 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Vision-Based Lane Detection and Tracking under Different Challenging Environmental Conditions
Oct 19, 2022
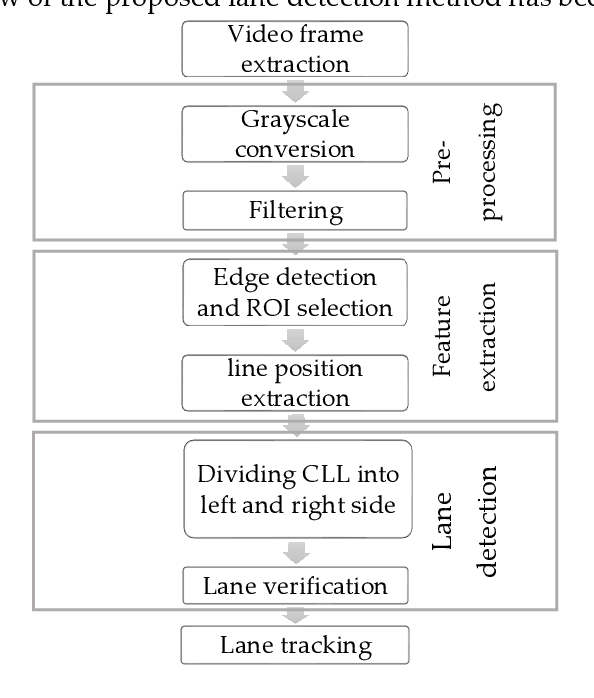
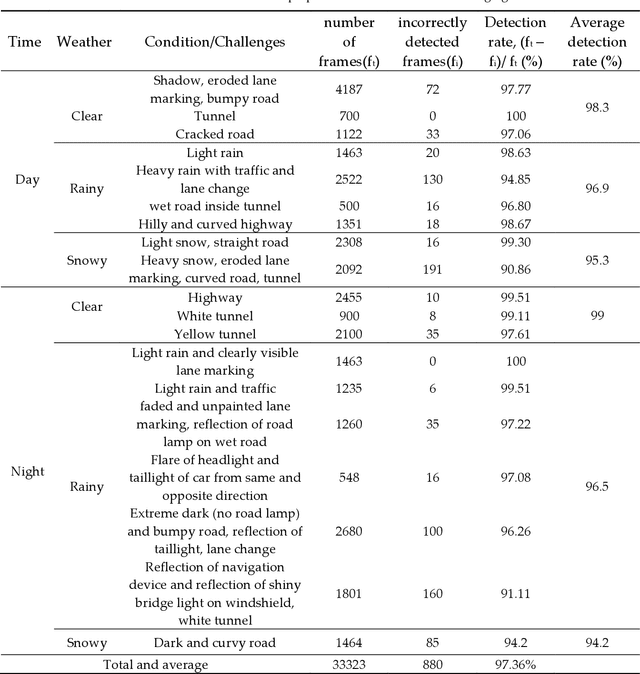
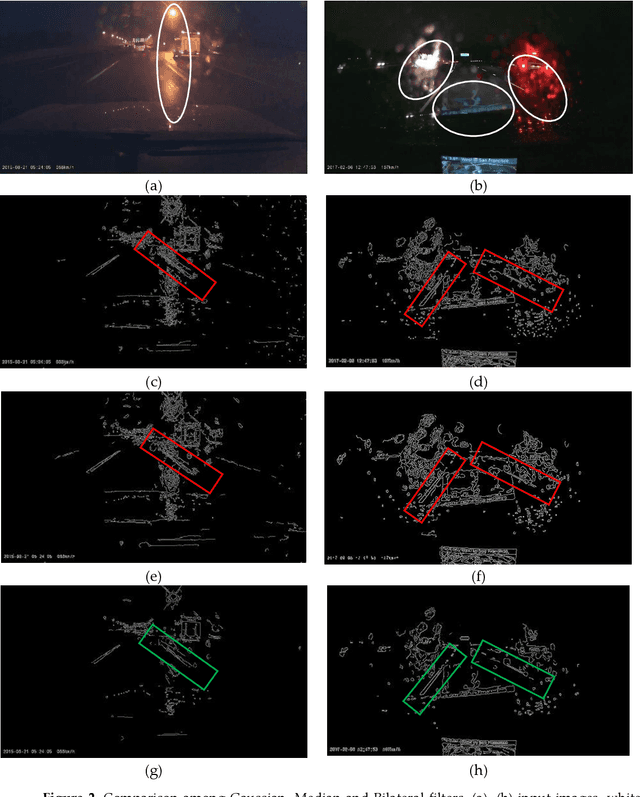
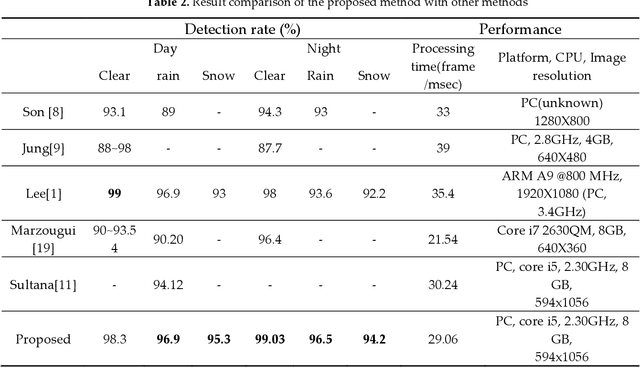
Driving is very challenging when the visibility of a road lane marking is low, obscured or often invisible due to abrupt environmental change which may lead to severe vehicle clash. A large volume of research has been done on lane marking detection. Most of the lane detection methods suffer from four types of major problems: (i) abrupt illumination change due to change in time (day, night), weather, road, etc.; (ii) lane markings get obscured partially or fully when they are colored, eroded or occluded; (iii) blurred view created by adverse weather like rain or snow; and (iv) incorrect lane detection due to presence of other lookalike lines e.g. guardrails, pavement marking, road divider, vehicle lines, the shadow of trees, etc. In this paper, we proposed a robust lane detection and tracking method to detect lane marking considering the abovementioned challenging conditions. In this method, we introduced three key technologies. First, the bilateral filter is applied to smooth and preserve the edges and we introduced an optimized intensity threshold range (OITR) to improve the performance of the canny operator which detects the edges of low intensity (colored, eroded, or blurred) lane markings. Second, we proposed a robust lane verification technique, the angle and length-based geometric constraint (ALGC) algorithm followed by Hough Transform, to verify the characteristics of lane marking and to prevent incorrect lane detection. Finally, a novel lane tracking technique, the horizontally adjustable lane repositioning range (HALRR) algorithm is proposed, which can keep track of the lane position. To evaluate the performance of the proposed method we used the DSDLDE dataset with 1080x1920 resolutions at 24 frames/sec. Experimental results show that the average detection rate is 97.36%, and the average detection time is 29.06msec per frame, which outperformed the state-of-the-art method.
A self-paced BCI system with low latency for motor imagery onset detection based on time series prediction paradigm
Apr 12, 2022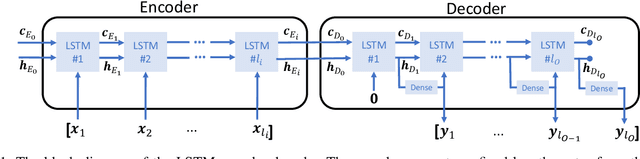
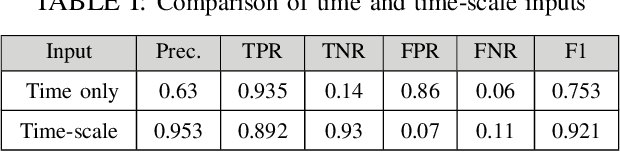
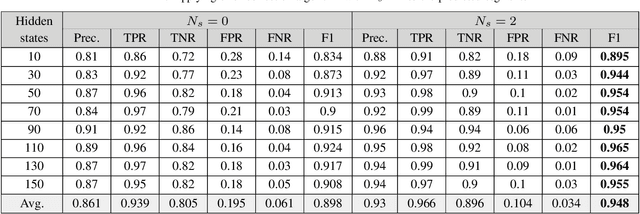
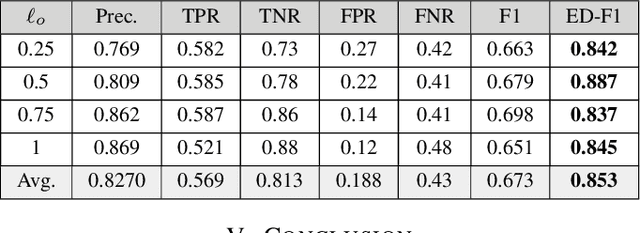
In a self-paced motor-imagery brain-computer interface (MI-BCI), the onsets of the MI commands presented in a continuous electroencephalogram (EEG) signal are unknown. To detect these onsets, most self-paced approaches apply a window function on the continuous EEG signal and split it into long segments for further analysis. As a result, the system has a high latency. To reduce the system latency, we propose an algorithm based on the time series prediction concept and use the data of the previously received time samples to predict the upcoming time samples. Our predictor is an encoder-decoder (ED) network built with long short-term memory (LSTM) units. The onsets of the MI commands are detected shortly by comparing the incoming signal with the predicted signal. The proposed method is validated on dataset IVc from BCI competition III. The simulation results show that the proposed algorithm improves the average F1-score achieved by the winner of the competition by 26.7% for latencies shorter than one second.
Just ClozE! A Fast and Simple Method for Evaluating the Factual Consistency in Abstractive Summarization
Oct 06, 2022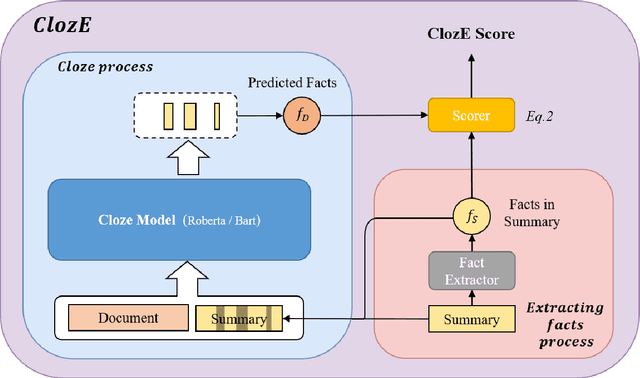
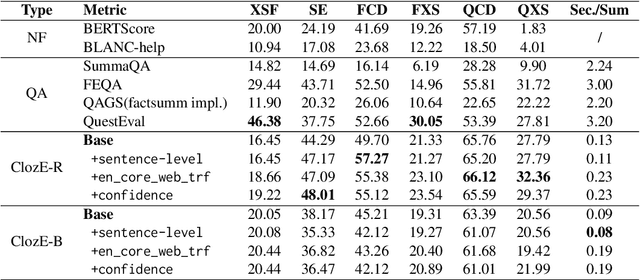
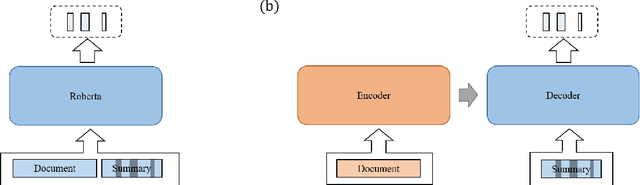

The issue of factual consistency in abstractive summarization has attracted much attention in recent years, and the evaluation of factual consistency between summary and document has become an important and urgent task. Most of the current evaluation metrics are adopted from the question answering (QA). However, the application of QA-based metrics is extremely time-consuming in practice, causing the iteration cycle of abstractive summarization research to be severely prolonged. In this paper, we propose a new method called ClozE to evaluate factual consistency by cloze model, instantiated based on masked language model(MLM), with strong interpretability and substantially higher speed. We demonstrate that ClozE can reduce the evaluation time by nearly 96$\%$ relative to QA-based metrics while retaining their interpretability and performance through experiments on six human-annotated datasets and a meta-evaluation benchmark GO FIGURE \citep{gabriel2020go}. We also implement experiments to further demonstrate more characteristics of ClozE in terms of performance and speed. In addition, we conduct an experimental analysis of the limitations of ClozE, which suggests future research directions. The code and models for ClozE will be released upon the paper acceptance.
HetSyn: Speeding Up Local SGD with Heterogeneous Synchronization
Oct 06, 2022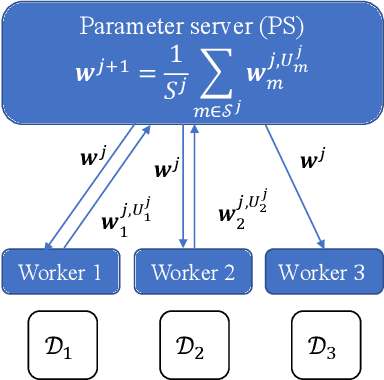
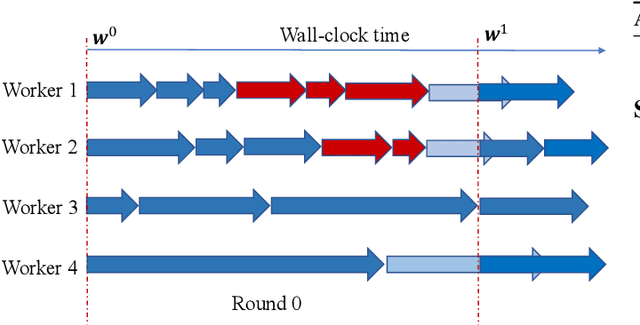
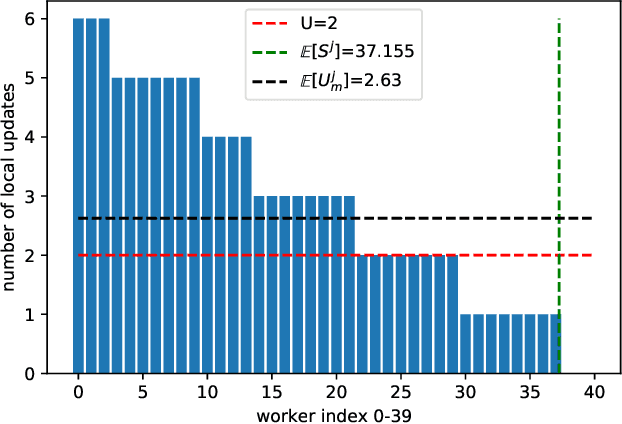
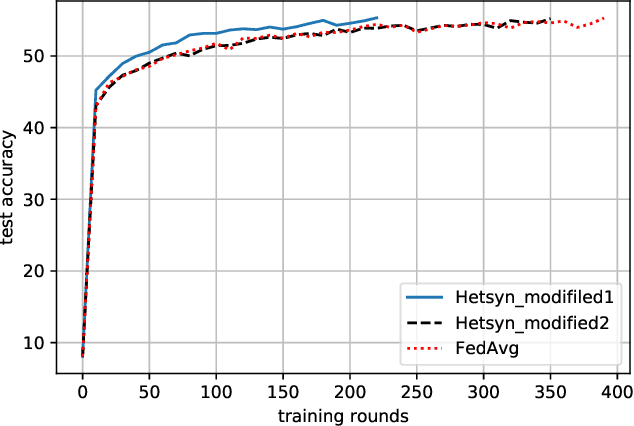
Synchronous local stochastic gradient descent (local SGD) suffers from some workers being idle and random delays due to slow and straggling workers, as it waits for the workers to complete the same amount of local updates. In this paper, to mitigate stragglers and improve communication efficiency, a novel local SGD strategy, named HetSyn, is developed. The key point is to keep all the workers computing continually at each synchronization round, and make full use of any effective (completed) local update of each worker regardless of stragglers. An analysis of the average wall-clock time, average number of local updates and average number of uploading workers per round is provided to gauge the performance of HetSyn. The convergence of HetSyn is also rigorously established even when the objective function is nonconvex. Experimental results show the superiority of the proposed HetSyn against state-of-the-art schemes through utilization of additional effective local updates at each worker, and the influence of system parameters is studied. By allowing heterogeneous synchronization with different numbers of local updates across workers, HetSyn provides substantial improvements both in time and communication efficiency.
Geodesic Graph Neural Network for Efficient Graph Representation Learning
Oct 06, 2022
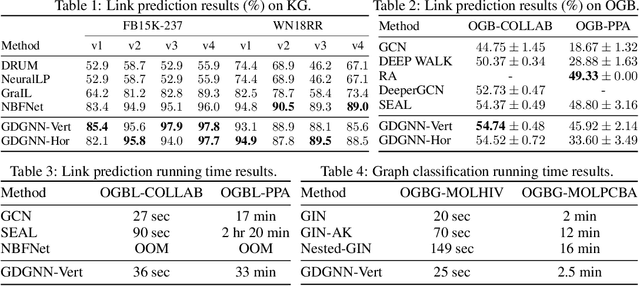
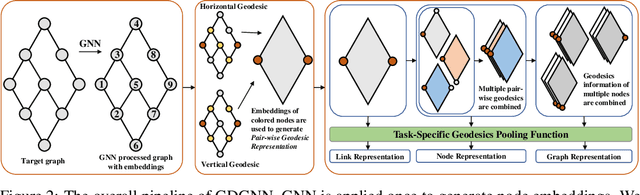
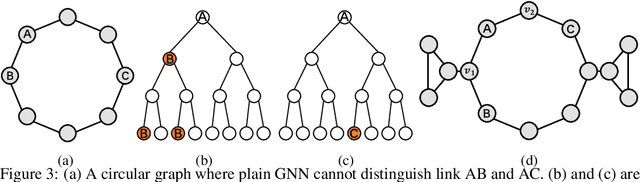
Recently, Graph Neural Networks (GNNs) have been applied to graph learning tasks and achieved state-of-the-art results. However, many competitive methods employ preprocessing on the target nodes, such as subgraph extraction and customized labeling, to capture some information that is hard to be learned by normal GNNs. Such operations are time-consuming and do not scale to large graphs. In this paper, we propose an efficient GNN framework called Geodesic GNN (GDGNN). It injects conditional relationships between nodes into the model without labeling. Specifically, we view the shortest paths between two nodes as the spatial graph context of the neighborhood around them. The GNN embeddings of nodes on the shortest paths are used to generate geodesic representations. Conditioned on the geodesic representations, GDGNN is able to generate node, link, and graph representations that carry much richer structural information than plain GNNs. We theoretically prove that GDGNN is more powerful than plain GNNs, and present experimental results to show that GDGNN achieves highly competitive performance with state-of-the-art GNN models on link prediction and graph classification tasks while taking significantly less time.
Lyapunov Function Consistent Adaptive Network Signal Control with Back Pressure and Reinforcement Learning
Oct 06, 2022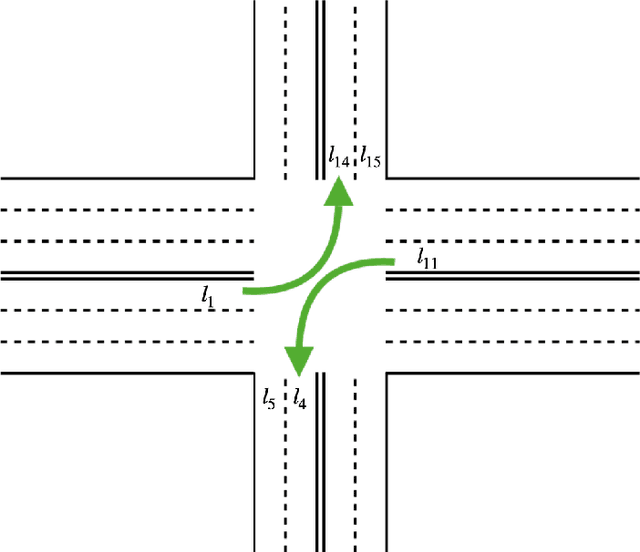
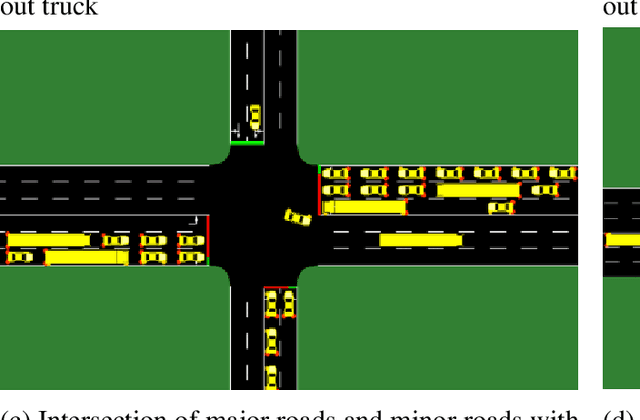

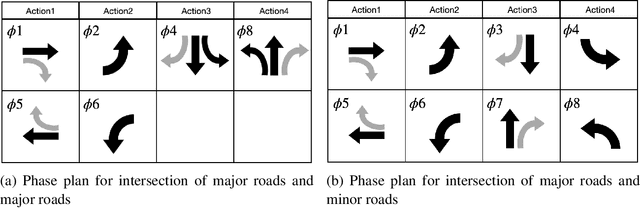
This research studies the network traffic signal control problem. It uses the Lyapunov control function to derive the back pressure method, which is equal to differential queue lengths weighted by intersection lane flows. Lyapunov control theory is a platform that unifies several current theories for intersection signal control. We further use the theorem to derive the flow-based and other pressure-based signal control algorithms. For example, the Dynamic, Optimal, Real-time Algorithm for Signals (DORAS) algorithm may be derived by defining the Lyapunov function as the sum of queue length. The study then utilizes the back pressure as a reward in the reinforcement learning (RL) based network signal control, whose agent is trained with double Deep Q-Network (Double-DQN). The proposed algorithm is compared with several traditional and RL-based methods under passenger traffic flow and mixed flow with freight traffic, respectively. The numerical tests are conducted on a single corridor and on a local grid network under three traffic demand scenarios of low, medium, and heavy traffic, respectively. The numerical simulation demonstrates that the proposed algorithm outperforms the others in terms of the average vehicle waiting time on the network.
Semi-Supervised Domain Adaptation for Cross-Survey Galaxy Morphology Classification and Anomaly Detection
Nov 04, 2022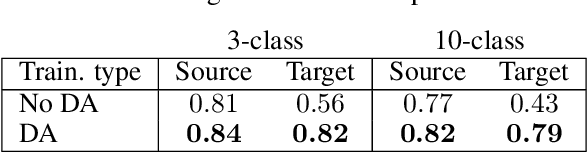

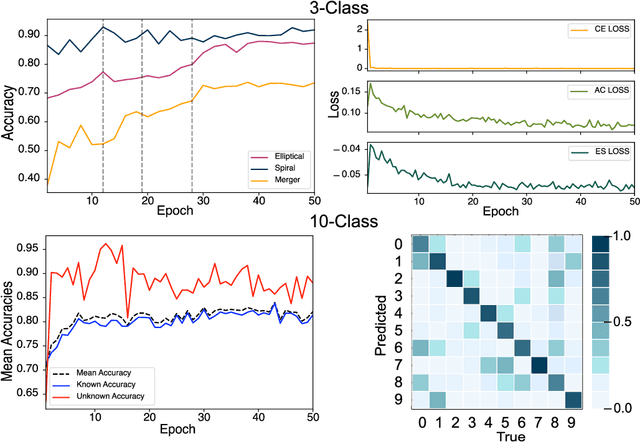
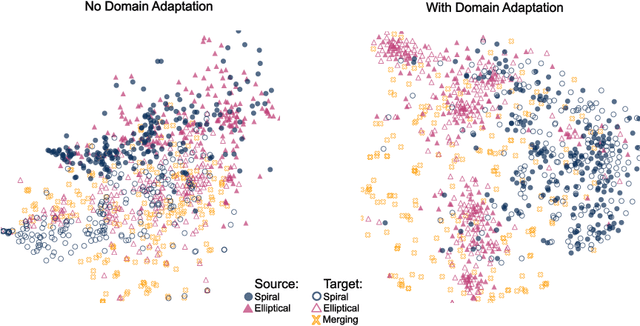
In the era of big astronomical surveys, our ability to leverage artificial intelligence algorithms simultaneously for multiple datasets will open new avenues for scientific discovery. Unfortunately, simply training a deep neural network on images from one data domain often leads to very poor performance on any other dataset. Here we develop a Universal Domain Adaptation method DeepAstroUDA, capable of performing semi-supervised domain alignment that can be applied to datasets with different types of class overlap. Extra classes can be present in any of the two datasets, and the method can even be used in the presence of unknown classes. For the first time, we demonstrate the successful use of domain adaptation on two very different observational datasets (from SDSS and DECaLS). We show that our method is capable of bridging the gap between two astronomical surveys, and also performs well for anomaly detection and clustering of unknown data in the unlabeled dataset. We apply our model to two examples of galaxy morphology classification tasks with anomaly detection: 1) classifying spiral and elliptical galaxies with detection of merging galaxies (three classes including one unknown anomaly class); 2) a more granular problem where the classes describe more detailed morphological properties of galaxies, with the detection of gravitational lenses (ten classes including one unknown anomaly class).
SPEAKER VGG CCT: Cross-corpus Speech Emotion Recognition with Speaker Embedding and Vision Transformers
Nov 04, 2022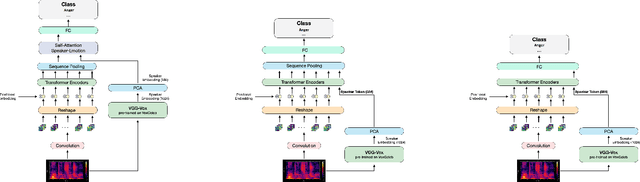

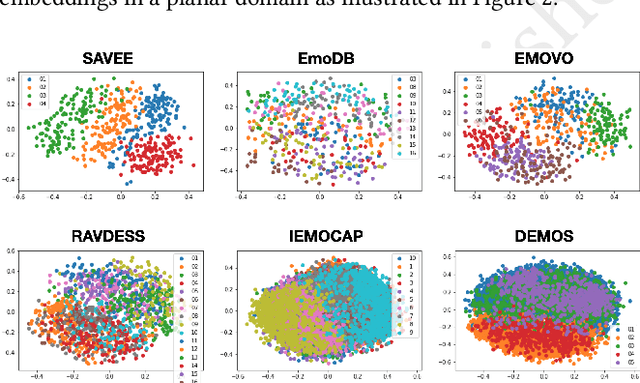
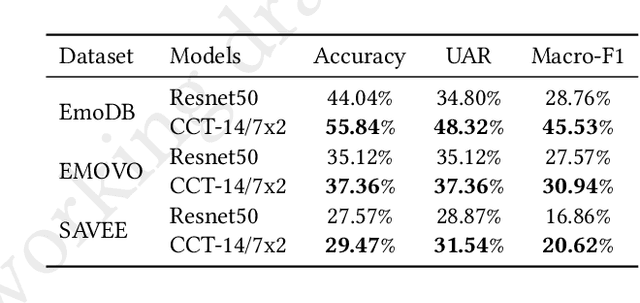
In recent years, Speech Emotion Recognition (SER) has been investigated mainly transforming the speech signal into spectrograms that are then classified using Convolutional Neural Networks pretrained on generic images and fine tuned with spectrograms. In this paper, we start from the general idea above and develop a new learning solution for SER, which is based on Compact Convolutional Transformers (CCTs) combined with a speaker embedding. With CCTs, the learning power of Vision Transformers (ViT) is combined with a diminished need for large volume of data as made possible by the convolution. This is important in SER, where large corpora of data are usually not available. The speaker embedding allows the network to extract an identity representation of the speaker, which is then integrated by means of a self-attention mechanism with the features that the CCT extracts from the spectrogram. Overall, the solution is capable of operating in real-time showing promising results in a cross-corpus scenario, where training and test datasets are kept separate. Experiments have been performed on several benchmarks in a cross-corpus setting as rarely used in the literature, with results that are comparable or superior to those obtained with state-of-the-art network architectures. Our code is available at https://github.com/JabuMlDev/Speaker-VGG-CCT.
Towards federated multivariate statistical process control (FedMSPC)
Nov 04, 2022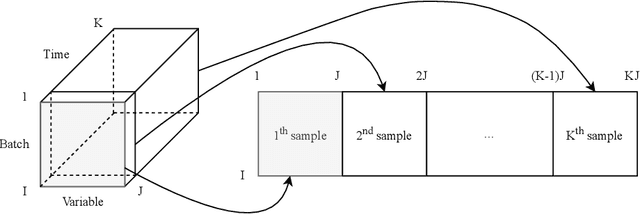
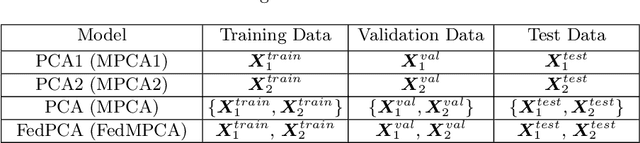
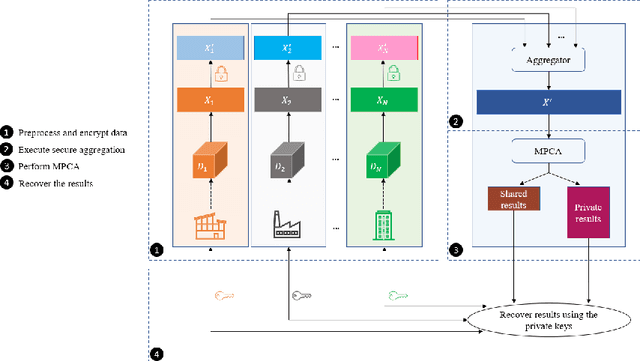

The ongoing transition from a linear (produce-use-dispose) to a circular economy poses significant challenges to current state-of-the-art information and communication technologies. In particular, the derivation of integrated, high-level views on material, process, and product streams from (real-time) data produced along value chains is challenging for several reasons. Most importantly, sufficiently rich data is often available yet not shared across company borders because of privacy concerns which make it impossible to build integrated process models that capture the interrelations between input materials, process parameters, and key performance indicators along value chains. In the current contribution, we propose a privacy-preserving, federated multivariate statistical process control (FedMSPC) framework based on Federated Principal Component Analysis (PCA) and Secure Multiparty Computation to foster the incentive for closer collaboration of stakeholders along value chains. We tested our approach on two industrial benchmark data sets - SECOM and ST-AWFD. Our empirical results demonstrate the superior fault detection capability of the proposed approach compared to standard, single-party (multiway) PCA. Furthermore, we showcase the possibility of our framework to provide privacy-preserving fault diagnosis to each data holder in the value chain to underpin the benefits of secure data sharing and federated process modeling.
Integrated Parameter-Efficient Tuning for General-Purpose Audio Models
Nov 04, 2022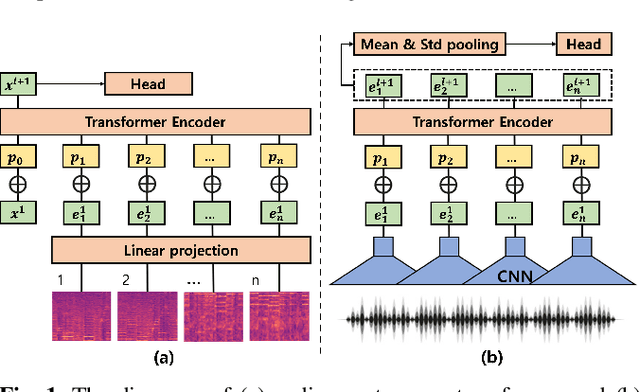
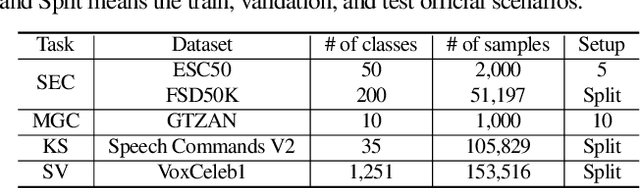
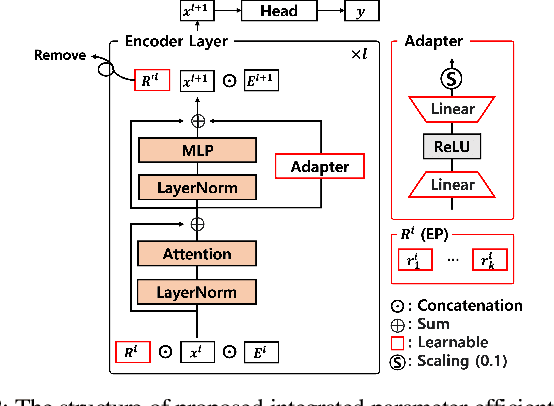
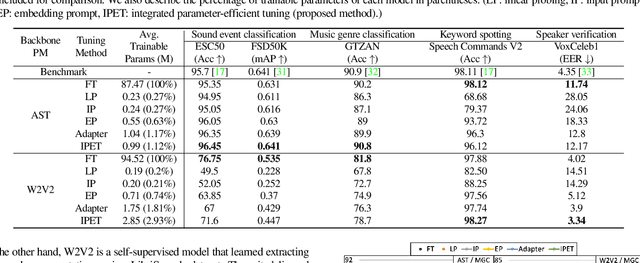
The advent of hyper-scale and general-purpose pre-trained models is shifting the paradigm of building task-specific models for target tasks. In the field of audio research, task-agnostic pre-trained models with high transferability and adaptability have achieved state-of-the-art performances through fine-tuning for downstream tasks. Nevertheless, re-training all the parameters of these massive models entails an enormous amount of time and cost, along with a huge carbon footprint. To overcome these limitations, the present study explores and applies efficient transfer learning methods in the audio domain. We also propose an integrated parameter-efficient tuning (IPET) framework by aggregating the embedding prompt (a prompt-based learning approach), and the adapter (an effective transfer learning method). We demonstrate the efficacy of the proposed framework using two backbone pre-trained audio models with different characteristics: the audio spectrogram transformer and wav2vec 2.0. The proposed IPET framework exhibits remarkable performance compared to fine-tuning method with fewer trainable parameters in four downstream tasks: sound event classification, music genre classification, keyword spotting, and speaker verification. Furthermore, the authors identify and analyze the shortcomings of the IPET framework, providing lessons and research directions for parameter efficient tuning in the audio domain.