 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adaptive Threshold for the Canny Edge Detection with Actor-Critic Algorithm
Sep 19, 2022
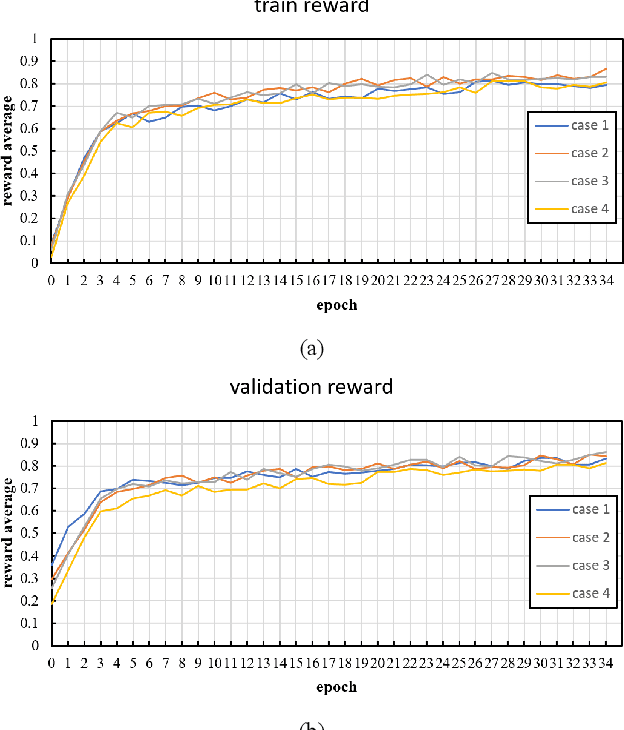


Visual surveillance aims to perform robust foreground object detection regardless of the time and place. Object detection shows good results using only spatial information, but foreground object detection in visual surveillance requires proper temporal and spatial information processing. In deep learning-based foreground object detection algorithms, the detection ability is superior to classical background subtraction (BGS) algorithms in an environment similar to training. However, the performance is lower than that of the classical BGS algorithm in the environment different from training. This paper proposes a spatio-temporal fusion network (STFN) that could extract temporal and spatial information using a temporal network and a spatial network. We suggest a method using a semi-foreground map for stable training of the proposed STFN. The proposed algorithm shows excellent performance in an environment different from training, and we show it through experiments with various public datasets. Also, STFN can generate a compliant background image in a semi-supervised method, and it can operate in real-time on a desktop with GPU. The proposed method shows 11.28% and 18.33% higher FM than the latest deep learning method in the LASIESTA and SBI dataset, respectively.
Spatio-temporal Data Augmentation for Visual Surveillance
Feb 15, 2021

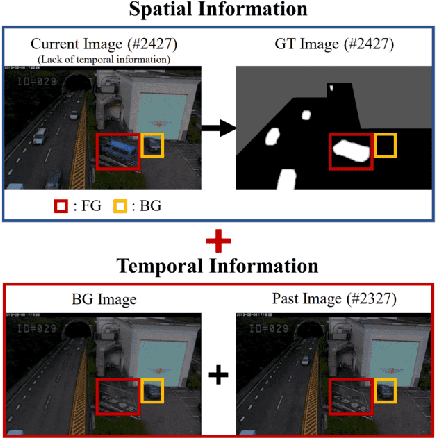
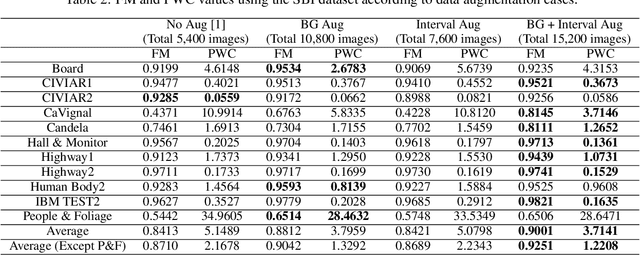
Visual surveillance aims to stably detect a foreground object using a continuous image acquired from a fixed camera. Recent deep learning methods based on supervised learning show superior performance compared to classical background subtraction algorithms. However, there is still a room for improvement in static foreground, dynamic background, hard shadow, illumination changes, camouflage, etc. In addition, most of the deep learning-based methods operates well on environments similar to training. If the testing environments are different from training ones, their performance degrades. As a result, additional training on those operating environments is required to ensure a good performance. Our previous work which uses spatio-temporal input data consisted of a number of past images, background images and current image showed promising results in different environments from training, although it uses a simple U-NET structure. In this paper, we propose a data augmentation technique suitable for visual surveillance for additional performance improvement using the same network used in our previous work. In deep learning, most data augmentation techniques deal with spatial-level data augmentation techniques for use in image classification and object detection. In this paper, we propose a new method of data augmentation in the spatio-temporal dimension suitable for our previous work. Two data augmentation methods of adjusting background model images and past images are proposed. Through this, it is shown that performance can be improved in difficult areas such as static foreground and ghost objects, compared to previous studies. Through quantitative and qualitative evaluation using SBI, LASIESTA, and our own dataset, we show that it gives superior performance compared to deep learning-based algorithms and background subtraction algorithms.