 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Delay-aware Multiple Access Design for Intelligent Reflecting Surface Aided Uplink Transmission
Jun 19, 2022
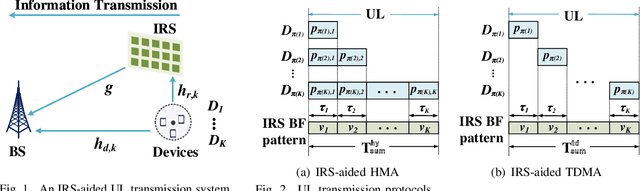
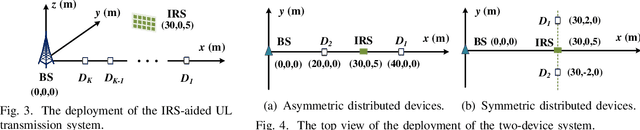
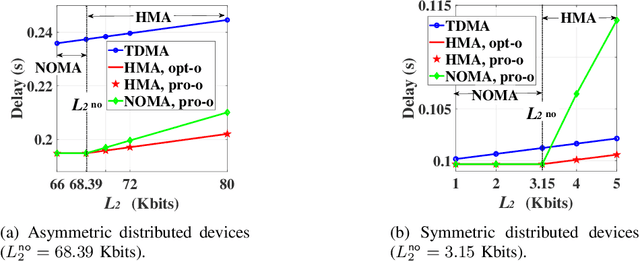
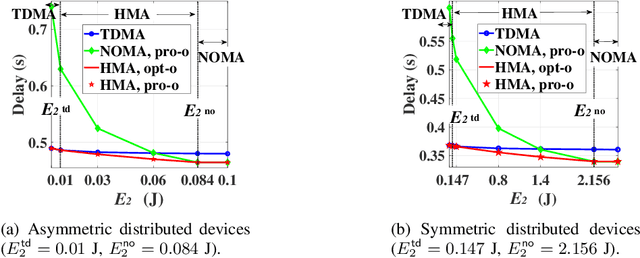
In this paper, we develop a novel multiple access (MA) protocol for an intelligent reflecting (IRS) aided uplink transmission network by incorporating the IRS-aided time-division MA (I-TDMA) protocol and the IRS-aided non-orthogonal MA protocol (I-NOMA) protocol as special cases. Two typical communication scenarios, namely the transmit power limited case and the transmit energy limited case are considered, where the device's rearranged order, time and power allocation, as well as dynamic IRS beamforming patterns over time are jointly optimized to minimize the sum transmission delay. To shed light on the superiority of the proposed IRS-aided hybrid MA (I-HMA) protocol over conventional protocols, the conditions under which I-HMA outperforms I-TDMA and I-NOMA are revealed by characterizing their corresponding optimal solution. Then, a computationally efficient algorithm is proposed to obtain the high-quality solution to the corresponding optimization problems. Simulation results validate our theoretical findings, demonstrate the superiority of the proposed design, and draw some useful insights. Specifically, it is found that the proposed protocol can significantly reduce the sum delay by combining the additional gain of dynamic IRS beamforming with the high spectral efficiency of NOMA, which thus reveals that integrating IRS into the proposed HMA protocol is an effective solution for delay-aware optimization. Furthermore, it reveals that the proposed design reduces the time consumption not only from the system-centric view, but also from the device-centric view.
Recurrent Neural Network-based Anti-jamming Framework for Defense Against Multiple Jamming Policies
Aug 19, 2022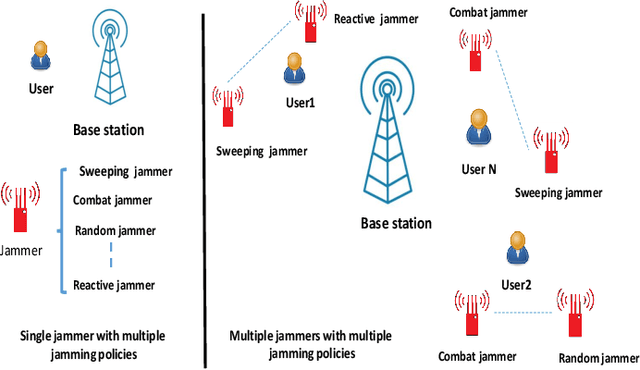
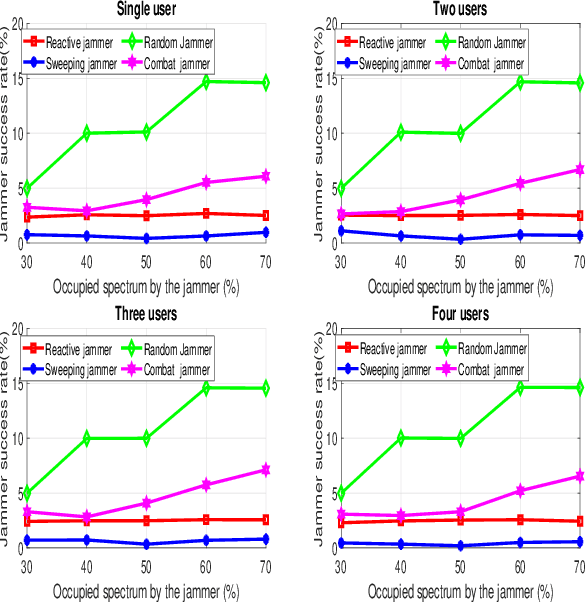
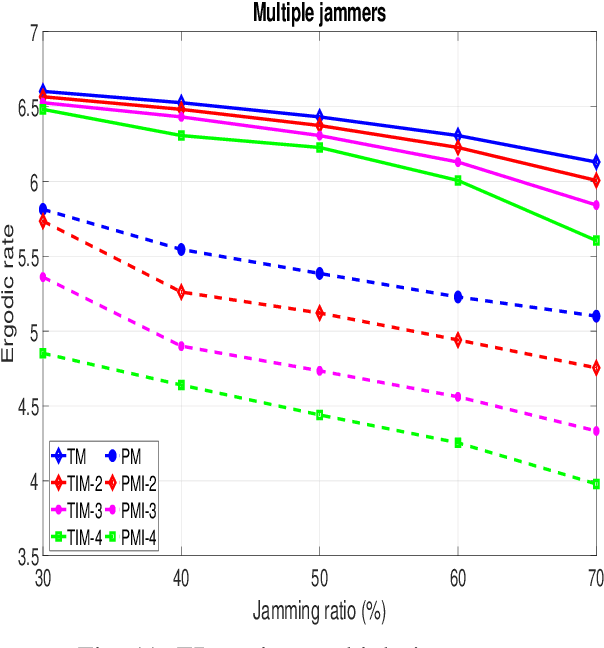
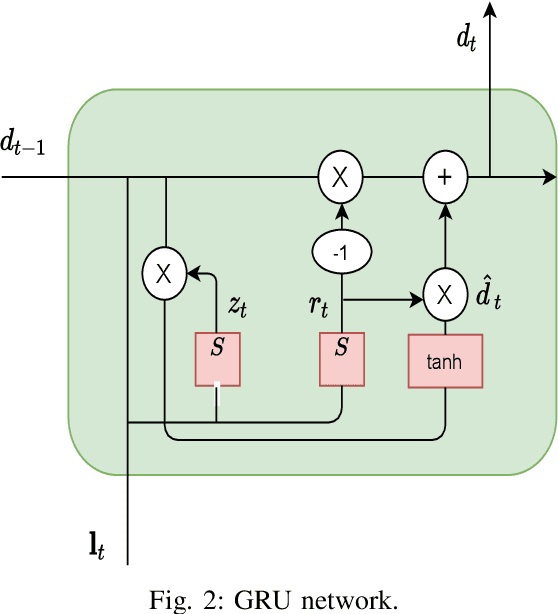
Conventional anti-jamming methods mainly focus on preventing single jammer attacks with an invariant jamming policy or jamming attacks from multiple jammers with similar jamming policies. These anti-jamming methods are ineffective against a single jammer following several different jamming policies or multiple jammers with distinct policies. Therefore, this paper proposes an anti-jamming method that can adapt its policy to the current jamming attack. Moreover, for the multiple jammers scenario, an anti-jamming method that estimates the future occupied channels using the jammers' occupied channels in previous time slots is proposed. In both single and multiple jammers scenarios, the interaction between the users and jammers is modeled using recurrent neural networks (RNN)s. The performance of the proposed anti-jamming methods is evaluated by calculating the users' successful transmission rate (STR) and ergodic rate (ER), and compared to a baseline based on Q-learning (DQL). Simulation results show that for the single jammer scenario, all the considered jamming policies are perfectly detected and high STR and ER are maintained. Moreover, when 70 % of the spectrum is under jamming attacks from multiple jammers, the proposed method achieves an STR and ER greater than 75 % and 80 %, respectively. These values rise to 90 % when 30 % of the spectrum is under jamming attacks. In addition, the proposed anti-jamming methods significantly outperform the DQL method for all the considered cases and jamming scenarios.
Improving the Efficiency of Gradient Descent Algorithms Applied to Optimization Problems with Dynamical Constraints
Aug 26, 2022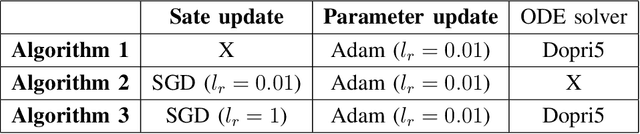
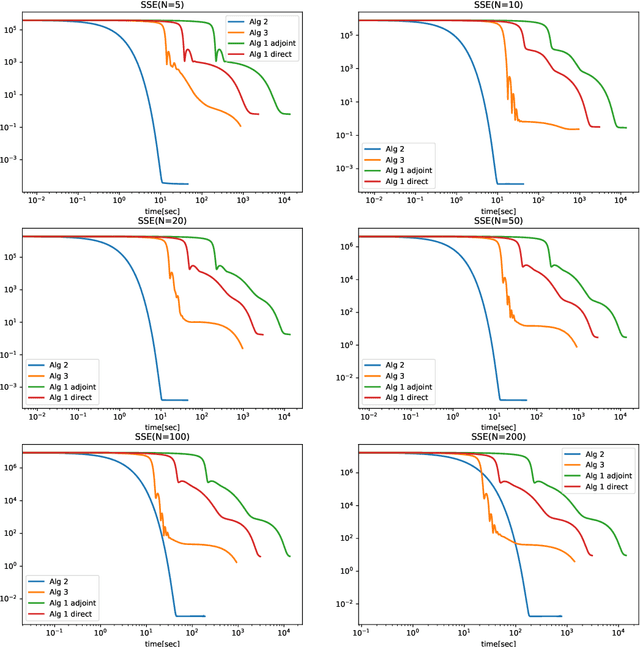

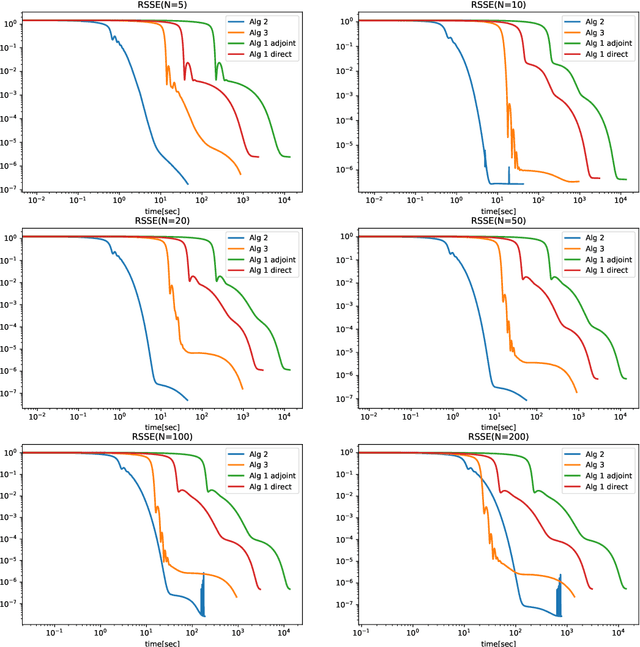
We introduce two block coordinate descent algorithms for solving optimization problems with ordinary differential equations (ODEs) as dynamical constraints. The algorithms do not need to implement direct or adjoint sensitivity analysis methods to evaluate loss function gradients. They results from reformulation of the original problem as an equivalent optimization problem with equality constraints. The algorithms naturally follow from steps aimed at recovering the gradient-decent algorithm based on ODE solvers that explicitly account for sensitivity of the ODE solution. In our first proposed algorithm we avoid explicitly solving the ODE by integrating the ODE solver as a sequence of implicit constraints. In our second algorithm, we use an ODE solver to reset the ODE solution, but no direct are adjoint sensitivity analysis methods are used. Both algorithm accepts mini-batch implementations and show significant efficiency benefits from GPU-based parallelization. We demonstrate the performance of the algorithms when applied to learning the parameters of the Cucker-Smale model. The algorithms are compared with gradient descent algorithms based on ODE solvers endowed with sensitivity analysis capabilities, for various number of state size, using Pytorch and Jax implementations. The experimental results demonstrate that the proposed algorithms are at least 4x faster than the Pytorch implementations, and at least 16x faster than Jax implementations. For large versions of the Cucker-Smale model, the Jax implementation is thousands of times faster than the sensitivity analysis-based implementation. In addition, our algorithms generate more accurate results both on training and test data. Such gains in computational efficiency is paramount for algorithms that implement real time parameter estimations, such as diagnosis algorithms.
Using Twitter Data to Understand Public Perceptions of Approved versus Off-label Use for COVID-19-related Medications
Jun 29, 2022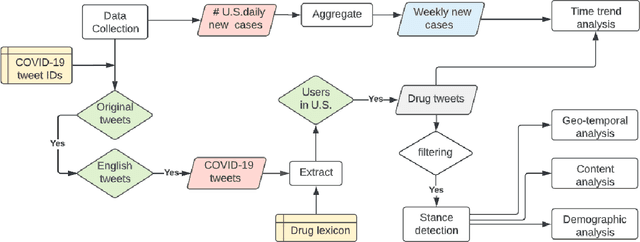

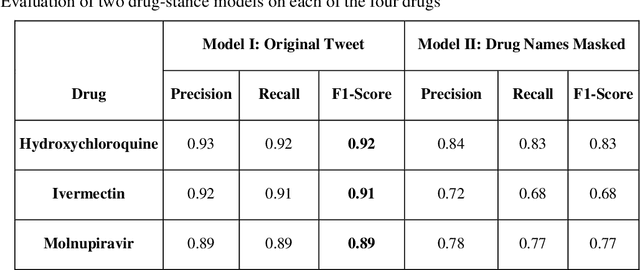
Understanding public discourse on emergency use of unproven therapeutics is essential to monitor safe use and combat misinformation. We developed a natural language processing (NLP)-based pipeline to understand public perceptions of and stances on COVID-19-related drugs on Twitter across time. This retrospective study included 609,189 US-based tweets between January 29th, 2020 and November 30th, 2021 on four drugs that gained wide public attention during the COVID-19 pandemic: 1) Hydroxychloroquine and Ivermectin, drug therapies with anecdotal evidence; and 2) Molnupiravir and Remdesivir, FDA-approved treatment options for eligible patients. Time-trend analysis was used to understand the popularity and related events. Content and demographic analyses were conducted to explore potential rationales of people's stances on each drug. Time-trend analysis revealed that Hydroxychloroquine and Ivermectin received much more discussion than Molnupiravir and Remdesivir, particularly during COVID-19 surges. Hydroxychloroquine and Ivermectin were highly politicized, related to conspiracy theories, hearsay, celebrity effects, etc. The distribution of stance between the two major US political parties was significantly different (p<0.001); Republicans were much more likely to support Hydroxychloroquine (+55%) and Ivermectin (+30%) than Democrats. People with healthcare backgrounds tended to oppose Hydroxychloroquine (+7%) more than the general population; in contrast, the general population was more likely to support Ivermectin (+14%). We make all the data, code, and models available at https://github.com/ningkko/COVID-drug.
* This is a preliminary version. For full paper please refer to JAMIA
Minkowski Tracker: A Sparse Spatio-Temporal R-CNN for Joint Object Detection and Tracking
Aug 26, 2022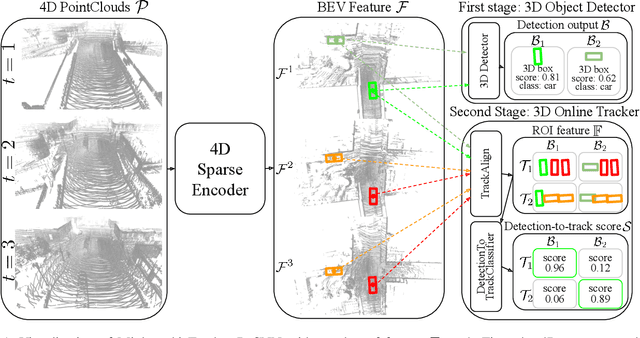
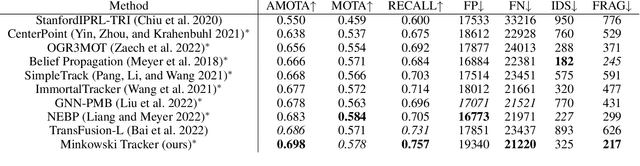
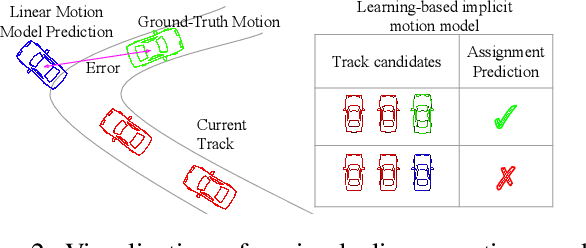
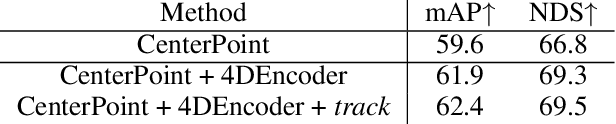
Recent research in multi-task learning reveals the benefit of solving related problems in a single neural network. 3D object detection and multi-object tracking (MOT) are two heavily intertwined problems predicting and associating an object instance location across time. However, most previous works in 3D MOT treat the detector as a preceding separated pipeline, disjointly taking the output of the detector as an input to the tracker. In this work, we present Minkowski Tracker, a sparse spatio-temporal R-CNN that jointly solves object detection and tracking. Inspired by region-based CNN (R-CNN), we propose to solve tracking as a second stage of the object detector R-CNN that predicts assignment probability to tracks. First, Minkowski Tracker takes 4D point clouds as input to generate a spatio-temporal Bird's-eye-view (BEV) feature map through a 4D sparse convolutional encoder network. Then, our proposed TrackAlign aggregates the track region-of-interest (ROI) features from the BEV features. Finally, Minkowski Tracker updates the track and its confidence score based on the detection-to-track match probability predicted from the ROI features. We show in large-scale experiments that the overall performance gain of our method is due to four factors: 1. The temporal reasoning of the 4D encoder improves the detection performance 2. The multi-task learning of object detection and MOT jointly enhances each other 3. The detection-to-track match score learns implicit motion model to enhance track assignment 4. The detection-to-track match score improves the quality of the track confidence score. As a result, Minkowski Tracker achieved the state-of-the-art performance on Nuscenes dataset tracking task without hand-designed motion models.
Convolutional Ensembling based Few-Shot Defect Detection Technique
Aug 05, 2022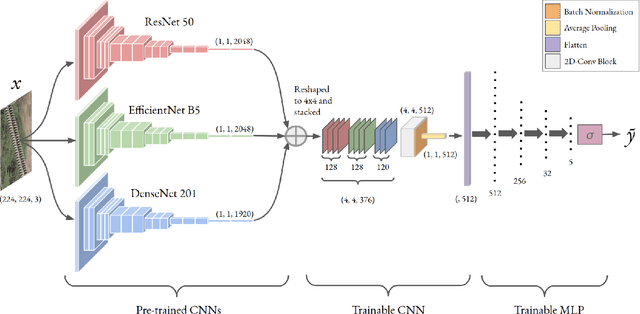
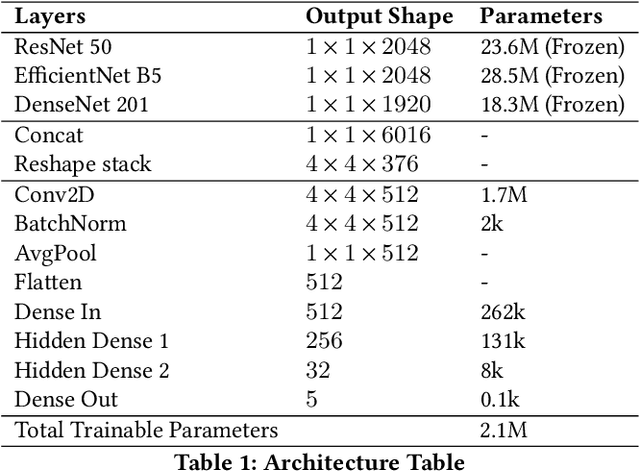
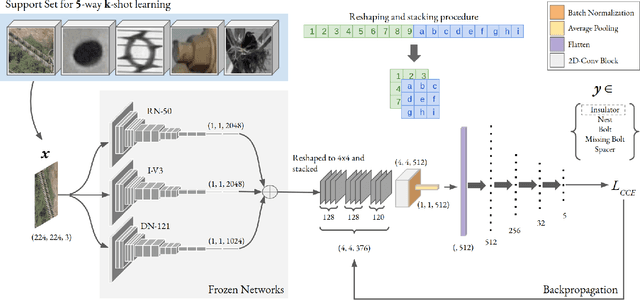
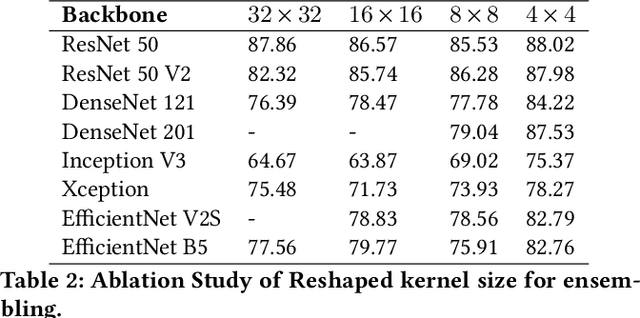
Over the past few years, there has been a significant improvement in the domain of few-shot learning. This learning paradigm has shown promising results for the challenging problem of anomaly detection, where the general task is to deal with heavy class imbalance. Our paper presents a new approach to few-shot classification, where we employ the knowledge-base of multiple pre-trained convolutional models that act as the backbone for our proposed few-shot framework. Our framework uses a novel ensembling technique for boosting the accuracy while drastically decreasing the total parameter count, thus paving the way for real-time implementation. We perform an extensive hyperparameter search using a power-line defect detection dataset and obtain an accuracy of 92.30% for the 5-way 5-shot task. Without further tuning, we evaluate our model on competing standards with the existing state-of-the-art methods and outperform them.
FLOWGEN: Fast and slow graph generation
Jul 21, 2022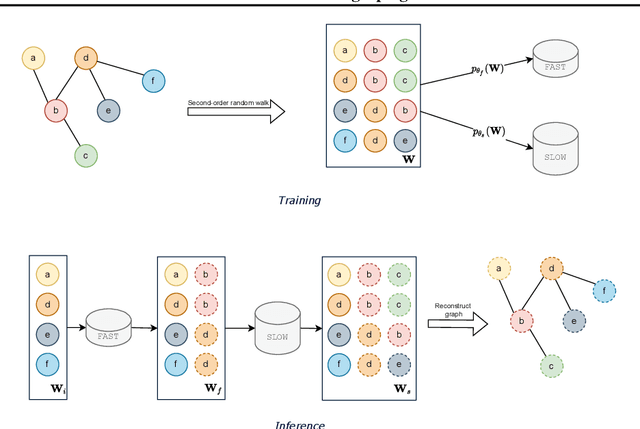

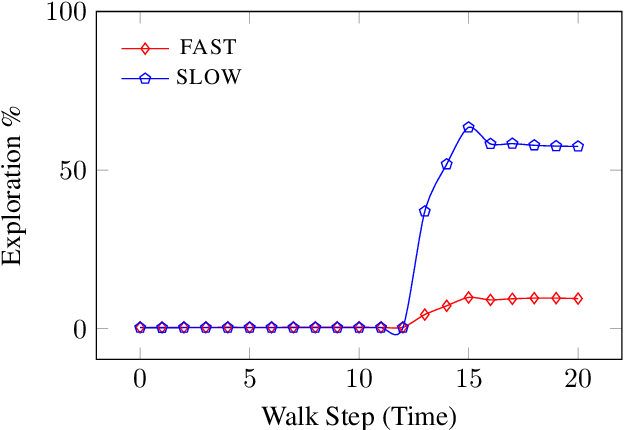

We present FLOWGEN, a graph-generation model inspired by the dual-process theory of mind that generates large graphs incrementally. Depending on the difficulty of completing the graph at the current step, graph generation is routed to either a fast~(weaker) or a slow~(stronger) model. fast and slow models have identical architectures, but vary in the number of parameters and consequently the strength. Experiments on real-world graphs show that ours can successfully generate graphs similar to those generated by a single large model in a fraction of time.
Initial Orbit Determination for the CR3BP using Particle Swarm Optimization
Jul 23, 2022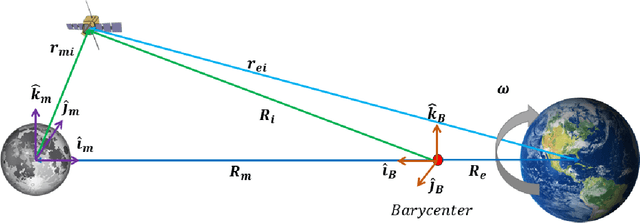
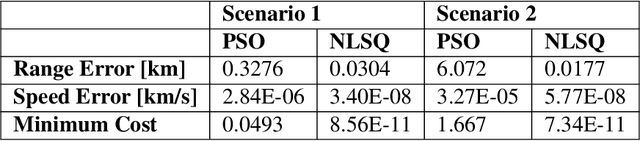
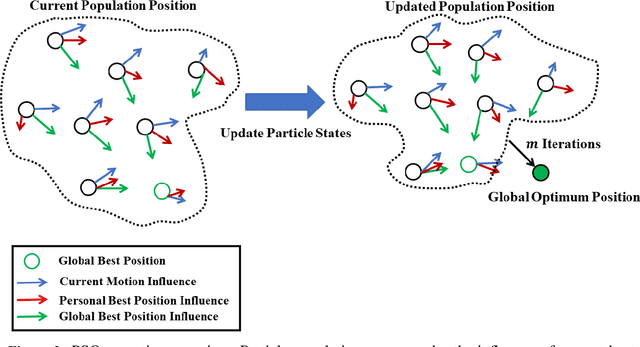
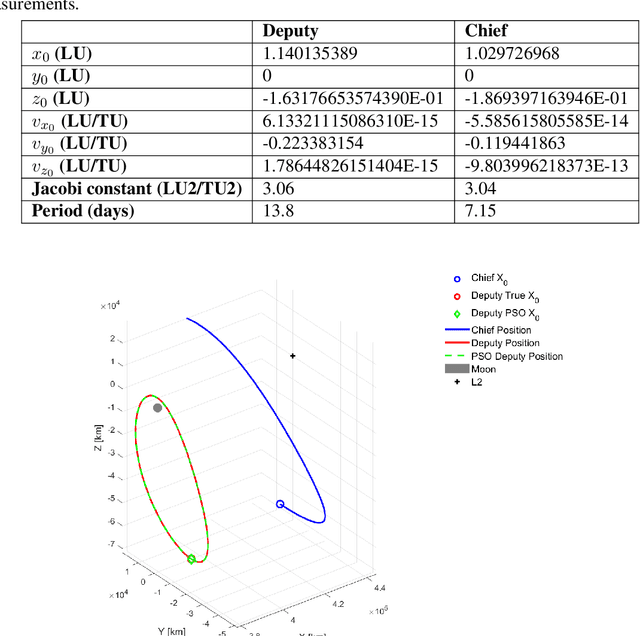
This work utilizes a particle swarm optimizer (PSO) for initial orbit determination for a chief and deputy scenario in the circular restricted three-body problem (CR3BP). The PSO is used to minimize the difference between actual and estimated observations and knowledge of the chief's position with known CR3BP dynamics to determine the deputy's initial state. Convergence is achieved through limiting particle starting positions to feasible positions based on the known chief position, and sensor constraints. Parallel and GPU processing methods are used to improve computation time and provide an accurate initial state estimate for a variety of cislunar orbit geometries.
Federated Variational Learning for Anomaly Detection in Multivariate Time Series
Aug 18, 2021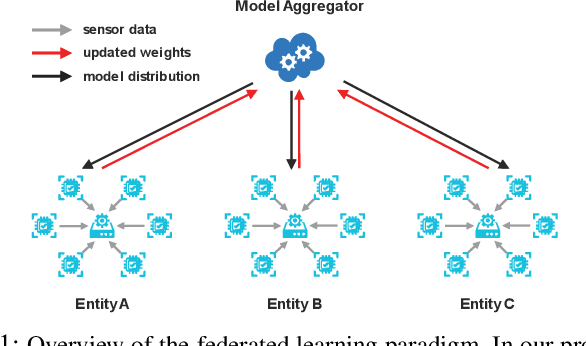
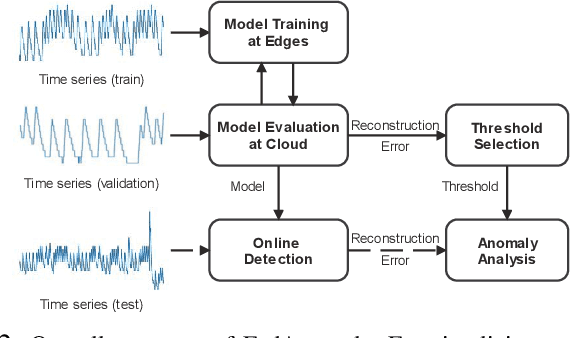
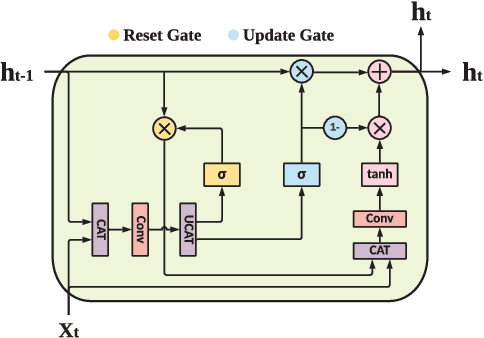
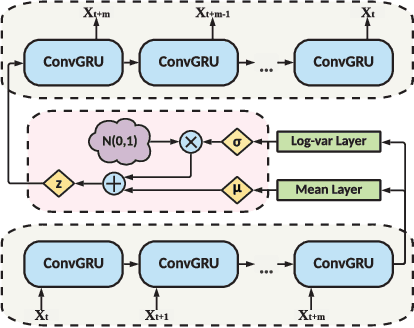
Anomaly detection has been a challenging task given high-dimensional multivariate time series data generated by networked sensors and actuators in Cyber-Physical Systems (CPS). Besides the highly nonlinear, complex, and dynamic natures of such time series, the lack of labeled data impedes data exploitation in a supervised manner and thus prevents an accurate detection of abnormal phenomenons. On the other hand, the collected data at the edge of the network is often privacy sensitive and large in quantity, which may hinder the centralized training at the main server. To tackle these issues, we propose an unsupervised time series anomaly detection framework in a federated fashion to continuously monitor the behaviors of interconnected devices within a network and alerts for abnormal incidents so that countermeasures can be taken before undesired consequences occur. To be specific, we leave the training data distributed at the edge to learn a shared Variational Autoencoder (VAE) based on Convolutional Gated Recurrent Unit (ConvGRU) model, which jointly captures feature and temporal dependencies in the multivariate time series data for representation learning and downstream anomaly detection tasks. Experiments on three real-world networked sensor datasets illustrate the advantage of our approach over other state-of-the-art models. We also conduct extensive experiments to demonstrate the effectiveness of our detection framework under non-federated and federated settings in terms of overall performance and detection latency.
Fast Auto-Differentiable Digitally Reconstructed Radiographs for Solving Inverse Problems in Intraoperative Imaging
Aug 26, 2022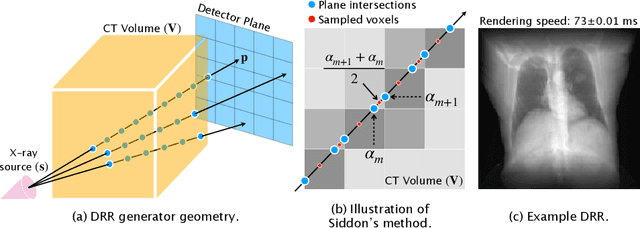
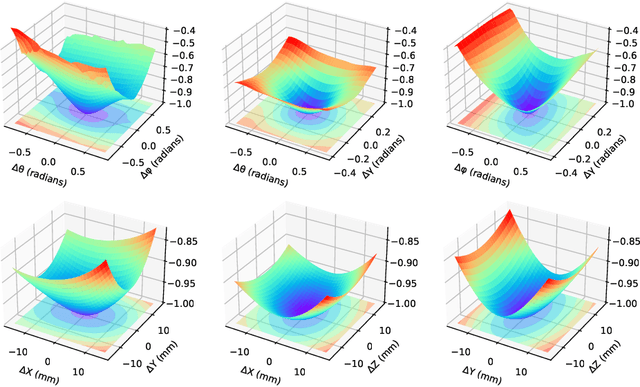
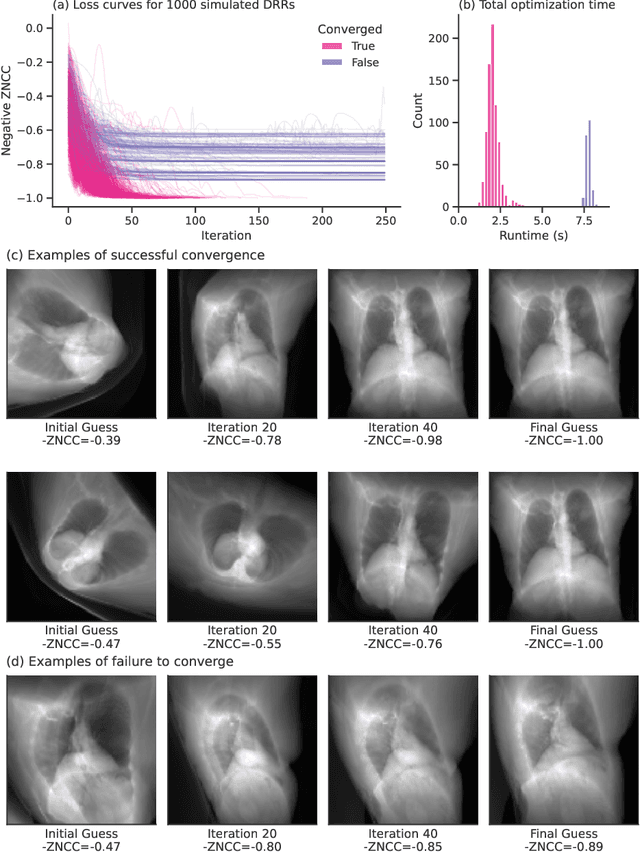
The use of digitally reconstructed radiographs (DRRs) to solve inverse problems such as slice-to-volume registration and 3D reconstruction is well-studied in preoperative settings. In intraoperative imaging, the utility of DRRs is limited by the challenges in generating them in real-time and supporting optimization procedures that rely on repeated DRR synthesis. While immense progress has been made in accelerating the generation of DRRs through algorithmic refinements and GPU implementations, DRR-based optimization remains slow because most DRR generators do not offer a straightforward way to obtain gradients with respect to the imaging parameters. To make DRRs interoperable with gradient-based optimization and deep learning frameworks, we have reformulated Siddon's method, the most popular ray-tracing algorithm used in DRR generation, as a series of vectorized tensor operations. We implemented this vectorized version of Siddon's method in PyTorch, taking advantage of the library's strong automatic differentiation engine to make this DRR generator fully differentiable with respect to its parameters. Additionally, using GPU-accelerated tensor computation enables our vectorized implementation to achieve rendering speeds equivalent to state-of-the-art DRR generators implemented in CUDA and C++. We illustrate the resulting method in the context of slice-to-volume registration. Moreover, our simulations suggest that the loss landscapes for the slice-to-volume registration problem are convex in the neighborhood of the optimal solution, and gradient-based registration promises a much faster solution than prevailing gradient-free optimization strategies. The proposed DRR generator enables fast computer vision algorithms to support image guidance in minimally invasive procedures. Our implementation is publically available at https://github.com/v715/DiffDRR.