 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Recurrent Convolutional Neural Networks Learn Succinct Learning Algorithms
Sep 01, 2022

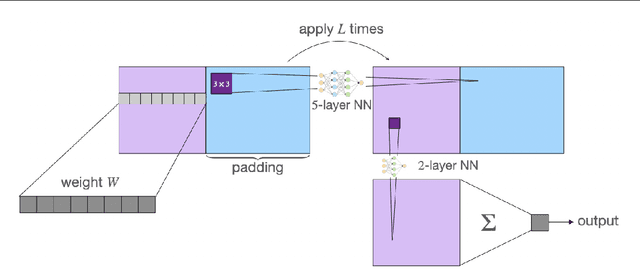
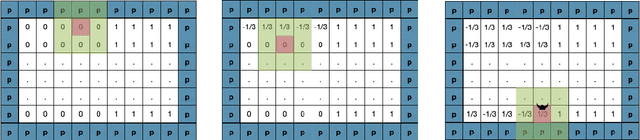
Neural Networks (NNs) struggle to efficiently learn certain problems, such as parity problems, even when there are simple learning algorithms for those problems. Can NNs discover learning algorithms on their own? We exhibit a NN architecture that, in polynomial time, learns as well as any efficient learning algorithm describable by a constant-sized learning algorithm. For example, on parity problems, the NN learns as well as row reduction, an efficient algorithm that can be succinctly described. Our architecture combines both recurrent weight-sharing between layers and convolutional weight-sharing to reduce the number of parameters down to a constant, even though the network itself may have trillions of nodes. While in practice the constants in our analysis are too large to be directly meaningful, our work suggests that the synergy of Recurrent and Convolutional NNs (RCNNs) may be more powerful than either alone.
Hierarchical Interdisciplinary Topic Detection Model for Research Proposal Classification
Sep 16, 2022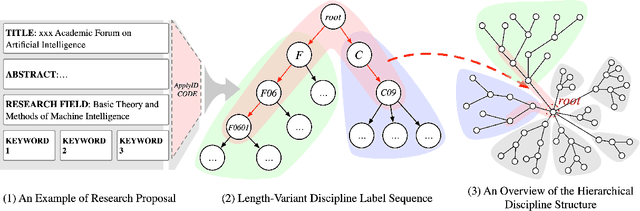
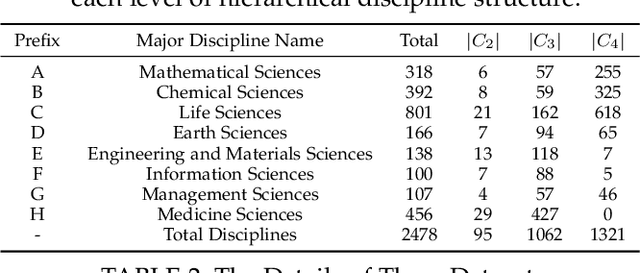
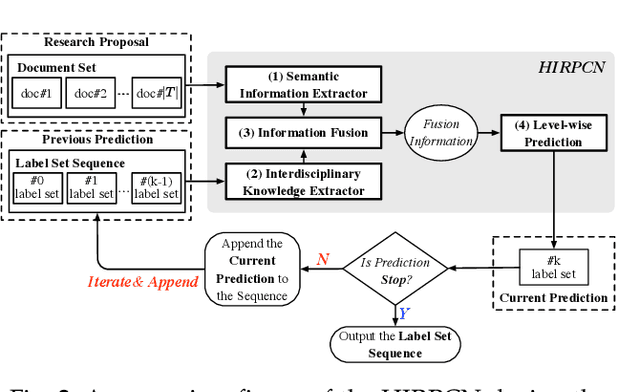
The peer merit review of research proposals has been the major mechanism for deciding grant awards. However, research proposals have become increasingly interdisciplinary. It has been a longstanding challenge to assign interdisciplinary proposals to appropriate reviewers, so proposals are fairly evaluated. One of the critical steps in reviewer assignment is to generate accurate interdisciplinary topic labels for proposal-reviewer matching. Existing systems mainly collect topic labels manually generated by principal investigators. However, such human-reported labels can be non-accurate, incomplete, labor intensive, and time costly. What role can AI play in developing a fair and precise proposal reviewer assignment system? In this study, we collaborate with the National Science Foundation of China to address the task of automated interdisciplinary topic path detection. For this purpose, we develop a deep Hierarchical Interdisciplinary Research Proposal Classification Network (HIRPCN). Specifically, we first propose a hierarchical transformer to extract the textual semantic information of proposals. We then design an interdisciplinary graph and leverage GNNs for learning representations of each discipline in order to extract interdisciplinary knowledge. After extracting the semantic and interdisciplinary knowledge, we design a level-wise prediction component to fuse the two types of knowledge representations and detect interdisciplinary topic paths for each proposal. We conduct extensive experiments and expert evaluations on three real-world datasets to demonstrate the effectiveness of our proposed model.
Automated MeSH Term Suggestion for Effective Query Formulation in Systematic Reviews Literature Search
Sep 19, 2022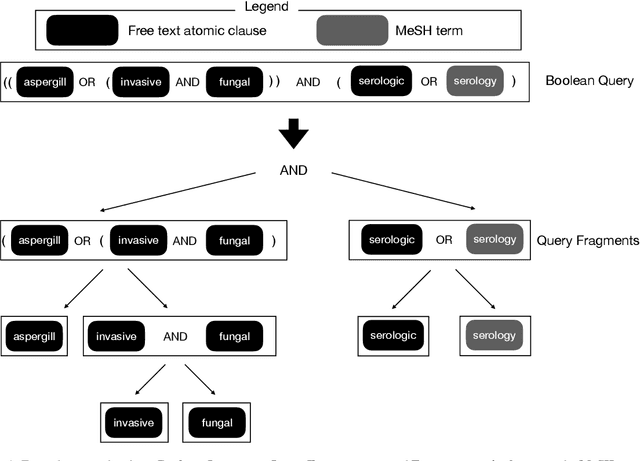

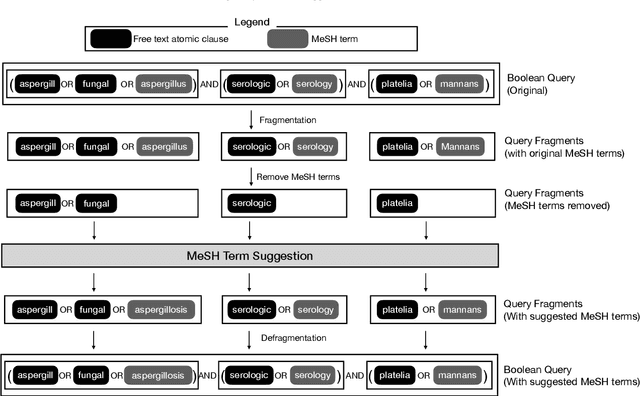
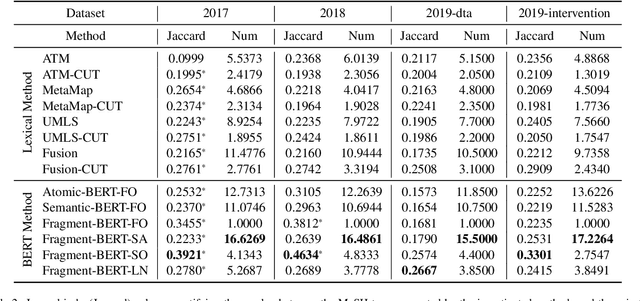
High-quality medical systematic reviews require comprehensive literature searches to ensure the recommendations and outcomes are sufficiently reliable. Indeed, searching for relevant medical literature is a key phase in constructing systematic reviews and often involves domain (medical researchers) and search (information specialists) experts in developing the search queries. Queries in this context are highly complex, based on Boolean logic, include free-text terms and index terms from standardised terminologies (e.g., the Medical Subject Headings (MeSH) thesaurus), and are difficult and time-consuming to build. The use of MeSH terms, in particular, has been shown to improve the quality of the search results. However, identifying the correct MeSH terms to include in a query is difficult: information experts are often unfamiliar with the MeSH database and unsure about the appropriateness of MeSH terms for a query. Naturally, the full value of the MeSH terminology is often not fully exploited. This article investigates methods to suggest MeSH terms based on an initial Boolean query that includes only free-text terms. In this context, we devise lexical and pre-trained language models based methods. These methods promise to automatically identify highly effective MeSH terms for inclusion in a systematic review query. Our study contributes an empirical evaluation of several MeSH term suggestion methods. We further contribute an extensive analysis of MeSH term suggestions for each method and how these suggestions impact the effectiveness of Boolean queries.
Continual Learning for Class- and Domain-Incremental Semantic Segmentation
Sep 16, 2022
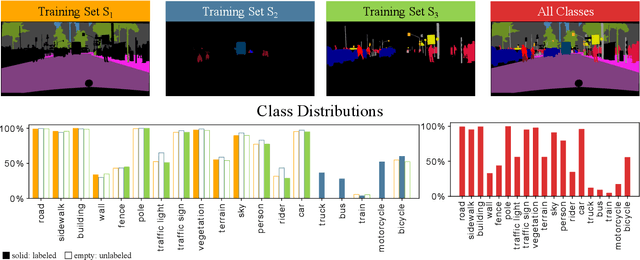
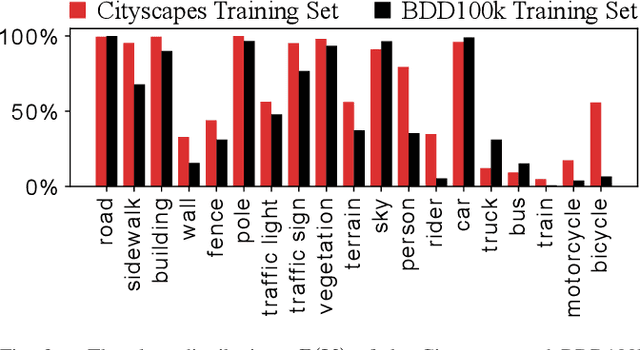
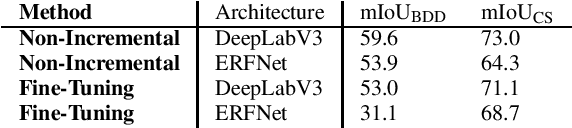
The field of continual deep learning is an emerging field and a lot of progress has been made. However, concurrently most of the approaches are only tested on the task of image classification, which is not relevant in the field of intelligent vehicles. Only recently approaches for class-incremental semantic segmentation were proposed. However, all of those approaches are based on some form of knowledge distillation. At the moment there are no investigations on replay-based approaches that are commonly used for object recognition in a continual setting. At the same time while unsupervised domain adaption for semantic segmentation gained a lot of traction, investigations regarding domain-incremental learning in an continual setting is not well-studied. Therefore, the goal of our work is to evaluate and adapt established solutions for continual object recognition to the task of semantic segmentation and to provide baseline methods and evaluation protocols for the task of continual semantic segmentation. We firstly introduce evaluation protocols for the class- and domain-incremental segmentation and analyze selected approaches. We show that the nature of the task of semantic segmentation changes which methods are most effective in mitigating forgetting compared to image classification. Especially, in class-incremental learning knowledge distillation proves to be a vital tool, whereas in domain-incremental learning replay methods are the most effective method.
Git Re-Basin: Merging Models modulo Permutation Symmetries
Sep 11, 2022
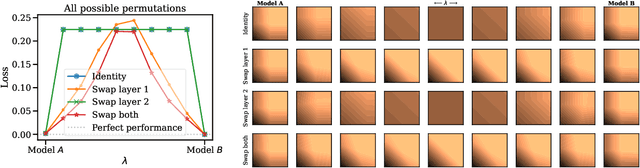

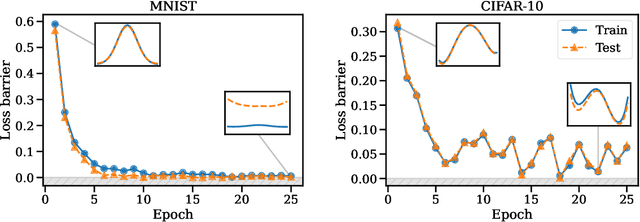
The success of deep learning is thanks to our ability to solve certain massive non-convex optimization problems with relative ease. Despite non-convex optimization being NP-hard, simple algorithms -- often variants of stochastic gradient descent -- exhibit surprising effectiveness in fitting large neural networks in practice. We argue that neural network loss landscapes contain (nearly) a single basin, after accounting for all possible permutation symmetries of hidden units. We introduce three algorithms to permute the units of one model to bring them into alignment with units of a reference model. This transformation produces a functionally equivalent set of weights that lie in an approximately convex basin near the reference model. Experimentally, we demonstrate the single basin phenomenon across a variety of model architectures and datasets, including the first (to our knowledge) demonstration of zero-barrier linear mode connectivity between independently trained ResNet models on CIFAR-10 and CIFAR-100. Additionally, we identify intriguing phenomena relating model width and training time to mode connectivity across a variety of models and datasets. Finally, we discuss shortcomings of a single basin theory, including a counterexample to the linear mode connectivity hypothesis.
Joint User and Data Detection in Grant-Free NOMA with Attention-based BiLSTM Network
Sep 14, 2022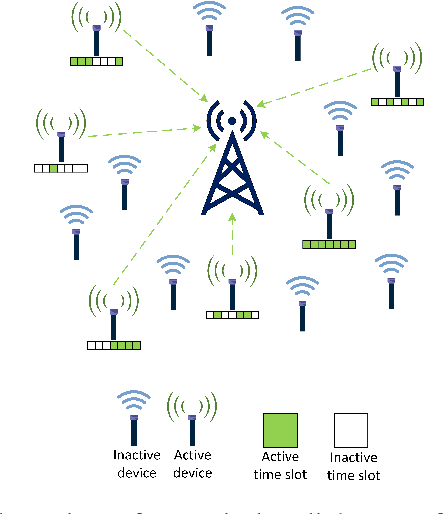
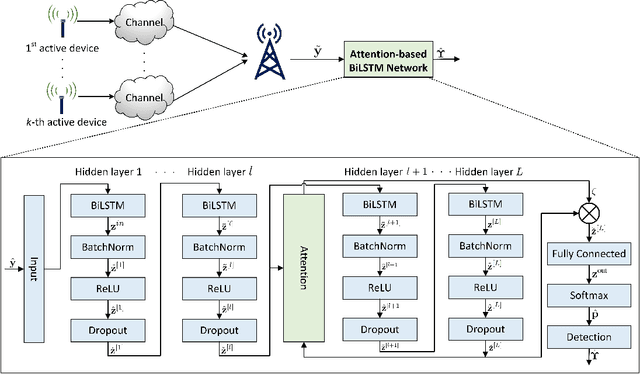
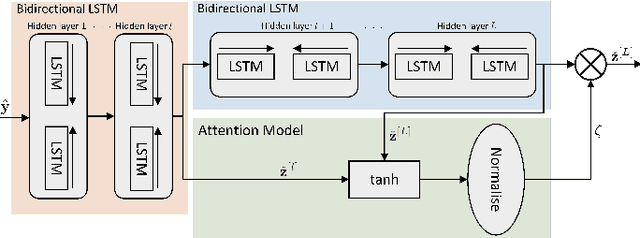
We consider the multi-user detection (MUD) problem in uplink grant-free non-orthogonal multiple access (NOMA), where the access point has to identify the total number and correct identity of the active Internet of Things (IoT) devices and decode their transmitted data. We assume that IoT devices use complex spreading sequences and transmit information in a random-access manner following the burst-sparsity model, where some IoT devices transmit their data in multiple adjacent time slots with a high probability, while others transmit only once during a frame. Exploiting the temporal correlation, we propose an attention-based bidirectional long short-term memory (BiLSTM) network to solve the MUD problem. The BiLSTM network creates a pattern of the device activation history using forward and reverse pass LSTMs, whereas the attention mechanism provides essential context to the device activation points. By doing so, a hierarchical pathway is followed for detecting active devices in a grant-free scenario. Then, by utilising the complex spreading sequences, blind data detection for the estimated active devices is performed. The proposed framework does not require prior knowledge of device sparsity levels and channels for performing MUD. The results show that the proposed network achieves better performance compared to existing benchmark schemes.
Time-Energy-Constrained Closed-Loop FBL Communication for Dependable MEC
Dec 07, 2021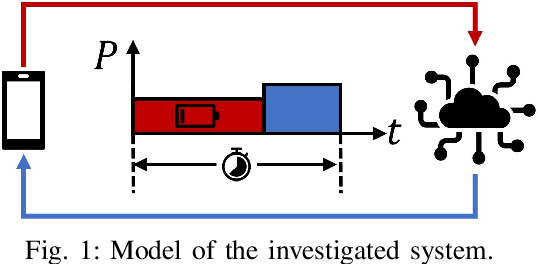
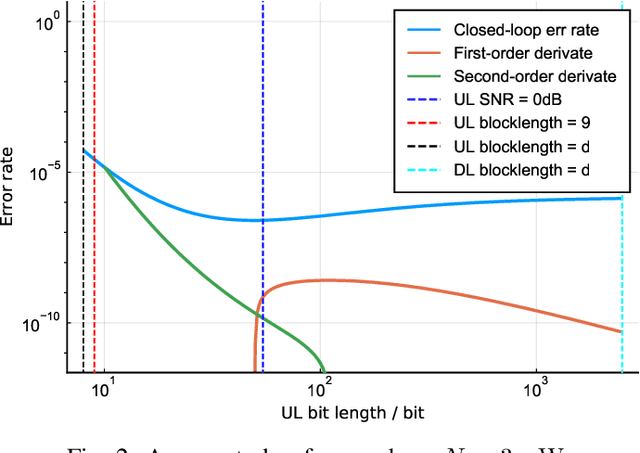
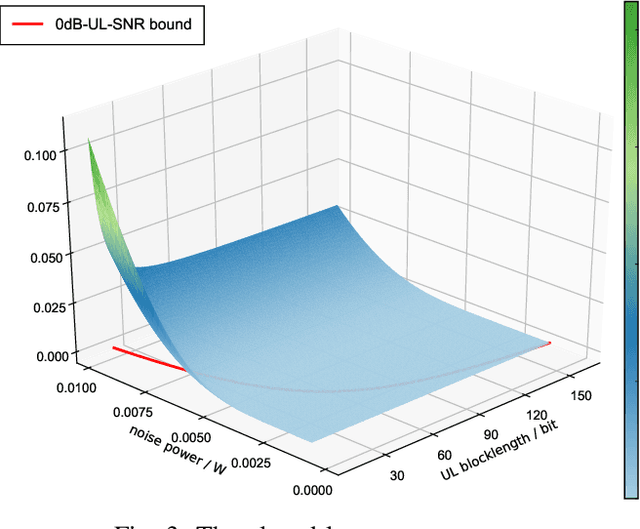
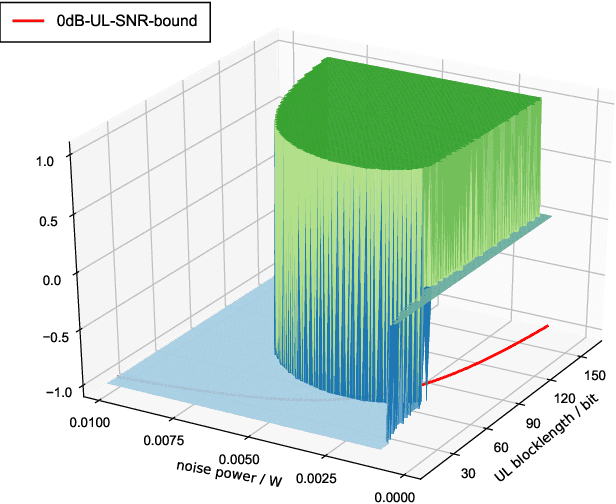
The deployment of multi-access edge computing (MEC) is paving the way towards pervasive intelligence in future 6G networks. This new paradigm also proposes emerging requirements of dependable communications, which goes beyond the ultra-reliable low latency communication (URLLC), focusing on the performance of a closed loop instead of that of an unidirectional link. This work studies the simple but efficient one-shot transmission scheme, investigating the closed-loop-reliability-optimal policy of blocklength allocation under stringent time and energy constraints.
QSAM-Net: Rain streak removal by quaternion neural network with self-attention module
Aug 08, 2022
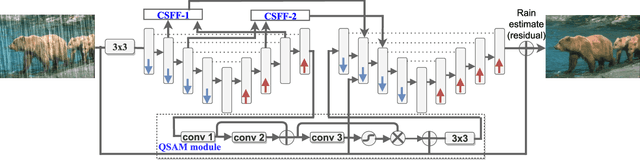


Images captured in real-world applications in remote sensing, image or video retrieval, and outdoor surveillance suffer degraded quality introduced by poor weather conditions. Conditions such as rain and mist, introduce artifacts that make visual analysis challenging and limit the performance of high-level computer vision methods. For time-critical applications where a rapid response is necessary, it becomes crucial to develop algorithms that automatically remove rain, without diminishing the quality of the image contents. This article aims to develop a novel quaternion multi-stage multiscale neural network with a self-attention module called QSAM-Net to remove rain streaks. The novelty of this algorithm is that it requires significantly fewer parameters by a factor of 3.98, over prior methods, while improving visual quality. This is demonstrated by the extensive evaluation and benchmarking on synthetic and real-world rainy images. This feature of QSAM-Net makes the network suitable for implementation on edge devices and applications requiring near real-time performance. The experiments demonstrate that by improving the visual quality of images. In addition, object detection accuracy and training speed are also improved.
BoxShrink: From Bounding Boxes to Segmentation Masks
Aug 05, 2022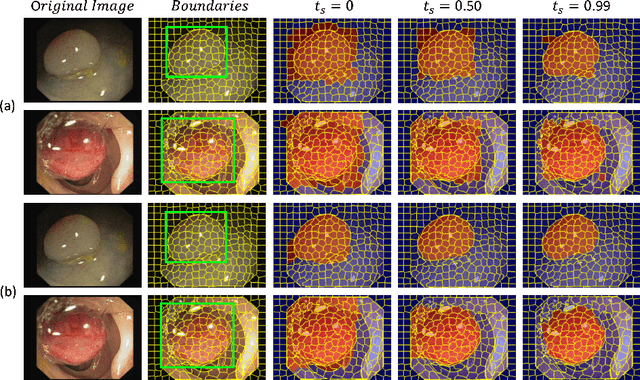
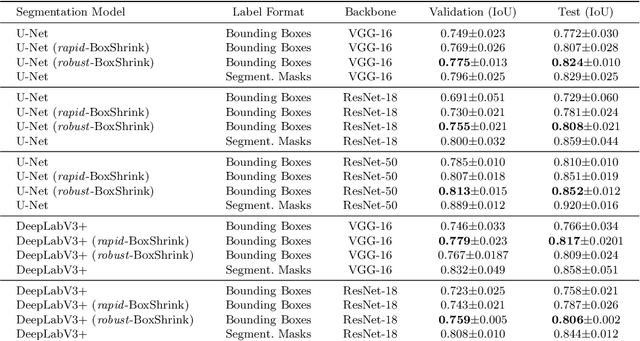
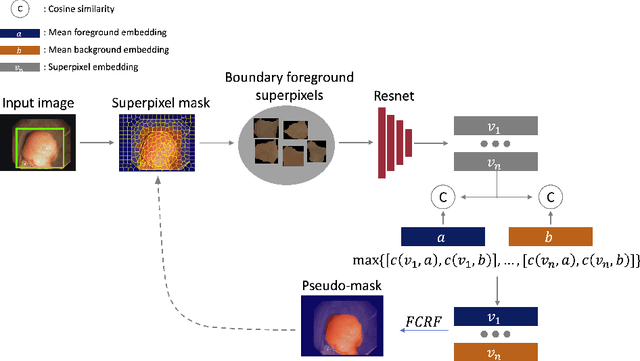
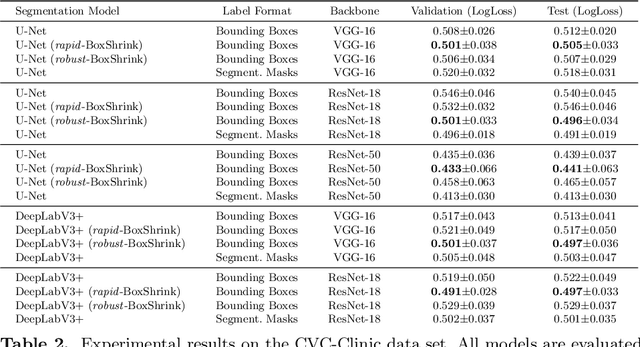
One of the core challenges facing the medical image computing community is fast and efficient data sample labeling. Obtaining fine-grained labels for segmentation is particularly demanding since it is expensive, time-consuming, and requires sophisticated tools. On the contrary, applying bounding boxes is fast and takes significantly less time than fine-grained labeling, but does not produce detailed results. In response, we propose a novel framework for weakly-supervised tasks with the rapid and robust transformation of bounding boxes into segmentation masks without training any machine learning model, coined BoxShrink. The proposed framework comes in two variants - rapid-BoxShrink for fast label transformations, and robust-BoxShrink for more precise label transformations. An average of four percent improvement in IoU is found across several models when being trained using BoxShrink in a weakly-supervised setting, compared to using only bounding box annotations as inputs on a colonoscopy image data set. We open-sourced the code for the proposed framework and published it online.
Efficient Heterogeneous Video Segmentation at the Edge
Aug 24, 2022
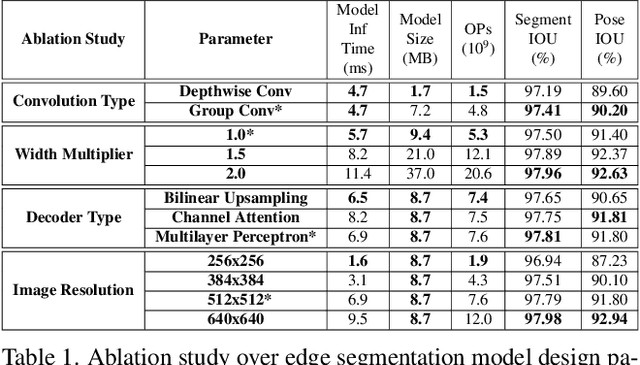
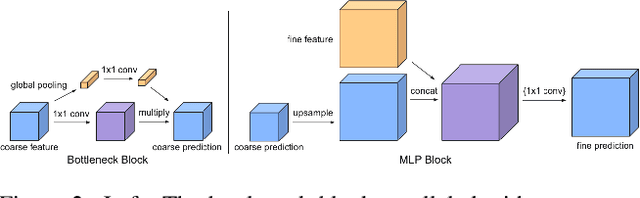
We introduce an efficient video segmentation system for resource-limited edge devices leveraging heterogeneous compute. Specifically, we design network models by searching across multiple dimensions of specifications for the neural architectures and operations on top of already light-weight backbones, targeting commercially available edge inference engines. We further analyze and optimize the heterogeneous data flows in our systems across the CPU, the GPU and the NPU. Our approach has empirically factored well into our real-time AR system, enabling remarkably higher accuracy with quadrupled effective resolutions, yet at much shorter end-to-end latency, much higher frame rate, and even lower power consumption on edge platforms.