 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Distribution, Sparsity, and Inference-time Quantization of Attention Values in Transformers
Jun 02, 2021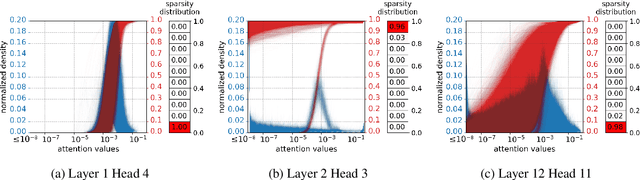
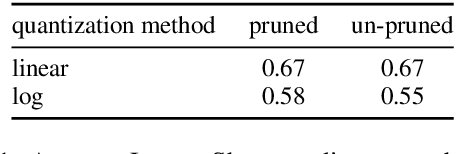
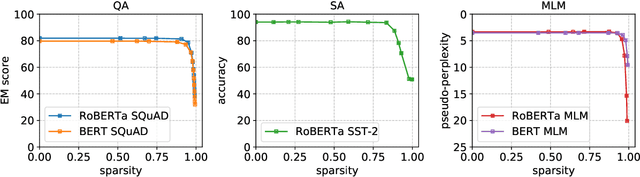
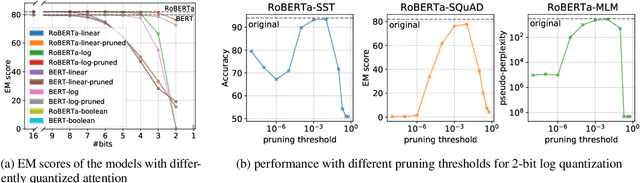
How much information do NLP tasks really need from a transformer's attention mechanism at application-time (inference)? From recent work, we know that there is sparsity in transformers and that the floating-points within its computation can be discretized to fewer values with minimal loss to task accuracies. However, this requires retraining or even creating entirely new models, both of which can be expensive and carbon-emitting. Focused on optimizations that do not require training, we systematically study the full range of typical attention values necessary. This informs the design of an inference-time quantization technique using both pruning and log-scaled mapping which produces only a few (e.g. $2^3$) unique values. Over the tasks of question answering and sentiment analysis, we find nearly 80% of attention values can be pruned to zeros with minimal ($< 1.0\%$) relative loss in accuracy. We use this pruning technique in conjunction with quantizing the attention values to only a 3-bit format, without retraining, resulting in only a 0.8% accuracy reduction on question answering with fine-tuned RoBERTa.
Medusa: A Scalable Interconnect for Many-Port DNN Accelerators and Wide DRAM Controller Interfaces
Jul 11, 2018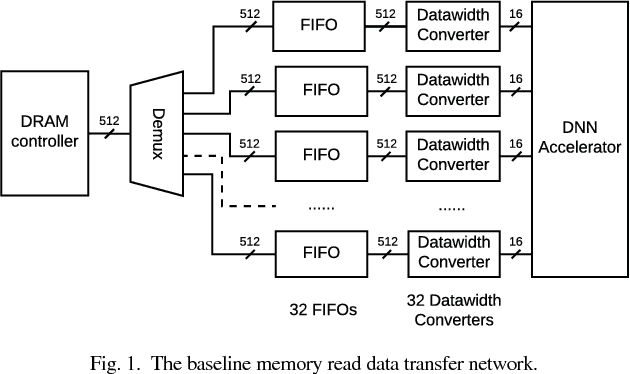
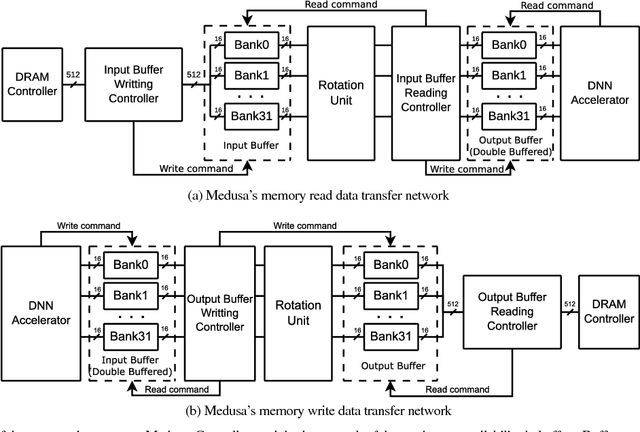
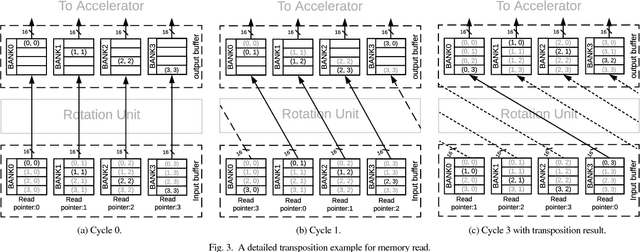
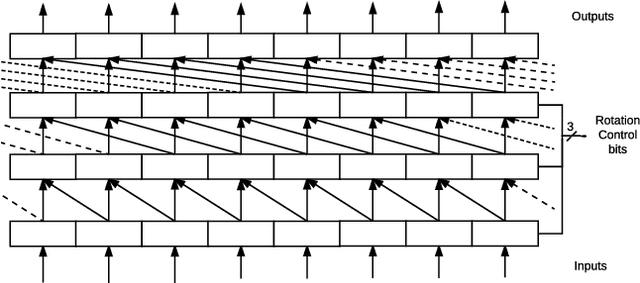
To cope with the increasing demand and computational intensity of deep neural networks (DNNs), industry and academia have turned to accelerator technologies. In particular, FPGAs have been shown to provide a good balance between performance and energy efficiency for accelerating DNNs. While significant research has focused on how to build efficient layer processors, the computational building blocks of DNN accelerators, relatively little attention has been paid to the on-chip interconnects that sit between the layer processors and the FPGA's DRAM controller. We observe a disparity between DNN accelerator interfaces, which tend to comprise many narrow ports, and FPGA DRAM controller interfaces, which tend to be wide buses. This mismatch causes traditional interconnects to consume significant FPGA resources. To address this problem, we designed Medusa: an optimized FPGA memory interconnect which transposes data in the interconnect fabric, tailoring the interconnect to the needs of DNN layer processors. Compared to a traditional FPGA interconnect, our design can reduce LUT and FF use by 4.7x and 6.0x, and improves frequency by 1.8x.