 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDead Weights, Live Signals: Feedforward Graphs of Frozen Language Models
Apr 09, 2026We present a feedforward graph architecture in which heterogeneous frozen large language models serve as computational nodes, communicating through a shared continuous latent space via learned linear projections. Building on recent work demonstrating geometric compatibility between independently trained LLM latent spaces~\cite{armstrong2026thinking}, we extend this finding from static two-model steering to end-to-end trainable multi-node graphs, where projection matrices are optimized jointly via backpropagation through residual stream injection hooks. Three small frozen models (Llama-3.2-1B, Qwen2.5-1.5B, Gemma-2-2B) encode the input into a shared latent space whose aggregate signal is injected into two larger frozen models (Phi-3-mini, Mistral-7B), whose representations feed a lightweight cross-attention output node. With only 17.6M trainable parameters against approximately 12B frozen, the architecture achieves 87.3\% on ARC-Challenge, 82.8\% on OpenBookQA, and 67.2\% on MMLU, outperforming the best single constituent model by 11.4, 6.2, and 1.2 percentage points respectively, and outperforming parameter-matched learned classifiers on frozen single models by 9.1, 5.2, and 6.7 points. Gradient flow through multiple frozen model boundaries is empirically verified to be tractable, and the output node develops selective routing behavior across layer-2 nodes without explicit supervision.
Thinking in Different Spaces: Domain-Specific Latent Geometry Survives Cross-Architecture Translation
Mar 20, 2026We investigate whether independently trained language models converge to geometrically compatible latent representations, and whether this compatibility can be exploited to correct model behavior at inference time without any weight updates. We learn a linear projection matrix that maps activation vectors from a large teacher model into the coordinate system of a smaller student model, then intervene on the student's residual stream during generation by substituting its internal state with the translated teacher representation. Across a fully crossed experimental matrix of 20 heterogeneous teacher-student pairings spanning mixture-of-experts, dense, code-specialized, and synthetically trained architectures, the Ridge projection consistently achieves R^2 = 0.50 on verbal reasoning and R^2 = 0.40 on mathematical reasoning, collapsing to R^2 = -0.22 under permutation control and R^2 = 0.01 under L_1 regularization. Behavioral correction rates range from 14.0% to 50.0% on TruthfulQA (mean 25.2%) and from 8.5% to 43.3% on GSM8K arithmetic reasoning (mean 25.5%), demonstrating that the method generalizes across fundamentally different reasoning domains. We report a near-zero correlation between geometric alignment quality and behavioral correction rate (r = -0.07), revealing a dissociation between representation space fidelity and output space impact. Intervention strength is architecture-specific: student models exhibit characteristic sensitivity profiles that invert across domains, with the most steerable verbal student becoming the least steerable mathematical student. Finally, a double dissociation experiment conducted across all 20 model pairings confirms without exception that projection matrices collapse catastrophically when transferred across reasoning domains (mean R^2 = -3.83 in both transfer directions), establishing domain-specific subspace geometry as a universal property of LMs.
Say Anything but This: When Tokenizer Betrays Reasoning in LLMs
Jan 21, 2026Large language models (LLMs) reason over discrete token ID sequences, yet modern subword tokenizers routinely produce non-unique encodings: multiple token ID sequences can detokenize to identical surface strings. This representational mismatch creates an unmeasured fragility wherein reasoning processes can fail. LLMs may treat two internal representations as distinct "words" even when they are semantically identical at the text level. In this work, we show that tokenization can betray LLM reasoning through one-to-many token ID mappings. We introduce a tokenization-consistency probe that requires models to replace designated target words in context while leaving all other content unchanged. The task is intentionally simple at the surface level, enabling us to attribute failures to tokenizer-detokenizer artifacts rather than to knowledge gaps or parameter limitations. Through analysis of over 11000 replacement trials across state-of-the-art open-source LLMs, we find a non-trivial rate of outputs exhibit phantom edits: cases where models operate under the illusion of correct reasoning, a phenomenon arising from tokenizer-induced representational defects. We further analyze these cases and provide a taxonomy of eight systematic tokenizer artifacts, including whitespace-boundary shifts and intra-word resegmentation. These findings indicate that part of apparent reasoning deficiency originates in the tokenizer layer, motivating tokenizer-level remedies before incurring the cost of training ever-larger models on ever-larger corpora.
ESPERANTO: Evaluating Synthesized Phrases to Enhance Robustness in AI Detection for Text Origination
Sep 22, 2024



While large language models (LLMs) exhibit significant utility across various domains, they simultaneously are susceptible to exploitation for unethical purposes, including academic misconduct and dissemination of misinformation. Consequently, AI-generated text detection systems have emerged as a countermeasure. However, these detection mechanisms demonstrate vulnerability to evasion techniques and lack robustness against textual manipulations. This paper introduces back-translation as a novel technique for evading detection, underscoring the need to enhance the robustness of current detection systems. The proposed method involves translating AI-generated text through multiple languages before back-translating to English. We present a model that combines these back-translated texts to produce a manipulated version of the original AI-generated text. Our findings demonstrate that the manipulated text retains the original semantics while significantly reducing the true positive rate (TPR) of existing detection methods. We evaluate this technique on nine AI detectors, including six open-source and three proprietary systems, revealing their susceptibility to back-translation manipulation. In response to the identified shortcomings of existing AI text detectors, we present a countermeasure to improve the robustness against this form of manipulation. Our results indicate that the TPR of the proposed method declines by only 1.85% after back-translation manipulation. Furthermore, we build a large dataset of 720k texts using eight different LLMs. Our dataset contains both human-authored and LLM-generated texts in various domains and writing styles to assess the performance of our method and existing detectors. This dataset is publicly shared for the benefit of the research community.
Seeing Through AI's Lens: Enhancing Human Skepticism Towards LLM-Generated Fake News
Jun 20, 2024



LLMs offer valuable capabilities, yet they can be utilized by malicious users to disseminate deceptive information and generate fake news. The growing prevalence of LLMs poses difficulties in crafting detection approaches that remain effective across various text domains. Additionally, the absence of precautionary measures for AI-generated news on online social platforms is concerning. Therefore, there is an urgent need to improve people's ability to differentiate between news articles written by humans and those produced by LLMs. By providing cues in human-written and LLM-generated news, we can help individuals increase their skepticism towards fake LLM-generated news. This paper aims to elucidate simple markers that help individuals distinguish between articles penned by humans and those created by LLMs. To achieve this, we initially collected a dataset comprising 39k news articles authored by humans or generated by four distinct LLMs with varying degrees of fake. We then devise a metric named Entropy-Shift Authorship Signature (ESAS) based on the information theory and entropy principles. The proposed ESAS ranks terms or entities, like POS tagging, within news articles based on their relevance in discerning article authorship. We demonstrate the effectiveness of our metric by showing the high accuracy attained by a basic method, i.e., TF-IDF combined with logistic regression classifier, using a small set of terms with the highest ESAS score. Consequently, we introduce and scrutinize these top ESAS-ranked terms to aid individuals in strengthening their skepticism towards LLM-generated fake news.
CNN Autoencoder Resizer: A Power-Efficient LoS/NLoS Detector in MIMO-enabled UAV Networks
May 26, 2024



Optimizing the design, performance, and resource efficiency of wireless networks (WNs) necessitates the ability to discern Line of Sight (LoS) and Non-Line of Sight (NLoS) scenarios across diverse applications and environments. Unmanned Aerial Vehicles (UAVs) exhibit significant potential in this regard due to their rapid mobility, aerial capabilities, and payload characteristics. Particularly, UAVs can serve as vital non-terrestrial base stations (NTBS) in the event of terrestrial base station (TBS) failures or downtime. In this paper, we propose CNN autoencoder resizer (CAR) as a framework that improves the accuracy of LoS/NLoS detection without demanding extra power consumption. Our proposed method increases the mean accuracy of detecting LoS/NLoS signals from 66% to 86%, while maintaining consistent power consumption levels. In addition, the resolution provided by CAR shows that it can be employed as a preprocessing tool in other methods to enhance the quality of signals.
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Oct 15, 2023In the realm of machine learning (ML) systems featuring client-host connections, the enhancement of privacy security can be effectively achieved through federated learning (FL) as a secure distributed ML methodology. FL effectively integrates cloud infrastructure to transfer ML models onto edge servers using blockchain technology. Through this mechanism, it guarantees the streamlined processing and data storage requirements of both centralized and decentralized systems, with an emphasis on scalability, privacy considerations, and cost-effective communication. In current FL implementations, data owners locally train their models, and subsequently upload the outcomes in the form of weights, gradients, and parameters to the cloud for overall model aggregation. This innovation obviates the necessity of engaging Internet of Things (IoT) clients and participants to communicate raw and potentially confidential data directly with a cloud center. This not only reduces the costs associated with communication networks but also enhances the protection of private data. This survey conducts an analysis and comparison of recent FL applications, aiming to assess their efficiency, accuracy, and privacy protection. However, in light of the complex and evolving nature of FL, it becomes evident that additional research is imperative to address lingering knowledge gaps and effectively confront the forthcoming challenges in this field. In this study, we categorize recent literature into the following clusters: privacy protection, resource allocation, case study analysis, and applications. Furthermore, at the end of each section, we tabulate the open areas and future directions presented in the referenced literature, affording researchers and scholars an insightful view of the evolution of the field.
The Looming Threat of Fake and LLM-generated LinkedIn Profiles: Challenges and Opportunities for Detection and Prevention
Jul 21, 2023



In this paper, we present a novel method for detecting fake and Large Language Model (LLM)-generated profiles in the LinkedIn Online Social Network immediately upon registration and before establishing connections. Early fake profile identification is crucial to maintaining the platform's integrity since it prevents imposters from acquiring the private and sensitive information of legitimate users and from gaining an opportunity to increase their credibility for future phishing and scamming activities. This work uses textual information provided in LinkedIn profiles and introduces the Section and Subsection Tag Embedding (SSTE) method to enhance the discriminative characteristics of these data for distinguishing between legitimate profiles and those created by imposters manually or by using an LLM. Additionally, the dearth of a large publicly available LinkedIn dataset motivated us to collect 3600 LinkedIn profiles for our research. We will release our dataset publicly for research purposes. This is, to the best of our knowledge, the first large publicly available LinkedIn dataset for fake LinkedIn account detection. Within our paradigm, we assess static and contextualized word embeddings, including GloVe, Flair, BERT, and RoBERTa. We show that the suggested method can distinguish between legitimate and fake profiles with an accuracy of about 95% across all word embeddings. In addition, we show that SSTE has a promising accuracy for identifying LLM-generated profiles, despite the fact that no LLM-generated profiles were employed during the training phase, and can achieve an accuracy of approximately 90% when only 20 LLM-generated profiles are added to the training set. It is a significant finding since the proliferation of several LLMs in the near future makes it extremely challenging to design a single system that can identify profiles created with various LLMs.
Unsupervised Motor Imagery Saliency Detection Based on Self-Attention Mechanism
Apr 19, 2022
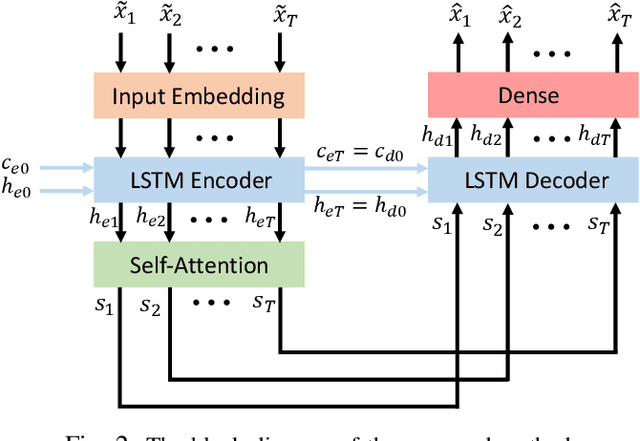
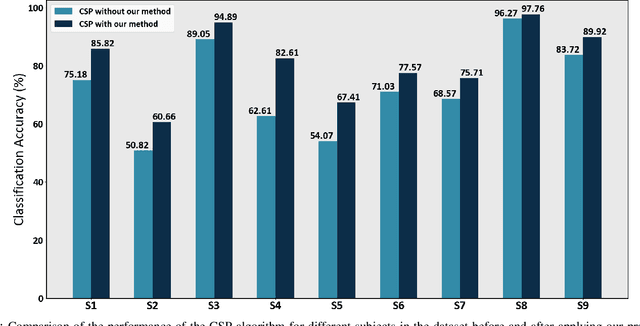
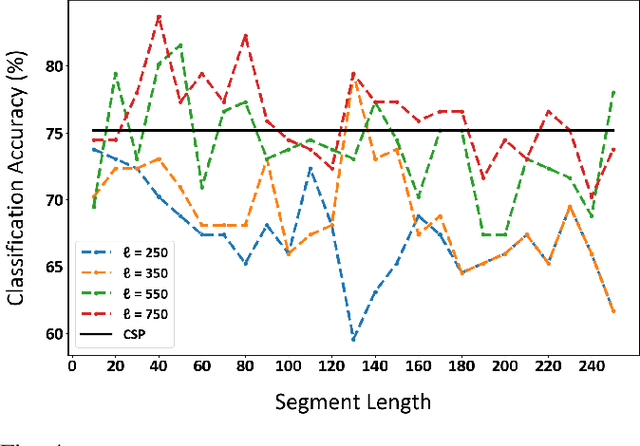
Detecting the salient parts of motor-imagery electroencephalogram (MI-EEG) signals can enhance the performance of the brain-computer interface (BCI) system and reduce the computational burden required for processing lengthy MI-EEG signals. In this paper, we propose an unsupervised method based on the self-attention mechanism to detect the salient intervals of MI-EEG signals automatically. Our suggested method can be used as a preprocessing step within any BCI algorithm to enhance its performance. The effectiveness of the suggested method is evaluated on the most widely used BCI algorithm, the common spatial pattern (CSP) algorithm, using dataset 2a from BCI competition IV. The results indicate that the proposed method can effectively prune MI-EEG signals and significantly enhance the performance of the CSP algorithm in terms of classification accuracy.
A Subject-Independent Brain-Computer Interface Framework Based on Supervised Autoencoder
Apr 19, 2022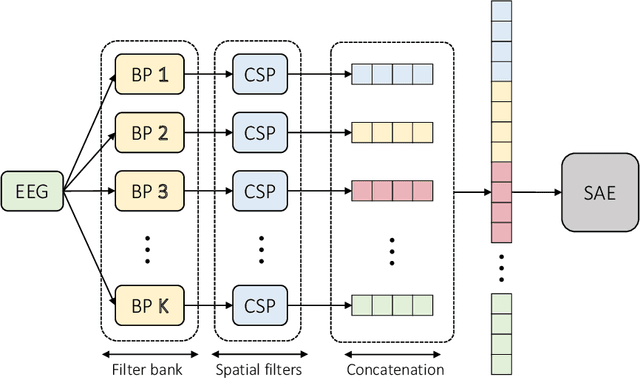
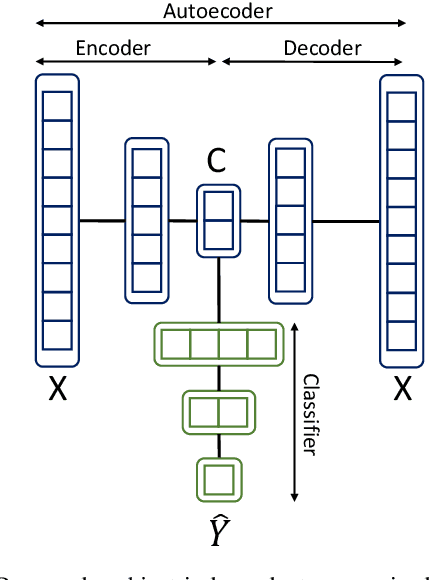
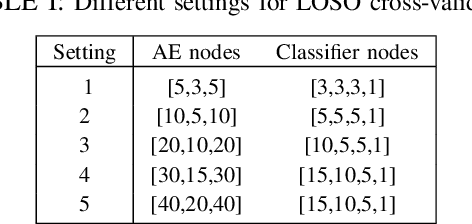
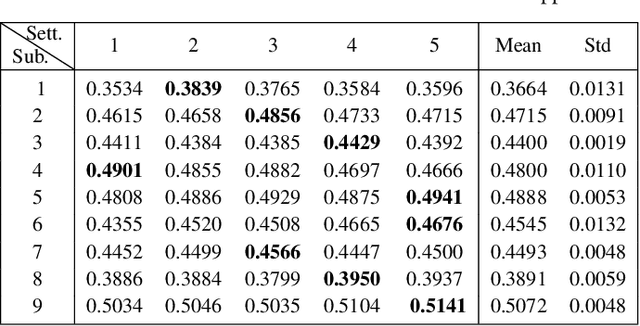
A calibration procedure is required in motor imagery-based brain-computer interface (MI-BCI) to tune the system for new users. This procedure is time-consuming and prevents na\"ive users from using the system immediately. Developing a subject-independent MI-BCI system to reduce the calibration phase is still challenging due to the subject-dependent characteristics of the MI signals. Many algorithms based on machine learning and deep learning have been developed to extract high-level features from the MI signals to improve the subject-to-subject generalization of a BCI system. However, these methods are based on supervised learning and extract features useful for discriminating various MI signals. Hence, these approaches cannot find the common underlying patterns in the MI signals and their generalization level is limited. This paper proposes a subject-independent MI-BCI based on a supervised autoencoder (SAE) to circumvent the calibration phase. The suggested framework is validated on dataset 2a from BCI competition IV. The simulation results show that our SISAE model outperforms the conventional and widely used BCI algorithms, common spatial and filter bank common spatial patterns, in terms of the mean Kappa value, in eight out of nine subjects.