 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FEANet: Feature-Enhanced Attention Network for RGB-Thermal Real-time Semantic Segmentation
Oct 18, 2021
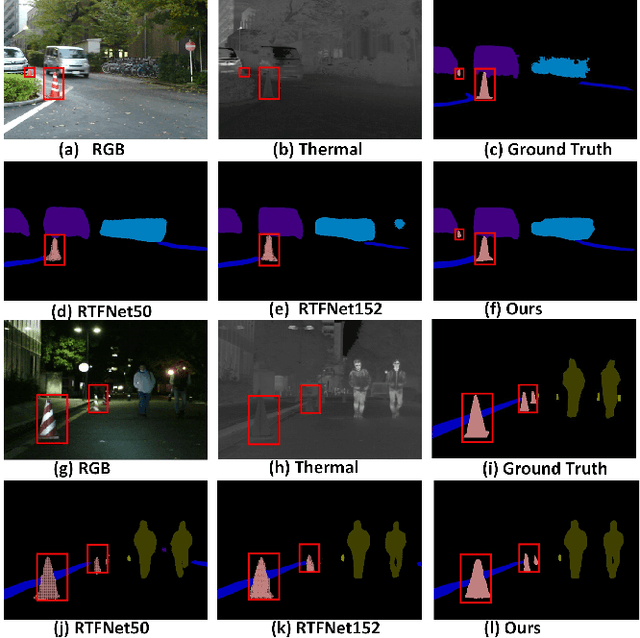
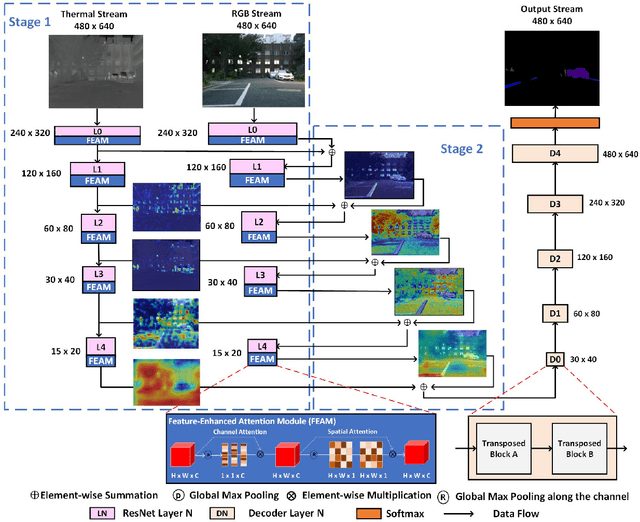
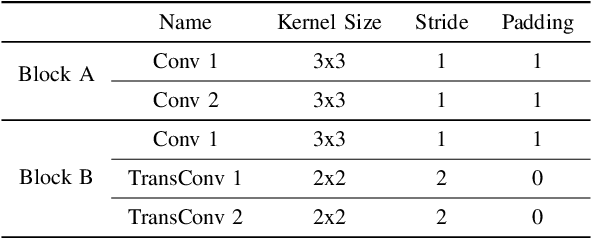
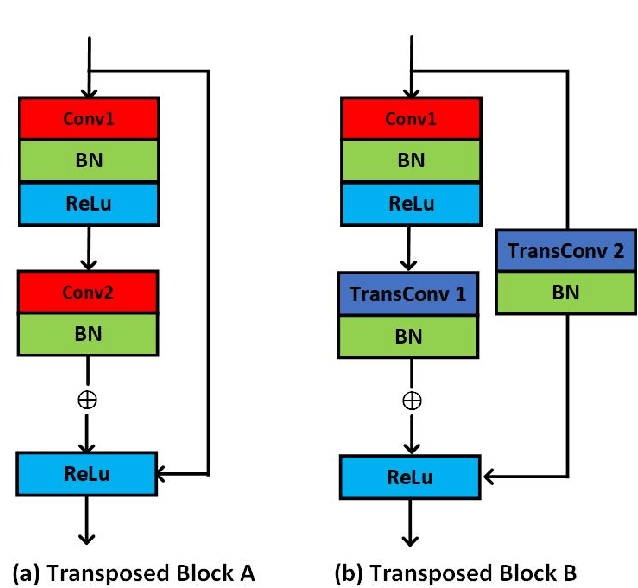
The RGB-Thermal (RGB-T) information for semantic segmentation has been extensively explored in recent years. However, most existing RGB-T semantic segmentation usually compromises spatial resolution to achieve real-time inference speed, which leads to poor performance. To better extract detail spatial information, we propose a two-stage Feature-Enhanced Attention Network (FEANet) for the RGB-T semantic segmentation task. Specifically, we introduce a Feature-Enhanced Attention Module (FEAM) to excavate and enhance multi-level features from both the channel and spatial views. Benefited from the proposed FEAM module, our FEANet can preserve the spatial information and shift more attention to high-resolution features from the fused RGB-T images. Extensive experiments on the urban scene dataset demonstrate that our FEANet outperforms other state-of-the-art (SOTA) RGB-T methods in terms of objective metrics and subjective visual comparison (+2.6% in global mAcc and +0.8% in global mIoU). For the 480 x 640 RGB-T test images, our FEANet can run with a real-time speed on an NVIDIA GeForce RTX 2080 Ti card.
Predicting microsatellite instability and key biomarkers in colorectal cancer from H&E-stained images: Achieving SOTA with Less Data using Swin Transformer
Aug 22, 2022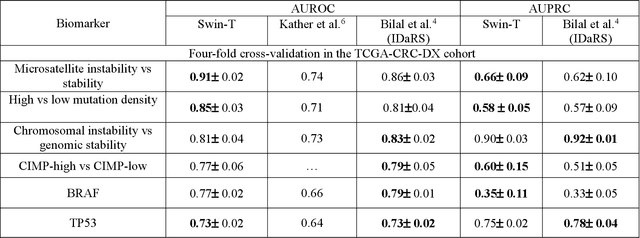
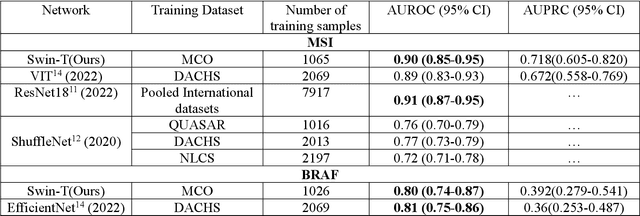
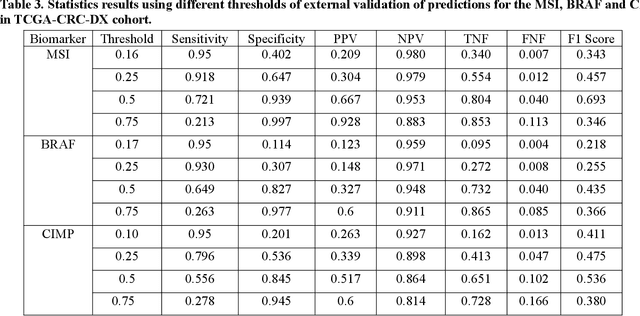
Artificial intelligence (AI) models have been developed for predicting clinically relevant biomarkers, including microsatellite instability (MSI), for colorectal cancers (CRC). However, the current deep-learning networks are data-hungry and require large training datasets, which are often lacking in the medical domain. In this study, based on the latest Hierarchical Vision Transformer using Shifted Windows (Swin-T), we developed an efficient workflow for biomarkers in CRC (MSI, hypermutation, chromosomal instability, CpG island methylator phenotype, BRAF, and TP53 mutation) that only required relatively small datasets, but achieved the state-of-the-art (SOTA) predictive performance. Our Swin-T workflow not only substantially outperformed published models in an intra-study cross-validation experiment using TCGA-CRC-DX dataset (N = 462), but also showed excellent generalizability in cross-study external validation and delivered a SOTA AUROC of 0.90 for MSI using the MCO dataset for training (N = 1065) and the same TCGA-CRC-DX for testing. Similar performance (AUROC=0.91) was achieved by Echle and colleagues using 8000 training samples (ResNet18) on the same testing dataset. Swin-T was extremely efficient using small training datasets and exhibits robust predictive performance with only 200-500 training samples. These data indicate that Swin-T may be 5-10 times more efficient than the current state-of-the-art algorithms for MSI based on ResNet18 and ShuffleNet. Furthermore, the Swin-T models showed promise as pre-screening tests for MSI status and BRAF mutation status, which could exclude and reduce the samples before the subsequent standard testing in a cascading diagnostic workflow to allow turnaround time reduction and cost saving.
FixMatchSeg: Fixing FixMatch for Semi-Supervised Semantic Segmentation
Aug 02, 2022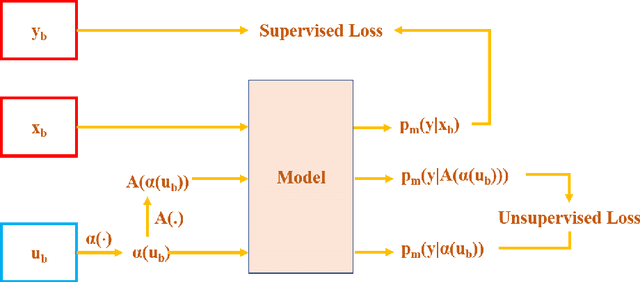
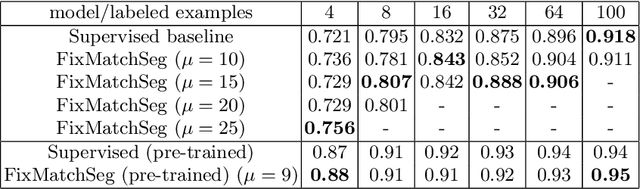
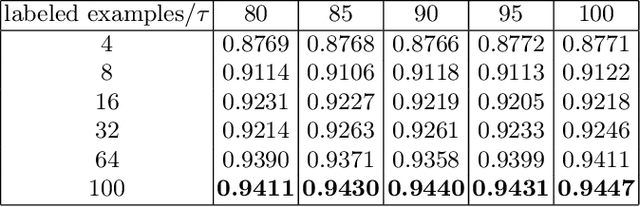
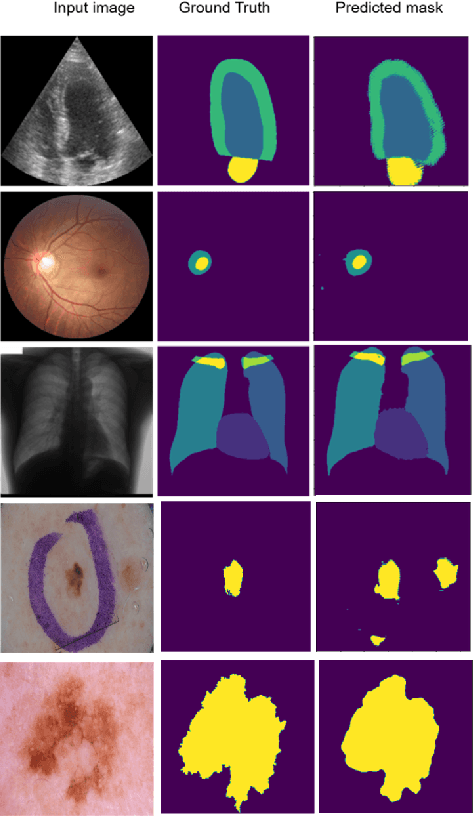
Supervised deep learning methods for semantic medical image segmentation are getting increasingly popular in the past few years.However, in resource constrained settings, getting large number of annotated images is very difficult as it mostly requires experts, is expensive and time-consuming.Semi-supervised segmentation can be an attractive solution where a very few labeled images are used along with a large number of unlabeled ones. While the gap between supervised and semi-supervised methods have been dramatically reduced for classification problems in the past couple of years, there still remains a larger gap in segmentation methods. In this work, we adapt a state-of-the-art semi-supervised classification method FixMatch to semantic segmentation task, introducing FixMatchSeg. FixMatchSeg is evaluated in four different publicly available datasets of different anatomy and different modality: cardiac ultrasound, chest X-ray, retinal fundus image, and skin images. When there are few labels, we show that FixMatchSeg performs on par with strong supervised baselines.
Learning to Reconstruct Missing Data from Spatiotemporal Graphs with Sparse Observations
May 26, 2022
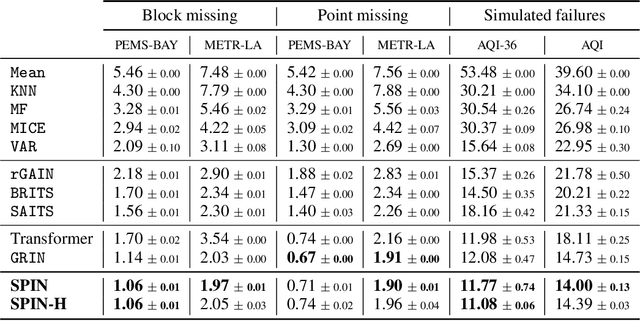
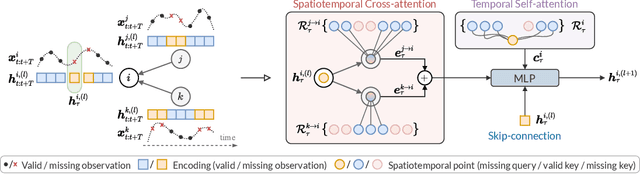
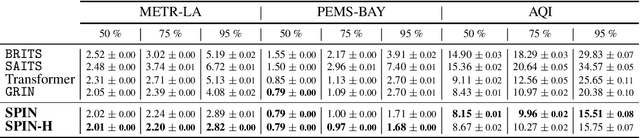
Modeling multivariate time series as temporal signals over a (possibly dynamic) graph is an effective representational framework that allows for developing models for time series analysis. In fact, discrete sequences of graphs can be processed by autoregressive graph neural networks to recursively learn representations at each discrete point in time and space. Spatiotemporal graphs are often highly sparse, with time series characterized by multiple, concurrent, and even long sequences of missing data, e.g., due to the unreliable underlying sensor network. In this context, autoregressive models can be brittle and exhibit unstable learning dynamics. The objective of this paper is, then, to tackle the problem of learning effective models to reconstruct, i.e., impute, missing data points by conditioning the reconstruction only on the available observations. In particular, we propose a novel class of attention-based architectures that, given a set of highly sparse discrete observations, learn a representation for points in time and space by exploiting a spatiotemporal diffusion architecture aligned with the imputation task. Representations are trained end-to-end to reconstruct observations w.r.t. the corresponding sensor and its neighboring nodes. Compared to the state of the art, our model handles sparse data without propagating prediction errors or requiring a bidirectional model to encode forward and backward time dependencies. Empirical results on representative benchmarks show the effectiveness of the proposed method.
Long-term dynamics of fairness: understanding the impact of data-driven targeted help on job seekers
Aug 17, 2022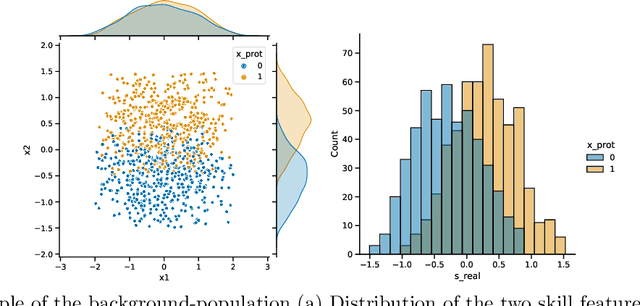
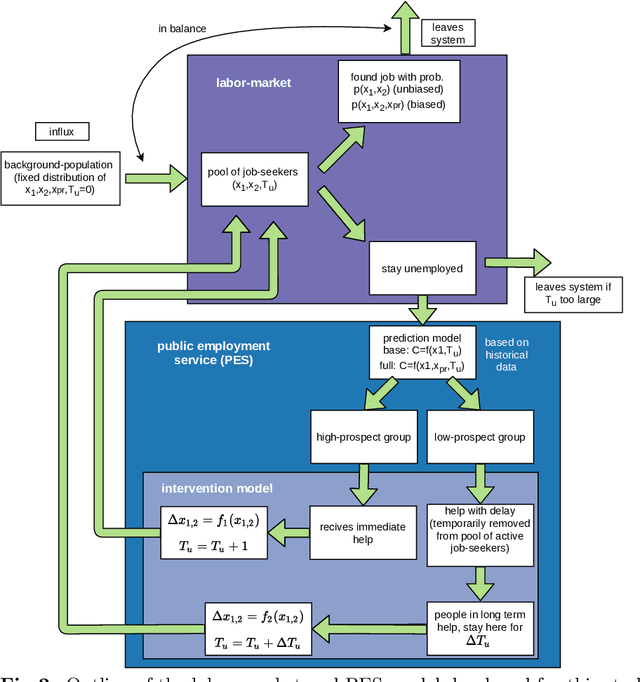
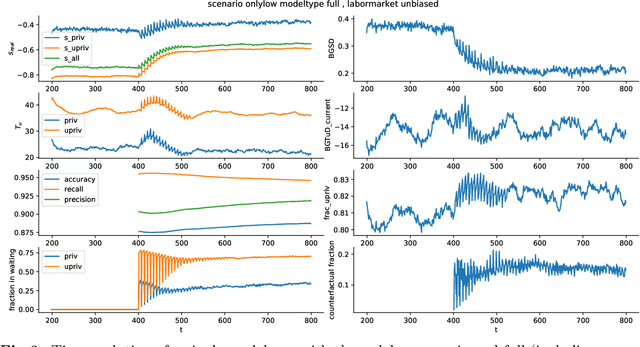
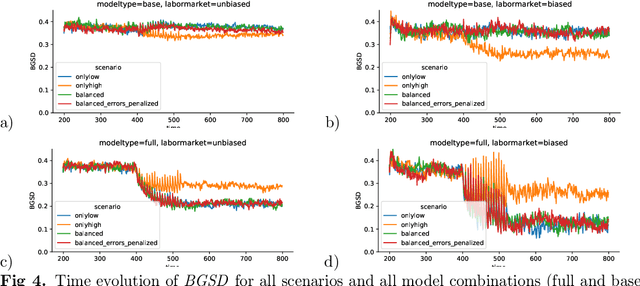
The use of data-driven decision support by public agencies is becoming more widespread and already influences the allocation of public resources. This raises ethical concerns, as it has adversely affected minorities and historically discriminated groups. In this paper, we use an approach that combines statistics and machine learning with dynamical modeling to assess long-term fairness effects of labor market interventions. Specifically, we develop and use a model to investigate the impact of decisions caused by a public employment authority that selectively supports job-seekers through targeted help. The selection of who receives what help is based on a data-driven intervention model that estimates an individual's chances of finding a job in a timely manner and is based on data that describes a population in which skills relevant to the labor market are unevenly distributed between two groups (e.g., males and females). The intervention model has incomplete access to the individual's actual skills and can augment this with knowledge of the individual's group affiliation, thus using a protected attribute to increase predictive accuracy. We assess this intervention model's dynamics -- especially fairness-related issues and trade-offs between different fairness goals -- over time and compare it to an intervention model that does not use group affiliation as a predictive feature. We conclude that in order to quantify the trade-off correctly and to assess the long-term fairness effects of such a system in the real-world, careful modeling of the surrounding labor market is indispensable.
Boosted Embeddings for Time Series Forecasting
Apr 10, 2021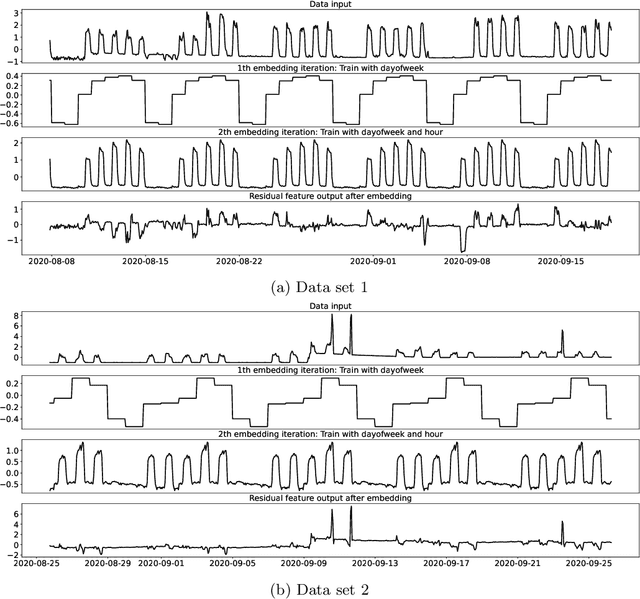

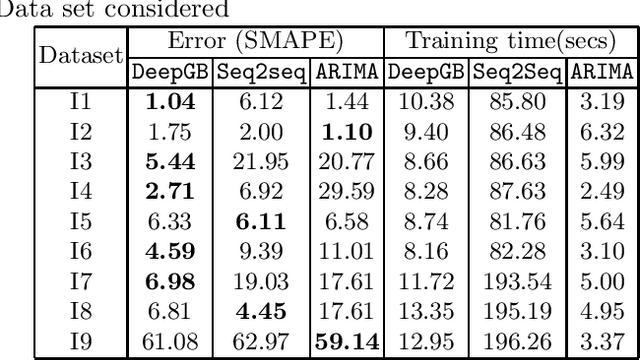
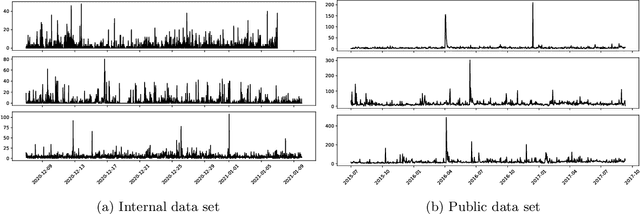
Time series forecasting is a fundamental task emerging from diverse data-driven applications. Many advanced autoregressive methods such as ARIMA were used to develop forecasting models. Recently, deep learning based methods such as DeepAr, NeuralProphet, Seq2Seq have been explored for time series forecasting problem. In this paper, we propose a novel time series forecast model, DeepGB. We formulate and implement a variant of Gradient boosting wherein the weak learners are DNNs whose weights are incrementally found in a greedy manner over iterations. In particular, we develop a new embedding architecture that improves the performance of many deep learning models on time series using Gradient boosting variant. We demonstrate that our model outperforms existing comparable state-of-the-art models using real-world sensor data and public dataset.
Scene Recognition with Objectness, Attribute and Category Learning
Jul 20, 2022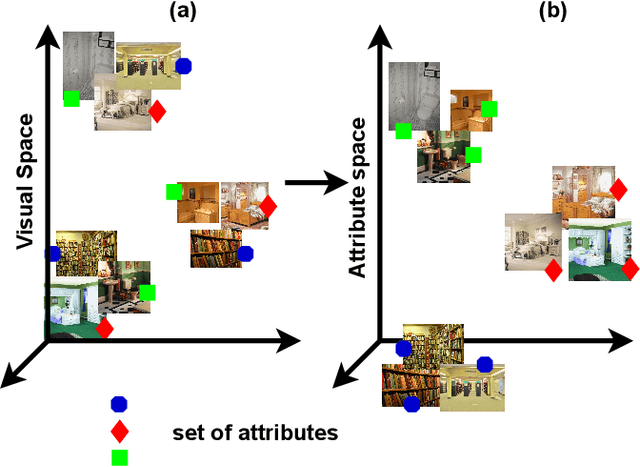
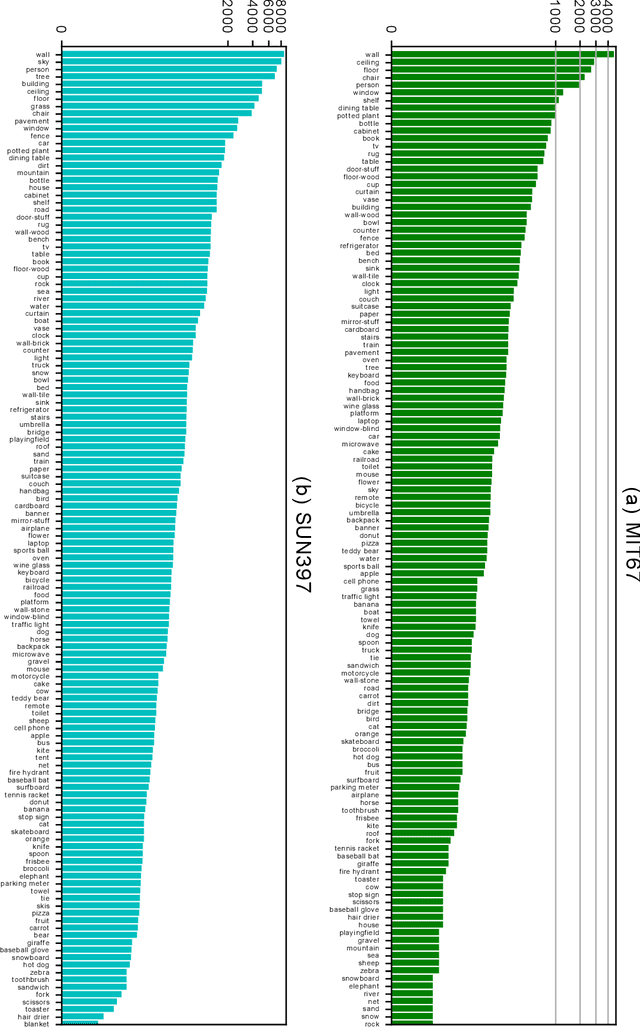
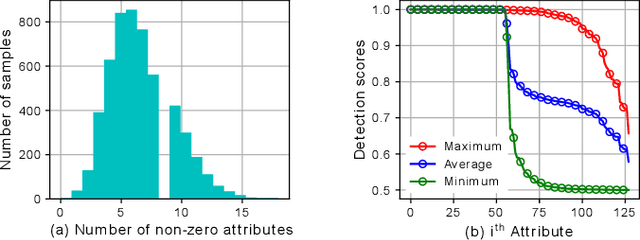
Scene classification has established itself as a challenging research problem. Compared to images of individual objects, scene images could be much more semantically complex and abstract. Their difference mainly lies in the level of granularity of recognition. Yet, image recognition serves as a key pillar for the good performance of scene recognition as the knowledge attained from object images can be used for accurate recognition of scenes. The existing scene recognition methods only take the category label of the scene into consideration. However, we find that the contextual information that contains detailed local descriptions are also beneficial in allowing the scene recognition model to be more discriminative. In this paper, we aim to improve scene recognition using attribute and category label information encoded in objects. Based on the complementarity of attribute and category labels, we propose a Multi-task Attribute-Scene Recognition (MASR) network which learns a category embedding and at the same time predicts scene attributes. Attribute acquisition and object annotation are tedious and time consuming tasks. We tackle the problem by proposing a partially supervised annotation strategy in which human intervention is significantly reduced. The strategy provides a much more cost-effective solution to real world scenarios, and requires considerably less annotation efforts. Moreover, we re-weight the attribute predictions considering the level of importance indicated by the object detected scores. Using the proposed method, we efficiently annotate attribute labels for four large-scale datasets, and systematically investigate how scene and attribute recognition benefit from each other. The experimental results demonstrate that MASR learns a more discriminative representation and achieves competitive recognition performance compared to the state-of-the-art methods
Towards Smart Fake News Detection Through Explainable AI
Jul 23, 2022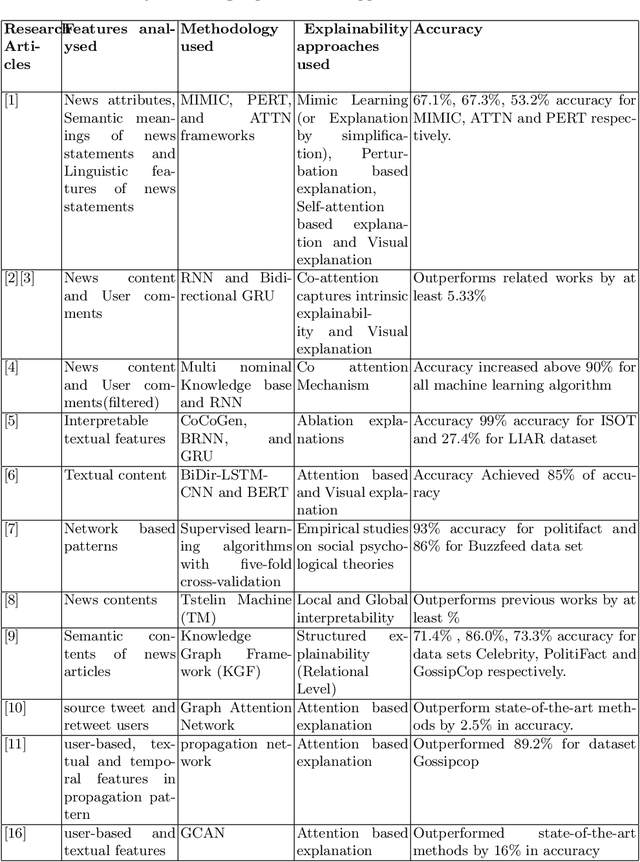

People now see social media sites as their sole source of information due to their popularity. The Majority of people get their news through social media. At the same time, fake news has grown exponentially on social media platforms in recent years. Several artificial intelligence-based solutions for detecting fake news have shown promising results. On the other hand, these detection systems lack explanation capabilities, i.e., the ability to explain why they made a prediction. This paper highlights the current state of the art in explainable fake news detection. We discuss the pitfalls in the current explainable AI-based fake news detection models and present our ongoing research on multi-modal explainable fake news detection model.
Fast Radix-32 Approximate DFTs for 1024-Beam Digital RF Beamforming
Jul 12, 2022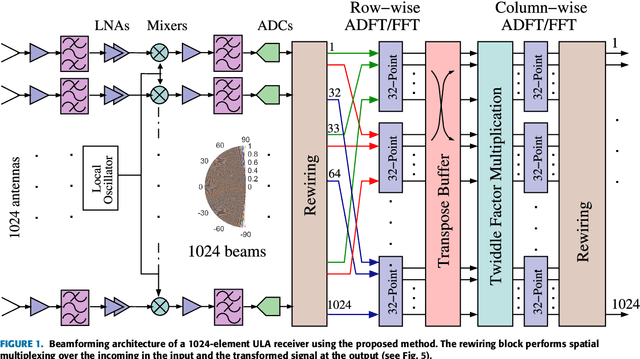
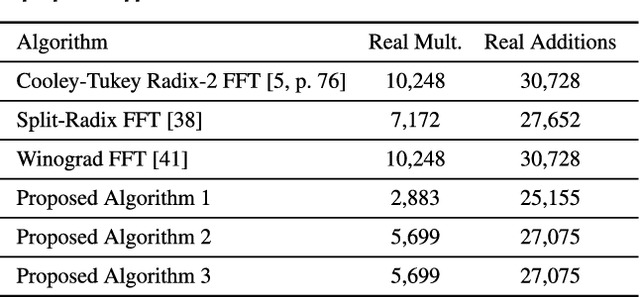
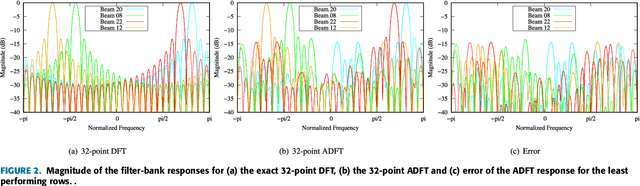
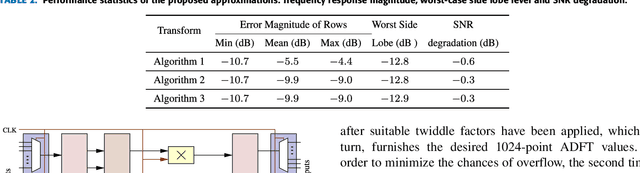
The discrete Fourier transform (DFT) is widely employed for multi-beam digital beamforming. The DFT can be efficiently implemented through the use of fast Fourier transform (FFT) algorithms, thus reducing chip area, power consumption, processing time, and consumption of other hardware resources. This paper proposes three new hybrid DFT 1024-point DFT approximations and their respective fast algorithms. These approximate DFT (ADFT) algorithms have significantly reduced circuit complexity and power consumption compared to traditional FFT approaches while trading off a subtle loss in computational precision which is acceptable for digital beamforming applications in RF antenna implementations. ADFT algorithms have not been introduced for beamforming beyond $N = 32$, but this paper anticipates the need for massively large adaptive arrays for future 5G and 6G systems. Digital CMOS circuit designs for the ADFTs show the resulting improvements in both circuit complexity and power consumption metrics. Simulation results show similar or lower critical path delay with up to 48.5% lower chip area compared to a standard Cooley-Tukey FFT. The time-area and dynamic power metrics are reduced up to 66.0%. The 1024-point ADFT beamformers produce signal-to-noise ratio (SNR) gains between 29.2--30.1 dB, which is a loss of $\le$ 0.9 dB SNR gain compared to exact 1024-point DFT beamformers (worst case) realizable at using an FFT.
* 21 pages, 8 figures, 5 tables. The factorization shown in Section 2 is fixed in this version
Inconsistencies in Measuring Student Engagement in Virtual Learning -- A Critical Review
Aug 09, 2022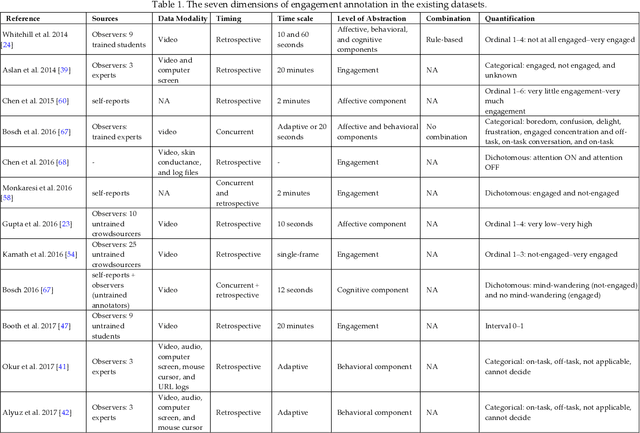
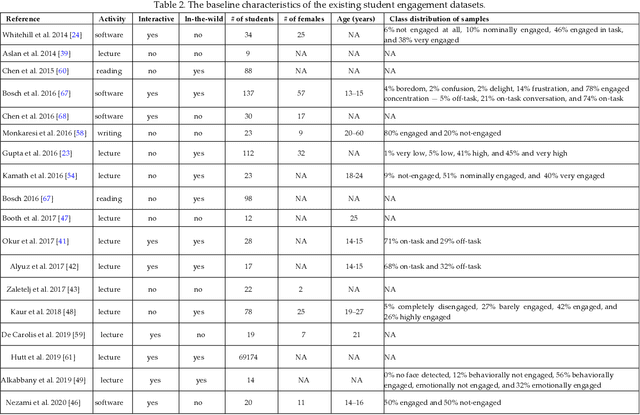
In recent years, virtual learning has emerged as an alternative to traditional classroom teaching. The engagement of students in virtual learning can have a major impact on meeting learning objectives and program dropout risks. There exist many measurement instruments specifically geared to Student Engagement (SE) in virtual learning environments. In this critical review, we analyze these works and highlight inconsistencies in terms of differing engagement definitions and measurement scales. This diversity among existing researchers could potentially be problematic in comparing different annotations and building generalizable predictive models. We further discuss issues in terms of engagement annotations and design flaws. We analyze the existing SE annotation scales based on our defined seven dimensions of engagement annotation, including sources, data modalities used for annotation, the time when the annotation takes place, the timesteps in which the annotation takes place, level of abstraction, combination, and quantification. One of the surprising findings was that very few of the reviewed datasets on SE measurement used existing psychometrically validated engagement scales in their annotation. Lastly, we discuss some other scales in settings other than virtual learning that have the potential to be used in measuring SE in virtual learning.