 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Langevin Diffusion Variational Inference
Aug 16, 2022
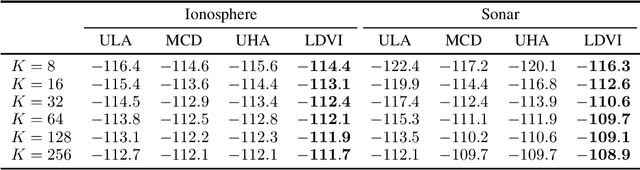
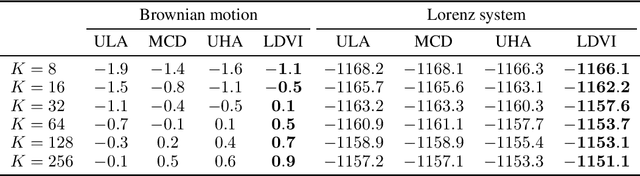
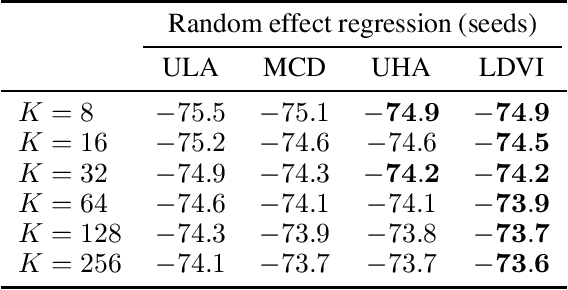
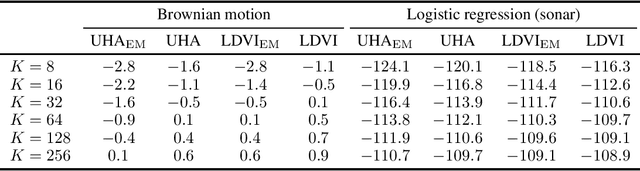
Many methods that build powerful variational distributions based on unadjusted Langevin transitions exist. Most of these were developed using a wide range of different approaches and techniques. Unfortunately, the lack of a unified analysis and derivation makes developing new methods and reasoning about existing ones a challenging task. We address this giving a single analysis that unifies and generalizes these existing techniques. The main idea is to augment the target and variational by numerically simulating the underdamped Langevin diffusion process and its time reversal. The benefits of this approach are twofold: it provides a unified formulation for many existing methods, and it simplifies the development of new ones. In fact, using our formulation we propose a new method that combines the strengths of previously existing algorithms; it uses underdamped Langevin transitions and powerful augmentations parameterized by a score network. Our empirical evaluation shows that our proposed method consistently outperforms relevant baselines in a wide range of tasks.
Modeling Live Video Streaming: Real-Time Classification, QoE Inference, and Field Evaluation
Dec 05, 2021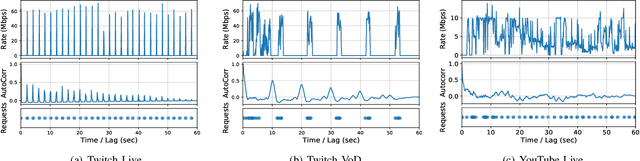
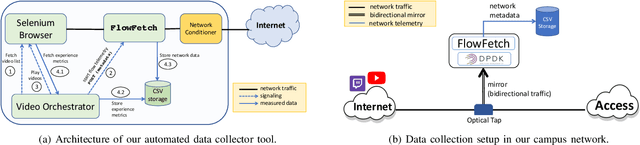
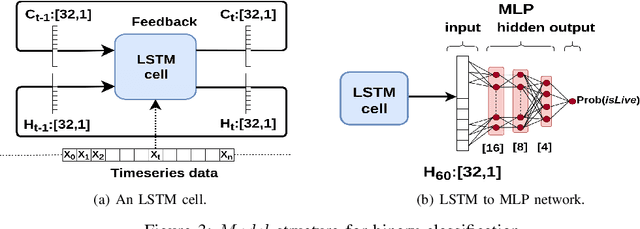
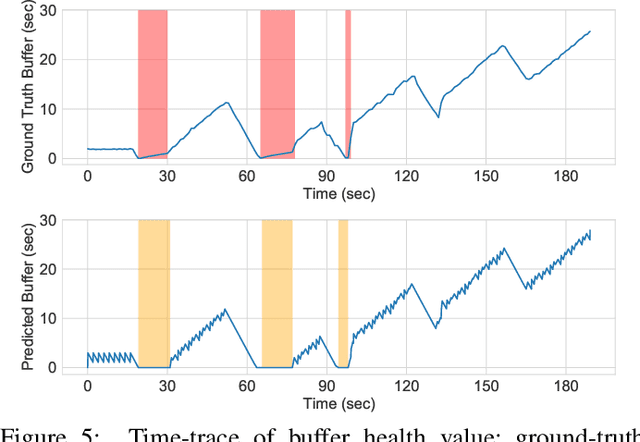
Social media, professional sports, and video games are driving rapid growth in live video streaming, on platforms such as Twitch and YouTube Live. Live streaming experience is very susceptible to short-time-scale network congestion since client playback buffers are often no more than a few seconds. Unfortunately, identifying such streams and measuring their QoE for network management is challenging, since content providers largely use the same delivery infrastructure for live and video-on-demand (VoD) streaming, and packet inspection techniques (including SNI/DNS query monitoring) cannot always distinguish between the two. In this paper, we design, build, and deploy ReCLive: a machine learning method for live video detection and QoE measurement based on network-level behavioral characteristics. Our contributions are four-fold: (1) We analyze about 23,000 video streams from Twitch and YouTube, and identify key features in their traffic profile that differentiate live and on-demand streaming. We release our traffic traces as open data to the public; (2) We develop an LSTM-based binary classifier model that distinguishes live from on-demand streams in real-time with over 95% accuracy across providers; (3) We develop a method that estimates QoE metrics of live streaming flows in terms of resolution and buffer stall events with overall accuracies of 93% and 90%, respectively; and (4) Finally, we prototype our solution, train it in the lab, and deploy it in a live ISP network serving more than 7,000 subscribers. Our method provides ISPs with fine-grained visibility into live video streams, enabling them to measure and improve user experience.
PirouNet: Creating Intentional Dance with Semi-Supervised Conditional Recurrent Variational Autoencoders
Jul 21, 2022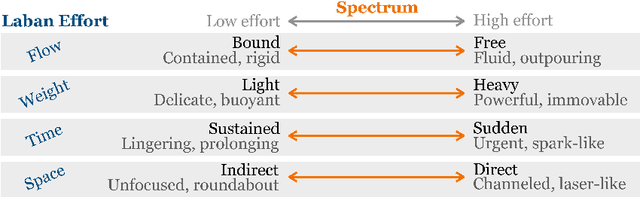

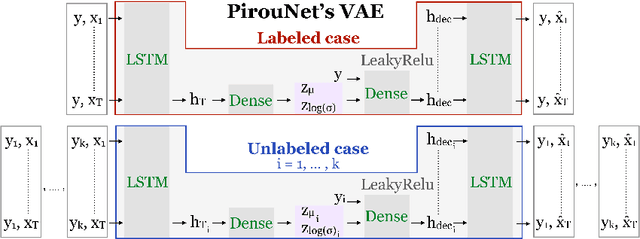

Using Artificial Intelligence (AI) to create dance choreography with intention is still at an early stage. Methods that conditionally generate dance sequences remain limited in their ability to follow choreographer-specific creative intentions, often relying on external prompts or supervised learning. In the same vein, fully annotated dance datasets are rare and labor intensive. To fill this gap and help leverage deep learning as a meaningful tool for choreographers, we propose "PirouNet", a semi-supervised conditional recurrent variational autoencoder together with a dance labeling web application. PirouNet allows dance professionals to annotate data with their own subjective creative labels and subsequently generate new bouts of choreography based on their aesthetic criteria. Thanks to the proposed semi-supervised approach, PirouNet only requires a small portion of the dataset to be labeled, typically on the order of 1%. We demonstrate PirouNet's capabilities as it generates original choreography based on the "Laban Time Effort", an established dance notion describing intention for a movement's time dynamics. We extensively evaluate PirouNet's dance creations through a series of qualitative and quantitative metrics, validating its applicability as a tool for choreographers.
Real-time Multi-Adaptive-Resolution-Surfel 6D LiDAR Odometry using Continuous-time Trajectory Optimization
May 05, 2021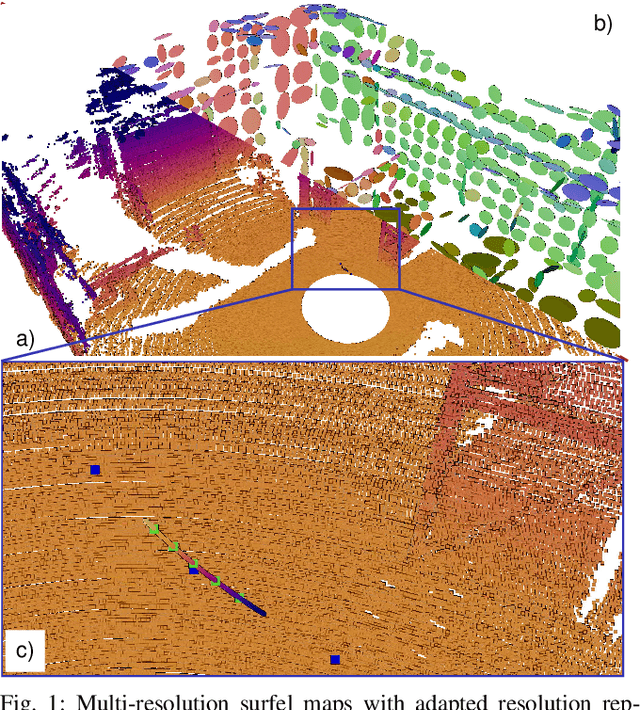
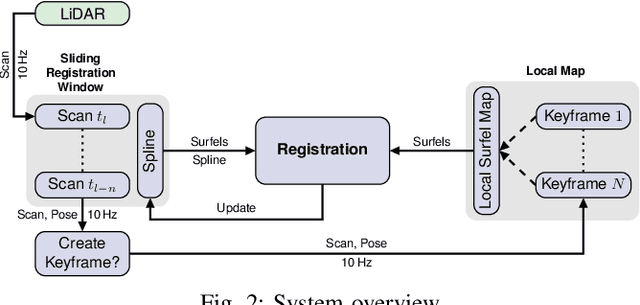
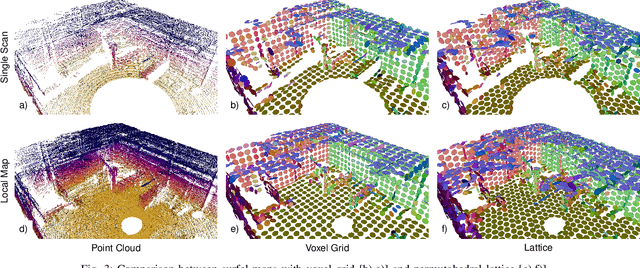
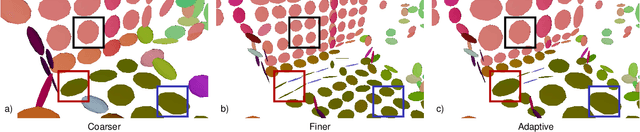
Simultaneous Localization and Mapping (SLAM) is an essential capability for autonomous robots, but due to high data rates of 3D LiDARs real-time SLAM is challenging. We propose a real-time method for 6D LiDAR odometry. Our approach combines a continuous-time B-Spline trajectory representation with a Gaussian Mixture Model (GMM) formulation to jointly align local multi-resolution surfel maps. Sparse voxel grids and permutohedral lattices ensure fast access to map surfels, and an adaptive resolution selection scheme effectively speeds up registration. A thorough experimental evaluation shows the performance of our approach on two datasets and during real-robot experiments.
Scalable Hybrid Classification-Regression Solution for High-Frequency Nonintrusive Load Monitoring
Aug 22, 2022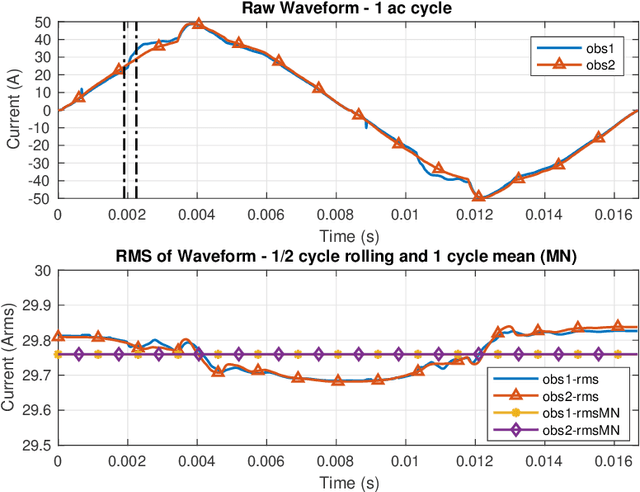
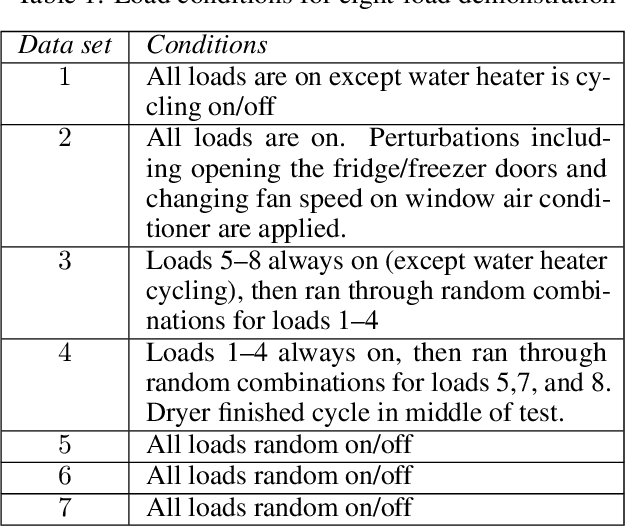
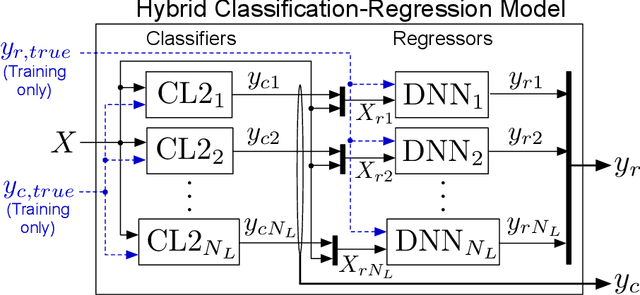
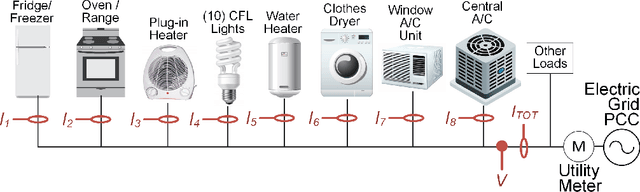
Residential buildings with the ability to monitor and control their net-load (sum of load and generation) can provide valuable flexibility to power grid operators. We present a novel multiclass nonintrusive load monitoring (NILM) approach that enables effective net-load monitoring capabilities at high-frequency with minimal additional equipment and cost. The proposed machine learning based solution provides accurate multiclass state predictions while operating at a faster timescale (able to provide a prediction for each 60-Hz ac cycle used in US power grid) without relying on event-detection techniques. We also introduce an innovative hybrid classification-regression method that allows for the prediction of not only load on/off states via classification but also individual load operating power levels via regression. A test bed with eight residential appliances is used for validating the NILM approach. Results show that the overall method has high accuracy and, good scaling and generalization properties. Furthermore, the method is shown to have sufficient response time (within 160ms, corresponding to 10 ac cycles) to support building grid-interactive control at fast timescales relevant to the provision of grid frequency support services.
Modeling and Predicting Transistor Aging under Workload Dependency using Machine Learning
Jul 08, 2022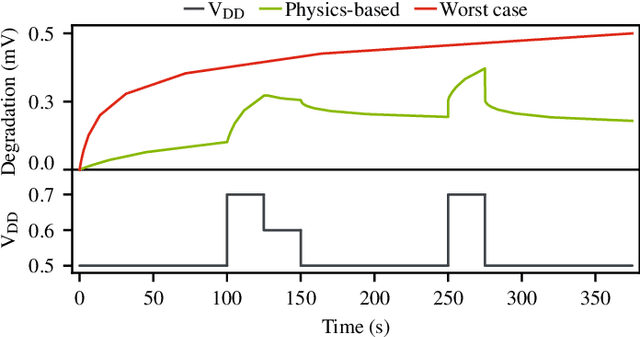
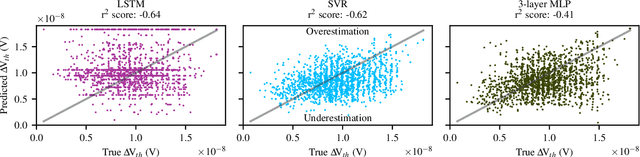
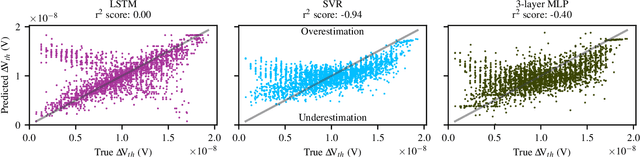
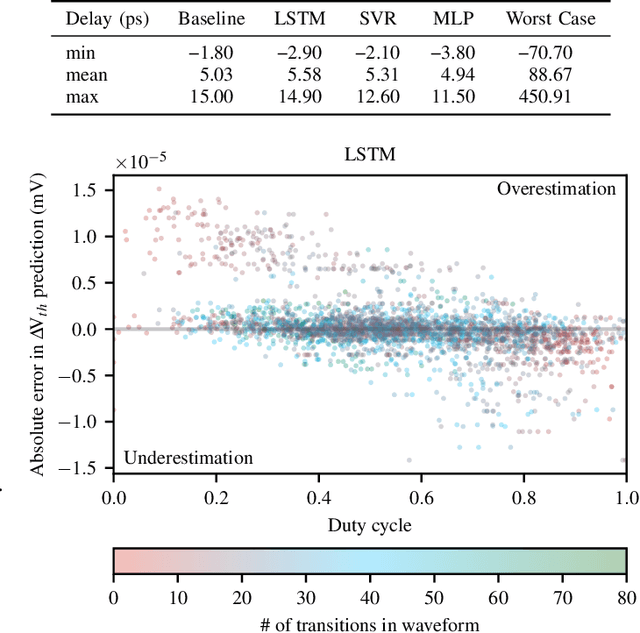
The pivotal issue of reliability is one of colossal concern for circuit designers. The driving force is transistor aging, dependent on operating voltage and workload. At the design time, it is difficult to estimate close-to-the-edge guardbands that keep aging effects during the lifetime at bay. This is because the foundry does not share its calibrated physics-based models, comprised of highly confidential technology and material parameters. However, the unmonitored yet necessary overestimation of degradation amounts to a performance decline, which could be preventable. Furthermore, these physics-based models are exceptionally computationally complex. The costs of modeling millions of individual transistors at design time can be evidently exorbitant. We propose the revolutionizing prospect of a machine learning model trained to replicate the physics-based model, such that no confidential parameters are disclosed. This effectual workaround is fully accessible to circuit designers for the purposes of design optimization. We demonstrate the models' ability to generalize by training on data from one circuit and applying it successfully to a benchmark circuit. The mean relative error is as low as 1.7%, with a speedup of up to 20X. Circuit designers, for the first time ever, will have ease of access to a high-precision aging model, which is paramount for efficient designs. This work is a promising step in the direction of bridging the wide gulf between the foundry and circuit designers.
DIDER: Discovering Interpretable Dynamically Evolving Relations
Aug 22, 2022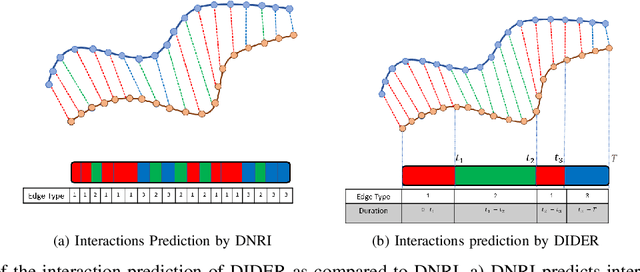
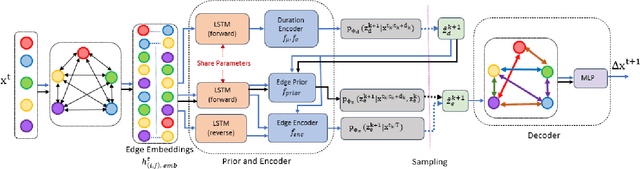
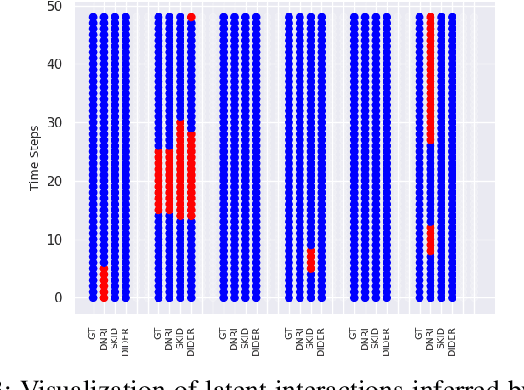
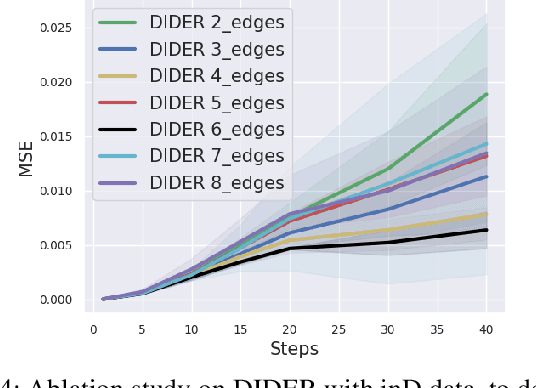
Effective understanding of dynamically evolving multiagent interactions is crucial to capturing the underlying behavior of agents in social systems. It is usually challenging to observe these interactions directly, and therefore modeling the latent interactions is essential for realizing the complex behaviors. Recent work on Dynamic Neural Relational Inference (DNRI) captures explicit inter-agent interactions at every step. However, prediction at every step results in noisy interactions and lacks intrinsic interpretability without post-hoc inspection. Moreover, it requires access to ground truth annotations to analyze the predicted interactions, which are hard to obtain. This paper introduces DIDER, Discovering Interpretable Dynamically Evolving Relations, a generic end-to-end interaction modeling framework with intrinsic interpretability. DIDER discovers an interpretable sequence of inter-agent interactions by disentangling the task of latent interaction prediction into sub-interaction prediction and duration estimation. By imposing the consistency of a sub-interaction type over an extended time duration, the proposed framework achieves intrinsic interpretability without requiring any post-hoc inspection. We evaluate DIDER on both synthetic and real-world datasets. The experimental results demonstrate that modeling disentangled and interpretable dynamic relations improves performance on trajectory forecasting tasks.
UniPreCIS : A data pre-processing solution for collocated services on shared IoT
Aug 01, 2022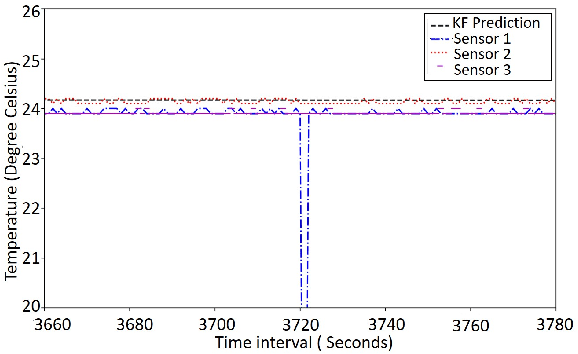
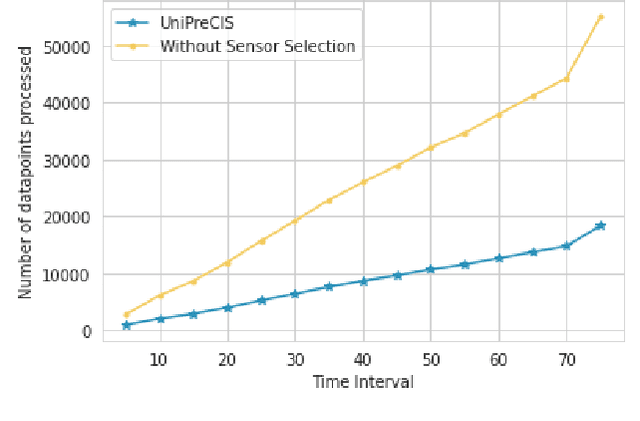
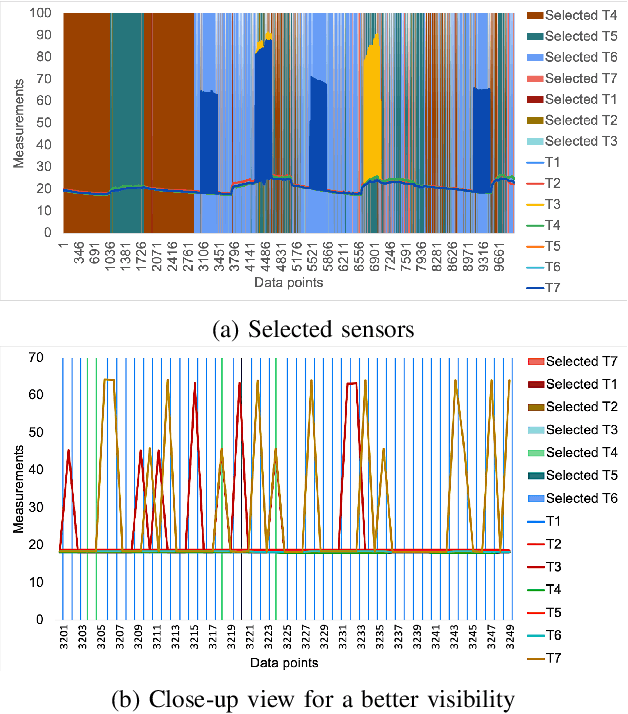
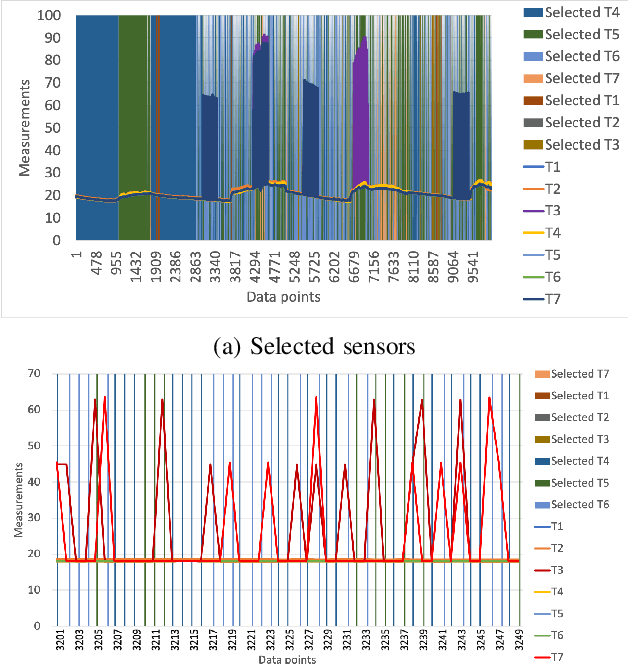
Next-generation smart city applications, attributed by the power of Internet of Things (IoT) and Cyber-Physical Systems (CPS), significantly rely on the quality of sensing data. With an exponential increase in intelligent applications for urban development and enterprises offering sensing-as-aservice these days, it is imperative to provision for a shared sensing infrastructure for better utilization of resources. However, a shared sensing infrastructure that leverages low-cost sensing devices for a cost effective solution, still remains an unexplored territory. A significant research effort is still needed to make edge based data shaping solutions, more reliable, feature-rich and costeffective while addressing the associated challenges in sharing the sensing infrastructure among multiple collocated services with diverse Quality of Service (QoS) requirements. Towards this, we propose a novel edge based data pre-processing solution, named UniPreCIS that accounts for the inherent characteristics of lowcost ambient sensors and the exhibited measurement dynamics with respect to application-specific QoS. UniPreCIS aims to identify and select quality data sources by performing sensor ranking and selection followed by multimodal data pre-processing in order to meet heterogeneous application QoS and at the same time reducing the resource consumption footprint for the resource constrained network edge. As observed, the processing time and memory utilization has been reduced in the proposed approach while achieving upto 90% accuracy which is arguably significant as compared to state-of-the-art techniques for sensing. The effectiveness of UniPreCIS has been evaluated on a testbed for a specific use case of indoor occupancy estimation that proves its effectiveness.
Improving Meta-Learning Generalization with Activation-Based Early-Stopping
Aug 03, 2022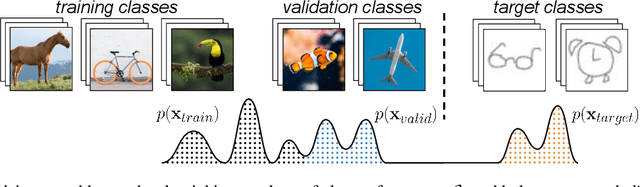

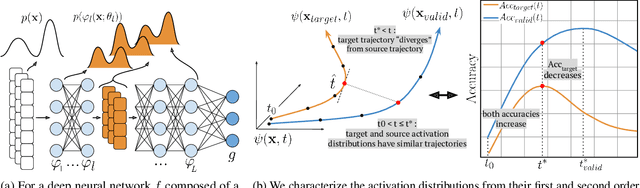
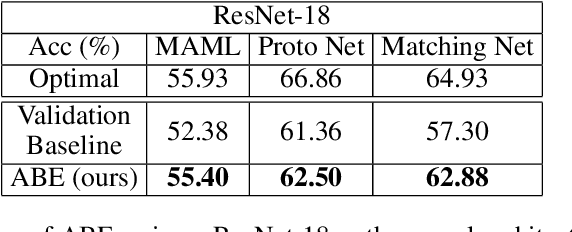
Meta-Learning algorithms for few-shot learning aim to train neural networks capable of generalizing to novel tasks using only a few examples. Early-stopping is critical for performance, halting model training when it reaches optimal generalization to the new task distribution. Early-stopping mechanisms in Meta-Learning typically rely on measuring the model performance on labeled examples from a meta-validation set drawn from the training (source) dataset. This is problematic in few-shot transfer learning settings, where the meta-test set comes from a different target dataset (OOD) and can potentially have a large distributional shift with the meta-validation set. In this work, we propose Activation Based Early-stopping (ABE), an alternative to using validation-based early-stopping for meta-learning. Specifically, we analyze the evolution, during meta-training, of the neural activations at each hidden layer, on a small set of unlabelled support examples from a single task of the target tasks distribution, as this constitutes a minimal and justifiably accessible information from the target problem. Our experiments show that simple, label agnostic statistics on the activations offer an effective way to estimate how the target generalization evolves over time. At each hidden layer, we characterize the activation distributions, from their first and second order moments, then further summarized along the feature dimensions, resulting in a compact yet intuitive characterization in a four-dimensional space. Detecting when, throughout training time, and at which layer, the target activation trajectory diverges from the activation trajectory of the source data, allows us to perform early-stopping and improve generalization in a large array of few-shot transfer learning settings, across different algorithms, source and target datasets.
Renaissance Robot: Optimal Transport Policy Fusion for Learning Diverse Skills
Jul 03, 2022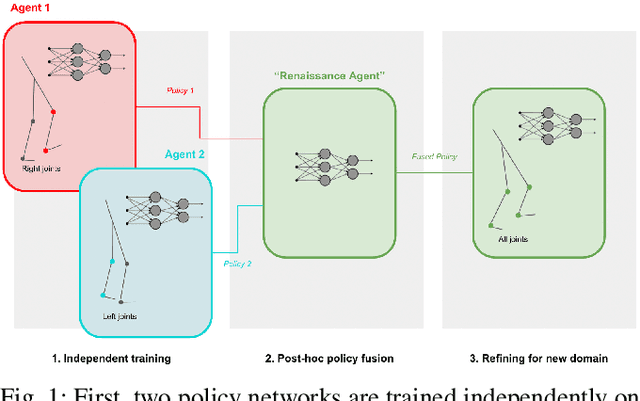
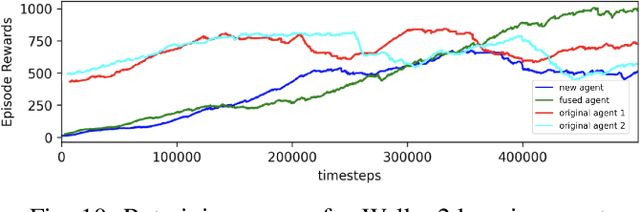
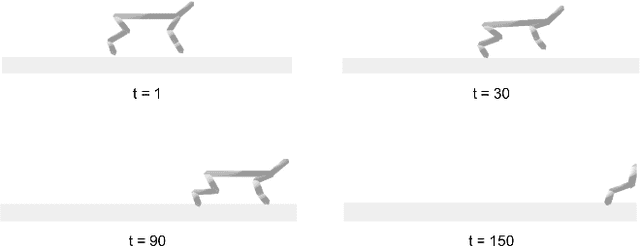
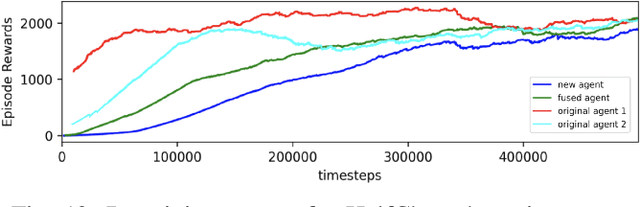
Deep reinforcement learning (RL) is a promising approach to solving complex robotics problems. However, the process of learning through trial-and-error interactions is often highly time-consuming, despite recent advancements in RL algorithms. Additionally, the success of RL is critically dependent on how well the reward-shaping function suits the task, which is also time-consuming to design. As agents trained on a variety of robotics problems continue to proliferate, the ability to reuse their valuable learning for new domains becomes increasingly significant. In this paper, we propose a post-hoc technique for policy fusion using Optimal Transport theory as a robust means of consolidating the knowledge of multiple agents that have been trained on distinct scenarios. We further demonstrate that this provides an improved weights initialisation of the neural network policy for learning new tasks, requiring less time and computational resources than either retraining the parent policies or training a new policy from scratch. Ultimately, our results on diverse agents commonly used in deep RL show that specialised knowledge can be unified into a "Renaissance agent", allowing for quicker learning of new skills.