 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ensemble neuroevolution based approach for multivariate time series anomaly detection
Aug 08, 2021
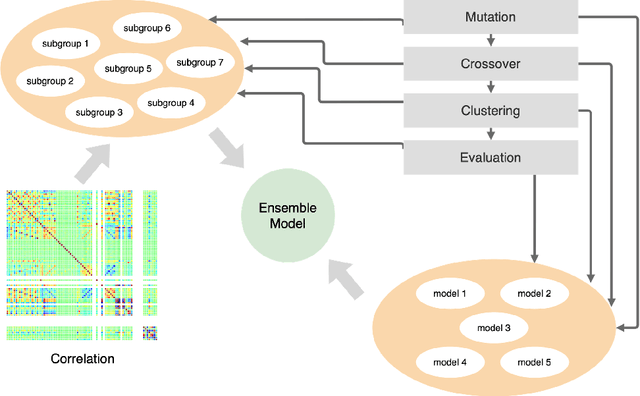
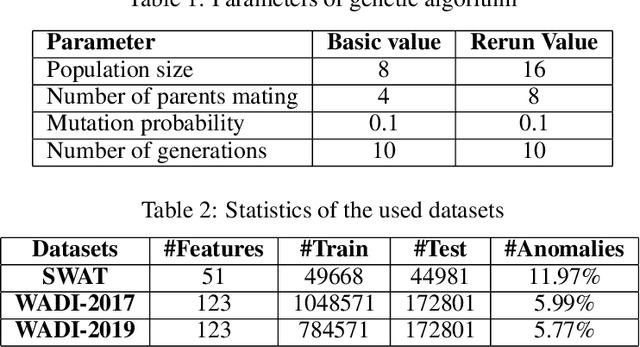
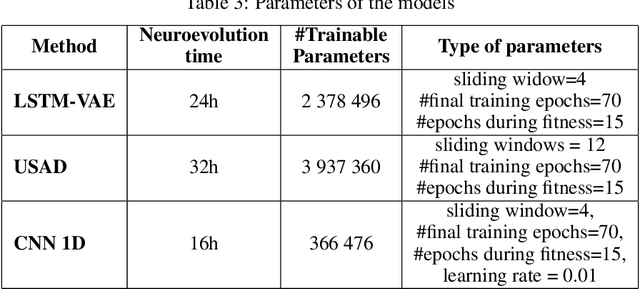
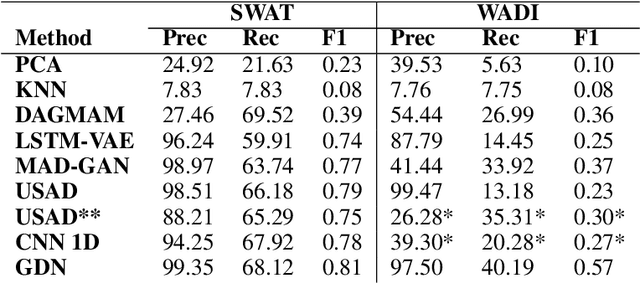
Multivariate time series anomaly detection is a very common problem in the field of failure prevention. Fast prevention means lower repair costs and losses. The amount of sensors in novel industry systems makes the anomaly detection process quite difficult for humans. Algorithms which automates the process of detecting anomalies are crucial in modern failure-prevention systems. Therefore, many machine and deep learning models have been designed to address this problem. Mostly, they are autoencoder-based architectures with some generative adversarial elements. In this work, a framework is shown which incorporates neuroevolution methods to boost the anomaly-detection scores of new and already known models. The presented approach adapts evolution strategies for evolving ensemble model, in which every single model works on a subgroup of data sensors. The next goal of neuroevolution is to optimise architecture and hyperparameters like window size, the number of layers, layer depths, etc. The proposed framework shows that it is possible to boost most of the anomaly detection deep learning models in a reasonable time and a fully automated mode. The tests were run on SWAT and WADI datasets. To our knowledge, this is the first approach in which an ensemble deep learning anomaly detection model is built in a fully automatic way using a neuroevolution strategy.
Unsupervised inter-frame motion correction for whole-body dynamic PET using convolutional long short-term memory in a convolutional neural network
Jun 13, 2022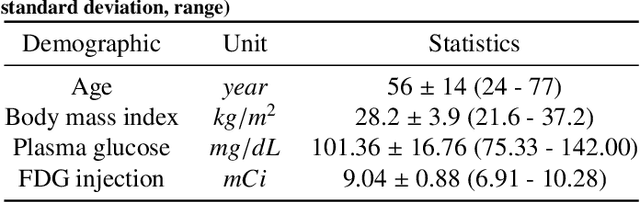
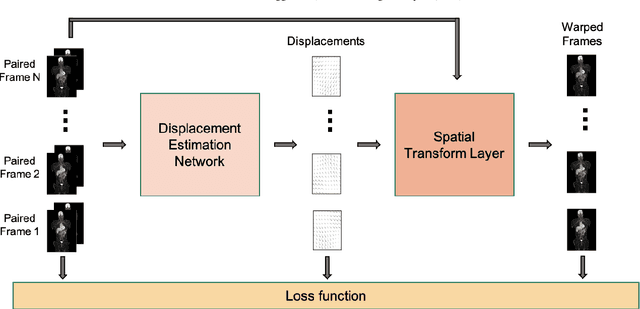
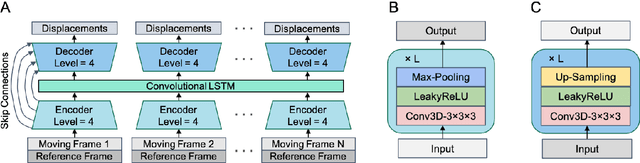
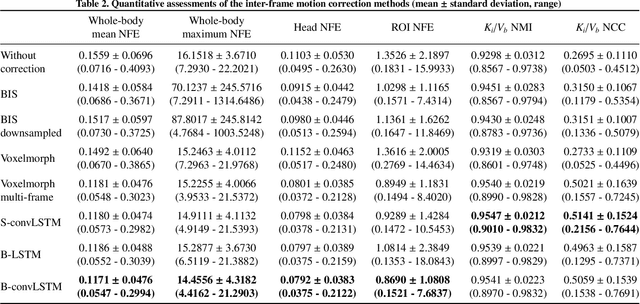
Subject motion in whole-body dynamic PET introduces inter-frame mismatch and seriously impacts parametric imaging. Traditional non-rigid registration methods are generally computationally intense and time-consuming. Deep learning approaches are promising in achieving high accuracy with fast speed, but have yet been investigated with consideration for tracer distribution changes or in the whole-body scope. In this work, we developed an unsupervised automatic deep learning-based framework to correct inter-frame body motion. The motion estimation network is a convolutional neural network with a combined convolutional long short-term memory layer, fully utilizing dynamic temporal features and spatial information. Our dataset contains 27 subjects each under a 90-min FDG whole-body dynamic PET scan. With 9-fold cross-validation, compared with both traditional and deep learning baselines, we demonstrated that the proposed network obtained superior performance in enhanced qualitative and quantitative spatial alignment between parametric $K_{i}$ and $V_{b}$ images and in significantly reduced parametric fitting error. We also showed the potential of the proposed motion correction method for impacting downstream analysis of the estimated parametric images, improving the ability to distinguish malignant from benign hypermetabolic regions of interest. Once trained, the motion estimation inference time of our proposed network was around 460 times faster than the conventional registration baseline, showing its potential to be easily applied in clinical settings.
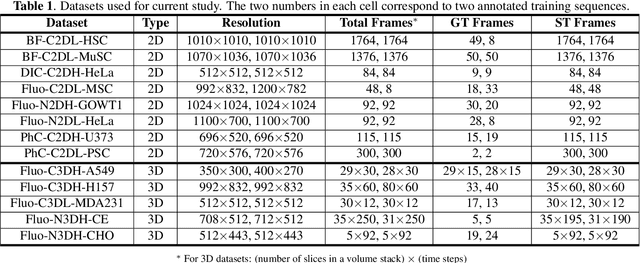
Training a universal instance segmentation network for live cell images of various cell types and imaging modalities
Jul 28, 2022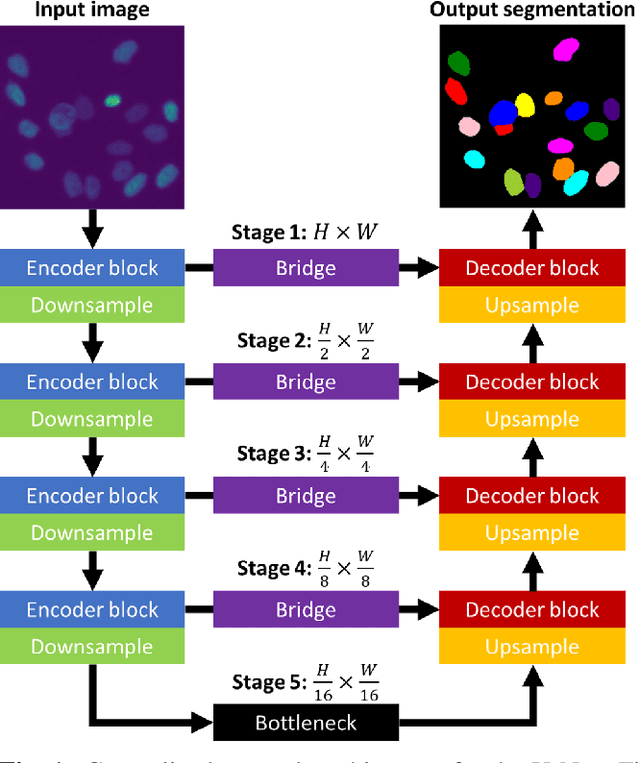

We share our recent findings in an attempt to train a universal segmentation network for various cell types and imaging modalities. Our method was built on the generalized U-Net architecture, which allows the evaluation of each component individually. We modified the traditional binary training targets to include three classes for direct instance segmentation. Detailed experiments were performed regarding training schemes, training settings, network backbones, and individual modules on the segmentation performance. Our proposed training scheme draws minibatches in turn from each dataset, and the gradients are accumulated before an optimization step. We found that the key to training a universal network is all-time supervision on all datasets, and it is necessary to sample each dataset in an unbiased way. Our experiments also suggest that there might exist common features to define cell boundaries across cell types and imaging modalities, which could allow application of trained models to totally unseen datasets. A few training tricks can further boost the segmentation performance, including uneven class weights in the cross-entropy loss function, well-designed learning rate scheduler, larger image crops for contextual information, and additional loss terms for unbalanced classes. We also found that segmentation performance can benefit from group normalization layer and Atrous Spatial Pyramid Pooling module, thanks to their more reliable statistics estimation and improved semantic understanding, respectively. We participated in the 6th Cell Tracking Challenge (CTC) held at IEEE International Symposium on Biomedical Imaging (ISBI) 2021 using one of the developed variants. Our method was evaluated as the best runner up during the initial submission for the primary track, and also secured the 3rd place in an additional round of competition in preparation for the summary publication.
Hidden Parameter Recurrent State Space Models For Changing Dynamics Scenarios
Jun 29, 2022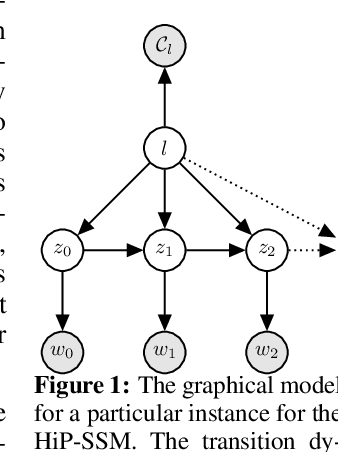

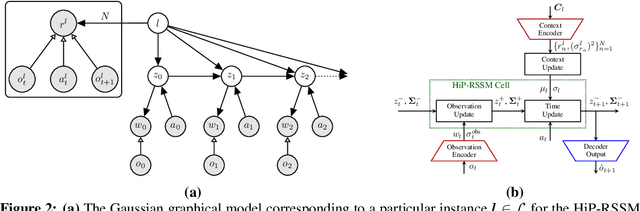
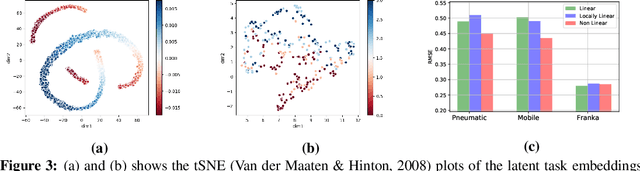
Recurrent State-space models (RSSMs) are highly expressive models for learning patterns in time series data and system identification. However, these models assume that the dynamics are fixed and unchanging, which is rarely the case in real-world scenarios. Many control applications often exhibit tasks with similar but not identical dynamics which can be modeled as a latent variable. We introduce the Hidden Parameter Recurrent State Space Models (HiP-RSSMs), a framework that parametrizes a family of related dynamical systems with a low-dimensional set of latent factors. We present a simple and effective way of learning and performing inference over this Gaussian graphical model that avoids approximations like variational inference. We show that HiP-RSSMs outperforms RSSMs and competing multi-task models on several challenging robotic benchmarks both on real-world systems and simulations.
A Survey on Collaborative DNN Inference for Edge Intelligence
Jul 16, 2022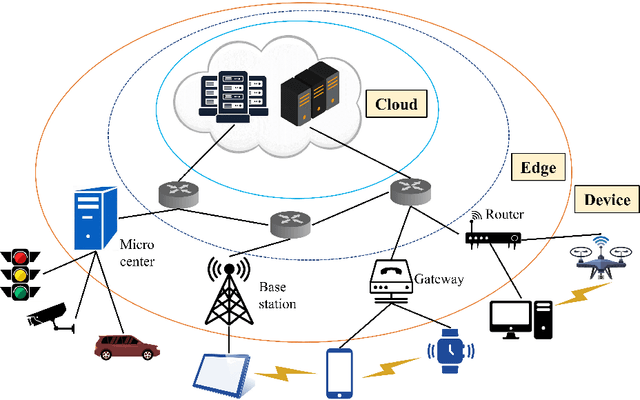
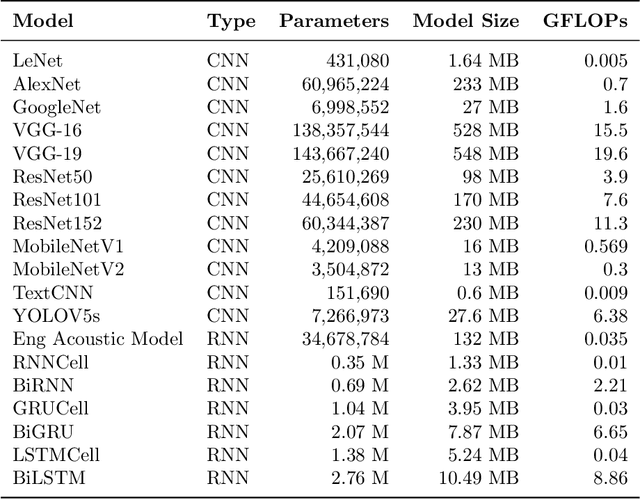
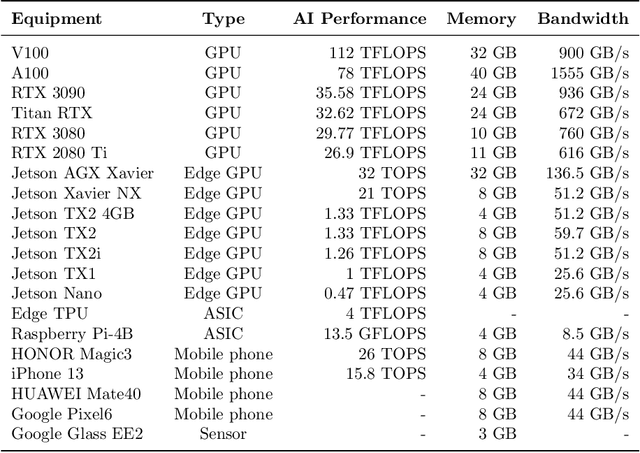
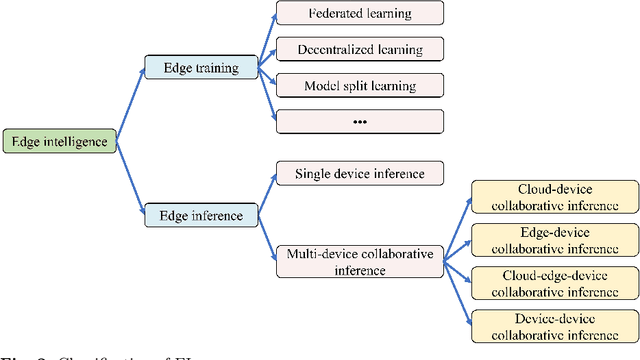
With the vigorous development of artificial intelligence (AI), the intelligent applications based on deep neural network (DNN) change people's lifestyles and the production efficiency. However, the huge amount of computation and data generated from the network edge becomes the major bottleneck, and traditional cloud-based computing mode has been unable to meet the requirements of real-time processing tasks. To solve the above problems, by embedding AI model training and inference capabilities into the network edge, edge intelligence (EI) becomes a cutting-edge direction in the field of AI. Furthermore, collaborative DNN inference among the cloud, edge, and end device provides a promising way to boost the EI. Nevertheless, at present, EI oriented collaborative DNN inference is still in its early stage, lacking a systematic classification and discussion of existing research efforts. Thus motivated, we have made a comprehensive investigation on the recent studies about EI oriented collaborative DNN inference. In this paper, we firstly review the background and motivation of EI. Then, we classify four typical collaborative DNN inference paradigms for EI, and analyze the characteristics and key technologies of them. Finally, we summarize the current challenges of collaborative DNN inference, discuss the future development trend and provide the future research direction.
Defending Substitution-Based Profile Pollution Attacks on Sequential Recommenders
Jul 19, 2022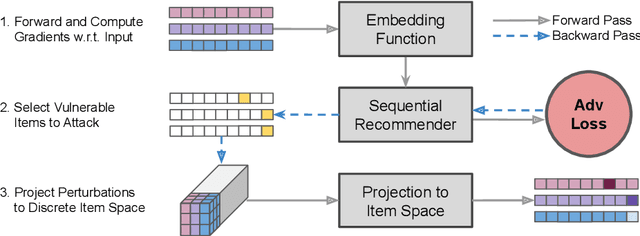

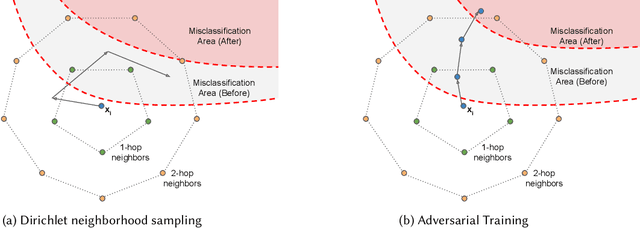
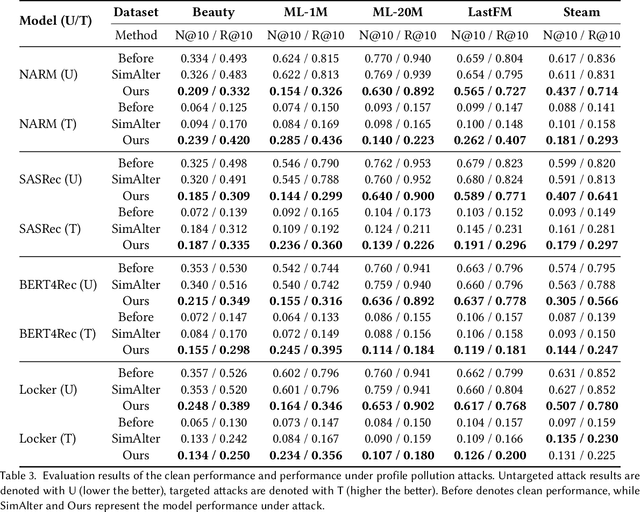
While sequential recommender systems achieve significant improvements on capturing user dynamics, we argue that sequential recommenders are vulnerable against substitution-based profile pollution attacks. To demonstrate our hypothesis, we propose a substitution-based adversarial attack algorithm, which modifies the input sequence by selecting certain vulnerable elements and substituting them with adversarial items. In both untargeted and targeted attack scenarios, we observe significant performance deterioration using the proposed profile pollution algorithm. Motivated by such observations, we design an efficient adversarial defense method called Dirichlet neighborhood sampling. Specifically, we sample item embeddings from a convex hull constructed by multi-hop neighbors to replace the original items in input sequences. During sampling, a Dirichlet distribution is used to approximate the probability distribution in the neighborhood such that the recommender learns to combat local perturbations. Additionally, we design an adversarial training method tailored for sequential recommender systems. In particular, we represent selected items with one-hot encodings and perform gradient ascent on the encodings to search for the worst case linear combination of item embeddings in training. As such, the embedding function learns robust item representations and the trained recommender is resistant to test-time adversarial examples. Extensive experiments show the effectiveness of both our attack and defense methods, which consistently outperform baselines by a significant margin across model architectures and datasets.
Pretraining on Interactions for Learning Grounded Affordance Representations
Jul 05, 2022
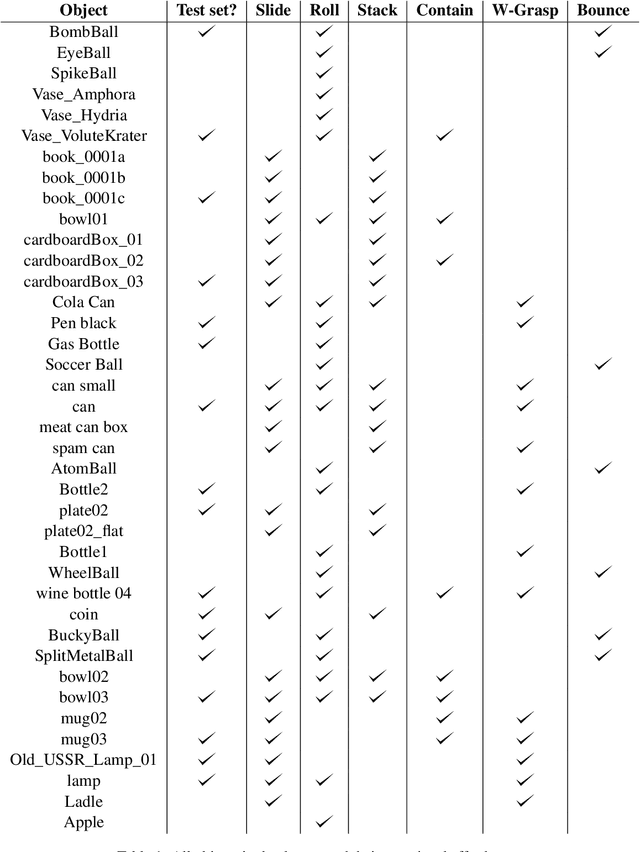

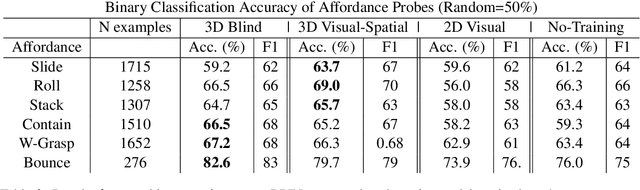
Lexical semantics and cognitive science point to affordances (i.e. the actions that objects support) as critical for understanding and representing nouns and verbs. However, study of these semantic features has not yet been integrated with the "foundation" models that currently dominate language representation research. We hypothesize that predictive modeling of object state over time will result in representations that encode object affordance information "for free". We train a neural network to predict objects' trajectories in a simulated interaction and show that our network's latent representations differentiate between both observed and unobserved affordances. We find that models trained using 3D simulations from our SPATIAL dataset outperform conventional 2D computer vision models trained on a similar task, and, on initial inspection, that differences between concepts correspond to expected features (e.g., roll entails rotation). Our results suggest a way in which modern deep learning approaches to grounded language learning can be integrated with traditional formal semantic notions of lexical representations.
End-to-End License Plate Recognition Pipeline for Real-time Low Resource Video Based Applications
Aug 18, 2021

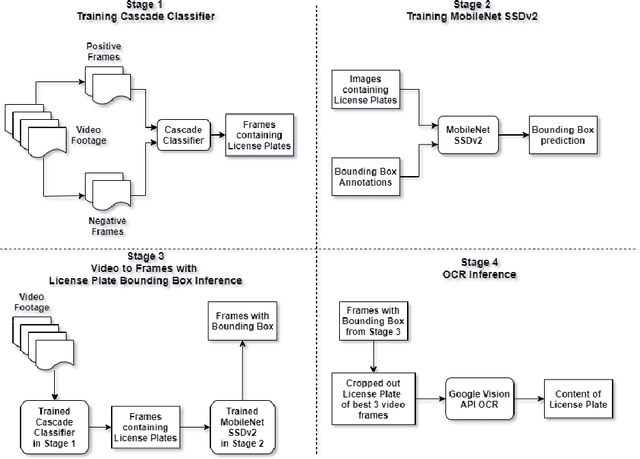
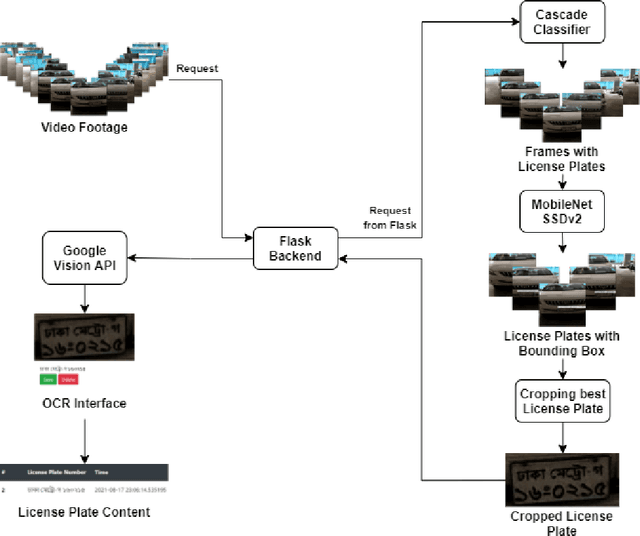
Automatic License Plate Recognition systems aim to provide an end-to-end solution towards detecting, localizing, and recognizing license plate characters from vehicles appearing in video frames. However, deploying such systems in the real world requires real-time performance in low-resource environments. In our paper, we propose a novel two-stage detection pipeline paired with Vision API that aims to provide real-time inference speed along with consistently accurate detection and recognition performance. We used a haar-cascade classifier as a filter on top of our backbone MobileNet SSDv2 detection model. This reduces inference time by only focusing on high confidence detections and using them for recognition. We also impose a temporal frame separation strategy to identify multiple vehicle license plates in the same clip. Furthermore, there are no publicly available Bangla license plate datasets, for which we created an image dataset and a video dataset containing license plates in the wild. We trained our models on the image dataset and achieved an AP(0.5) score of 86% and tested our pipeline on the video dataset and observed reasonable detection and recognition performance (82.7% detection rate, and 60.8% OCR F1 score) with real-time processing speed (27.2 frames per second).
A Conceptual Framework for Using Machine Learning to Support Child Welfare Decisions
Jul 12, 2022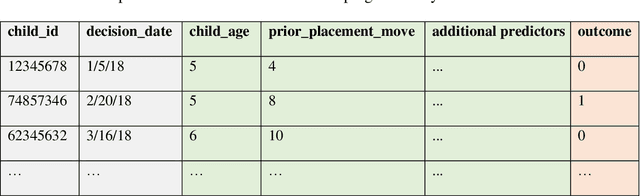
Human services systems make key decisions that impact individuals in the society. The U.S. child welfare system makes such decisions, from screening-in hotline reports of suspected abuse or neglect for child protective investigations, placing children in foster care, to returning children to permanent home settings. These complex and impactful decisions on children's lives rely on the judgment of child welfare decisionmakers. Child welfare agencies have been exploring ways to support these decisions with empirical, data-informed methods that include machine learning (ML). This paper describes a conceptual framework for ML to support child welfare decisions. The ML framework guides how child welfare agencies might conceptualize a target problem that ML can solve; vet available administrative data for building ML; formulate and develop ML specifications that mirror relevant populations and interventions the agencies are undertaking; deploy, evaluate, and monitor ML as child welfare context, policy, and practice change over time. Ethical considerations, stakeholder engagement, and avoidance of common pitfalls underpin the framework's impact and success. From abstract to concrete, we describe one application of this framework to support a child welfare decision. This ML framework, though child welfare-focused, is generalizable to solving other public policy problems.
Positioning Fog Computing for Smart Manufacturing
May 22, 2022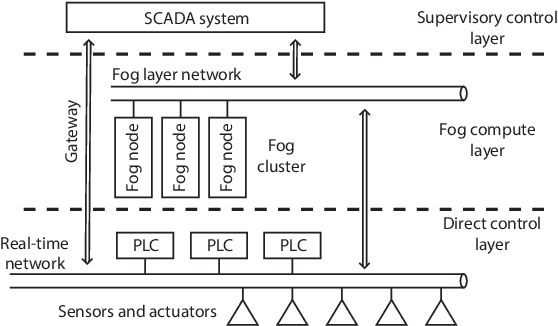
We study machine learning systems for real-time industrial quality control. In many factory systems, production processes must be continuously controlled in order to maintain product quality. Especially challenging are the systems that must balance in real-time between stringent resource consumption constraints and the risk of defective end-product. There is a need for automated quality control systems as human control is tedious and error-prone. We see machine learning as a viable choice for developing automated quality control systems, but integrating such system with existing factory automation remains a challenge. In this paper we propose introducing a new fog computing layer to the standard hierarchy of automation control to meet the needs of machine learning driven quality control.