 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Magnitude-image based data-consistent deep learning method for MRI super resolution
Sep 07, 2022
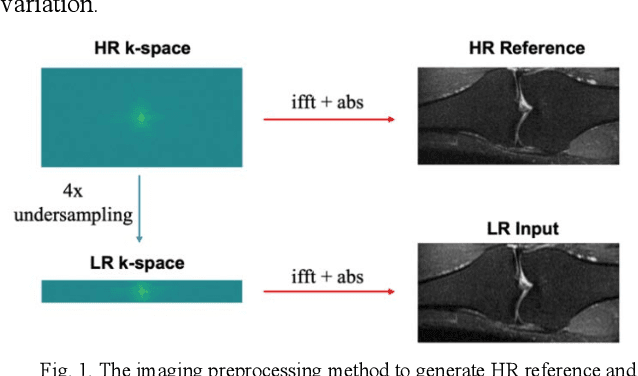
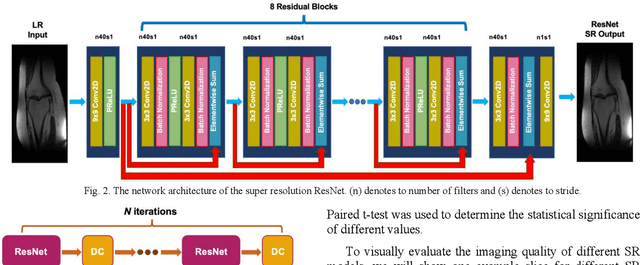
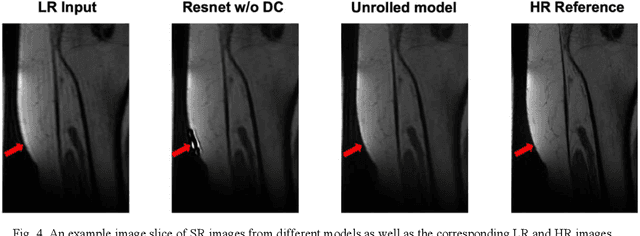
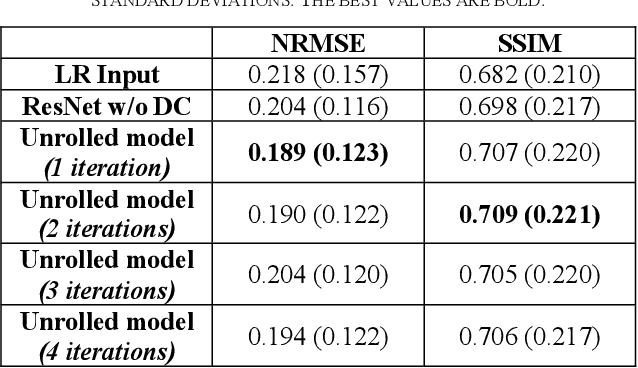
Magnetic Resonance Imaging (MRI) is important in clinic to produce high resolution images for diagnosis, but its acquisition time is long for high resolution images. Deep learning based MRI super resolution methods can reduce scan time without complicated sequence programming, but may create additional artifacts due to the discrepancy between training data and testing data. Data consistency layer can improve the deep learning results but needs raw k-space data. In this work, we propose a magnitude-image based data consistency deep learning MRI super resolution method to improve super resolution images' quality without raw k-space data. Our experiments show that the proposed method can improve NRMSE and SSIM of super resolution images compared to the same Convolutional Neural Network (CNN) block without data consistency module.
Real-time Human Detection Model for Edge Devices
Nov 20, 2021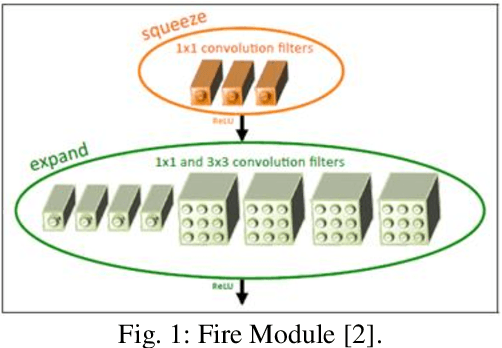
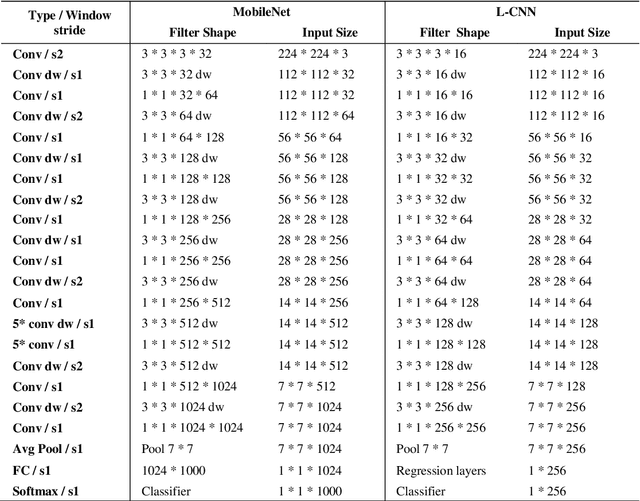
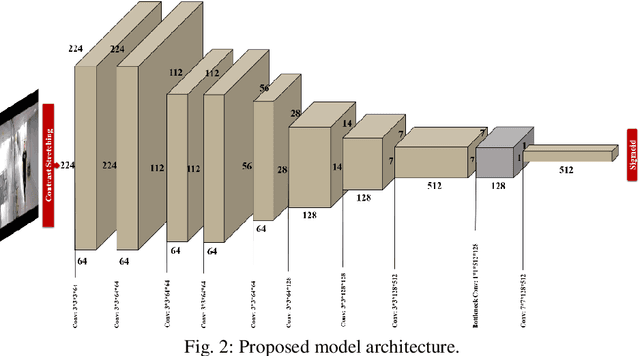
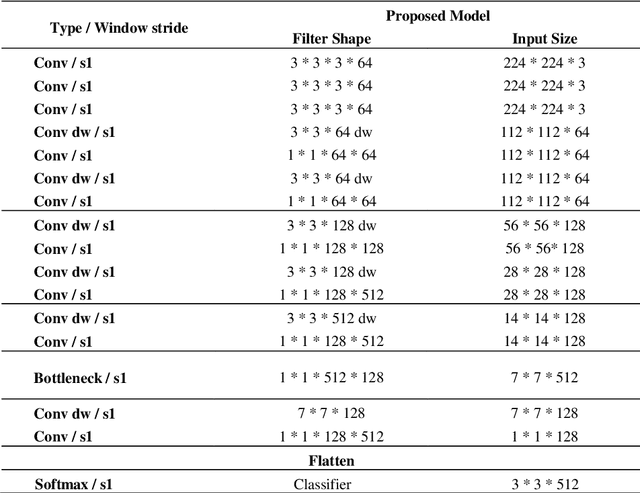
Building a small-sized fast surveillance system model to fit on limited resource devices is a challenging, yet an important task. Convolutional Neural Networks (CNNs) have replaced traditional feature extraction and machine learning models in detection and classification tasks. Various complex large CNN models are proposed that achieve significant improvement in the accuracy. Lightweight CNN models have been recently introduced for real-time tasks. This paper suggests a CNN-based lightweight model that can fit on a limited edge device such as Raspberry Pi. Our proposed model provides better performance time, smaller size and comparable accuracy with existing method. The model performance is evaluated on multiple benchmark datasets. It is also compared with existing models in terms of size, average processing time, and F-score. Other enhancements for future research are suggested.
Computing Forward Reachable Sets for Nonlinear Adaptive Multirotor Controllers
Sep 16, 2022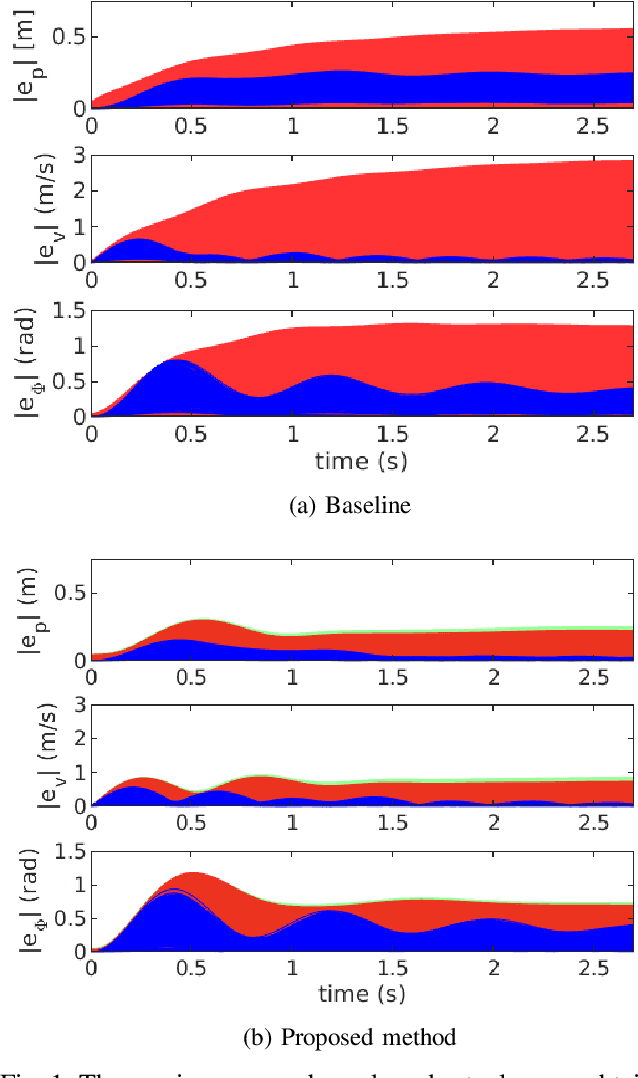
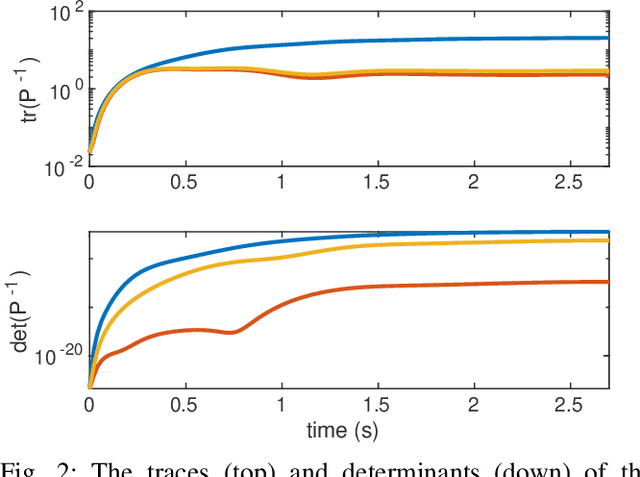
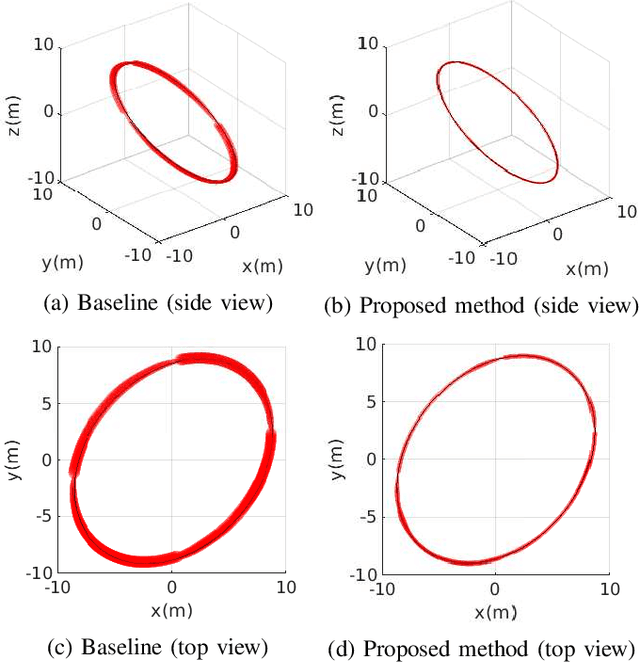
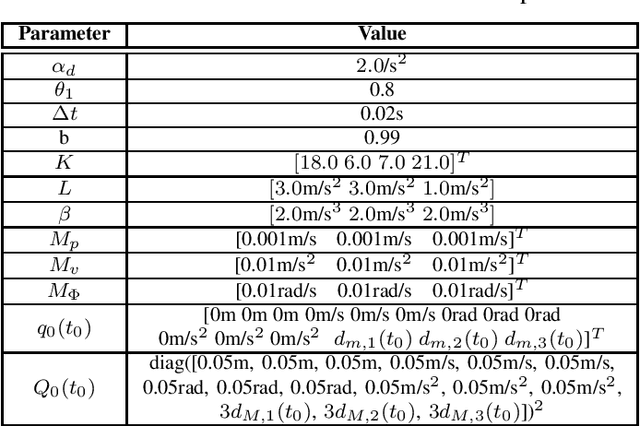
In multirotor systems, guaranteeing safety while considering unknown disturbances is essential for robust trajectory planning. Computing the forward reachable set (FRS), the set of all possible states with bounded disturbances, can be a viable solution to find robust and collision-free trajectories. However, in many cases, the FRS is not calculated in real time and is too conservative to be used in actual applications. In this paper, we mitigate these problems by applying a nonlinear disturbance observer (NDOB) and an adaptive controller to the multirotor system. We formulate the FRS of the closed-loop system combined with the adaptive controller in augmented state space by exploiting the Hamilton-Jacobi reachability analysis and then present the ellipsoidal approximation in a closed-form expression to compute the small FRS in real time. Moreover, tighter disturbance bounds in the prediction horizon are inferred from the NDOB so that a much smaller FRS can be generated. Numerical examples validate the computational efficiency and the smaller scale of the proposed FRS compared to the baseline.
Text-Free Learning of a Natural Language Interface for Pretrained Face Generators
Sep 08, 2022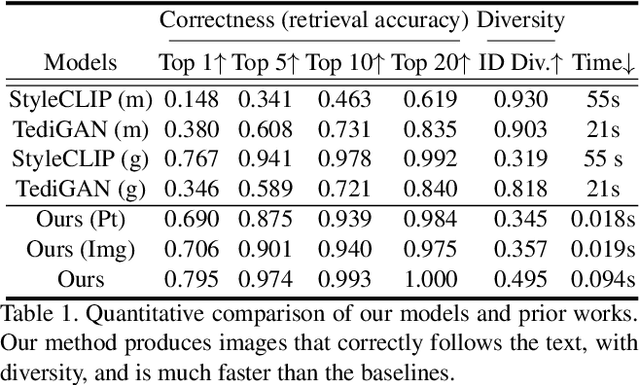
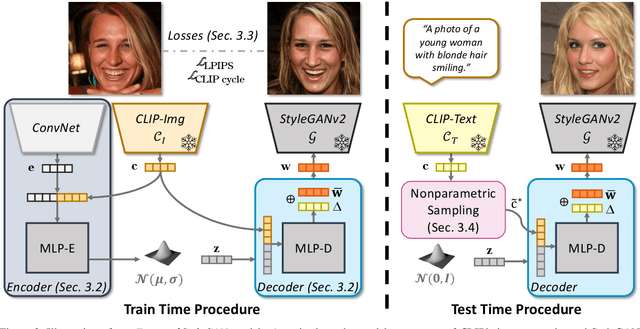
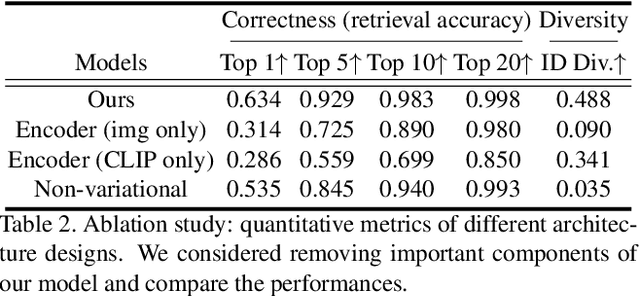

We propose Fast text2StyleGAN, a natural language interface that adapts pre-trained GANs for text-guided human face synthesis. Leveraging the recent advances in Contrastive Language-Image Pre-training (CLIP), no text data is required during training. Fast text2StyleGAN is formulated as a conditional variational autoencoder (CVAE) that provides extra control and diversity to the generated images at test time. Our model does not require re-training or fine-tuning of the GANs or CLIP when encountering new text prompts. In contrast to prior work, we do not rely on optimization at test time, making our method orders of magnitude faster than prior work. Empirically, on FFHQ dataset, our method offers faster and more accurate generation of images from natural language descriptions with varying levels of detail compared to prior work.
An Adaptive Threshold for the Canny Edge Detection with Actor-Critic Algorithm
Sep 19, 2022


Visual surveillance aims to perform robust foreground object detection regardless of the time and place. Object detection shows good results using only spatial information, but foreground object detection in visual surveillance requires proper temporal and spatial information processing. In deep learning-based foreground object detection algorithms, the detection ability is superior to classical background subtraction (BGS) algorithms in an environment similar to training. However, the performance is lower than that of the classical BGS algorithm in the environment different from training. This paper proposes a spatio-temporal fusion network (STFN) that could extract temporal and spatial information using a temporal network and a spatial network. We suggest a method using a semi-foreground map for stable training of the proposed STFN. The proposed algorithm shows excellent performance in an environment different from training, and we show it through experiments with various public datasets. Also, STFN can generate a compliant background image in a semi-supervised method, and it can operate in real-time on a desktop with GPU. The proposed method shows 11.28% and 18.33% higher FM than the latest deep learning method in the LASIESTA and SBI dataset, respectively.
Characterization of causal ancestral graphs for time series with latent confounders
Dec 15, 2021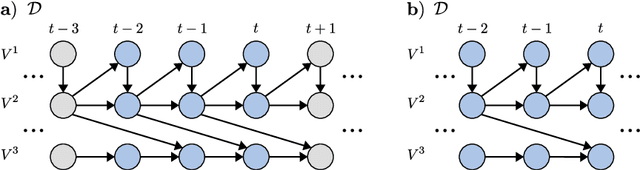
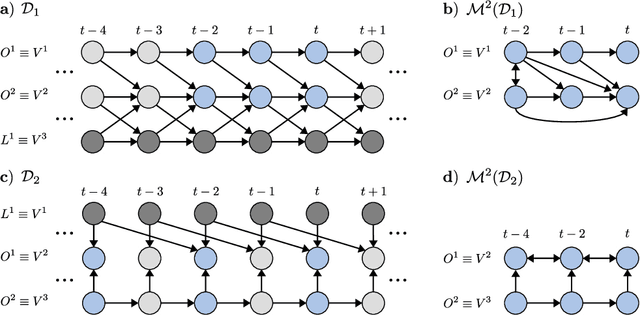


Generalizing directed maximal ancestral graphs, we introduce a class of graphical models for representing time lag specific causal relationships and independencies among finitely many regularly sampled and regularly subsampled time steps of multivariate time series with unobserved variables. We completely characterize these graphs and show that they entail constraints beyond those that have previously been considered in the literature. This allows for stronger causal inferences without having imposed additional assumptions. In generalization of directed partial ancestral graphs we further introduce a graphical representation of Markov equivalence classes of the novel type of graphs and show that these are more informative than what current state-of-the-art causal discovery algorithms learn. We also analyze the additional information gained by increasing the number of observed time steps.
Efficient On-Device Session-Based Recommendation
Sep 28, 2022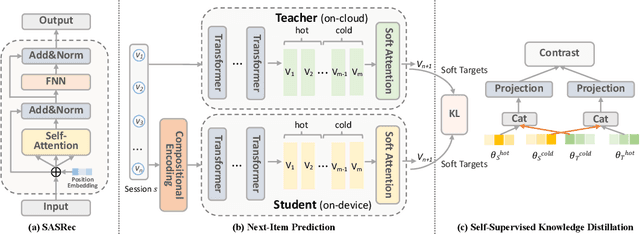
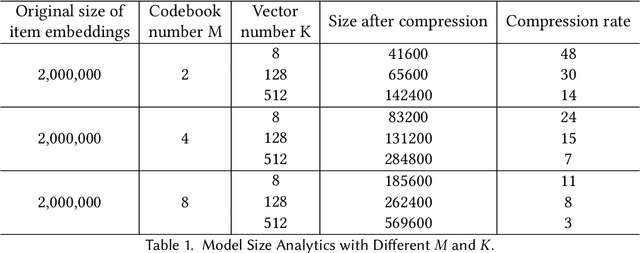
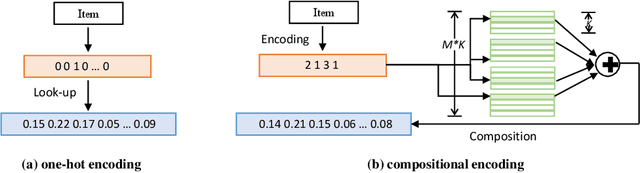

On-device session-based recommendation systems have been achieving increasing attention on account of the low energy/resource consumption and privacy protection while providing promising recommendation performance. To fit the powerful neural session-based recommendation models in resource-constrained mobile devices, tensor-train decomposition and its variants have been widely applied to reduce memory footprint by decomposing the embedding table into smaller tensors, showing great potential in compressing recommendation models. However, these model compression techniques significantly increase the local inference time due to the complex process of generating index lists and a series of tensor multiplications to form item embeddings, and the resultant on-device recommender fails to provide real-time response and recommendation. To improve the online recommendation efficiency, we propose to learn compositional encoding-based compact item representations. Specifically, each item is represented by a compositional code that consists of several codewords, and we learn embedding vectors to represent each codeword instead of each item. Then the composition of the codeword embedding vectors from different embedding matrices (i.e., codebooks) forms the item embedding. Since the size of codebooks can be extremely small, the recommender model is thus able to fit in resource-constrained devices and meanwhile can save the codebooks for fast local inference.Besides, to prevent the loss of model capacity caused by compression, we propose a bidirectional self-supervised knowledge distillation framework. Extensive experimental results on two benchmark datasets demonstrate that compared with existing methods, the proposed on-device recommender not only achieves an 8x inference speedup with a large compression ratio but also shows superior recommendation performance.
Evaluating Agent Interactions Through Episodic Knowledge Graphs
Sep 26, 2022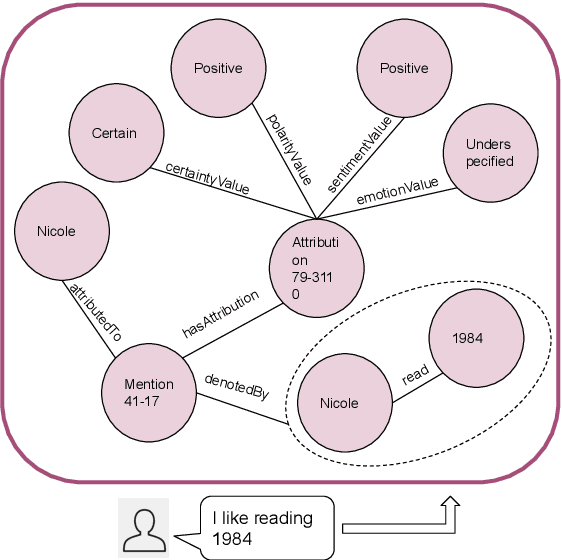
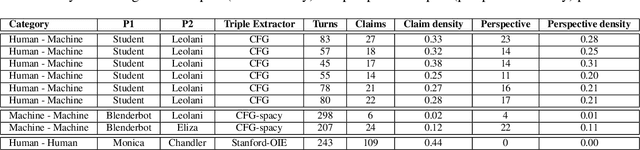
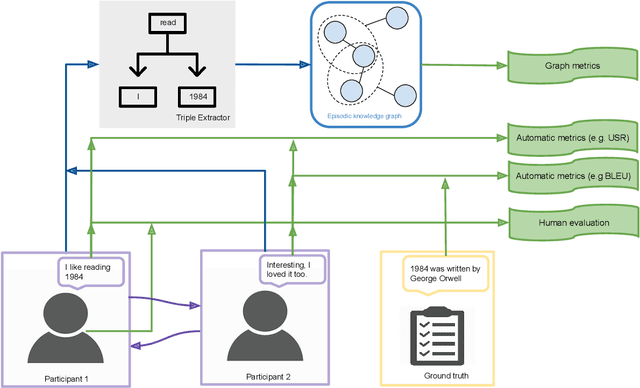
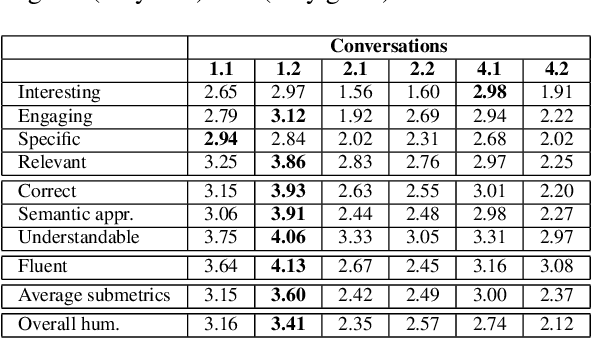
We present a new method based on episodic Knowledge Graphs (eKGs) for evaluating (multimodal) conversational agents in open domains. This graph is generated by interpreting raw signals during conversation and is able to capture the accumulation of knowledge over time. We apply structural and semantic analysis of the resulting graphs and translate the properties into qualitative measures. We compare these measures with existing automatic and manual evaluation metrics commonly used for conversational agents. Our results show that our Knowledge-Graph-based evaluation provides more qualitative insights into interaction and the agent's behavior.
DEPTS: Deep Expansion Learning for Periodic Time Series Forecasting
Mar 15, 2022
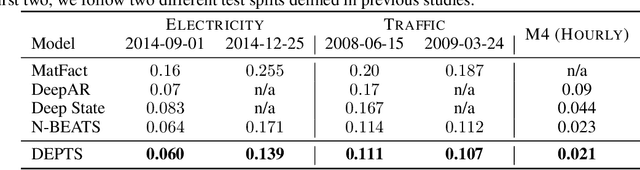
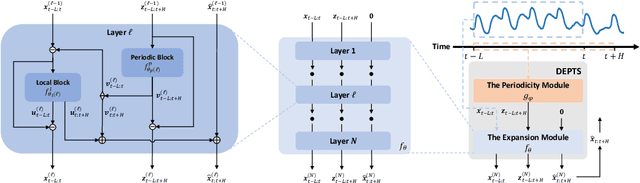
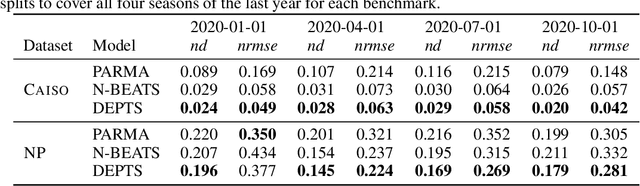
Periodic time series (PTS) forecasting plays a crucial role in a variety of industries to foster critical tasks, such as early warning, pre-planning, resource scheduling, etc. However, the complicated dependencies of the PTS signal on its inherent periodicity as well as the sophisticated composition of various periods hinder the performance of PTS forecasting. In this paper, we introduce a deep expansion learning framework, DEPTS, for PTS forecasting. DEPTS starts with a decoupled formulation by introducing the periodic state as a hidden variable, which stimulates us to make two dedicated modules to tackle the aforementioned two challenges. First, we develop an expansion module on top of residual learning to perform a layer-by-layer expansion of those complicated dependencies. Second, we introduce a periodicity module with a parameterized periodic function that holds sufficient capacity to capture diversified periods. Moreover, our two customized modules also have certain interpretable capabilities, such as attributing the forecasts to either local momenta or global periodicity and characterizing certain core periodic properties, e.g., amplitudes and frequencies. Extensive experiments on both synthetic data and real-world data demonstrate the effectiveness of DEPTS on handling PTS. In most cases, DEPTS achieves significant improvements over the best baseline. Specifically, the error reduction can even reach up to 20% for a few cases. Finally, all codes are publicly available.
Neural State-Space Modeling with Latent Causal-Effect Disentanglement
Sep 26, 2022
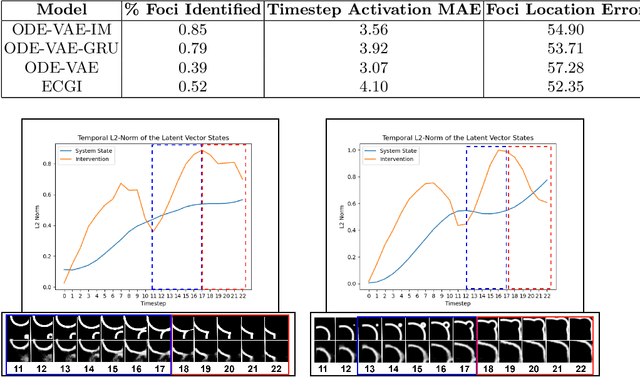


Despite substantial progress in deep learning approaches to time-series reconstruction, no existing methods are designed to uncover local activities with minute signal strength due to their negligible contribution to the optimization loss. Such local activities however can signify important abnormal events in physiological systems, such as an extra foci triggering an abnormal propagation of electrical waves in the heart. We discuss a novel technique for reconstructing such local activity that, while small in signal strength, is the cause of subsequent global activities that have larger signal strength. Our central innovation is to approach this by explicitly modeling and disentangling how the latent state of a system is influenced by potential hidden internal interventions. In a novel neural formulation of state-space models (SSMs), we first introduce causal-effect modeling of the latent dynamics via a system of interacting neural ODEs that separately describes 1) the continuous-time dynamics of the internal intervention, and 2) its effect on the trajectory of the system's native state. Because the intervention can not be directly observed but have to be disentangled from the observed subsequent effect, we integrate knowledge of the native intervention-free dynamics of a system, and infer the hidden intervention by assuming it to be responsible for differences observed between the actual and hypothetical intervention-free dynamics. We demonstrated a proof-of-concept of the presented framework on reconstructing ectopic foci disrupting the course of normal cardiac electrical propagation from remote observations.