 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinaural Angular Separation Network
Jan 16, 2024



We propose a neural network model that can separate target speech sources from interfering sources at different angular regions using two microphones. The model is trained with simulated room impulse responses (RIRs) using omni-directional microphones without needing to collect real RIRs. By relying on specific angular regions and multiple room simulations, the model utilizes consistent time difference of arrival (TDOA) cues, or what we call delay contrast, to separate target and interference sources while remaining robust in various reverberation environments. We demonstrate the model is not only generalizable to a commercially available device with a slightly different microphone geometry, but also outperforms our previous work which uses one additional microphone on the same device. The model runs in real-time on-device and is suitable for low-latency streaming applications such as telephony and video conferencing.
StreamVC: Real-Time Low-Latency Voice Conversion
Jan 05, 2024We present StreamVC, a streaming voice conversion solution that preserves the content and prosody of any source speech while matching the voice timbre from any target speech. Unlike previous approaches, StreamVC produces the resulting waveform at low latency from the input signal even on a mobile platform, making it applicable to real-time communication scenarios like calls and video conferencing, and addressing use cases such as voice anonymization in these scenarios. Our design leverages the architecture and training strategy of the SoundStream neural audio codec for lightweight high-quality speech synthesis. We demonstrate the feasibility of learning soft speech units causally, as well as the effectiveness of supplying whitened fundamental frequency information to improve pitch stability without leaking the source timbre information.
On-device Real-time Custom Hand Gesture Recognition
Sep 19, 2023



Most existing hand gesture recognition (HGR) systems are limited to a predefined set of gestures. However, users and developers often want to recognize new, unseen gestures. This is challenging due to the vast diversity of all plausible hand shapes, e.g. it is impossible for developers to include all hand gestures in a predefined list. In this paper, we present a user-friendly framework that lets users easily customize and deploy their own gesture recognition pipeline. Our framework provides a pre-trained single-hand embedding model that can be fine-tuned for custom gesture recognition. Users can perform gestures in front of a webcam to collect a small amount of images per gesture. We also offer a low-code solution to train and deploy the custom gesture recognition model. This makes it easy for users with limited ML expertise to use our framework. We further provide a no-code web front-end for users without any ML expertise. This makes it even easier to build and test the end-to-end pipeline. The resulting custom HGR is then ready to be run on-device for real-time scenarios. This can be done by calling a simple function in our open-sourced model inference API, MediaPipe Tasks. This entire process only takes a few minutes.
Learning to Detect Touches on Cluttered Tables
Apr 10, 2023
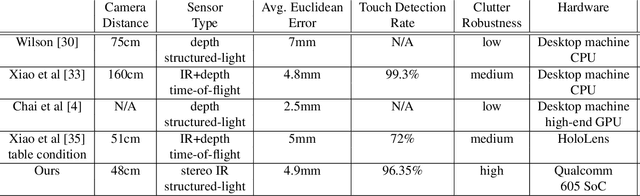

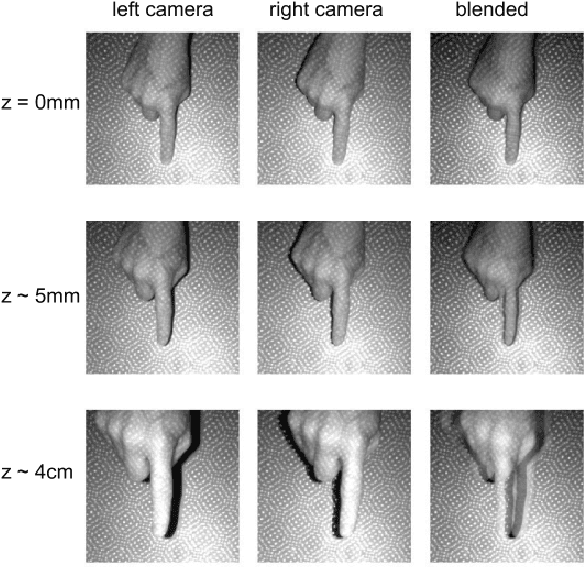
We present a novel self-contained camera-projector tabletop system with a lamp form-factor that brings digital intelligence to our tables. We propose a real-time, on-device, learning-based touch detection algorithm that makes any tabletop interactive. The top-down configuration and learning-based algorithm makes our method robust to the presence of clutter, a main limitation of existing camera-projector tabletop systems. Our research prototype enables a set of experiences that combine hand interactions and objects present on the table. A video can be found at https://youtu.be/hElC_c25Fg8.
Guided Speech Enhancement Network
Mar 13, 2023High quality speech capture has been widely studied for both voice communication and human computer interface reasons. To improve the capture performance, we can often find multi-microphone speech enhancement techniques deployed on various devices. Multi-microphone speech enhancement problem is often decomposed into two decoupled steps: a beamformer that provides spatial filtering and a single-channel speech enhancement model that cleans up the beamformer output. In this work, we propose a speech enhancement solution that takes both the raw microphone and beamformer outputs as the input for an ML model. We devise a simple yet effective training scheme that allows the model to learn from the cues of the beamformer by contrasting the two inputs and greatly boost its capability in spatial rejection, while conducting the general tasks of denoising and dereverberation. The proposed solution takes advantage of classical spatial filtering algorithms instead of competing with them. By design, the beamformer module then could be selected separately and does not require a large amount of data to be optimized for a given form factor, and the network model can be considered as a standalone module which is highly transferable independently from the microphone array. We name the ML module in our solution as GSENet, short for Guided Speech Enhancement Network. We demonstrate its effectiveness on real world data collected on multi-microphone devices in terms of the suppression of noise and interfering speech.
Efficient Heterogeneous Video Segmentation at the Edge
Aug 24, 2022
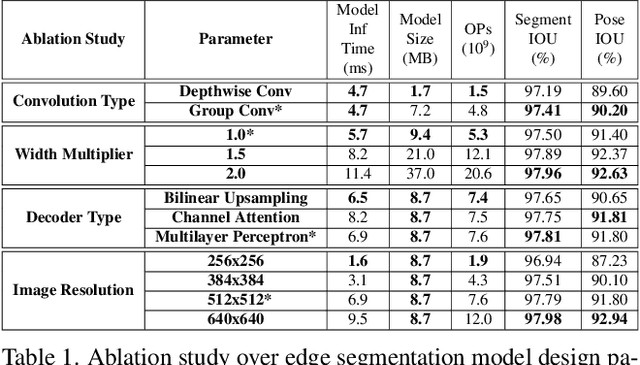
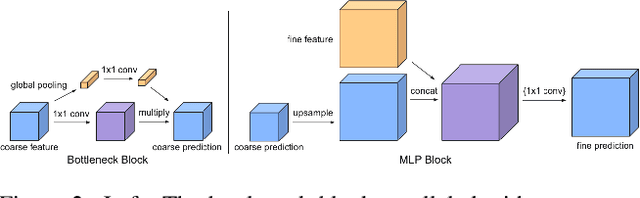
We introduce an efficient video segmentation system for resource-limited edge devices leveraging heterogeneous compute. Specifically, we design network models by searching across multiple dimensions of specifications for the neural architectures and operations on top of already light-weight backbones, targeting commercially available edge inference engines. We further analyze and optimize the heterogeneous data flows in our systems across the CPU, the GPU and the NPU. Our approach has empirically factored well into our real-time AR system, enabling remarkably higher accuracy with quadrupled effective resolutions, yet at much shorter end-to-end latency, much higher frame rate, and even lower power consumption on edge platforms.
On-device Real-time Hand Gesture Recognition
Oct 29, 2021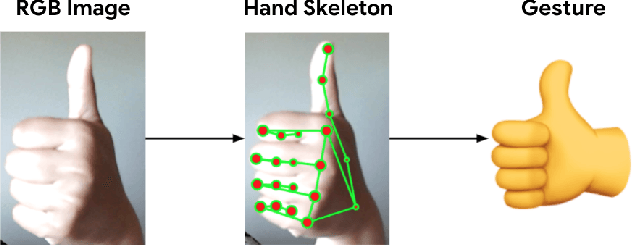
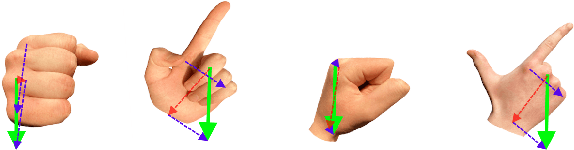

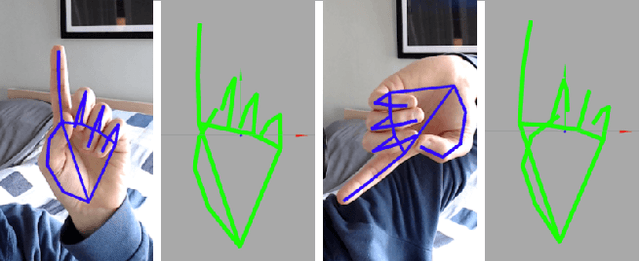
We present an on-device real-time hand gesture recognition (HGR) system, which detects a set of predefined static gestures from a single RGB camera. The system consists of two parts: a hand skeleton tracker and a gesture classifier. We use MediaPipe Hands as the basis of the hand skeleton tracker, improve the keypoint accuracy, and add the estimation of 3D keypoints in a world metric space. We create two different gesture classifiers, one based on heuristics and the other using neural networks (NN).
MediaPipe Hands: On-device Real-time Hand Tracking
Jun 18, 2020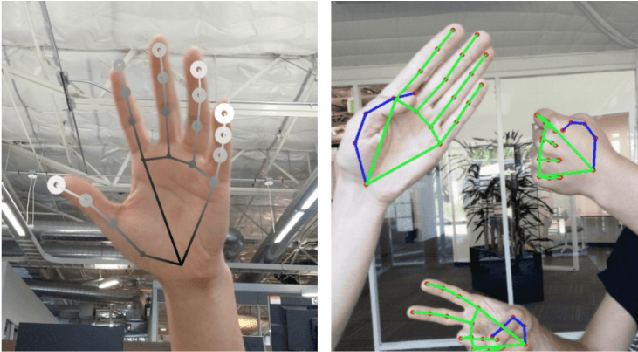
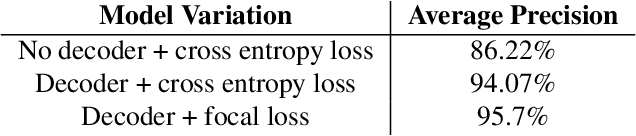
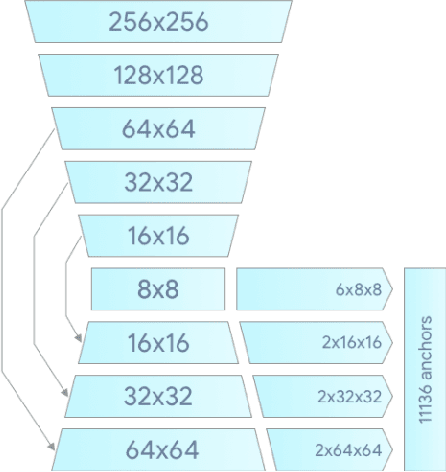

We present a real-time on-device hand tracking pipeline that predicts hand skeleton from single RGB camera for AR/VR applications. The pipeline consists of two models: 1) a palm detector, 2) a hand landmark model. It's implemented via MediaPipe, a framework for building cross-platform ML solutions. The proposed model and pipeline architecture demonstrates real-time inference speed on mobile GPUs and high prediction quality. MediaPipe Hands is open sourced at https://mediapipe.dev.