 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmbiguity Detection and Elimination in Automated Executable Process Modeling
Apr 13, 2026Automated generation of executable Business Process Model and Notation (BPMN) models from natural-language specifications is increasingly enabled by large language models. However, ambiguous or underspecified text can yield structurally valid models with different simulated behavior. Our goal is not to prove that one generated BPMN model is semantically correct, but to detect when a natural-language specification fails to support a stable executable interpretation under repeated generation and simulation. We present a diagnosis-driven framework that detects behavioral inconsistency from the empirical distribution of key performance indicators (KPIs), localizes divergence to gateway logic using model-based diagnosis, maps that logic back to verbatim narrative segments, and repairs the source text through evidence-based refinement. Experiments on diabetic nephropathy health-guidance policies show that the method reduces variability in regenerated model behavior. The result is a closed-loop approach for validating and repairing executable process specifications in the absence of ground-truth BPMN models.
Automatic Generation of Executable BPMN Models from Medical Guidelines
Apr 09, 2026We present an end-to-end pipeline that converts healthcare policy documents into executable, data-aware Business Process Model and Notation (BPMN) models using large language models (LLMs) for simulation-based policy evaluation. We address the main challenges of automated policy digitization with four contributions: data-grounded BPMN generation with syntax auto-correction, executable augmentation, KPI instrumentation, and entropy-based uncertainty detection. We evaluate the pipeline on diabetic nephropathy prevention guidelines from three Japanese municipalities, generating 100 models per backend across three LLMs and executing each against 1,000 synthetic patients. On well-structured policies, the pipeline achieves a 100% ground-truth match with perfect per-patient decision agreement. Across all conditions, raw per-patient decision agreement exceeds 92%, and entropy scores increase monotonically with document complexity, confirming that the detector reliably separates unambiguous policies from those requiring targeted human clarification.
Improving the Efficiency of Gradient Descent Algorithms Applied to Optimization Problems with Dynamical Constraints
Aug 26, 2022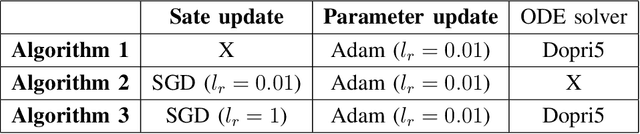
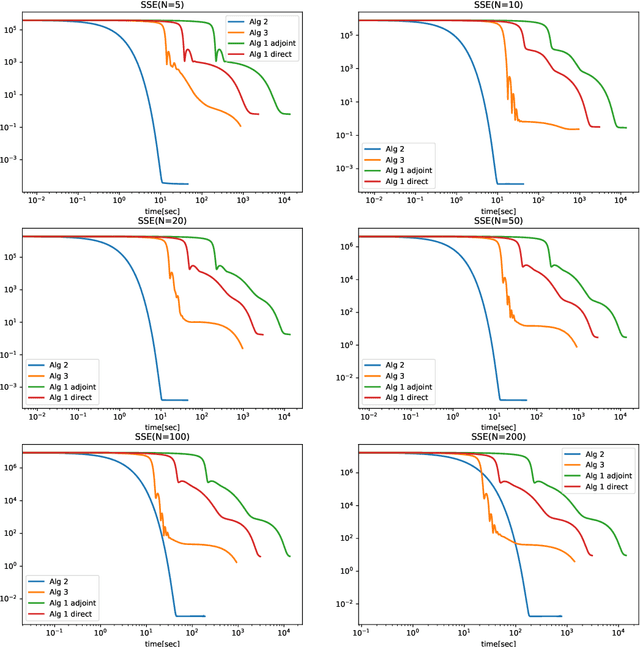

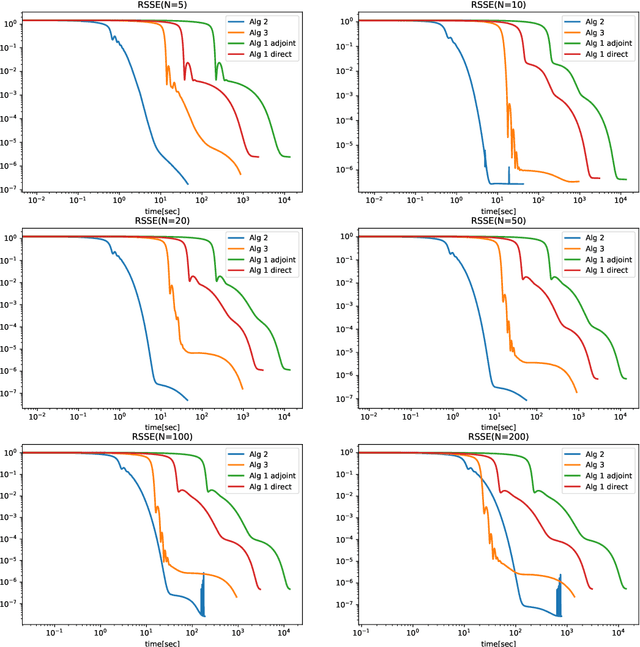
We introduce two block coordinate descent algorithms for solving optimization problems with ordinary differential equations (ODEs) as dynamical constraints. The algorithms do not need to implement direct or adjoint sensitivity analysis methods to evaluate loss function gradients. They results from reformulation of the original problem as an equivalent optimization problem with equality constraints. The algorithms naturally follow from steps aimed at recovering the gradient-decent algorithm based on ODE solvers that explicitly account for sensitivity of the ODE solution. In our first proposed algorithm we avoid explicitly solving the ODE by integrating the ODE solver as a sequence of implicit constraints. In our second algorithm, we use an ODE solver to reset the ODE solution, but no direct are adjoint sensitivity analysis methods are used. Both algorithm accepts mini-batch implementations and show significant efficiency benefits from GPU-based parallelization. We demonstrate the performance of the algorithms when applied to learning the parameters of the Cucker-Smale model. The algorithms are compared with gradient descent algorithms based on ODE solvers endowed with sensitivity analysis capabilities, for various number of state size, using Pytorch and Jax implementations. The experimental results demonstrate that the proposed algorithms are at least 4x faster than the Pytorch implementations, and at least 16x faster than Jax implementations. For large versions of the Cucker-Smale model, the Jax implementation is thousands of times faster than the sensitivity analysis-based implementation. In addition, our algorithms generate more accurate results both on training and test data. Such gains in computational efficiency is paramount for algorithms that implement real time parameter estimations, such as diagnosis algorithms.