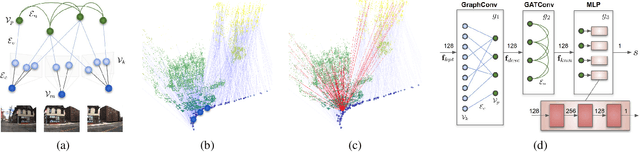
We address the problem of map sparsification for long-term visual localization. For map sparsification, a commonly employed assumption is that the pre-build map and the later captured localization query are consistent. However, this assumption can be easily violated in the dynamic world. Additionally, the map size grows as new data accumulate through time, causing large data overhead in the long term. In this paper, we aim to overcome the environmental changes and reduce the map size at the same time by selecting points that are valuable to future localization. Inspired by the recent progress in Graph Neural Network(GNN), we propose the first work that models SfM maps as heterogeneous graphs and predicts 3D point importance scores with a GNN, which enables us to directly exploit the rich information in the SfM map graph. Two novel supervisions are proposed: 1) a data-fitting term for selecting valuable points to future localization based on training queries; 2) a K-Cover term for selecting sparse points with full map coverage. The experiments show that our method selected map points on stable and widely visible structures and outperformed baselines in localization performance.
A Topological Approach for Semi-Supervised Learning
May 19, 2022


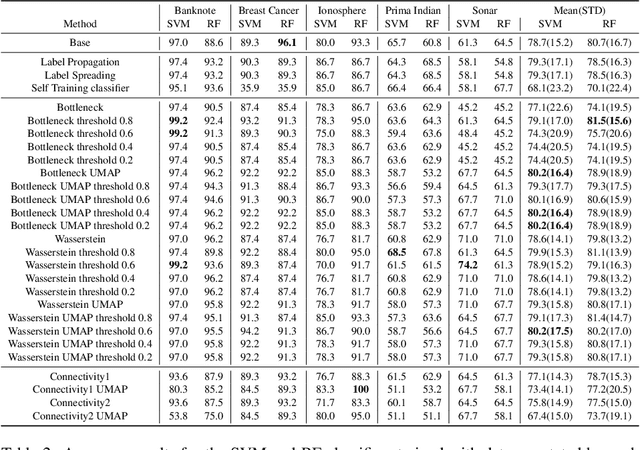
Nowadays, Machine Learning and Deep Learning methods have become the state-of-the-art approach to solve data classification tasks. In order to use those methods, it is necessary to acquire and label a considerable amount of data; however, this is not straightforward in some fields, since data annotation is time consuming and might require expert knowledge. This challenge can be tackled by means of semi-supervised learning methods that take advantage of both labelled and unlabelled data. In this work, we present new semi-supervised learning methods based on techniques from Topological Data Analysis (TDA), a field that is gaining importance for analysing large amounts of data with high variety and dimensionality. In particular, we have created two semi-supervised learning methods following two different topological approaches. In the former, we have used a homological approach that consists in studying the persistence diagrams associated with the data using the Bottleneck and Wasserstein distances. In the latter, we have taken into account the connectivity of the data. In addition, we have carried out a thorough analysis of the developed methods using 3 synthetic datasets, 5 structured datasets, and 2 datasets of images. The results show that the semi-supervised methods developed in this work outperform both the results obtained with models trained with only manually labelled data, and those obtained with classical semi-supervised learning methods, reaching improvements of up to a 16%.
Linear TDOA-based Measurements for Distributed Estimation and Localized Tracking
Apr 26, 2022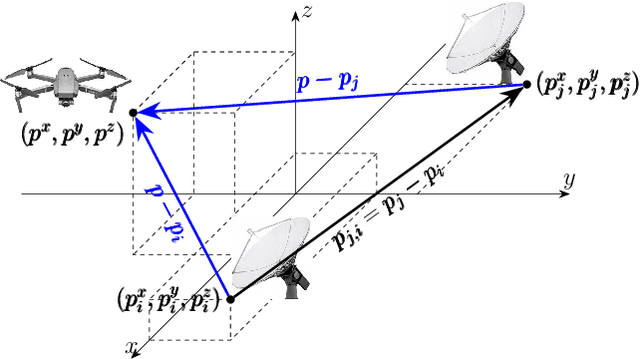
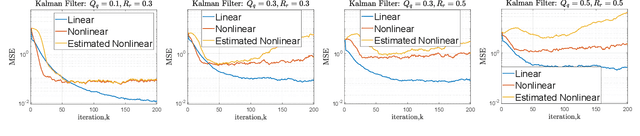
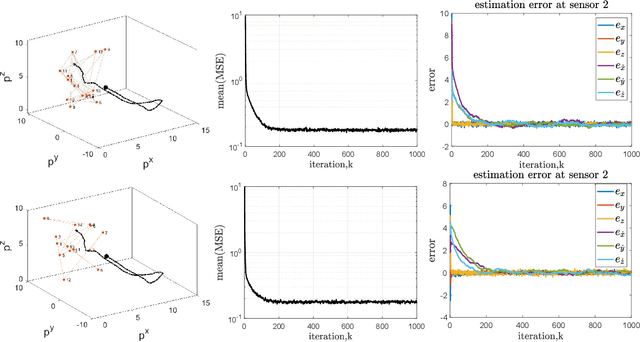

We propose a linear time-difference-of-arrival (TDOA) measurement model to improve \textit{distributed} estimation performance for localized target tracking. We design distributed filters over sparse (possibly large-scale) communication networks using consensus-based data-fusion techniques. The proposed distributed and localized tracking protocols considerably reduce the sensor network's required connectivity and communication rate. We, further, consider $\kappa$-redundant observability and fault-tolerant design in case of losing communication links or sensor nodes. We present the minimal conditions on the remaining sensor network (after link/node removal) such that the distributed observability is still preserved and, thus, the sensor network can track the (single) maneuvering target. The motivation is to reduce the communication load versus the processing load, as the computational units are, in general, less costly than the communication devices. We evaluate the tracking performance via simulations in MATLAB.
Do Time Constraints Re-Prioritize Attention to Shapes During Visual Photo Inspection?
Apr 14, 2021


People's visual experiences of the world are easy to carve up and examine along natural language boundaries, e.g., by category labels, attribute labels, etc. However, it is more difficult to elicit detailed visuospatial information about what a person attends to, e.g., the specific shape of a tree. Paying attention to the shapes of things not only feeds into well defined tasks like visual category learning, but it is also what enables us to differentiate similarly named objects and to take on creative visual pursuits, like poetically describing the shape of a thing, or finding shapes in the clouds or stars. We use a new data collection method that elicits people's prioritized attention to shapes during visual photo inspection by asking them to trace important parts of the image under varying time constraints. Using data collected via crowdsourcing over a set of 187 photographs, we examine changes in patterns of visual attention across individuals, across image types, and across time constraints.
Improving Source Separation by Explicitly Modeling Dependencies Between Sources
Mar 28, 2022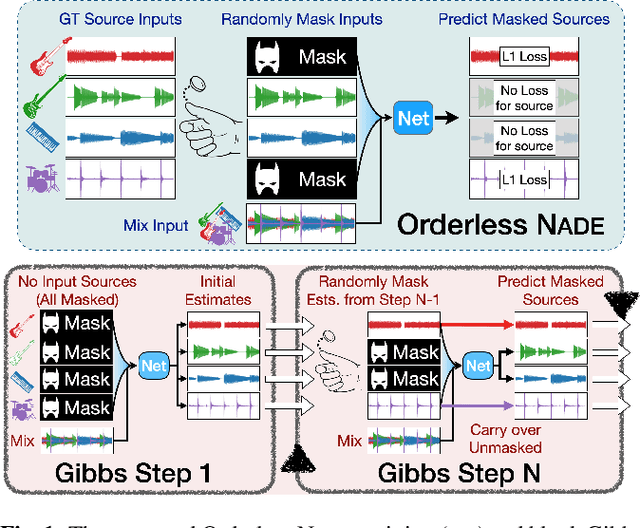
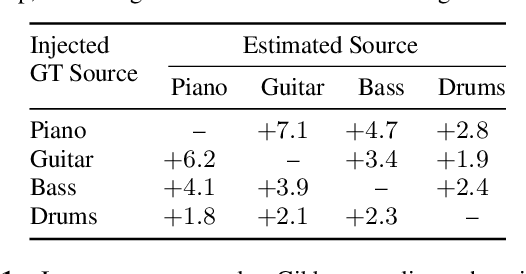
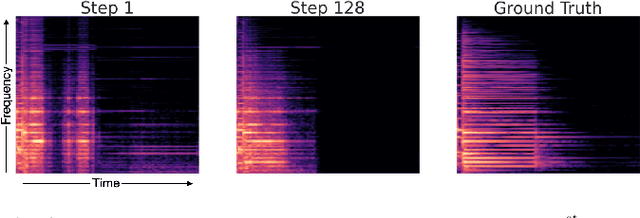
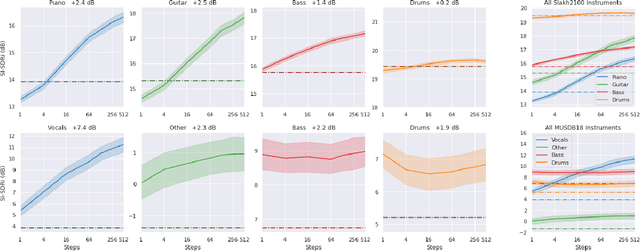
We propose a new method for training a supervised source separation system that aims to learn the interdependent relationships between all combinations of sources in a mixture. Rather than independently estimating each source from a mix, we reframe the source separation problem as an Orderless Neural Autoregressive Density Estimator (NADE), and estimate each source from both the mix and a random subset of the other sources. We adapt a standard source separation architecture, Demucs, with additional inputs for each individual source, in addition to the input mixture. We randomly mask these input sources during training so that the network learns the conditional dependencies between the sources. By pairing this training method with a block Gibbs sampling procedure at inference time, we demonstrate that the network can iteratively improve its separation performance by conditioning a source estimate on its earlier source estimates. Experiments on two source separation datasets show that training a Demucs model with an Orderless NADE approach and using Gibbs sampling (up to 512 steps) at inference time strongly outperforms a Demucs baseline that uses a standard regression loss and direct (one step) estimation of sources.
STC-mix: Space, Time, Channel mixing for Self-supervised Video Representation
Dec 07, 2021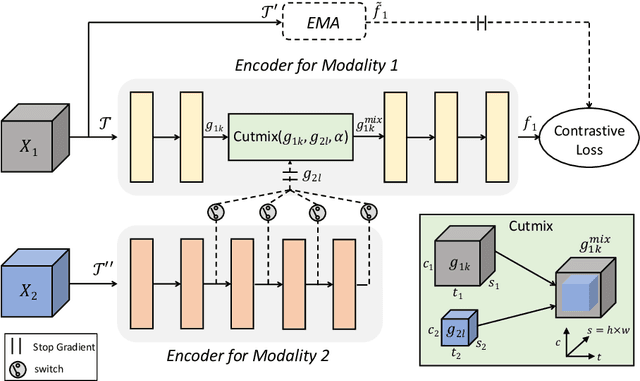
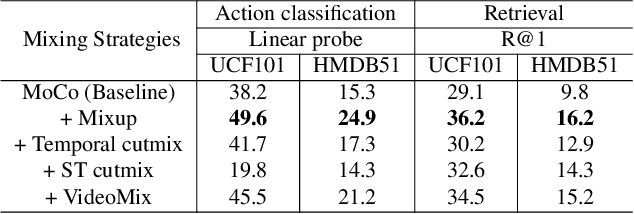
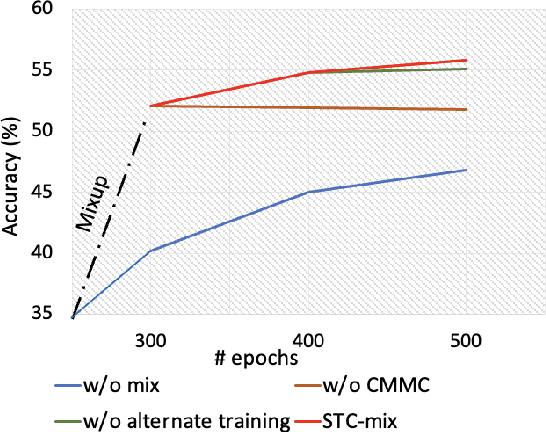
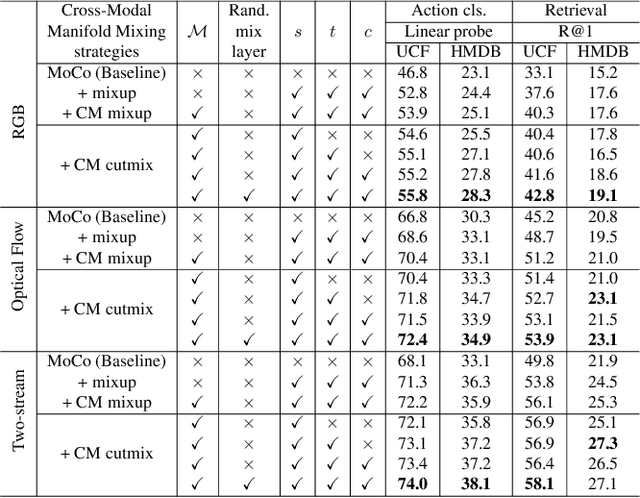
Contrastive representation learning of videos highly relies on the availability of millions of unlabelled videos. This is practical for videos available on web but acquiring such large scale of videos for real-world applications is very expensive and laborious. Therefore, in this paper we focus on designing video augmentation for self-supervised learning, we first analyze the best strategy to mix videos to create a new augmented video sample. Then, the question remains, can we make use of the other modalities in videos for data mixing? To this end, we propose Cross-Modal Manifold Cutmix (CMMC) that inserts a video tesseract into another video tesseract in the feature space across two different modalities. We find that our video mixing strategy STC-mix, i.e. preliminary mixing of videos followed by CMMC across different modalities in a video, improves the quality of learned video representations. We conduct thorough experiments for two downstream tasks: action recognition and video retrieval on two small scale video datasets UCF101, and HMDB51. We also demonstrate the effectiveness of our STC-mix on NTU dataset where domain knowledge is limited. We show that the performance of our STC-mix on both the downstream tasks is on par with the other self-supervised approaches while requiring less training data.
Knowledge distillation with error-correcting transfer learning for wind power prediction
Apr 01, 2022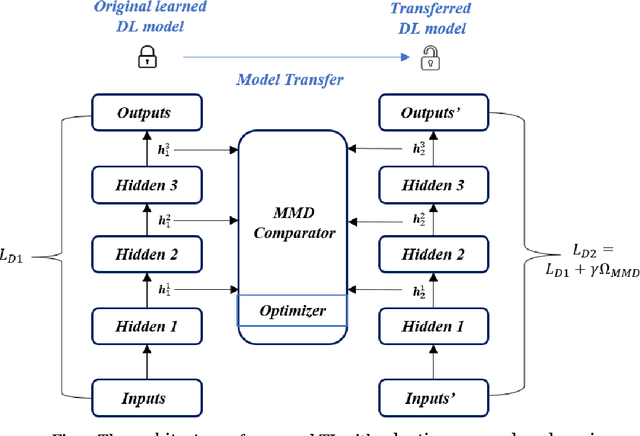

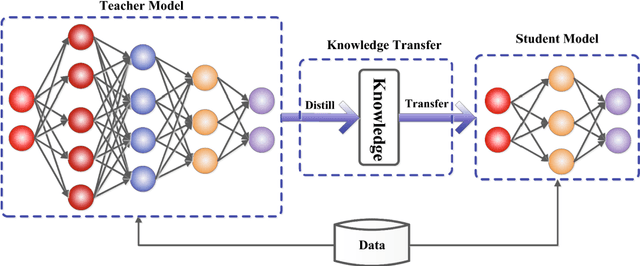
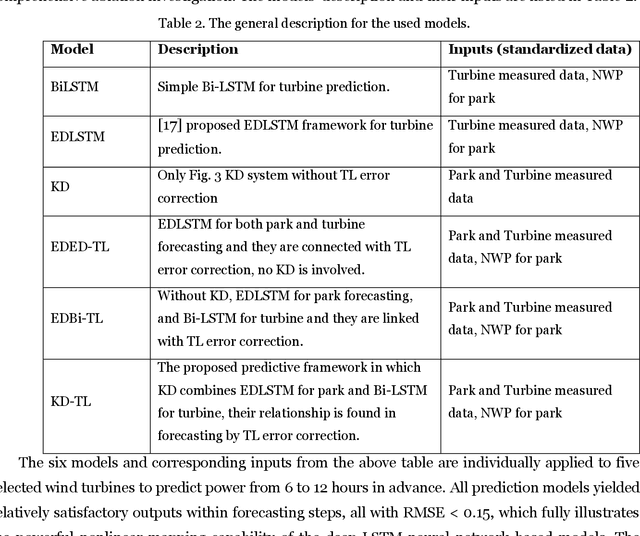
Wind power prediction, especially for turbines, is vital for the operation, controllability, and economy of electricity companies. Hybrid methodologies combining advanced data science with weather forecasting have been incrementally applied to the predictions. Nevertheless, individually modeling massive turbines from scratch and downscaling weather forecasts to turbine size are neither easy nor economical. Aiming at it, this paper proposes a novel framework with mathematical underpinnings for turbine power prediction. This framework is the first time to incorporate knowledge distillation into energy forecasting, enabling accurate and economical constructions of turbine models by learning knowledge from the well-established park model. Besides, park-scale weather forecasts non-explicitly are mapped to turbines by transfer learning of predicted power errors, achieving model correction for better performance. The proposed framework is deployed on five turbines featuring various terrains in an Arctic wind park, the results are evaluated against the competitors of ablation investigation. The major findings reveal that the proposed framework, developed on favorable knowledge distillation and transfer learning parameters tuning, yields performance boosts from 3.3 % to 23.9 % over its competitors. This advantage also exists in terms of wind energy physics and computing efficiency, which are verified by the prediction quality rate and calculation time.
Reachability Constrained Reinforcement Learning
May 16, 2022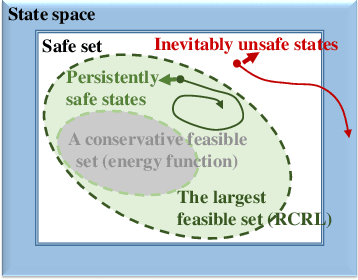
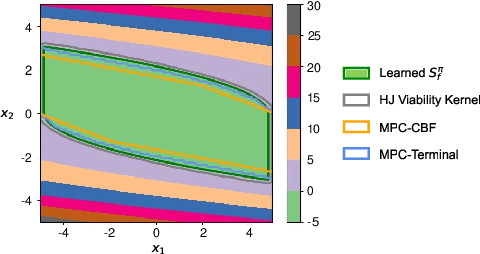
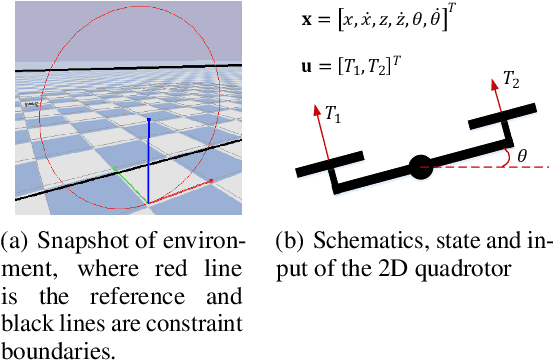
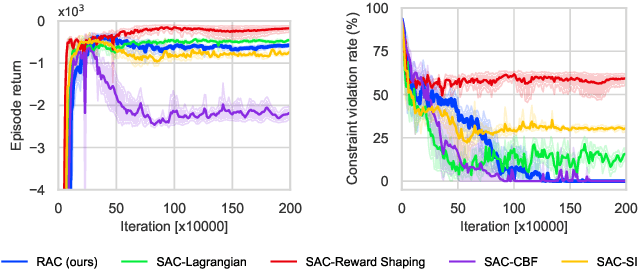
Constrained Reinforcement Learning (CRL) has gained significant interest recently, since the satisfaction of safety constraints is critical for real world problems. However, existing CRL methods constraining discounted cumulative costs generally lack rigorous definition and guarantee of safety. On the other hand, in the safe control research, safety is defined as persistently satisfying certain state constraints. Such persistent safety is possible only on a subset of the state space, called feasible set, where an optimal largest feasible set exists for a given environment. Recent studies incorporating safe control with CRL using energy-based methods such as control barrier function (CBF), safety index (SI) leverage prior conservative estimation of feasible sets, which harms performance of the learned policy. To deal with this problem, this paper proposes a reachability CRL (RCRL) method by using reachability analysis to characterize the largest feasible sets. We characterize the feasible set by the established self-consistency condition, then a safety value function can be learned and used as constraints in CRL. We also use the multi-time scale stochastic approximation theory to prove that the proposed algorithm converges to a local optimum, where the largest feasible set can be guaranteed. Empirical results on different benchmarks such as safe-control-gym and Safety-Gym validate the learned feasible set, the performance in optimal criteria, and constraint satisfaction of RCRL, compared to state-of-the-art CRL baselines.
A Duality-based Approach for Real-time Obstacle Avoidance between Polytopes with Control Barrier Functions
Jul 18, 2021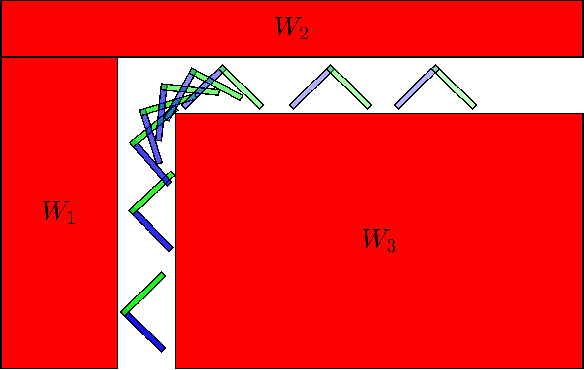
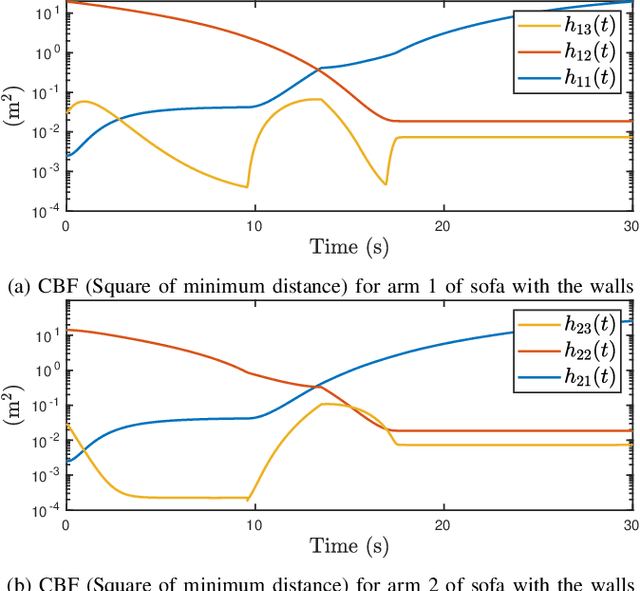
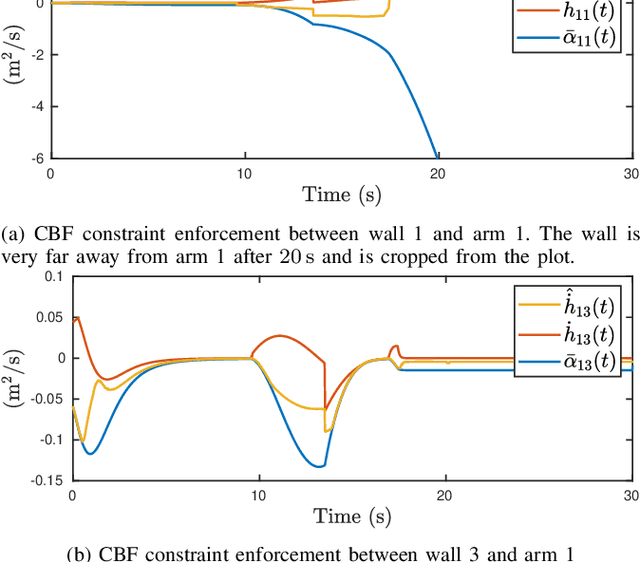

Developing controllers for obstacle avoidance between polytopes is a challenging and necessary problem for navigation in a tight space. Traditional approaches can only formulate the obstacle avoidance problem as an offline optimization problem. To address these challenges, we propose a duality-based safety-critical optimal control using control barrier functions for obstacle avoidance between polytopes, which can be solved in real-time with a QP-based optimization problem. A dual optimization problem is introduced to represent the minimum distance between polytopes and the Lagrangian function for the dual form is applied to construct a control barrier function. We demonstrate the proposed controller on a moving sofa problem where non-conservative maneuvers can be achieved in a tight space.