 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Framework for Behavioral Disorder Detection Using Machine Learning and Application of Virtual Cognitive Behavioral Therapy in COVID-19 Pandemic
Apr 29, 2022
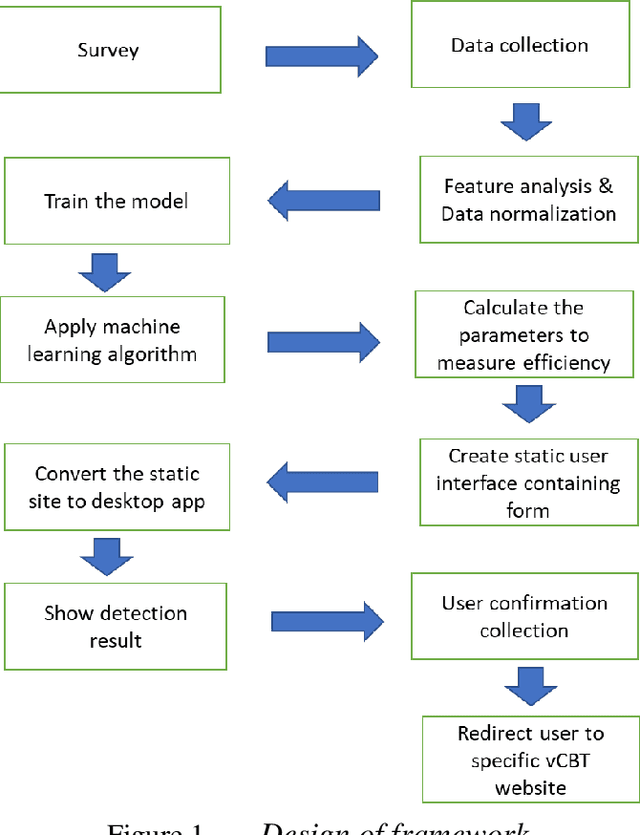
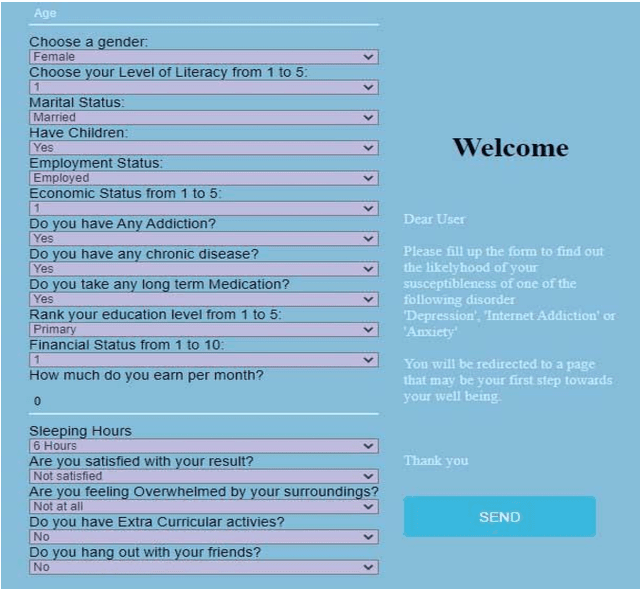


In this modern world, people are becoming more self-centered and unsocial. On the other hand, people are stressed, becoming more anxious during COVID-19 pandemic situation and exhibits symptoms of behavioral disorder. To measure the symptoms of behavioral disorder, usually psychiatrist use long hour sessions and inputs from specific questionnaire. This process is time consuming and sometime is ineffective to detect the right behavioral disorder. Also, reserved people sometime hesitate to follow this process. We have created a digital framework which can detect behavioral disorder and prescribe virtual Cognitive Behavioral Therapy (vCBT) for recovery. By using this framework people can input required data that are highly responsible for the three behavioral disorders namely depression, anxiety and internet addiction. We have applied machine learning technique to detect specific behavioral disorder from samples. This system guides the user with basic understanding and treatment through vCBT from anywhere any time which would potentially be the steppingstone for the user to be conscious and pursue right treatment.
Breaking Down Out-of-Distribution Detection: Many Methods Based on OOD Training Data Estimate a Combination of the Same Core Quantities
Jun 20, 2022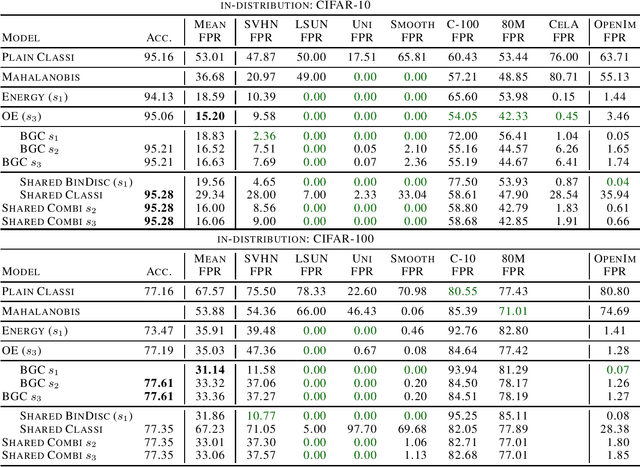
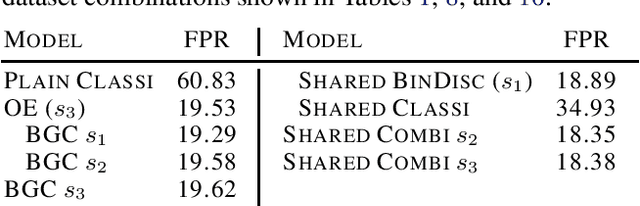


It is an important problem in trustworthy machine learning to recognize out-of-distribution (OOD) inputs which are inputs unrelated to the in-distribution task. Many out-of-distribution detection methods have been suggested in recent years. The goal of this paper is to recognize common objectives as well as to identify the implicit scoring functions of different OOD detection methods. We focus on the sub-class of methods that use surrogate OOD data during training in order to learn an OOD detection score that generalizes to new unseen out-distributions at test time. We show that binary discrimination between in- and (different) out-distributions is equivalent to several distinct formulations of the OOD detection problem. When trained in a shared fashion with a standard classifier, this binary discriminator reaches an OOD detection performance similar to that of Outlier Exposure. Moreover, we show that the confidence loss which is used by Outlier Exposure has an implicit scoring function which differs in a non-trivial fashion from the theoretically optimal scoring function in the case where training and test out-distribution are the same, which again is similar to the one used when training an Energy-Based OOD detector or when adding a background class. In practice, when trained in exactly the same way, all these methods perform similarly.
Deep Multi-Agent Reinforcement Learning with Hybrid Action Spaces based on Maximum Entropy
Jun 10, 2022

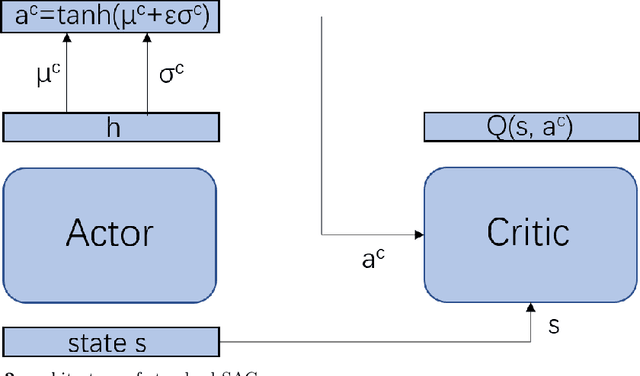
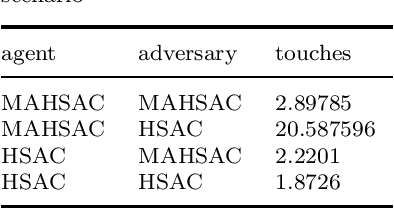
Multi-agent deep reinforcement learning has been applied to address a variety of complex problems with either discrete or continuous action spaces and achieved great success. However, most real-world environments cannot be described by only discrete action spaces or only continuous action spaces. And there are few works having ever utilized deep reinforcement learning (drl) to multi-agent problems with hybrid action spaces. Therefore, we propose a novel algorithm: Deep Multi-Agent Hybrid Soft Actor-Critic (MAHSAC) to fill this gap. This algorithm follows the centralized training but decentralized execution (CTDE) paradigm, and extend the Soft Actor-Critic algorithm (SAC) to handle hybrid action space problems in Multi-Agent environments based on maximum entropy. Our experiences are running on an easy multi-agent particle world with a continuous observation and discrete action space, along with some basic simulated physics. The experimental results show that MAHSAC has good performance in training speed, stability, and anti-interference ability. At the same time, it outperforms existing independent deep hybrid learning method in cooperative scenarios and competitive scenarios.
Permutation Search of Tensor Network Structures via Local Sampling
Jun 14, 2022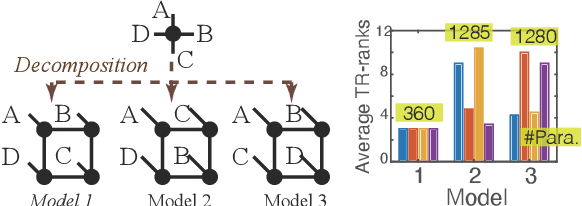
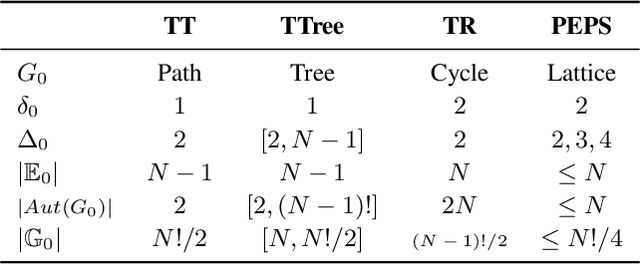
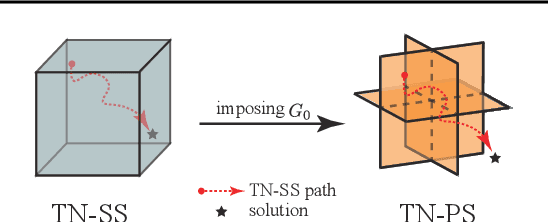
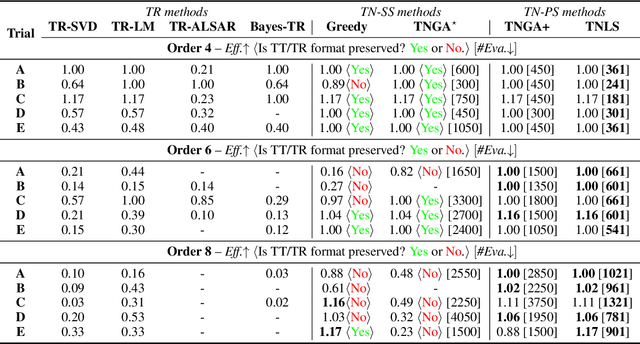
Recent works put much effort into tensor network structure search (TN-SS), aiming to select suitable tensor network (TN) structures, involving the TN-ranks, formats, and so on, for the decomposition or learning tasks. In this paper, we consider a practical variant of TN-SS, dubbed TN permutation search (TN-PS), in which we search for good mappings from tensor modes onto TN vertices (core tensors) for compact TN representations. We conduct a theoretical investigation of TN-PS and propose a practically-efficient algorithm to resolve the problem. Theoretically, we prove the counting and metric properties of search spaces of TN-PS, analyzing for the first time the impact of TN structures on these unique properties. Numerically, we propose a novel meta-heuristic algorithm, in which the searching is done by randomly sampling in a neighborhood established in our theory, and then recurrently updating the neighborhood until convergence. Numerical results demonstrate that the new algorithm can reduce the required model size of TNs in extensive benchmarks, implying the improvement in the expressive power of TNs. Furthermore, the computational cost for the new algorithm is significantly less than that in~\cite{li2020evolutionary}.
Structural Dropout for Model Width Compression
May 13, 2022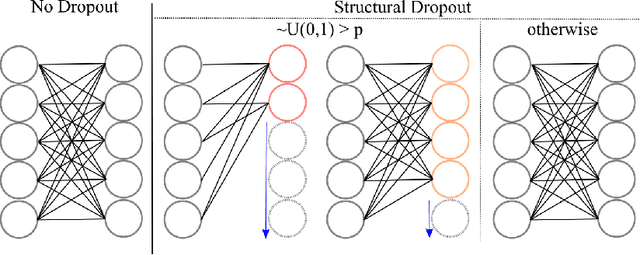

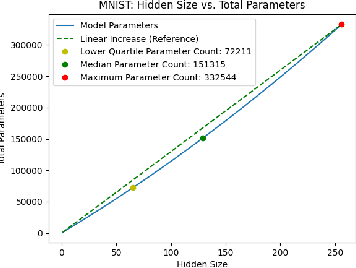
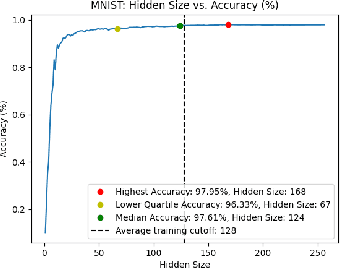
Existing ML models are known to be highly over-parametrized, and use significantly more resources than required for a given task. Prior work has explored compressing models offline, such as by distilling knowledge from larger models into much smaller ones. This is effective for compression, but does not give an empirical method for measuring how much the model can be compressed, and requires additional training for each compressed model. We propose a method that requires only a single training session for the original model and a set of compressed models. The proposed approach is a "structural" dropout that prunes all elements in the hidden state above a randomly chosen index, forcing the model to learn an importance ordering over its features. After learning this ordering, at inference time unimportant features can be pruned while retaining most accuracy, reducing parameter size significantly. In this work, we focus on Structural Dropout for fully-connected layers, but the concept can be applied to any kind of layer with unordered features, such as convolutional or attention layers. Structural Dropout requires no additional pruning/retraining, but requires additional validation for each possible hidden sizes. At inference time, a non-expert can select a memory versus accuracy trade-off that best suits their needs, across a wide range of highly compressed versus more accurate models.
No GPU? No problem: an ultra fast 3D detection of road users with a simple proposal generator and energy-based out-of-distribution PointNets
Jun 06, 2022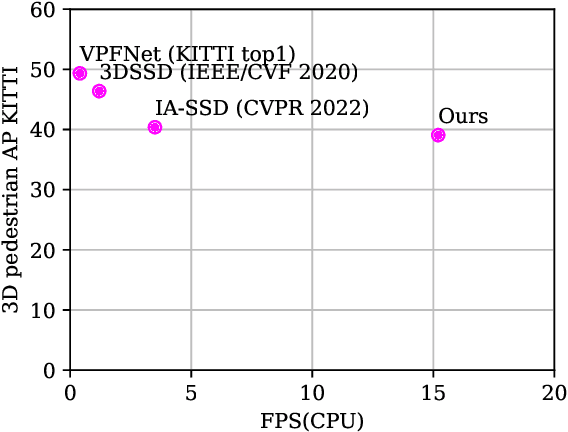
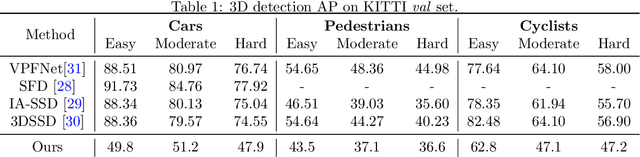
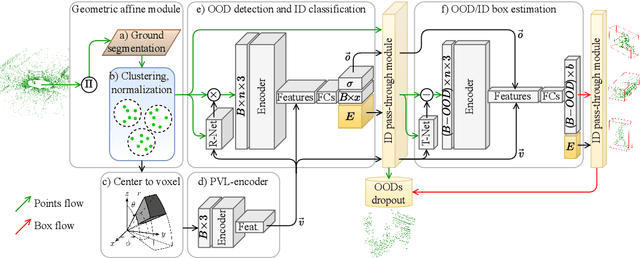
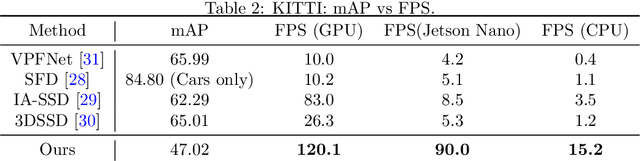
This paper presents a novel architecture for point cloud road user detection, which is based on a classical point cloud proposal generator approach, that utilizes simple geometrical rules. New methods are coupled with this technique to achieve extremely small computational requirement, and mAP that is comparable to the state-of-the-art. The idea is to specifically exploit geometrical rules in hopes of faster performance. The typical downsides of this approach, e.g. global context loss, are tackled in this paper, and solutions are presented. This approach allows real-time performance on a single core CPU, which is not the case with end-to-end solutions presented in the state-of-the-art. We have evaluated the performance of the method with the public KITTI dataset, and with our own annotated dataset collected with a small mobile robot platform. Moreover, we also present a novel ground segmentation method, which is evaluated with the public SemanticKITTI dataset.
Knowledge Distillation for Oriented Object Detection on Aerial Images
Jun 20, 2022
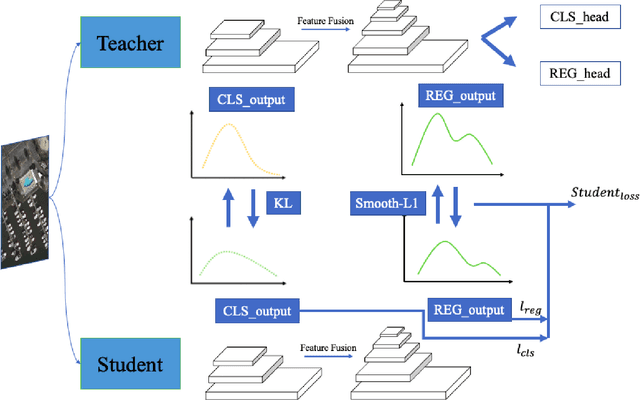
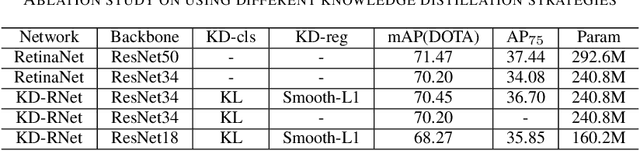
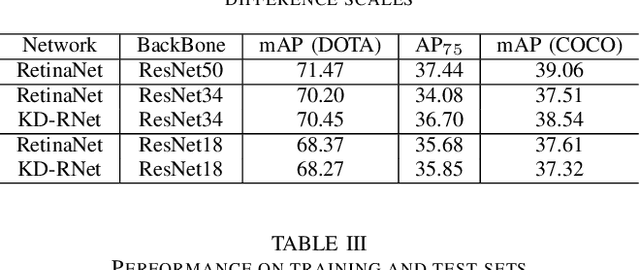
Deep convolutional neural network with increased number of parameters has achieved improved precision in task of object detection on natural images, where objects of interests are annotated with horizontal boundary boxes. On aerial images captured from the bird-view perspective, these improvements on model architecture and deeper convolutional layers can also boost the performance on oriented object detection task. However, it is hard to directly apply those state-of-the-art object detectors on the devices with limited computation resources, which necessitates lightweight models through model compression. In order to address this issue, we present a model compression method for rotated object detection on aerial images by knowledge distillation, namely KD-RNet. With a well-trained teacher oriented object detector with a large number of parameters, the obtained object category and location information are both transferred to a compact student network in KD-RNet by collaborative training strategy. Transferring the category information is achieved by knowledge distillation on predicted probability distribution, and a soft regression loss is adopted for handling displacement in location information transfer. The experimental result on a large-scale aerial object detection dataset (DOTA) demonstrates that the proposed KD-RNet model can achieve improved mean-average precision (mAP) with reduced number of parameters, at the same time, KD-RNet boost the performance on providing high quality detections with higher overlap with groundtruth annotations.
Time-Aware Tensor Decomposition for Missing Entry Prediction
Dec 16, 2020
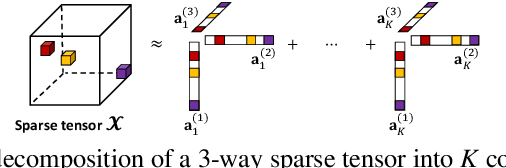
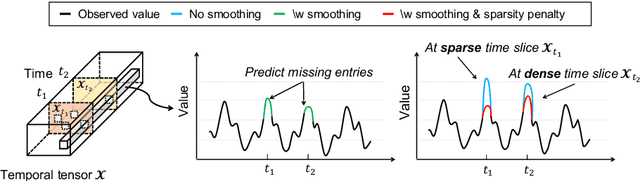

Given a time-evolving tensor with missing entries, how can we effectively factorize it for precisely predicting the missing entries? Tensor factorization has been extensively utilized for analyzing various multi-dimensional real-world data. However, existing models for tensor factorization have disregarded the temporal property for tensor factorization while most real-world data are closely related to time. Moreover, they do not address accuracy degradation due to the sparsity of time slices. The essential problems of how to exploit the temporal property for tensor decomposition and consider the sparsity of time slices remain unresolved. In this paper, we propose TATD (Time-Aware Tensor Decomposition), a novel tensor decomposition method for real-world temporal tensors. TATD is designed to exploit temporal dependency and time-varying sparsity of real-world temporal tensors. We propose a new smoothing regularization with Gaussian kernel for modeling time dependency. Moreover, we improve the performance of TATD by considering time-varying sparsity. We design an alternating optimization scheme suitable for temporal tensor factorization with our smoothing regularization. Extensive experiments show that TATD provides the state-of-the-art accuracy for decomposing temporal tensors.
EvoVGM: A Deep Variational Generative Model for Evolutionary Parameter Estimation
May 25, 2022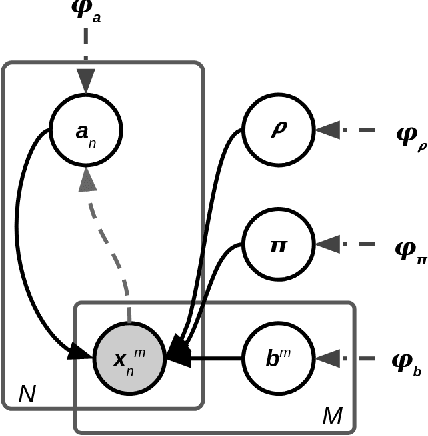
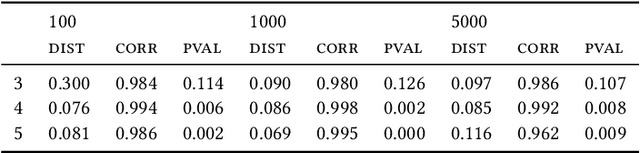
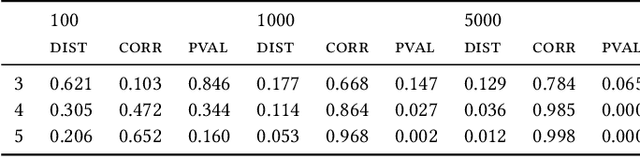
Most evolutionary-oriented deep generative models do not explicitly consider the underlying evolutionary dynamics of biological sequences as it is performed within the Bayesian phylogenetic inference framework. In this study, we propose a method for a deep variational Bayesian generative model that jointly approximates the true posterior of local biological evolutionary parameters and generates sequence alignments. Moreover, it is instantiated and tuned for continuous-time Markov chain substitution models such as JC69 and GTR. We train the model via a low-variance variational objective function and a gradient ascent algorithm. Here, we show the consistency and effectiveness of the method on synthetic sequence alignments simulated with several evolutionary scenarios and on a real virus sequence alignment.
One Step at a Time: Long-Horizon Vision-and-Language Navigation with Milestones
Feb 14, 2022

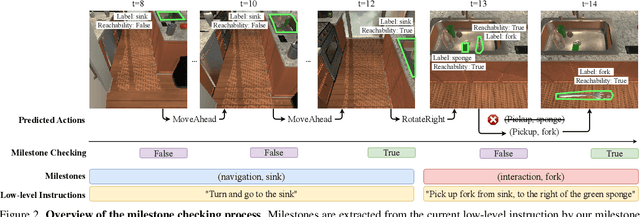
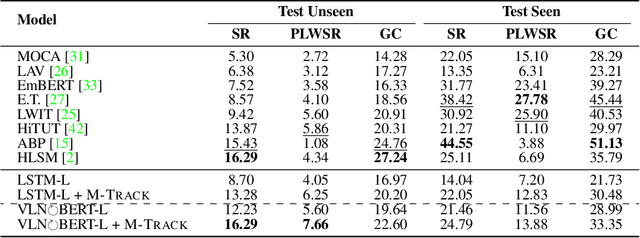
We study the problem of developing autonomous agents that can follow human instructions to infer and perform a sequence of actions to complete the underlying task. Significant progress has been made in recent years, especially for tasks with short horizons. However, when it comes to long-horizon tasks with extended sequences of actions, an agent can easily ignore some instructions or get stuck in the middle of the long instructions and eventually fail the task. To address this challenge, we propose a model-agnostic milestone-based task tracker (M-TRACK) to guide the agent and monitor its progress. Specifically, we propose a milestone builder that tags the instructions with navigation and interaction milestones which the agent needs to complete step by step, and a milestone checker that systemically checks the agent's progress in its current milestone and determines when to proceed to the next. On the challenging ALFRED dataset, our M-TRACK leads to a notable 45% and 70% relative improvement in unseen success rate over two competitive base models.