 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Key Event Detection from Massive Text Corpora
Jun 08, 2022

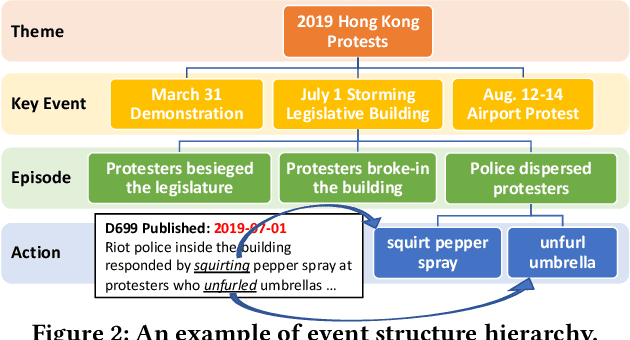
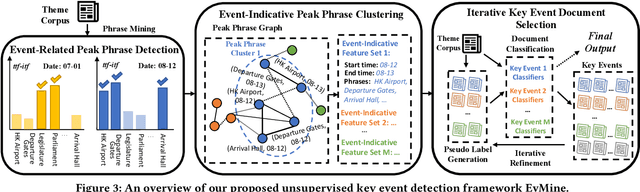
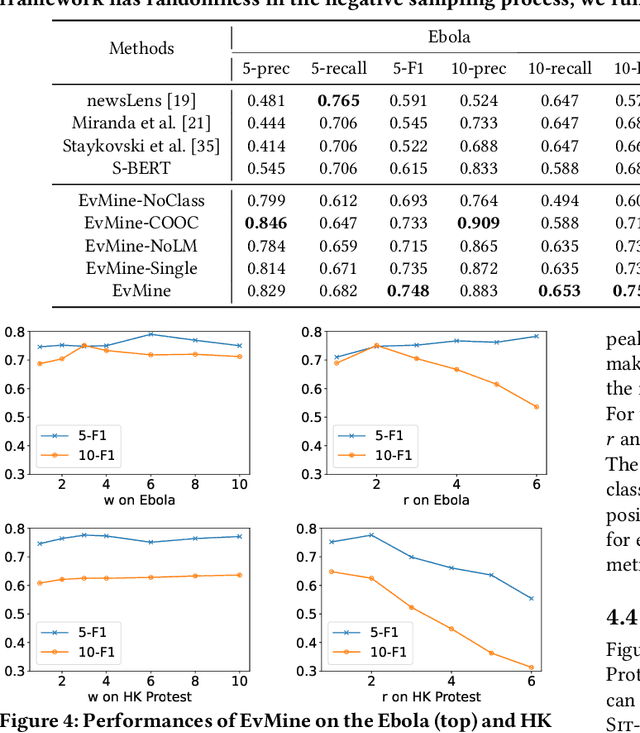
Automated event detection from news corpora is a crucial task towards mining fast-evolving structured knowledge. As real-world events have different granularities, from the top-level themes to key events and then to event mentions corresponding to concrete actions, there are generally two lines of research: (1) theme detection identifies from a news corpus major themes (e.g., "2019 Hong Kong Protests" vs. "2020 U.S. Presidential Election") that have very distinct semantics; and (2) action extraction extracts from one document mention-level actions (e.g., "the police hit the left arm of the protester") that are too fine-grained for comprehending the event. In this paper, we propose a new task, key event detection at the intermediate level, aiming to detect from a news corpus key events (e.g., "HK Airport Protest on Aug. 12-14"), each happening at a particular time/location and focusing on the same topic. This task can bridge event understanding and structuring and is inherently challenging because of the thematic and temporal closeness of key events and the scarcity of labeled data due to the fast-evolving nature of news articles. To address these challenges, we develop an unsupervised key event detection framework, EvMine, that (1) extracts temporally frequent peak phrases using a novel ttf-itf score, (2) merges peak phrases into event-indicative feature sets by detecting communities from our designed peak phrase graph that captures document co-occurrences, semantic similarities, and temporal closeness signals, and (3) iteratively retrieves documents related to each key event by training a classifier with automatically generated pseudo labels from the event-indicative feature sets and refining the detected key events using the retrieved documents. Extensive experiments and case studies show EvMine outperforms all the baseline methods and its ablations on two real-world news corpora.
Multimodal Masked Autoencoders Learn Transferable Representations
May 31, 2022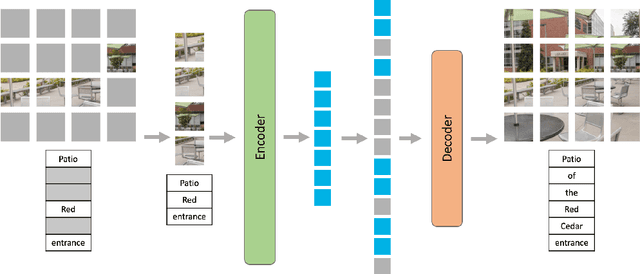
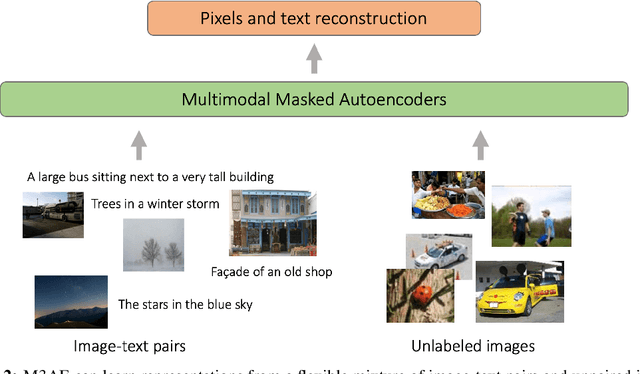
Building scalable models to learn from diverse, multimodal data remains an open challenge. For vision-language data, the dominant approaches are based on contrastive learning objectives that train a separate encoder for each modality. While effective, contrastive learning approaches introduce sampling bias depending on the data augmentations used, which can degrade performance on downstream tasks. Moreover, these methods are limited to paired image-text data, and cannot leverage widely-available unpaired data. In this paper, we investigate whether a large multimodal model trained purely via masked token prediction, without using modality-specific encoders or contrastive learning, can learn transferable representations for downstream tasks. We propose a simple and scalable network architecture, the Multimodal Masked Autoencoder (M3AE), which learns a unified encoder for both vision and language data via masked token prediction. We provide an empirical study of M3AE trained on a large-scale image-text dataset, and find that M3AE is able to learn generalizable representations that transfer well to downstream tasks. Surprisingly, we find that M3AE benefits from a higher text mask ratio (50-90%), in contrast to BERT whose standard masking ratio is 15%, due to the joint training of two data modalities. We also provide qualitative analysis showing that the learned representation incorporates meaningful information from both image and language. Lastly, we demonstrate the scalability of M3AE with larger model size and training time, and its flexibility to train on both paired image-text data as well as unpaired data.
Innovations in the field of on-board scheduling technologies
May 04, 2022
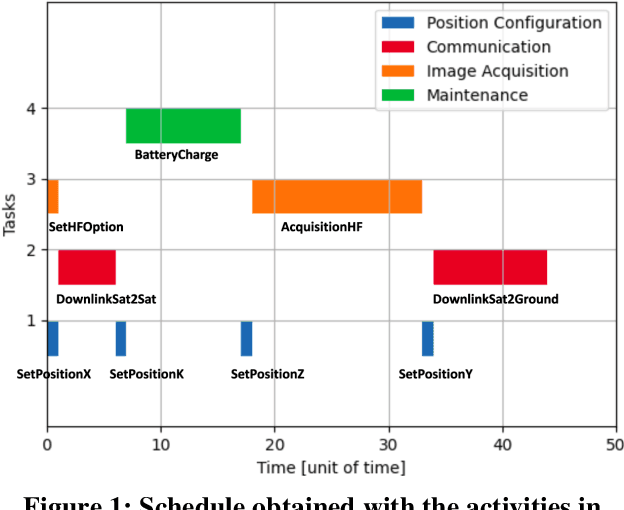
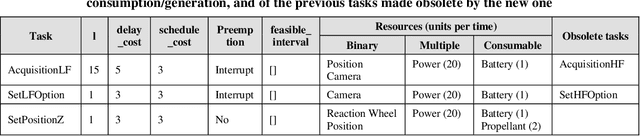
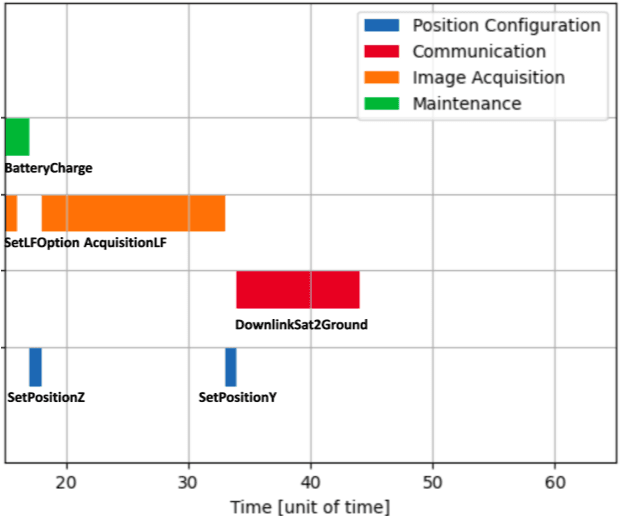
Space missions are characterized by long distances, difficult or unavailable communication and high operating costs. Moreover, complexity has been constantly increasing in recent years. For this reason, improving the autonomy of space operators is an attractive goal to increase the mission reward with lower costs. This paper proposes an onboard scheduler, that integrates inside an onboard software framework for mission autonomy. Given a set of activities, it is responsible for determining the starting time of each activity according to their priority, order constraints, and resource consumption. The presented scheduler is based on linear integer programming and relies on the use of a branch-and-cut solver. The technology has been tested on an Earth Observation scenario, comparing its performance against the state-of-the-art scheduling technology.
Paired Image-to-Image Translation Quality Assessment Using Multi-Method Fusion
May 09, 2022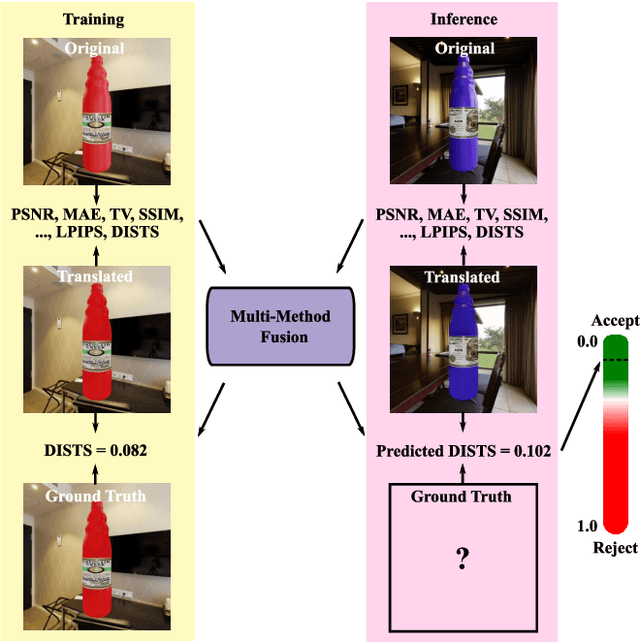
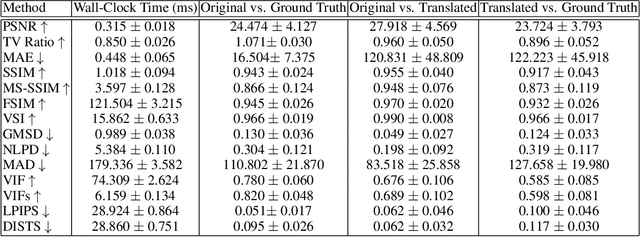
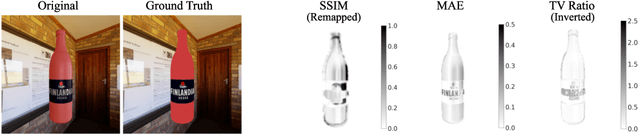
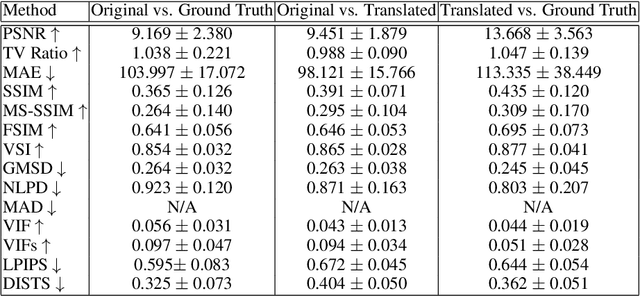
How best to evaluate synthesized images has been a longstanding problem in image-to-image translation, and to date remains largely unresolved. This paper proposes a novel approach that combines signals of image quality between paired source and transformation to predict the latter's similarity with a hypothetical ground truth. We trained a Multi-Method Fusion (MMF) model via an ensemble of gradient-boosted regressors using Image Quality Assessment (IQA) metrics to predict Deep Image Structure and Texture Similarity (DISTS), enabling models to be ranked without the need for ground truth data. Analysis revealed the task to be feature-constrained, introducing a trade-off at inference between metric computation time and prediction accuracy. The MMF model we present offers an efficient way to automate the evaluation of synthesized images, and by extension the image-to-image translation models that generated them.
Time series classification for predictive maintenance on event logs
Nov 24, 2020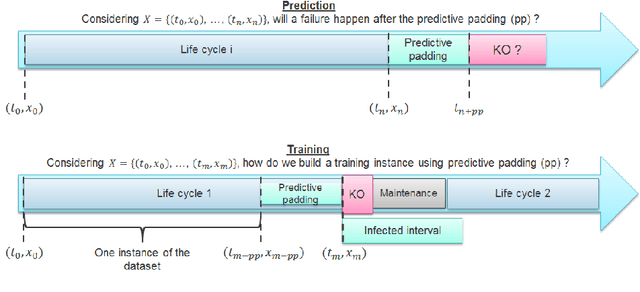
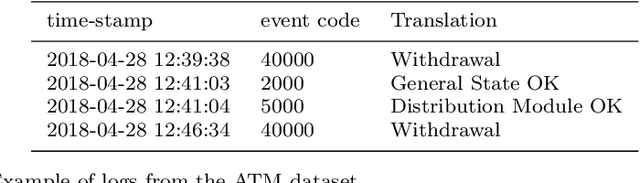
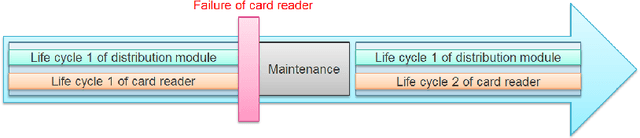
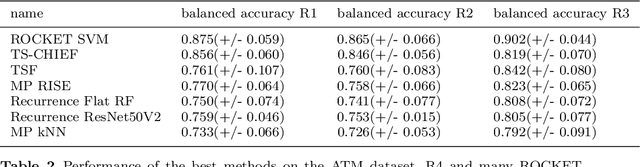
Time series classification (TSC) gained a lot of attention in the past decade and number of methods for representing and classifying time series have been proposed. Nowadays, methods based on convolutional networks and ensemble techniques represent the state of the art for time series classification. Techniques transforming time series to image or text also provide reliable ways to extract meaningful features or representations of time series. We compare the state-of-the-art representation and classification methods on a specific application, that is predictive maintenance from sequences of event logs. The contributions of this paper are twofold: introducing a new data set for predictive maintenance on automated teller machines (ATMs) log data and comparing the performance of different representation methods for predicting the occurrence of a breakdown. The problem is difficult since unlike the classic case of predictive maintenance via signals from sensors, we have sequences of discrete event logs occurring at any time and the lengths of the sequences, corresponding to life cycles, vary a lot.
Robust Longitudinal Control for Vehicular Autonomous Platoons Using Deep Reinforcement Learning
May 31, 2022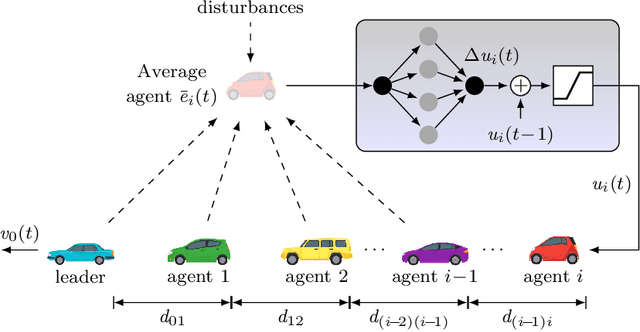
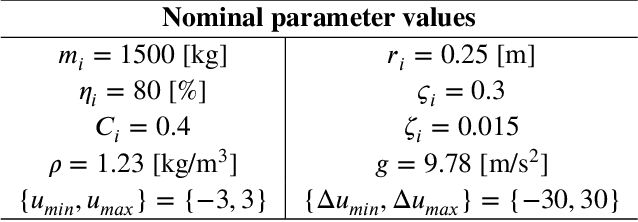
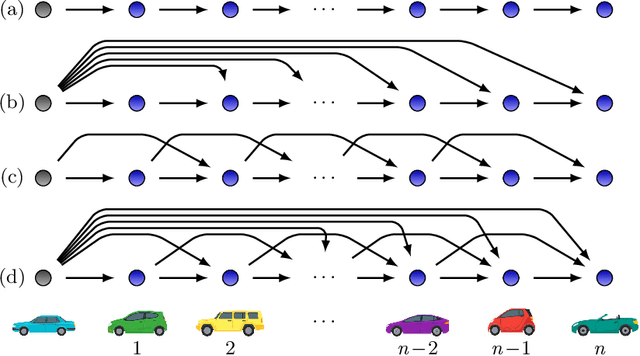
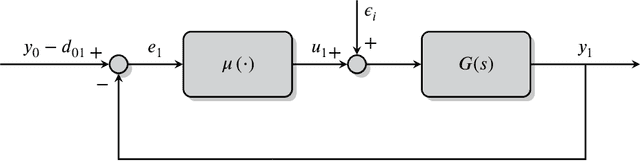
In the last few years, researchers have applied machine learning strategies in the context of vehicular platoons to increase the safety and efficiency of cooperative transportation. Reinforcement Learning methods have been employed in the longitudinal spacing control of Cooperative Adaptive Cruise Control systems, but to date, none of those studies have addressed problems of disturbance rejection in such scenarios. Characteristics such as uncertain parameters in the model and external interferences may prevent agents from reaching null-spacing errors when traveling at cruising speed. On the other hand, complex communication topologies lead to specific training processes that can not be generalized to other contexts, demanding re-training every time the configuration changes. Therefore, in this paper, we propose an approach to generalize the training process of a vehicular platoon, such that the acceleration command of each agent becomes independent of the network topology. Also, we have modeled the acceleration input as a term with integral action, such that the Convolutional Neural Network is capable of learning corrective actions when the states are disturbed by unknown effects. We illustrate the effectiveness of our proposal with experiments using different network topologies, uncertain parameters, and external forces. Comparative analyses, in terms of the steady-state error and overshoot response, were conducted against the state-of-the-art literature. The findings offer new insights concerning generalization and robustness of using Reinforcement Learning in the control of autonomous platoons.
Exact Paired-Permutation Testing for Structured Test Statistics
May 04, 2022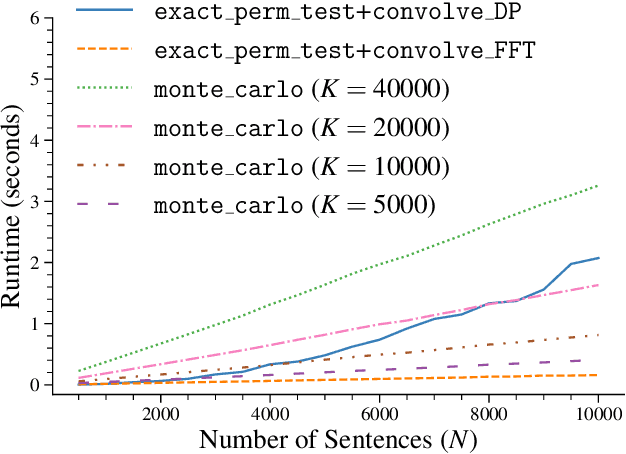
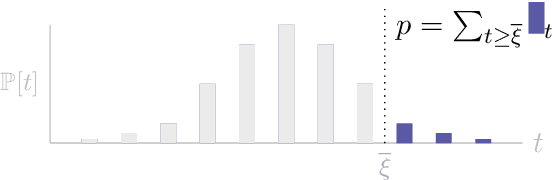
Significance testing -- especially the paired-permutation test -- has played a vital role in developing NLP systems to provide confidence that the difference in performance between two systems (i.e., the test statistic) is not due to luck. However, practitioners rely on Monte Carlo approximation to perform this test due to a lack of a suitable exact algorithm. In this paper, we provide an efficient exact algorithm for the paired-permutation test for a family of structured test statistics. Our algorithm runs in $\mathcal{O}(GN (\log GN )(\log N ))$ time where $N$ is the dataset size and $G$ is the range of the test statistic. We found that our exact algorithm was $10$x faster than the Monte Carlo approximation with $20000$ samples on a common dataset.
On the Distribution, Sparsity, and Inference-time Quantization of Attention Values in Transformers
Jun 02, 2021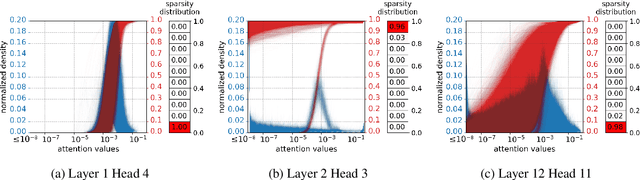
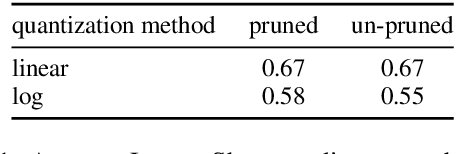
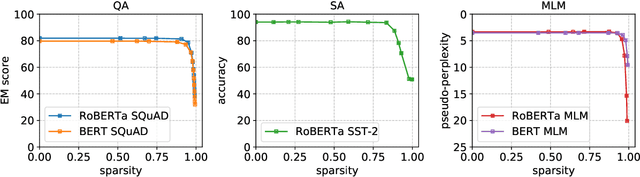
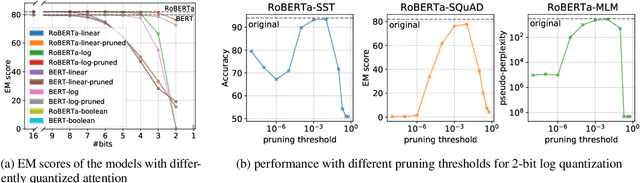
How much information do NLP tasks really need from a transformer's attention mechanism at application-time (inference)? From recent work, we know that there is sparsity in transformers and that the floating-points within its computation can be discretized to fewer values with minimal loss to task accuracies. However, this requires retraining or even creating entirely new models, both of which can be expensive and carbon-emitting. Focused on optimizations that do not require training, we systematically study the full range of typical attention values necessary. This informs the design of an inference-time quantization technique using both pruning and log-scaled mapping which produces only a few (e.g. $2^3$) unique values. Over the tasks of question answering and sentiment analysis, we find nearly 80% of attention values can be pruned to zeros with minimal ($< 1.0\%$) relative loss in accuracy. We use this pruning technique in conjunction with quantizing the attention values to only a 3-bit format, without retraining, resulting in only a 0.8% accuracy reduction on question answering with fine-tuned RoBERTa.
muNet: Evolving Pretrained Deep Neural Networks into Scalable Auto-tuning Multitask Systems
May 25, 2022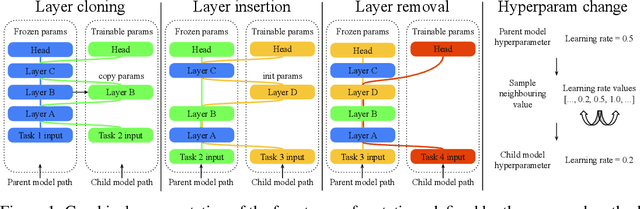
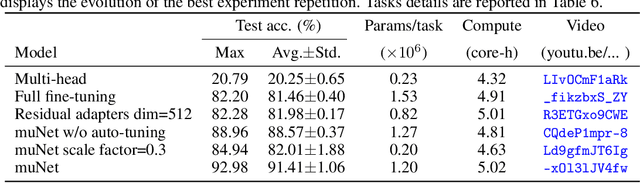
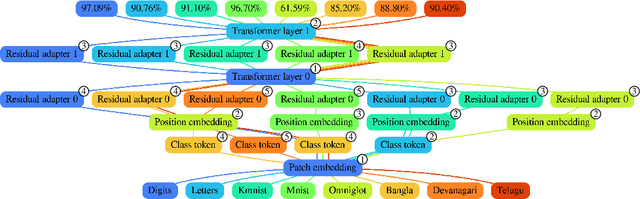
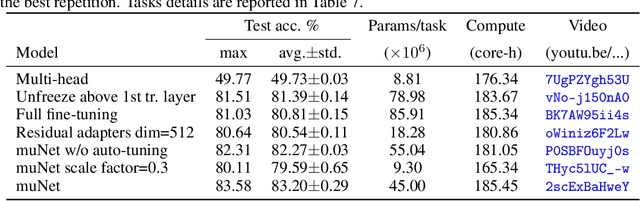
Most uses of machine learning today involve training a model from scratch for a particular task, or sometimes starting with a model pretrained on a related task and then fine-tuning on a downstream task. Both approaches offer limited knowledge transfer between different tasks, time-consuming human-driven customization to individual tasks and high computational costs especially when starting from randomly initialized models. We propose a method that uses the layers of a pretrained deep neural network as building blocks to construct an ML system that can jointly solve an arbitrary number of tasks. The resulting system can leverage cross tasks knowledge transfer, while being immune from common drawbacks of multitask approaches such as catastrophic forgetting, gradients interference and negative transfer. We define an evolutionary approach designed to jointly select the prior knowledge relevant for each task, choose the subset of the model parameters to train and dynamically auto-tune its hyperparameters. Furthermore, a novel scale control method is employed to achieve quality/size trade-offs that outperform common fine-tuning techniques. Compared with standard fine-tuning on a benchmark of 10 diverse image classification tasks, the proposed model improves the average accuracy by 2.39% while using 47% less parameters per task.
Transitivity, Time Consumption, and Quality of Preference Judgments in Crowdsourcing
Apr 18, 2021
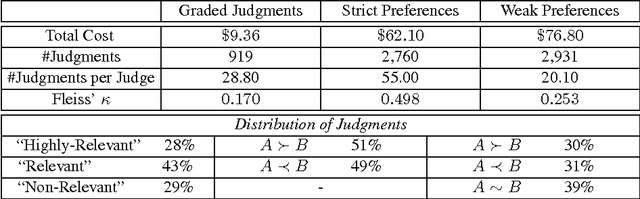
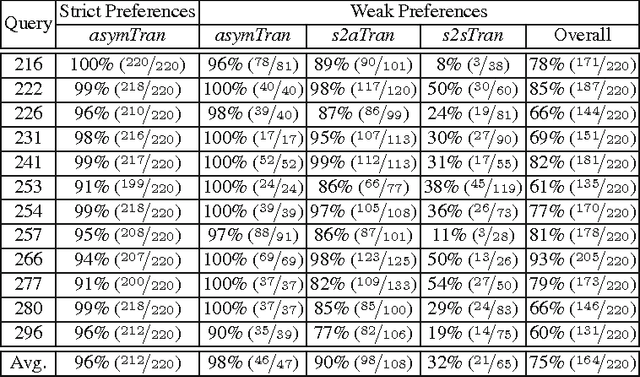
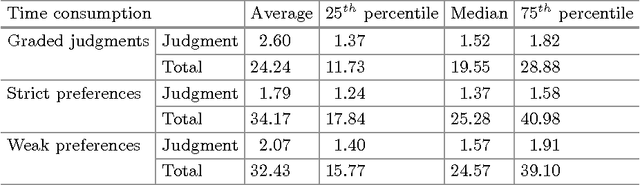
Preference judgments have been demonstrated as a better alternative to graded judgments to assess the relevance of documents relative to queries. Existing work has verified transitivity among preference judgments when collected from trained judges, which reduced the number of judgments dramatically. Moreover, strict preference judgments and weak preference judgments, where the latter additionally allow judges to state that two documents are equally relevant for a given query, are both widely used in literature. However, whether transitivity still holds when collected from crowdsourcing, i.e., whether the two kinds of preference judgments behave similarly remains unclear. In this work, we collect judgments from multiple judges using a crowdsourcing platform and aggregate them to compare the two kinds of preference judgments in terms of transitivity, time consumption, and quality. That is, we look into whether aggregated judgments are transitive, how long it takes judges to make them, and whether judges agree with each other and with judgments from TREC. Our key findings are that only strict preference judgments are transitive. Meanwhile, weak preference judgments behave differently in terms of transitivity, time consumption, as well as of quality of judgment.