 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Focal Sparse Convolutional Networks for 3D Object Detection
Apr 26, 2022
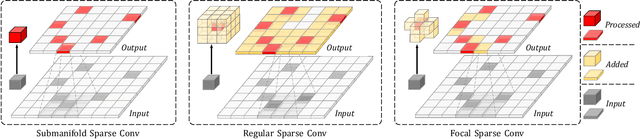
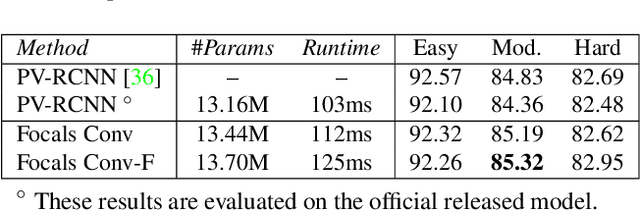

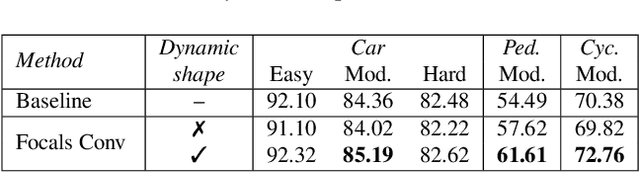
Non-uniformed 3D sparse data, e.g., point clouds or voxels in different spatial positions, make contribution to the task of 3D object detection in different ways. Existing basic components in sparse convolutional networks (Sparse CNNs) process all sparse data, regardless of regular or submanifold sparse convolution. In this paper, we introduce two new modules to enhance the capability of Sparse CNNs, both are based on making feature sparsity learnable with position-wise importance prediction. They are focal sparse convolution (Focals Conv) and its multi-modal variant of focal sparse convolution with fusion, or Focals Conv-F for short. The new modules can readily substitute their plain counterparts in existing Sparse CNNs and be jointly trained in an end-to-end fashion. For the first time, we show that spatially learnable sparsity in sparse convolution is essential for sophisticated 3D object detection. Extensive experiments on the KITTI, nuScenes and Waymo benchmarks validate the effectiveness of our approach. Without bells and whistles, our results outperform all existing single-model entries on the nuScenes test benchmark at the paper submission time. Code and models are at https://github.com/dvlab-research/FocalsConv.
Learning Sequential Contexts using Transformer for 3D Hand Pose Estimation
Jun 01, 2022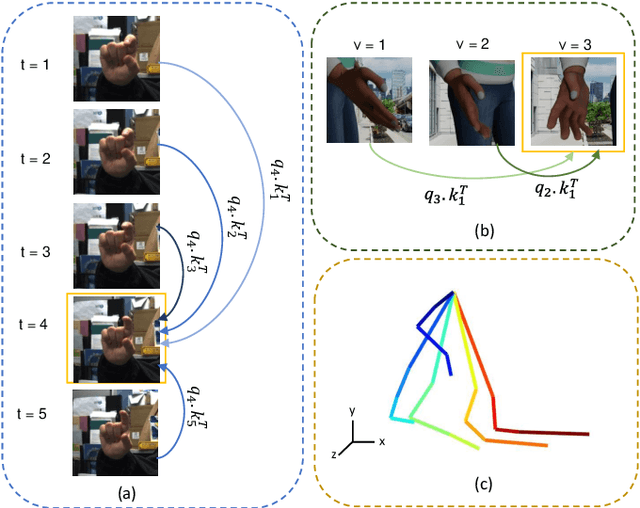
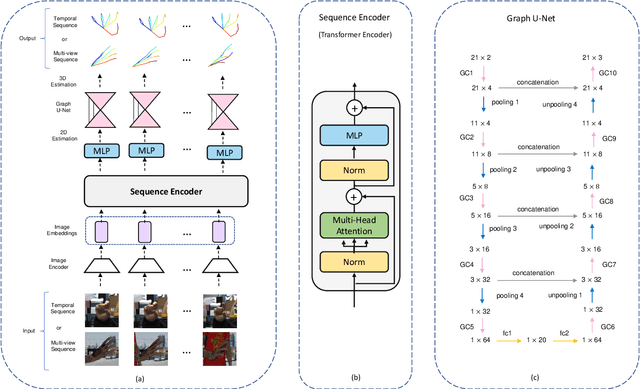
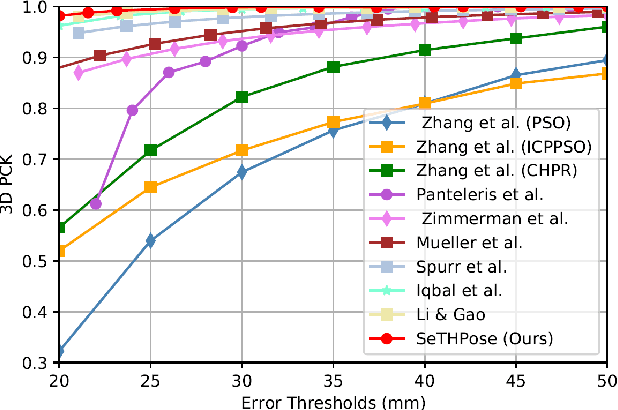
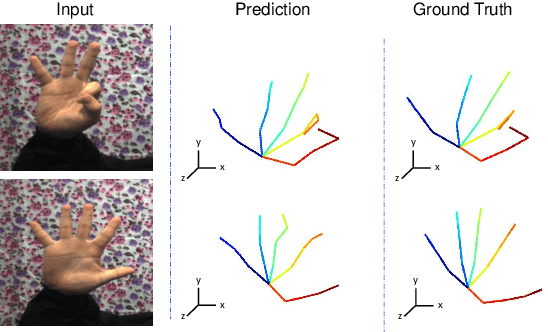
3D hand pose estimation (HPE) is the process of locating the joints of the hand in 3D from any visual input. HPE has recently received an increased amount of attention due to its key role in a variety of human-computer interaction applications. Recent HPE methods have demonstrated the advantages of employing videos or multi-view images, allowing for more robust HPE systems. Accordingly, in this study, we propose a new method to perform Sequential learning with Transformer for Hand Pose (SeTHPose) estimation. Our SeTHPose pipeline begins by extracting visual embeddings from individual hand images. We then use a transformer encoder to learn the sequential context along time or viewing angles and generate accurate 2D hand joint locations. Then, a graph convolutional neural network with a U-Net configuration is used to convert the 2D hand joint locations to 3D poses. Our experiments show that SeTHPose performs well on both hand sequence varieties, temporal and angular. Also, SeTHPose outperforms other methods in the field to achieve new state-of-the-art results on two public available sequential datasets, STB and MuViHand.
Investigation of Optimization Techniques on the Elevator Dispatching Problem
Feb 26, 2022
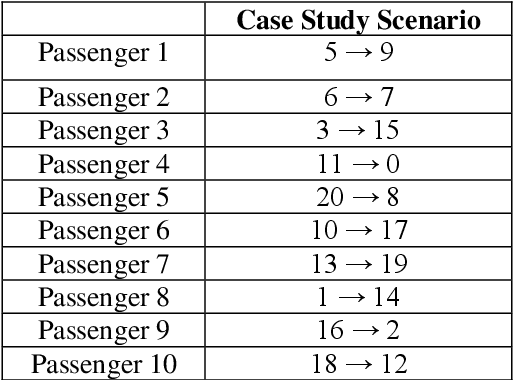
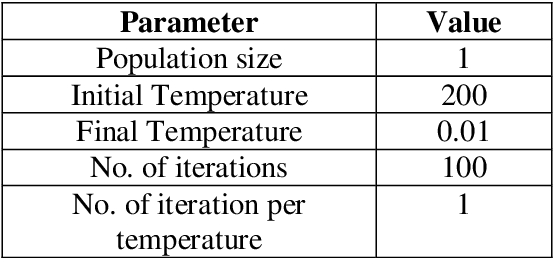

In the elevator industry, reducing passenger journey time in an elevator system is a major aim. The key obstacle to optimising elevator dispatching is the unpredictable traffic flow of passengers. To address this difficulty, two main features must be optimised: waiting time and journey time. To address the problem in real time, several strategies are employed, including Simulated Annealing (SA), Genetic Algorithm (GA), Particle Swarm Optimization Algorithm (PSO), and Whale Optimization Algorithm (WOA). This research article compares the algorithms discussed above. To investigate the functioning of the algorithms for visualisation and insight, a case study was created. In order to discover the optimum algorithm for the elevator dispatching problem, performance indices such as average and ideal fitness value are generated in 5 runs to compare the outcomes of the methods. The goal of this study is to compute a dispatching scheme, which is the result of the algorithms, in order to lower the average trip time for all passengers. This study builds on previous studies that recommended ways to reduce waiting time. The proposed technique reduces average wait time, improves lift efficiency, and improves customer experience.
BiT: Robustly Binarized Multi-distilled Transformer
May 25, 2022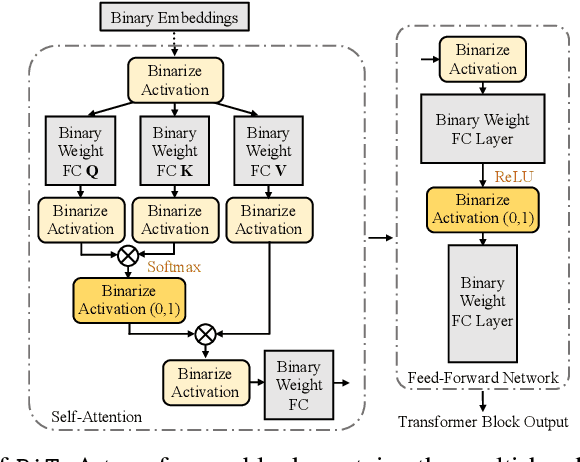
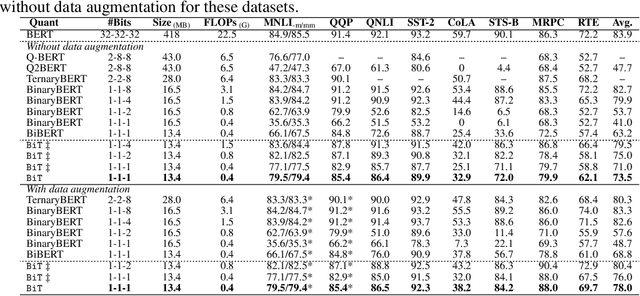

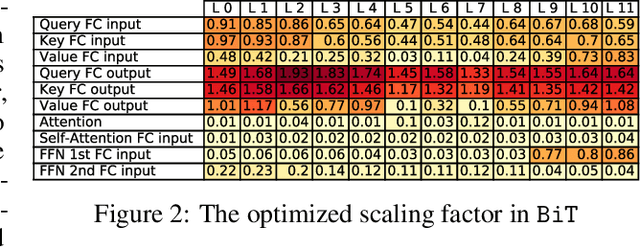
Modern pre-trained transformers have rapidly advanced the state-of-the-art in machine learning, but have also grown in parameters and computational complexity, making them increasingly difficult to deploy in resource-constrained environments. Binarization of the weights and activations of the network can significantly alleviate these issues, however is technically challenging from an optimization perspective. In this work, we identify a series of improvements which enables binary transformers at a much higher accuracy than what was possible previously. These include a two-set binarization scheme, a novel elastic binary activation function with learned parameters, and a method to quantize a network to its limit by successively distilling higher precision models into lower precision students. These approaches allow for the first time, fully binarized transformer models that are at a practical level of accuracy, approaching a full-precision BERT baseline on the GLUE language understanding benchmark within as little as 5.9%.
Scalable Kernel-Based Minimum Mean Square Error Estimator for Accelerated Image Error Concealment
May 23, 2022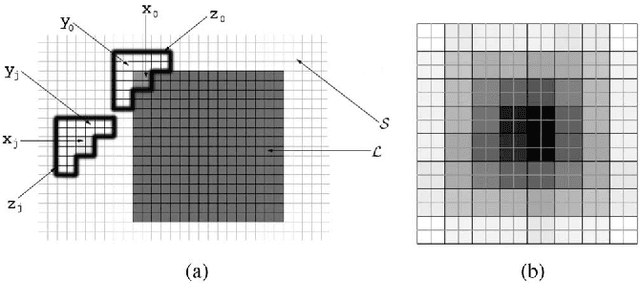

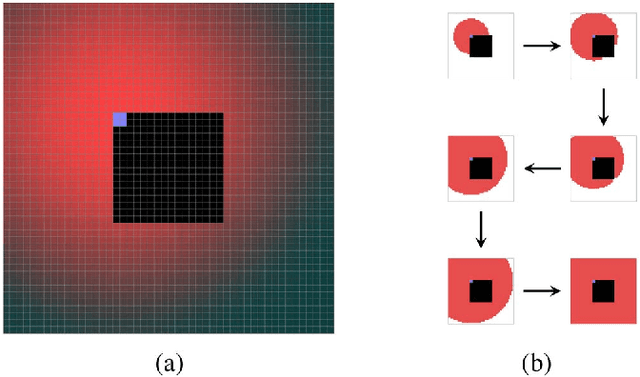
Error concealment is of great importance for block-based video systems, such as DVB or video streaming services. In this paper, we propose a novel scalable spatial error concealment algorithm that aims at obtaining high quality reconstructions with reduced computational burden. The proposed technique exploits the excellent reconstructing abilities of the kernel-based minimum mean square error K-MMSE estimator. We propose to decompose this approach into a set of hierarchically stacked layers. The first layer performs the basic reconstruction that the subsequent layers can eventually refine. In addition, we design a layer management mechanism, based on profiles, that dynamically adapts the use of higher layers to the visual complexity of the area being reconstructed. The proposed technique outperforms other state-of-the-art algorithms and produces high quality reconstructions, equivalent to K-MMSE, while requiring around one tenth of its computational time.
Research on Sparsity Measures for Rotating Machinery Health Monitoring
Apr 30, 2022
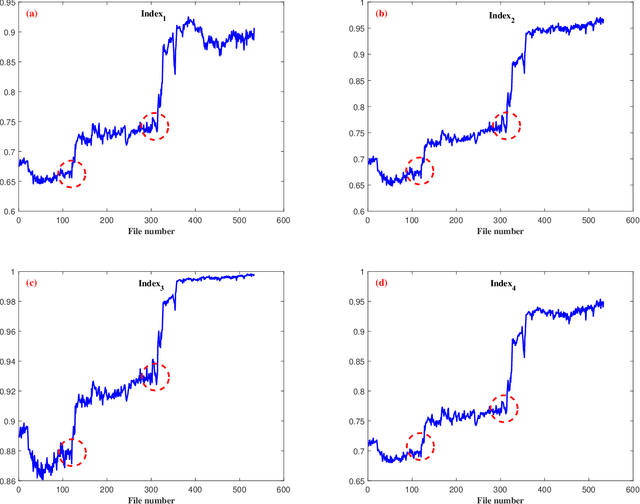
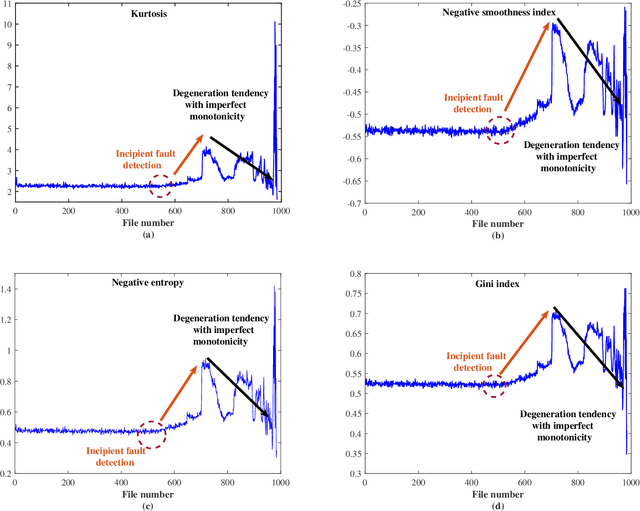
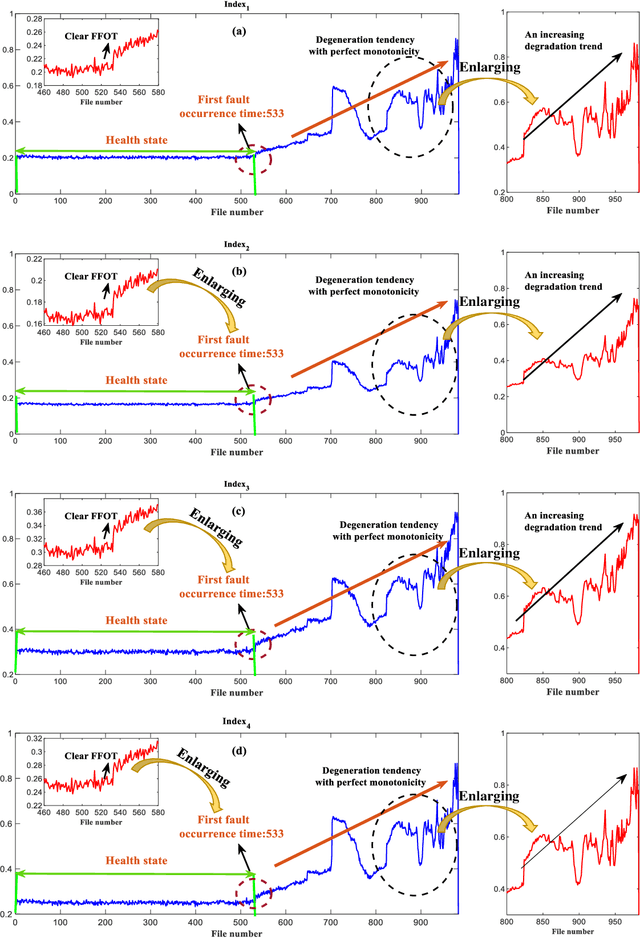
Machine health management is one of the main research contents of PHM technology, which aims to monitor the health states of machines online and evaluate degradation stages through real-time sensor data. In recent years, classic sparsity measures such as kurtosis, Lp/Lq norm, pq-mean, smoothness index, negative entropy, and Gini index have been widely used to characterize the impulsivity of repetitive transients. Since smoothness index and negative entropy were proposed, the sparse properties have not been fully analyzed. The first work of this paper is to analyze six properties of smoothness index and negative entropy. In addition, this paper conducts a thorough investigation on multivariate power average function and finds that existing classical sparsity measures can be respectively reformulated as the ratio of multivariate power mean functions (MPMFs). Finally, a general paradigm of index design are proposed for the expansion of sparsity measures family, and several newly designed dimensionless health indexes are given as examples. Two different run-to-failure bearing datasets were used to analyze and validate the capabilities and advantages of the newly designed health indexes. Experimental results prove that the newly designed health indexes show good performance in terms of monotonic degradation description, first fault occurrence time determination and degradation state assessment.
HybVIO: Pushing the Limits of Real-time Visual-inertial Odometry
Jun 22, 2021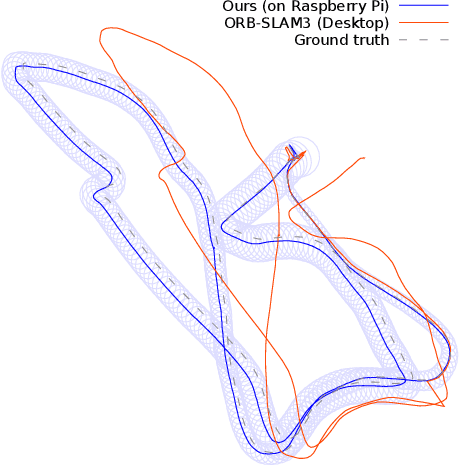
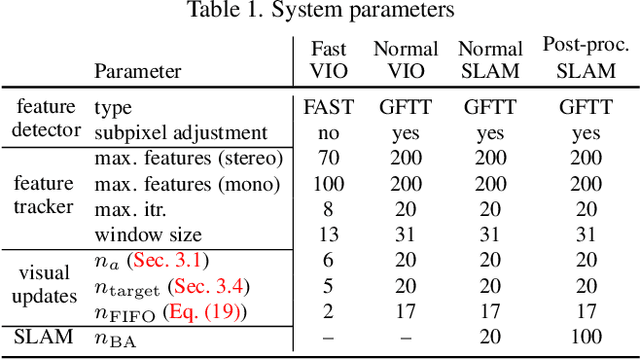

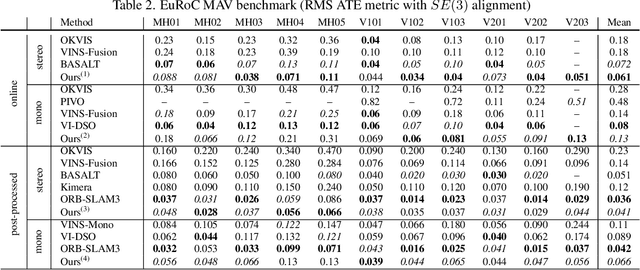
We present HybVIO, a novel hybrid approach for combining filtering-based visual-inertial odometry (VIO) with optimization-based SLAM. The core of our method is highly robust, independent VIO with improved IMU bias modeling, outlier rejection, stationarity detection, and feature track selection, which is adjustable to run on embedded hardware. Long-term consistency is achieved with a loosely-coupled SLAM module. In academic benchmarks, our solution yields excellent performance in all categories, especially in the real-time use case, where we outperform the current state-of-the-art. We also demonstrate the feasibility of VIO for vehicular tracking on consumer-grade hardware using a custom dataset, and show good performance in comparison to current commercial VISLAM alternatives.
WHIS: Hearing impairment simulator based on the gammachirp auditory filterbank
Jun 14, 2022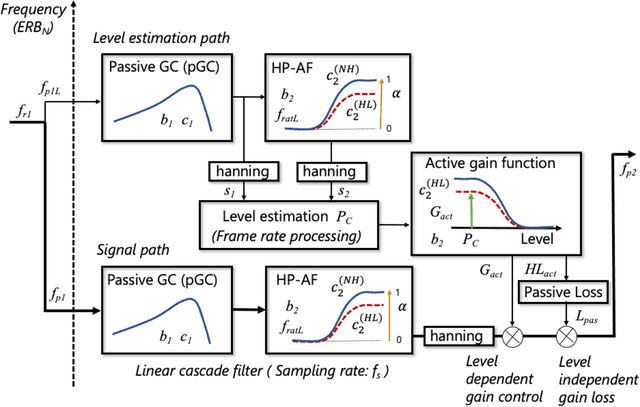
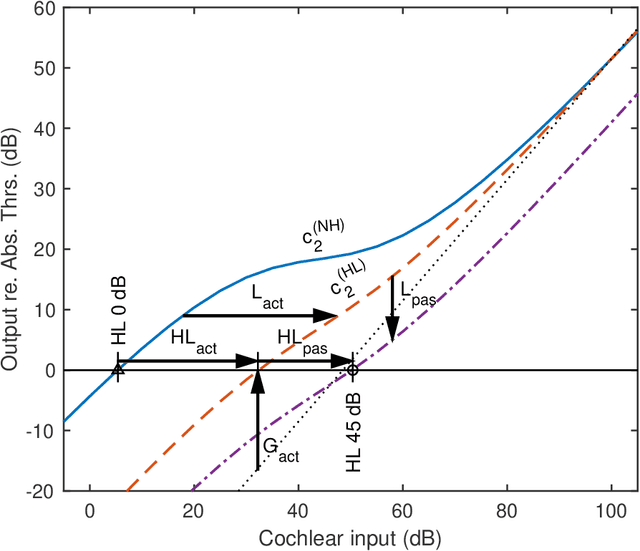
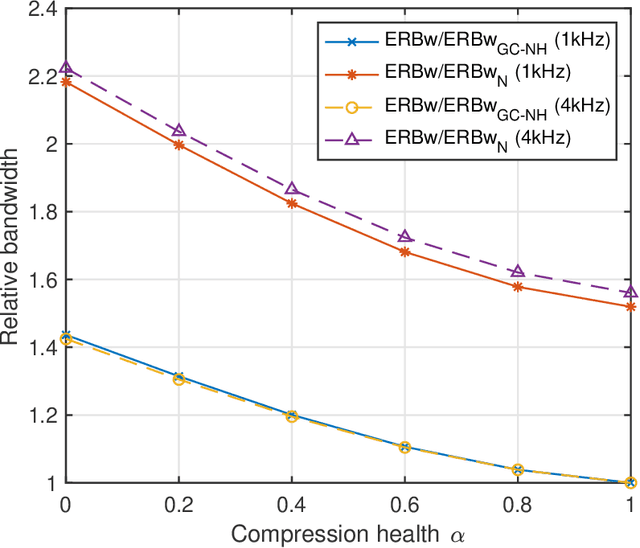
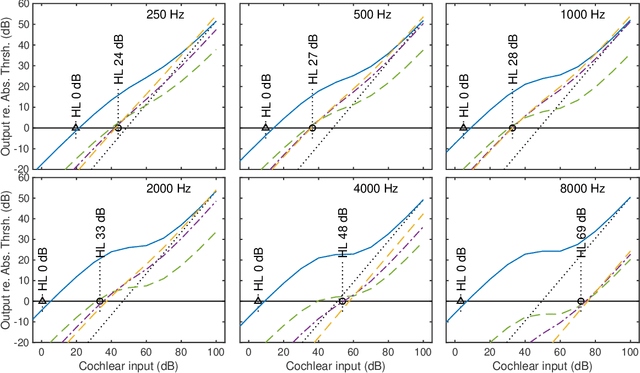
A new version of a hearing impairment simulator (WHIS) was implemented based on a revised version of the gammachirp filterbank (GCFB), which incorporates fast frame-based processing, absolute threshold (AT), an audiogram of a hearing-impaired (HI) listener, and a parameter to control the cochlear input-output (IO) function. The parameter referred to as the compression health $\alpha$ controlled the slope of the IO function to range from normal hearing (NH) listeners to HI listeners, without largely changing the total hearing loss (HL). The new WHIS was designed provide an NH listener the same EPs as those of a target HI listener.The analysis part of WHIS was almost the same as that of the revised GCFB, except that the IO function was used instead of the gain function. We proposed two synthesis methods: a direct time-varying filter for perceptually small distortion and a filterbank analysis-synthesis for further HI simulations including temporal smearing. We evaluated the WHIS family and a Cambridge version of the HL simulator (CamHLS) in terms of differences in the IO function and spectral distance. The IO functions were simulated fairly well at $\alpha$ less than 0.5 but not at $\alpha$ equal to 1. Thus, it is difficult to simulate the HL when the IO function is sufficiently healthy. This is a fundamental limit of any existing HL simulator as well as WHIS. The new WHIS yielded a smaller spectral distortion than CamHLS and was fairly compatible with the previous version.
TTOpt: A Maximum Volume Quantized Tensor Train-based Optimization and its Application to Reinforcement Learning
Apr 30, 2022
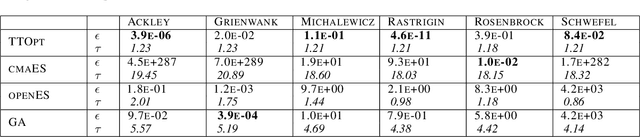
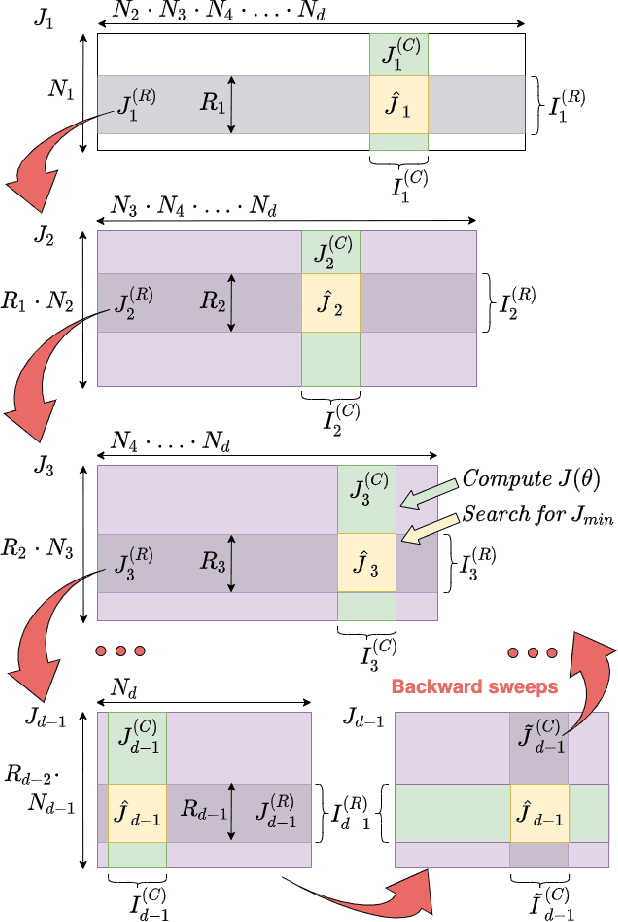
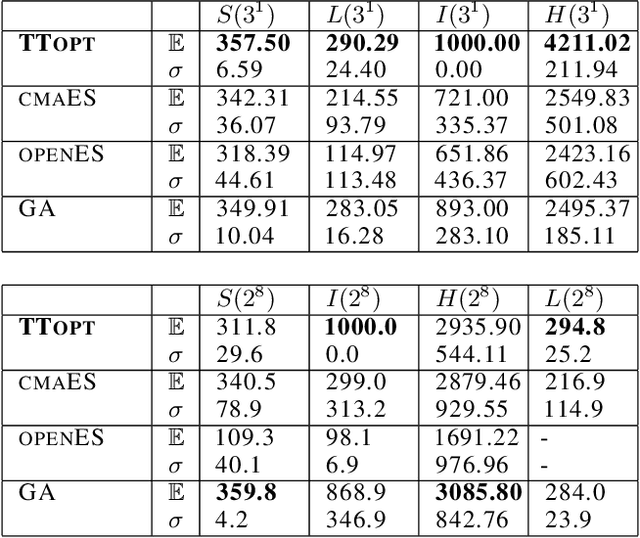
We present a novel procedure for optimization based on the combination of efficient quantized tensor train representation and a generalized maximum matrix volume principle. We demonstrate the applicability of the new Tensor Train Optimizer (TTOpt) method for various tasks, ranging from minimization of multidimensional functions to reinforcement learning. Our algorithm compares favorably to popular evolutionary-based methods and outperforms them by the number of function evaluations or execution time, often by a significant margin.
RLFlow: Optimising Neural Network Subgraph Transformation with World Models
May 09, 2022
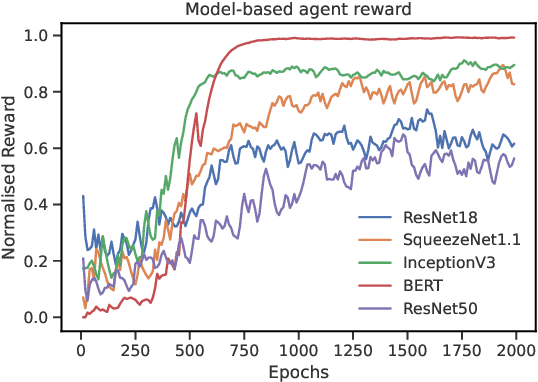
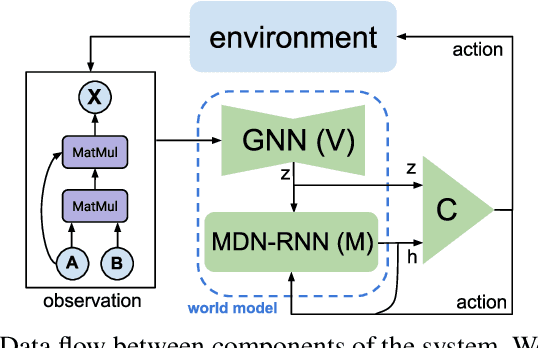
Training deep learning models takes an extremely long execution time and consumes large amounts of computing resources. At the same time, recent research proposed systems and compilers that are expected to decrease deep learning models runtime. An effective optimisation methodology in data processing is desirable, and the reduction of compute requirements of deep learning models is the focus of extensive research. In this paper, we address the neural network sub-graph transformation by exploring reinforcement learning (RL) agents to achieve performance improvement. Our proposed approach RLFlow can learn to perform neural network subgraph transformations, without the need for expertly designed heuristics to achieve a high level of performance. Recent work has aimed at applying RL to computer systems with some success, especially using model-free RL techniques. Model-based reinforcement learning methods have seen an increased focus in research as they can be used to learn the transition dynamics of the environment; this can be leveraged to train an agent using a hallucinogenic environment such as World Model (WM), thereby increasing sample efficiency compared to model-free approaches. WM uses variational auto-encoders and it builds a model of the system and allows exploring the model in an inexpensive way. In RLFlow, we propose a design for a model-based agent with WM which learns to optimise the architecture of neural networks by performing a sequence of sub-graph transformations to reduce model runtime. We show that our approach can match the state-of-the-art performance on common convolutional networks and outperforms by up to 5% those based on transformer-style architectures