 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Concepts and Experiments on Psychoanalysis Driven Computing
Sep 29, 2022
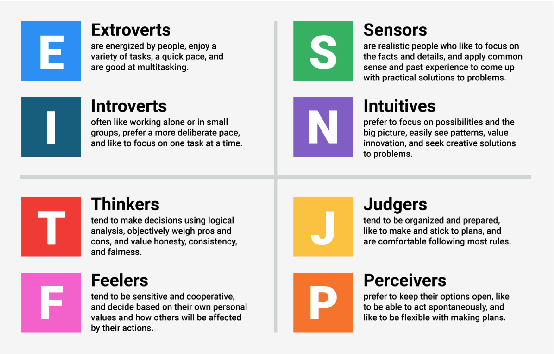
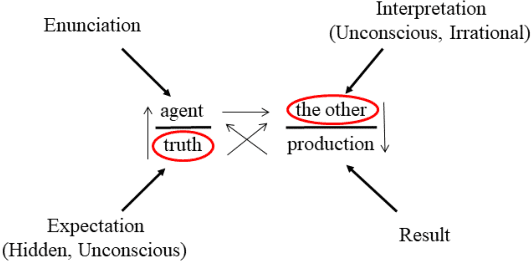
This research investigates the effective incorporation of the human factor and user perception in text-based interactive media. In such contexts, the reliability of user texts is often compromised by behavioural and emotional dimensions. To this end, several attempts have been made in the state of the art, to introduce psychological approaches in such systems, including computational psycholinguistics, personality traits and cognitive psychology methods. In contrast, our method is fundamentally different since we employ a psychoanalysis-based approach; in particular, we use the notion of Lacanian discourse types, to capture and deeply understand real (possibly elusive) characteristics, qualities and contents of texts, and evaluate their reliability. As far as we know, this is the first time computational methods are systematically combined with psychoanalysis. We believe such psychoanalytic framework is fundamentally more effective than standard methods, since it addresses deeper, quite primitive elements of human personality, behaviour and expression which usually escape methods functioning at "higher", conscious layers. In fact, this research is a first attempt to form a new paradigm of psychoanalysis-driven interactive technologies, with broader impact and diverse applications. To exemplify this generic approach, we apply it to the case-study of fake news detection; we first demonstrate certain limitations of the well-known Myers-Briggs Type Indicator (MBTI) personality type method, and then propose and evaluate our new method of analysing user texts and detecting fake news based on the Lacanian discourses psychoanalytic approach.
Efficient Planar Pose Estimation via UWB Measurements
Sep 15, 2022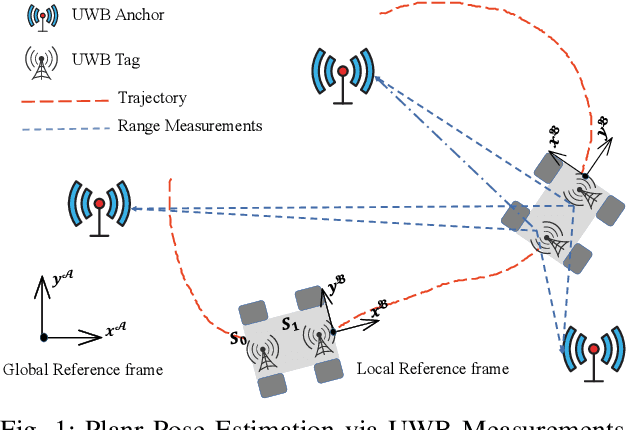
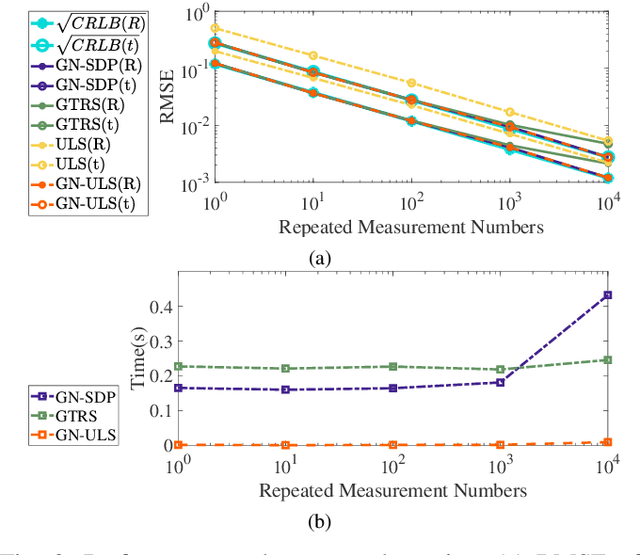
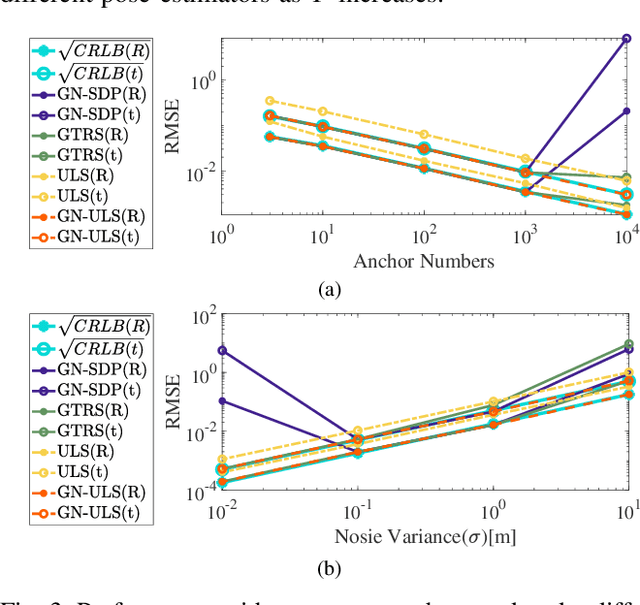

State estimation is an essential part of autonomous systems. Integrating the Ultra-Wideband(UWB) technique has been shown to correct the long-term estimation drift and bypass the complexity of loop closure detection. However, few works on robotics adopt UWB as a stand-alone state estimation solution. The primary purpose of this work is to investigate planar pose estimation using only UWB range measurements and study the estimator's statistical efficiency. We prove the excellent property of a two-step scheme, which says that we can refine a consistent estimator to be asymptotically efficient by one step of Gauss-Newton iteration. Grounded on this result, we design the GN-ULS estimator and evaluate it through simulations and collected datasets. GN-ULS attains millimeter and sub-degree level accuracy on our static datasets and attains centimeter and degree level accuracy on our dynamic datasets, presenting the possibility of using only UWB for real-time state estimation.
A Computer Vision-assisted Approach to Automated Real-Time Road Infrastructure Management
Feb 27, 2022
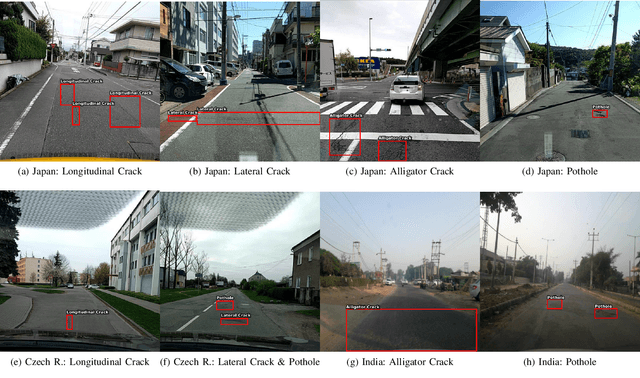
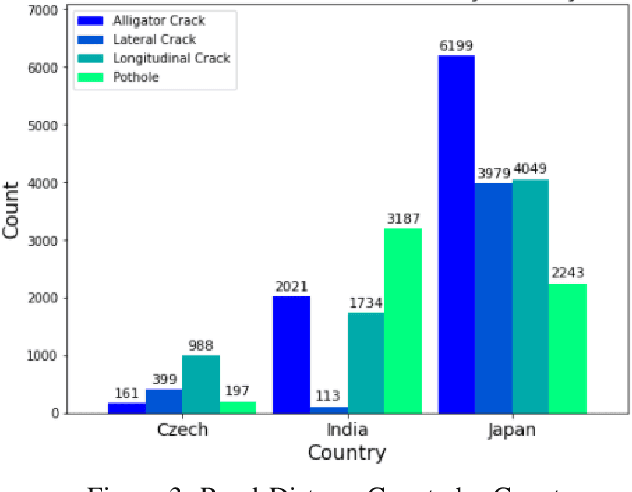
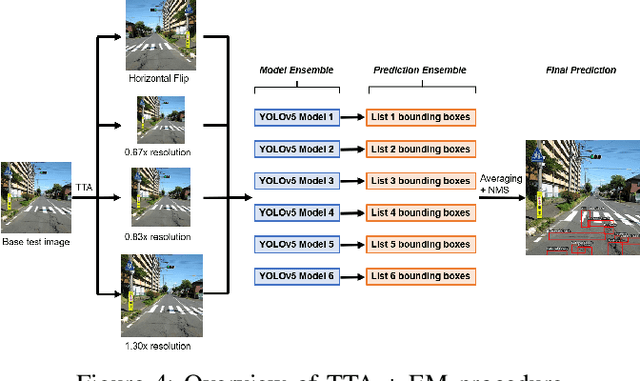
Accurate automated detection of road pavement distresses is critical for the timely identification and repair of potentially accident-inducing road hazards such as potholes and other surface-level asphalt cracks. Deployment of such a system would be further advantageous in low-resource environments where lack of government funding for infrastructure maintenance typically entails heightened risks of potentially fatal vehicular road accidents as a result of inadequate and infrequent manual inspection of road systems for road hazards. To remedy this, a recent research initiative organized by the Institute of Electrical and Electronics Engineers ("IEEE") as part of their 2020 Global Road Damage Detection ("GRDC") Challenge published in May 2020 a novel 21,041 annotated image dataset of various road distresses calling upon academic and other researchers to submit innovative deep learning-based solutions to these road hazard detection problems. Making use of this dataset, we propose a supervised object detection approach leveraging You Only Look Once ("YOLO") and the Faster R-CNN frameworks to detect and classify road distresses in real-time via a vehicle dashboard-mounted smartphone camera, producing 0.68 F1-score experimental results ranking in the top 5 of 121 teams that entered this challenge as of December 2021.
Adversarially Robust Learning: A Generic Minimax Optimal Learner and Characterization
Sep 15, 2022We present a minimax optimal learner for the problem of learning predictors robust to adversarial examples at test-time. Interestingly, we find that this requires new algorithmic ideas and approaches to adversarially robust learning. In particular, we show, in a strong negative sense, the suboptimality of the robust learner proposed by Montasser, Hanneke, and Srebro (2019) and a broader family of learners we identify as local learners. Our results are enabled by adopting a global perspective, specifically, through a key technical contribution: the global one-inclusion graph, which may be of independent interest, that generalizes the classical one-inclusion graph due to Haussler, Littlestone, and Warmuth (1994). Finally, as a byproduct, we identify a dimension characterizing qualitatively and quantitatively what classes of predictors $\mathcal{H}$ are robustly learnable. This resolves an open problem due to Montasser et al. (2019), and closes a (potentially) infinite gap between the established upper and lower bounds on the sample complexity of adversarially robust learning.
Random orthogonal additive filters: a solution to the vanishing/exploding gradient of deep neural networks
Oct 03, 2022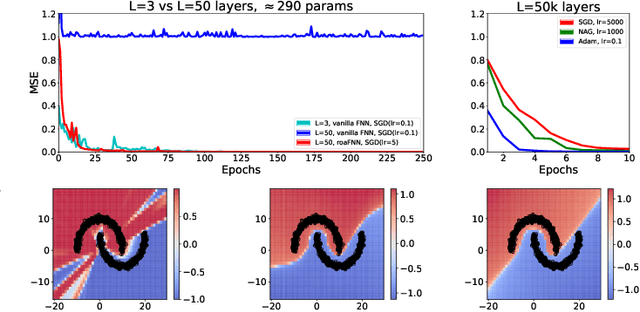
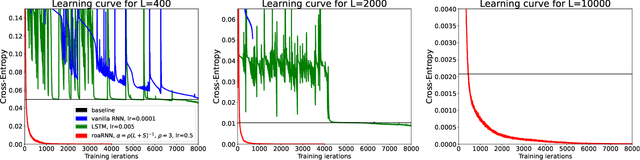
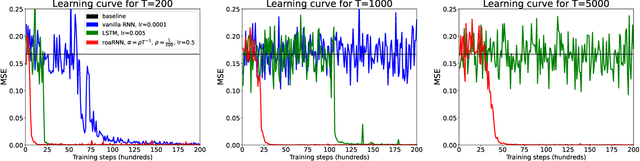

Since the recognition in the early nineties of the vanishing/exploding (V/E) gradient issue plaguing the training of neural networks (NNs), significant efforts have been exerted to overcome this obstacle. However, a clear solution to the V/E issue remained elusive so far. In this manuscript a new architecture of NN is proposed, designed to mathematically prevent the V/E issue to occur. The pursuit of approximate dynamical isometry, i.e. parameter configurations where the singular values of the input-output Jacobian are tightly distributed around 1, leads to the derivation of a NN's architecture that shares common traits with the popular Residual Network model. Instead of skipping connections between layers, the idea is to filter the previous activations orthogonally and add them to the nonlinear activations of the next layer, realising a convex combination between them. Remarkably, the impossibility for the gradient updates to either vanish or explode is demonstrated with analytical bounds that hold even in the infinite depth case. The effectiveness of this method is empirically proved by means of training via backpropagation an extremely deep multilayer perceptron of 50k layers, and an Elman NN to learn long-term dependencies in the input of 10k time steps in the past. Compared with other architectures specifically devised to deal with the V/E problem, e.g. LSTMs for recurrent NNs, the proposed model is way simpler yet more effective. Surprisingly, a single layer vanilla RNN can be enhanced to reach state of the art performance, while converging super fast; for instance on the psMNIST task, it is possible to get test accuracy of over 94% in the first epoch, and over 98% after just 10 epochs.
A Benchmark for Multi-Modal Lidar SLAM with Ground Truth in GNSS-Denied Environments
Oct 03, 2022


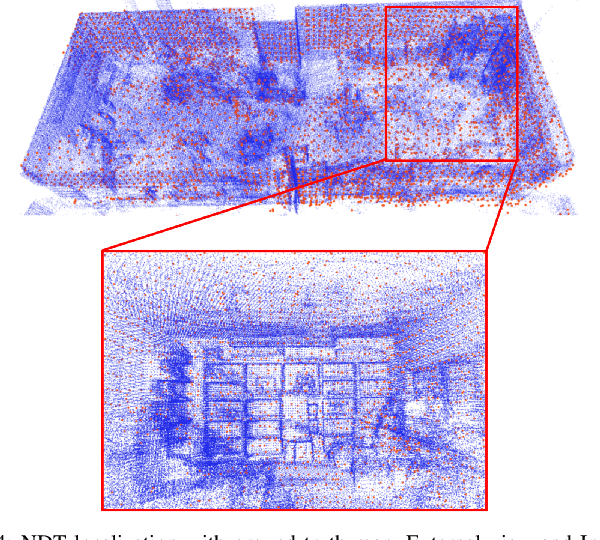
Lidar-based simultaneous localization and mapping (SLAM) approaches have obtained considerable success in autonomous robotic systems. This is in part owing to the high-accuracy of robust SLAM algorithms and the emergence of new and lower-cost lidar products. This study benchmarks current state-of-the-art lidar SLAM algorithms with a multi-modal lidar sensor setup showcasing diverse scanning modalities (spinning and solid-state) and sensing technologies, and lidar cameras, mounted on a mobile sensing and computing platform. We extend our previous multi-modal multi-lidar dataset with additional sequences and new sources of ground truth data. Specifically, we propose a new multi-modal multi-lidar SLAM-assisted and ICP-based sensor fusion method for generating ground truth maps. With these maps, we then match real-time pointcloud data using a natural distribution transform (NDT) method to obtain the ground truth with full 6 DOF pose estimation. This novel ground truth data leverages high-resolution spinning and solid-state lidars. We also include new open road sequences with GNSS-RTK data and additional indoor sequences with motion capture (MOCAP) ground truth, complementing the previous forest sequences with MOCAP data. We perform an analysis of the positioning accuracy achieved with ten different SLAM algorithm and lidar combinations. We also report the resource utilization in four different computational platforms and a total of five settings (Intel and Jetson ARM CPUs). Our experimental results show that current state-of-the-art lidar SLAM algorithms perform very differently for different types of sensors. More results, code, and the dataset can be found at: \href{https://github.com/TIERS/tiers-lidars-dataset-enhanced}{github.com/TIERS/tiers-lidars-dataset-enhanced.
Deep Speech Synthesis from Articulatory Representations
Sep 13, 2022

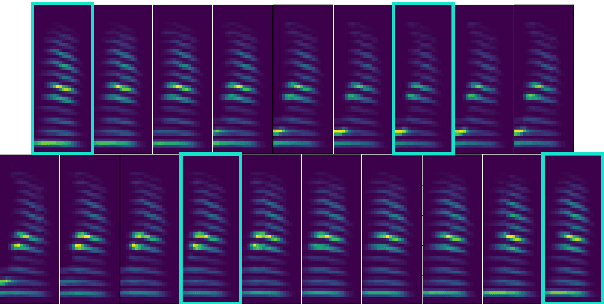
In the articulatory synthesis task, speech is synthesized from input features containing information about the physical behavior of the human vocal tract. This task provides a promising direction for speech synthesis research, as the articulatory space is compact, smooth, and interpretable. Current works have highlighted the potential for deep learning models to perform articulatory synthesis. However, it remains unclear whether these models can achieve the efficiency and fidelity of the human speech production system. To help bridge this gap, we propose a time-domain articulatory synthesis methodology and demonstrate its efficacy with both electromagnetic articulography (EMA) and synthetic articulatory feature inputs. Our model is computationally efficient and achieves a transcription word error rate (WER) of 18.5% for the EMA-to-speech task, yielding an improvement of 11.6% compared to prior work. Through interpolation experiments, we also highlight the generalizability and interpretability of our approach.
Siamese Network-based Lightweight Framework for Tomato Leaf Disease Recognition
Sep 18, 2022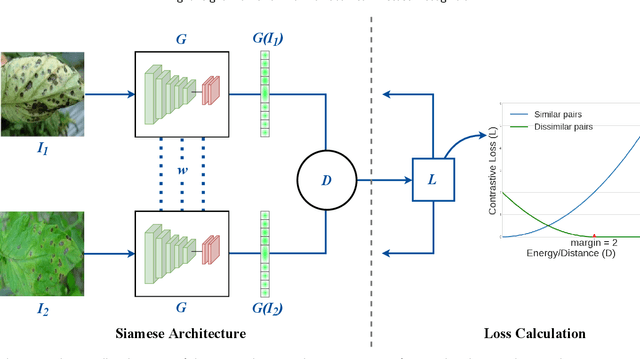
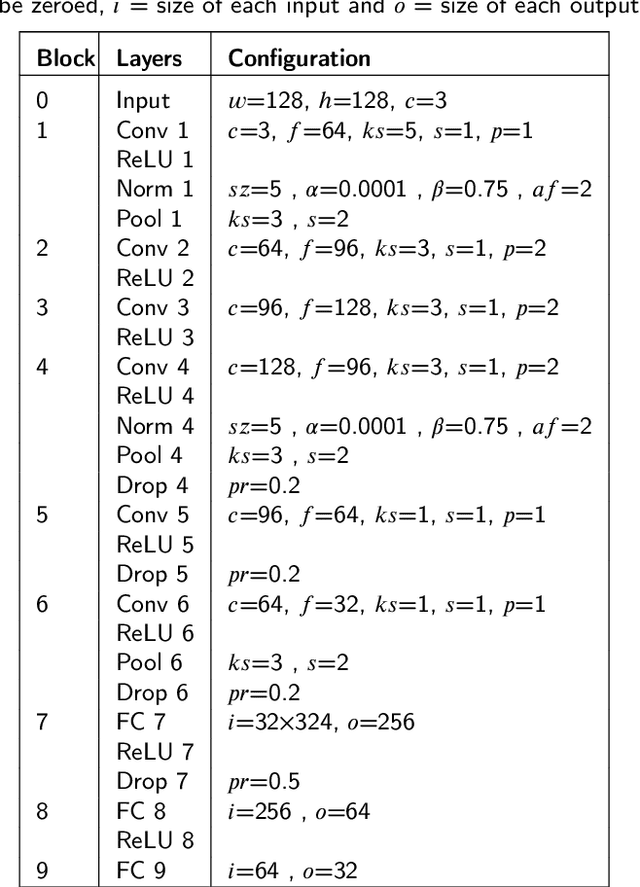

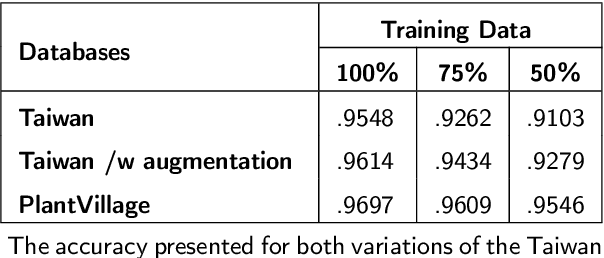
Automatic tomato disease recognition from leaf images is vital to avoid crop losses by applying control measures on time. Even though recent deep learning-based tomato disease recognition methods with classical training procedures showed promising recognition results, they demand large labelled data and involve expensive training. The traditional deep learning models proposed for tomato disease recognition also consume high memory and storage because of a high number of parameters. While lightweight networks overcome some of these issues to a certain extent, they continue to show low performance and struggle to handle imbalanced data. In this paper, a novel Siamese network-based lightweight framework is proposed for automatic tomato leaf disease recognition. This framework achieves the highest accuracy of 96.97% on the tomato subset obtained from the PlantVillage dataset and 95.48% on the Taiwan tomato leaf disease dataset. Experimental results further confirm that the proposed framework is effective with imbalanced and small data. The backbone deep network integrated with this framework is lightweight with approximately 2.9629 million trainable parameters, which is way lower than existing lightweight deep networks.
Learning Generalized Causal Structure in Time-series
Dec 06, 2021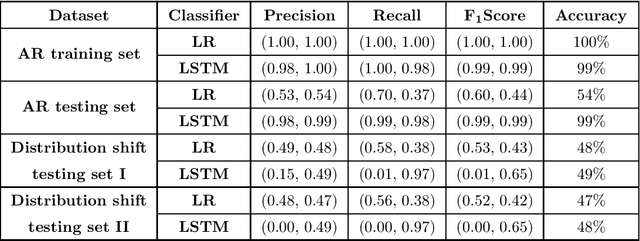
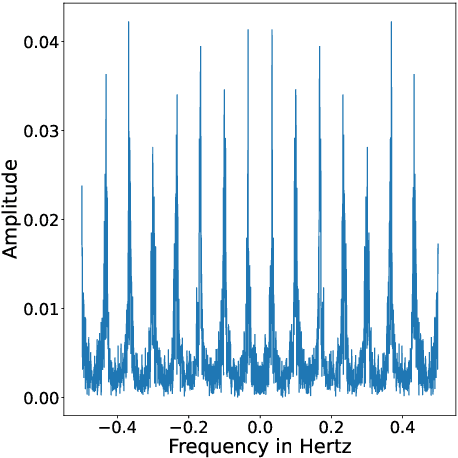
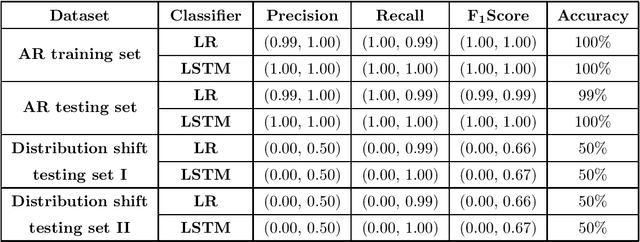
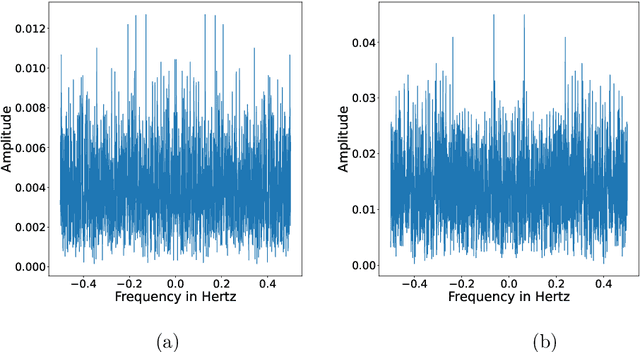
The science of causality explains/determines 'cause-effect' relationship between the entities of a system by providing mathematical tools for the purpose. In spite of all the success and widespread applications of machine-learning (ML) algorithms, these algorithms are based on statistical learning alone. Currently, they are nowhere close to 'human-like' intelligence as they fail to answer and learn based on the important "Why?" questions. Hence, researchers are attempting to integrate ML with the science of causality. Among the many causal learning issues encountered by ML, one is that these algorithms are dumb to the temporal order or structure in data. In this work we develop a machine learning pipeline based on a recently proposed 'neurochaos' feature learning technique (ChaosFEX feature extractor), that helps us to learn generalized causal-structure in given time-series data.
FIRE: A Failure-Adaptive Reinforcement Learning Framework for Edge Computing Migrations
Sep 28, 2022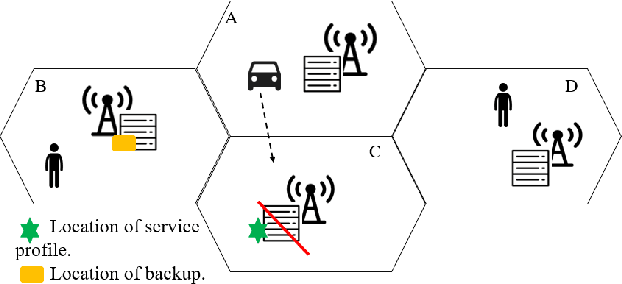
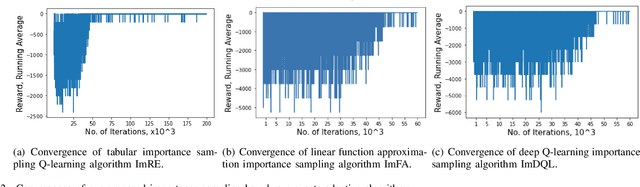
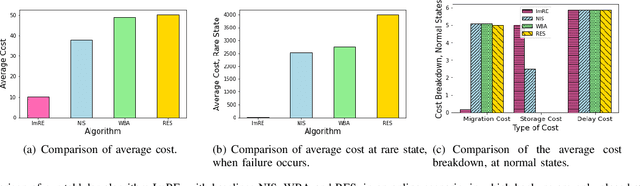
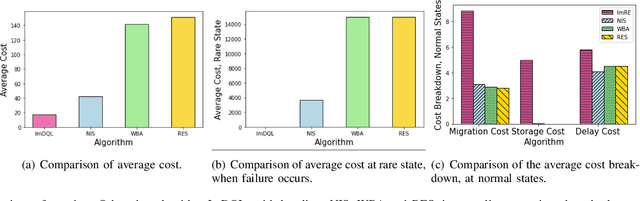
In edge computing, users' service profiles must be migrated in response to user mobility. Reinforcement learning (RL) frameworks have been proposed to do so. Nevertheless, these frameworks do not consider occasional server failures, which although rare, can prevent the smooth and safe functioning of edge computing users' latency sensitive applications such as autonomous driving and real-time obstacle detection, because users' computing jobs can no longer be completed. As these failures occur at a low probability, it is difficult for RL algorithms, which are inherently data-driven, to learn an optimal service migration solution for both the typical and rare event scenarios. Therefore, we introduce a rare events adaptive resilience framework FIRE, which integrates importance sampling into reinforcement learning to place backup services. We sample rare events at a rate proportional to their contribution to the value function, to learn an optimal policy. Our framework balances service migration trade-offs between delay and migration costs, with the costs of failure and the costs of backup placement and migration. We propose an importance sampling based Q-learning algorithm, and prove its boundedness and convergence to optimality. Following which we propose novel eligibility traces, linear function approximation and deep Q-learning versions of our algorithm to ensure it scales to real-world scenarios. We extend our framework to cater to users with different risk tolerances towards failure. Finally, we use trace driven experiments to show that our algorithm gives cost reductions in the event of failures.