 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiLaDiff: Distilled Latent-Augmented Diffusion for Language Modeling
May 22, 2026Diffusion language models intrinsically fail to capture correlations between decoded tokens, which leads to a harsh trade-off between sampling quality and throughput. To solve this issue, we propose DiLaDiff, a variant of masked diffusion language models with three components: (1) a continuous latent space with semantic capabilities, learned by an auto-encoder fine-tuned from an existing masked diffusion language model; (2) a latent diffusion model learning the prior over the encoder distribution; (3) a consistency model distilling the learned prior into a few-step latent generative model. We show that, even without distillation, our latent-guided diffusion model outperforms the masked diffusion baseline while significantly accelerating inference. Consistency distillation further lowers the computational overhead of continuous diffusion, such that the latent is generated in negligible time compared to discrete decoding.
Scaling Atomistic Protein Binder Design with Generative Pretraining and Test-Time Compute
Mar 30, 2026Protein interaction modeling is central to protein design, which has been transformed by machine learning with applications in drug discovery and beyond. In this landscape, structure-based de novo binder design is cast as either conditional generative modeling or sequence optimization via structure predictors ("hallucination"). We argue that this is a false dichotomy and propose Proteina-Complexa, a novel fully atomistic binder generation method unifying both paradigms. We extend recent flow-based latent protein generation architectures and leverage the domain-domain interactions of monomeric computationally predicted protein structures to construct Teddymer, a new large-scale dataset of synthetic binder-target pairs for pretraining. Combined with high-quality experimental multimers, this enables training a strong base model. We then perform inference-time optimization with this generative prior, unifying the strengths of previously distinct generative and hallucination methods. Proteina-Complexa sets a new state of the art in computational binder design benchmarks: it delivers markedly higher in-silico success rates than existing generative approaches, and our novel test-time optimization strategies greatly outperform previous hallucination methods under normalized compute budgets. We also demonstrate interface hydrogen bond optimization, fold class-guided binder generation, and extensions to small molecule targets and enzyme design tasks, again surpassing prior methods. Code, models and new data will be publicly released.
Latent Target Score Matching, with an application to Simulation-Based Inference
Feb 06, 2026Denoising score matching (DSM) for training diffusion models may suffer from high variance at low noise levels. Target Score Matching (TSM) mitigates this when clean data scores are available, providing a low-variance objective. In many applications clean scores are inaccessible due to the presence of latent variables, leaving only joint signals exposed. We propose Latent Target Score Matching (LTSM), an extension of TSM to leverage joint scores for low-variance supervision of the marginal score. While LTSM is effective at low noise levels, a mixture with DSM ensures robustness across noise scales. Across simulation-based inference tasks, LTSM consistently improves variance, score accuracy, and sample quality.
Learning Straight Flows by Learning Curved Interpolants
Mar 26, 2025



Flow matching models typically use linear interpolants to define the forward/noise addition process. This, together with the independent coupling between noise and target distributions, yields a vector field which is often non-straight. Such curved fields lead to a slow inference/generation process. In this work, we propose to learn flexible (potentially curved) interpolants in order to learn straight vector fields to enable faster generation. We formulate this via a multi-level optimization problem and propose an efficient approximate procedure to solve it. Our framework provides an end-to-end and simulation-free optimization procedure, which can be leveraged to learn straight line generative trajectories.
Energy-Based Diffusion Language Models for Text Generation
Oct 28, 2024



Despite remarkable progress in autoregressive language models, alternative generative paradigms beyond left-to-right generation are still being actively explored. Discrete diffusion models, with the capacity for parallel generation, have recently emerged as a promising alternative. Unfortunately, these models still underperform the autoregressive counterparts, with the performance gap increasing when reducing the number of sampling steps. Our analysis reveals that this degradation is a consequence of an imperfect approximation used by diffusion models. In this work, we propose Energy-based Diffusion Language Model (EDLM), an energy-based model operating at the full sequence level for each diffusion step, introduced to improve the underlying approximation used by diffusion models. More specifically, we introduce an EBM in a residual form, and show that its parameters can be obtained by leveraging a pretrained autoregressive model or by finetuning a bidirectional transformer via noise contrastive estimation. We also propose an efficient generation algorithm via parallel important sampling. Comprehensive experiments on language modeling benchmarks show that our model can consistently outperform state-of-the-art diffusion models by a significant margin, and approaches autoregressive models' perplexity. We further show that, without any generation performance drop, our framework offers a 1.3$\times$ sampling speedup over existing diffusion models.
Truncated Consistency Models
Oct 18, 2024



Consistency models have recently been introduced to accelerate sampling from diffusion models by directly predicting the solution (i.e., data) of the probability flow ODE (PF ODE) from initial noise. However, the training of consistency models requires learning to map all intermediate points along PF ODE trajectories to their corresponding endpoints. This task is much more challenging than the ultimate objective of one-step generation, which only concerns the PF ODE's noise-to-data mapping. We empirically find that this training paradigm limits the one-step generation performance of consistency models. To address this issue, we generalize consistency training to the truncated time range, which allows the model to ignore denoising tasks at earlier time steps and focus its capacity on generation. We propose a new parameterization of the consistency function and a two-stage training procedure that prevents the truncated-time training from collapsing to a trivial solution. Experiments on CIFAR-10 and ImageNet $64\times64$ datasets show that our method achieves better one-step and two-step FIDs than the state-of-the-art consistency models such as iCT-deep, using more than 2$\times$ smaller networks. Project page: https://truncated-cm.github.io/
Aligning Target-Aware Molecule Diffusion Models with Exact Energy Optimization
Jul 01, 2024Generating ligand molecules for specific protein targets, known as structure-based drug design, is a fundamental problem in therapeutics development and biological discovery. Recently, target-aware generative models, especially diffusion models, have shown great promise in modeling protein-ligand interactions and generating candidate drugs. However, existing models primarily focus on learning the chemical distribution of all drug candidates, which lacks effective steerability on the chemical quality of model generations. In this paper, we propose a novel and general alignment framework to align pretrained target diffusion models with preferred functional properties, named AliDiff. AliDiff shifts the target-conditioned chemical distribution towards regions with higher binding affinity and structural rationality, specified by user-defined reward functions, via the preference optimization approach. To avoid the overfitting problem in common preference optimization objectives, we further develop an improved Exact Energy Preference Optimization method to yield an exact and efficient alignment of the diffusion models, and provide the closed-form expression for the converged distribution. Empirical studies on the CrossDocked2020 benchmark show that AliDiff can generate molecules with state-of-the-art binding energies with up to -7.07 Avg. Vina Score, while maintaining strong molecular properties.
A Dual Control Variate for doubly stochastic optimization and black-box variational inference
Oct 13, 2022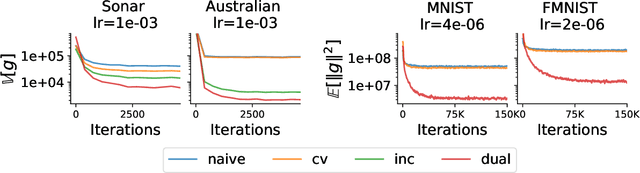
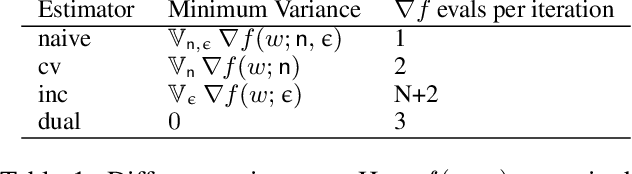
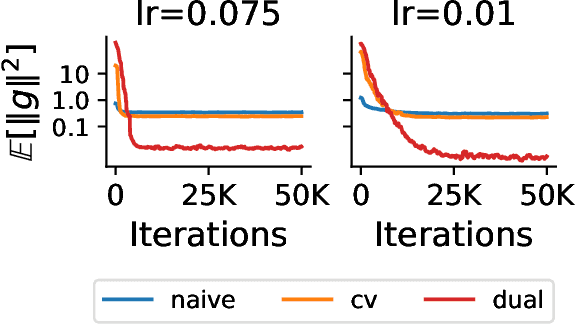
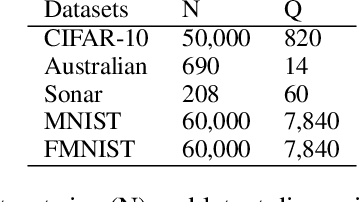
In this paper, we aim at reducing the variance of doubly stochastic optimization, a type of stochastic optimization algorithm that contains two independent sources of randomness: The subsampling of training data and the Monte Carlo estimation of expectations. Such an optimization regime often has the issue of large gradient variance which would lead to a slow rate of convergence. Therefore we propose Dual Control Variate, a new type of control variate capable of reducing gradient variance from both sources jointly. The dual control variate is built upon approximation-based control variates and incremental gradient methods. We show that on doubly stochastic optimization problems, compared with past variance reduction approaches that take only one source of randomness into account, dual control variate leads to a gradient estimator of significant smaller variance and demonstrates superior performance on real-world applications, like generalized linear models with dropout and black-box variational inference.
Score Modeling for Simulation-based Inference
Sep 28, 2022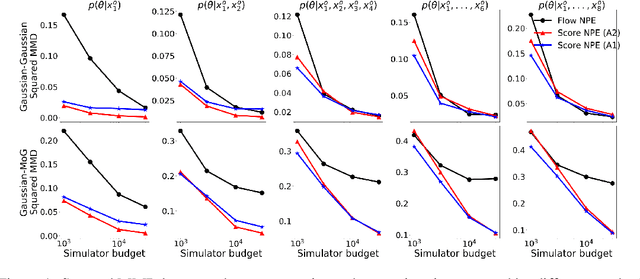
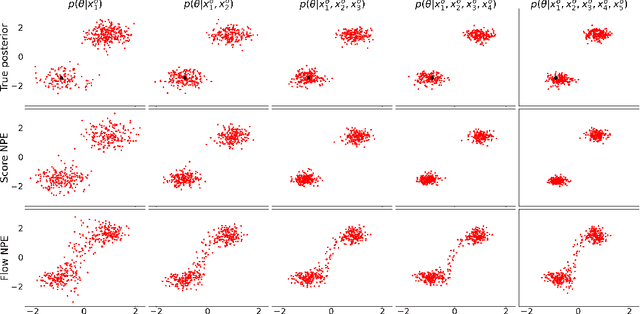
Neural Posterior Estimation methods for simulation-based inference can be ill-suited for dealing with posterior distributions obtained by conditioning on multiple observations, as they may require a large number of simulator calls to yield accurate approximations. Neural Likelihood Estimation methods can naturally handle multiple observations, but require a separate inference step, which may affect their efficiency and performance. We introduce a new method for simulation-based inference that enjoys the benefits of both approaches. We propose to model the scores for the posterior distributions induced by individual observations, and introduce a sampling algorithm that combines the learned scores to approximately sample from the target efficiently.
Langevin Diffusion Variational Inference
Aug 16, 2022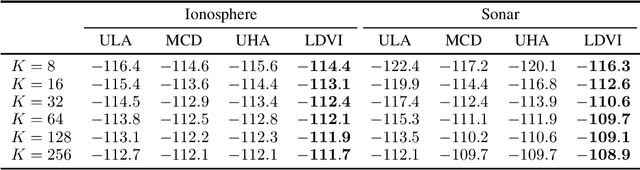
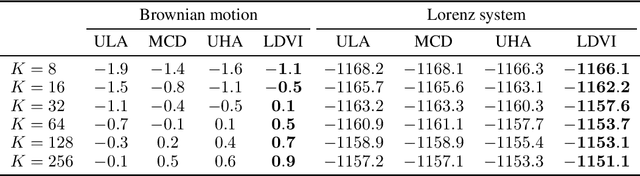
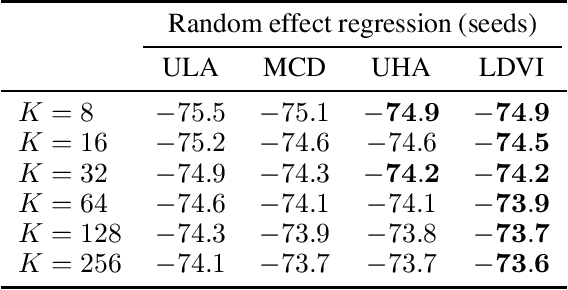
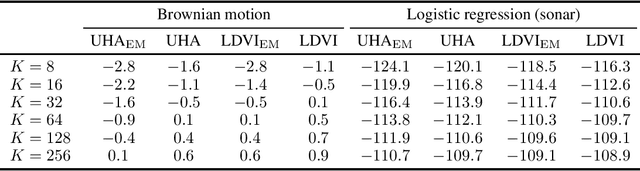
Many methods that build powerful variational distributions based on unadjusted Langevin transitions exist. Most of these were developed using a wide range of different approaches and techniques. Unfortunately, the lack of a unified analysis and derivation makes developing new methods and reasoning about existing ones a challenging task. We address this giving a single analysis that unifies and generalizes these existing techniques. The main idea is to augment the target and variational by numerically simulating the underdamped Langevin diffusion process and its time reversal. The benefits of this approach are twofold: it provides a unified formulation for many existing methods, and it simplifies the development of new ones. In fact, using our formulation we propose a new method that combines the strengths of previously existing algorithms; it uses underdamped Langevin transitions and powerful augmentations parameterized by a score network. Our empirical evaluation shows that our proposed method consistently outperforms relevant baselines in a wide range of tasks.