 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Driving Telescopes: Autonomous Scheduling of Astronomical Observation Campaigns with Offline Reinforcement Learning
Nov 29, 2023



Modern astronomical experiments are designed to achieve multiple scientific goals, from studies of galaxy evolution to cosmic acceleration. These goals require data of many different classes of night-sky objects, each of which has a particular set of observational needs. These observational needs are typically in strong competition with one another. This poses a challenging multi-objective optimization problem that remains unsolved. The effectiveness of Reinforcement Learning (RL) as a valuable paradigm for training autonomous systems has been well-demonstrated, and it may provide the basis for self-driving telescopes capable of optimizing the scheduling for astronomy campaigns. Simulated datasets containing examples of interactions between a telescope and a discrete set of sky locations on the celestial sphere can be used to train an RL model to sequentially gather data from these several locations to maximize a cumulative reward as a measure of the quality of the data gathered. We use simulated data to test and compare multiple implementations of a Deep Q-Network (DQN) for the task of optimizing the schedule of observations from the Stone Edge Observatory (SEO). We combine multiple improvements on the DQN and adjustments to the dataset, showing that DQNs can achieve an average reward of 87%+-6% of the maximum achievable reward in each state on the test set. This is the first comparison of offline RL algorithms for a particular astronomical challenge and the first open-source framework for performing such a comparison and assessment task.
Domain Adaptive Graph Neural Networks for Constraining Cosmological Parameters Across Multiple Data Sets
Nov 02, 2023


Deep learning models have been shown to outperform methods that rely on summary statistics, like the power spectrum, in extracting information from complex cosmological data sets. However, due to differences in the subgrid physics implementation and numerical approximations across different simulation suites, models trained on data from one cosmological simulation show a drop in performance when tested on another. Similarly, models trained on any of the simulations would also likely experience a drop in performance when applied to observational data. Training on data from two different suites of the CAMELS hydrodynamic cosmological simulations, we examine the generalization capabilities of Domain Adaptive Graph Neural Networks (DA-GNNs). By utilizing GNNs, we capitalize on their capacity to capture structured scale-free cosmological information from galaxy distributions. Moreover, by including unsupervised domain adaptation via Maximum Mean Discrepancy (MMD), we enable our models to extract domain-invariant features. We demonstrate that DA-GNN achieves higher accuracy and robustness on cross-dataset tasks (up to $28\%$ better relative error and up to almost an order of magnitude better $\chi^2$). Using data visualizations, we show the effects of domain adaptation on proper latent space data alignment. This shows that DA-GNNs are a promising method for extracting domain-independent cosmological information, a vital step toward robust deep learning for real cosmic survey data.
WavPool: A New Block for Deep Neural Networks
Jun 14, 2023



Modern deep neural networks comprise many operational layers, such as dense or convolutional layers, which are often collected into blocks. In this work, we introduce a new, wavelet-transform-based network architecture that we call the multi-resolution perceptron: by adding a pooling layer, we create a new network block, the WavPool. The first step of the multi-resolution perceptron is transforming the data into its multi-resolution decomposition form by convolving the input data with filters of fixed coefficients but increasing size. Following image processing techniques, we are able to make scale and spatial information simultaneously accessible to the network without increasing the size of the data vector. WavPool outperforms a similar multilayer perceptron while using fewer parameters, and outperforms a comparable convolutional neural network by ~ 10% on relative accuracy on CIFAR-10.
Neural Inference of Gaussian Processes for Time Series Data of Quasars
Nov 17, 2022



The study of quasar light curves poses two problems: inference of the power spectrum and interpolation of an irregularly sampled time series. A baseline approach to these tasks is to interpolate a time series with a Damped Random Walk (DRW) model, in which the spectrum is inferred using Maximum Likelihood Estimation (MLE). However, the DRW model does not describe the smoothness of the time series, and MLE faces many problems in terms of optimization and numerical precision. In this work, we introduce a new stochastic model that we call $\textit{Convolved Damped Random Walk}$ (CDRW). This model introduces a concept of smoothness to a DRW, which enables it to describe quasar spectra completely. We also introduce a new method of inference of Gaussian process parameters, which we call $\textit{Neural Inference}$. This method uses the powers of state-of-the-art neural networks to improve the conventional MLE inference technique. In our experiments, the Neural Inference method results in significant improvement over the baseline MLE (RMSE: $0.318 \rightarrow 0.205$, $0.464 \rightarrow 0.444$). Moreover, the combination of both the CDRW model and Neural Inference significantly outperforms the baseline DRW and MLE in interpolating a typical quasar light curve ($\chi^2$: $0.333 \rightarrow 0.998$, $2.695 \rightarrow 0.981$). The code is published on GitHub.
Semi-Supervised Domain Adaptation for Cross-Survey Galaxy Morphology Classification and Anomaly Detection
Nov 11, 2022



In the era of big astronomical surveys, our ability to leverage artificial intelligence algorithms simultaneously for multiple datasets will open new avenues for scientific discovery. Unfortunately, simply training a deep neural network on images from one data domain often leads to very poor performance on any other dataset. Here we develop a Universal Domain Adaptation method DeepAstroUDA, capable of performing semi-supervised domain alignment that can be applied to datasets with different types of class overlap. Extra classes can be present in any of the two datasets, and the method can even be used in the presence of unknown classes. For the first time, we demonstrate the successful use of domain adaptation on two very different observational datasets (from SDSS and DECaLS). We show that our method is capable of bridging the gap between two astronomical surveys, and also performs well for anomaly detection and clustering of unknown data in the unlabeled dataset. We apply our model to two examples of galaxy morphology classification tasks with anomaly detection: 1) classifying spiral and elliptical galaxies with detection of merging galaxies (three classes including one unknown anomaly class); 2) a more granular problem where the classes describe more detailed morphological properties of galaxies, with the detection of gravitational lenses (ten classes including one unknown anomaly class).
A robust estimator of mutual information for deep learning interpretability
Oct 31, 2022We develop the use of mutual information (MI), a well-established metric in information theory, to interpret the inner workings of deep learning models. To accurately estimate MI from a finite number of samples, we present GMM-MI (pronounced $``$Jimmie$"$), an algorithm based on Gaussian mixture models that can be applied to both discrete and continuous settings. GMM-MI is computationally efficient, robust to the choice of hyperparameters and provides the uncertainty on the MI estimate due to the finite sample size. We extensively validate GMM-MI on toy data for which the ground truth MI is known, comparing its performance against established mutual information estimators. We then demonstrate the use of our MI estimator in the context of representation learning, working with synthetic data and physical datasets describing highly non-linear processes. We train deep learning models to encode high-dimensional data within a meaningful compressed (latent) representation, and use GMM-MI to quantify both the level of disentanglement between the latent variables, and their association with relevant physical quantities, thus unlocking the interpretability of the latent representation. We make GMM-MI publicly available.
Interpretable Uncertainty Quantification in AI for HEP
Aug 08, 2022Estimating uncertainty is at the core of performing scientific measurements in HEP: a measurement is not useful without an estimate of its uncertainty. The goal of uncertainty quantification (UQ) is inextricably linked to the question, "how do we physically and statistically interpret these uncertainties?" The answer to this question depends not only on the computational task we aim to undertake, but also on the methods we use for that task. For artificial intelligence (AI) applications in HEP, there are several areas where interpretable methods for UQ are essential, including inference, simulation, and control/decision-making. There exist some methods for each of these areas, but they have not yet been demonstrated to be as trustworthy as more traditional approaches currently employed in physics (e.g., non-AI frequentist and Bayesian methods). Shedding light on the questions above requires additional understanding of the interplay of AI systems and uncertainty quantification. We briefly discuss the existing methods in each area and relate them to tasks across HEP. We then discuss recommendations for avenues to pursue to develop the necessary techniques for reliable widespread usage of AI with UQ over the next decade.
Discovering the building blocks of dark matter halo density profiles with neural networks
Mar 16, 2022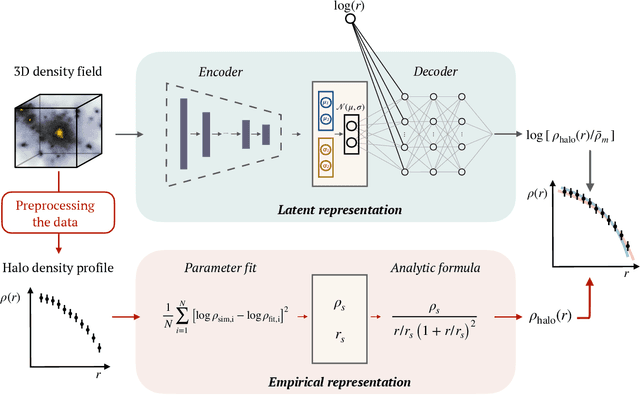
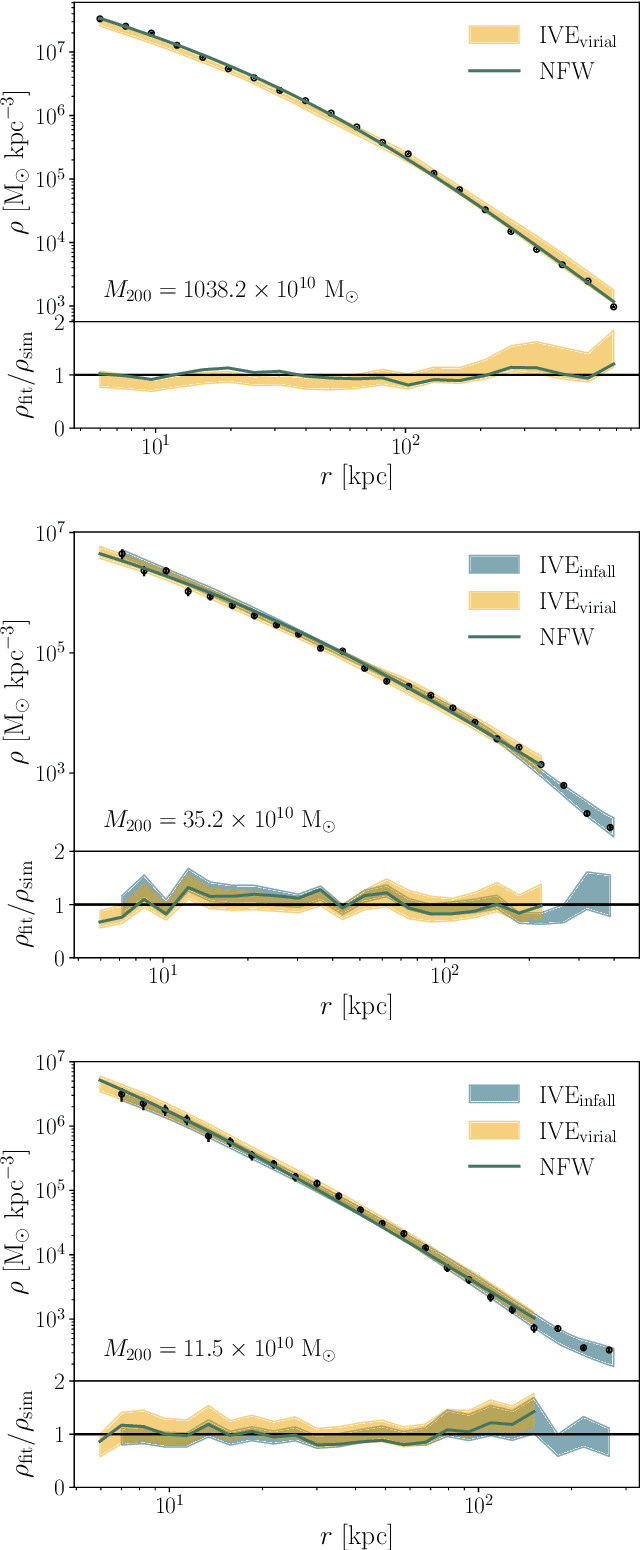
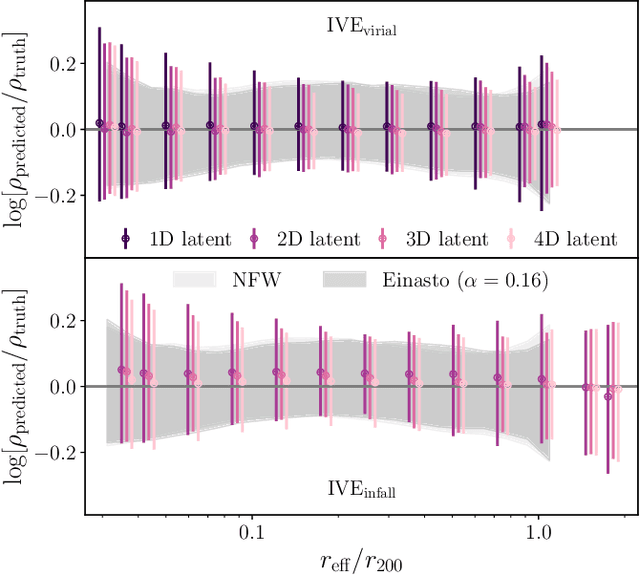
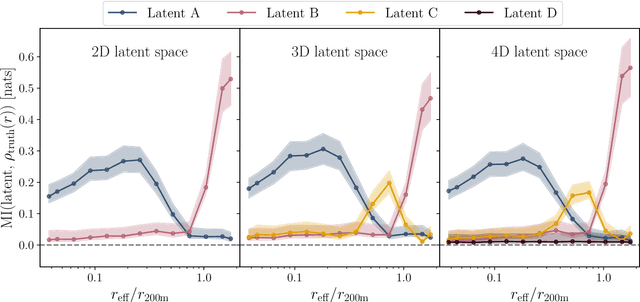
The density profiles of dark matter halos are typically modeled using empirical formulae fitted to the density profiles of relaxed halo populations. We present a neural network model that is trained to learn the mapping from the raw density field containing each halo to the dark matter density profile. We show that the model recovers the widely-used Navarro-Frenk-White (NFW) profile out to the virial radius, and can additionally describe the variability in the outer profile of the halos. The neural network architecture consists of a supervised encoder-decoder framework, which first compresses the density inputs into a low-dimensional latent representation, and then outputs $\rho(r)$ for any desired value of radius $r$. The latent representation contains all the information used by the model to predict the density profiles. This allows us to interpret the latent representation by quantifying the mutual information between the representation and the halos' ground-truth density profiles. A two-dimensional representation is sufficient to accurately model the density profiles up to the virial radius; however, a three-dimensional representation is required to describe the outer profiles beyond the virial radius. The additional dimension in the representation contains information about the infalling material in the outer profiles of dark matter halos, thus discovering the splashback boundary of halos without prior knowledge of the halos' dynamical history.
Learning Representation for Bayesian Optimization with Collision-free Regularization
Mar 16, 2022


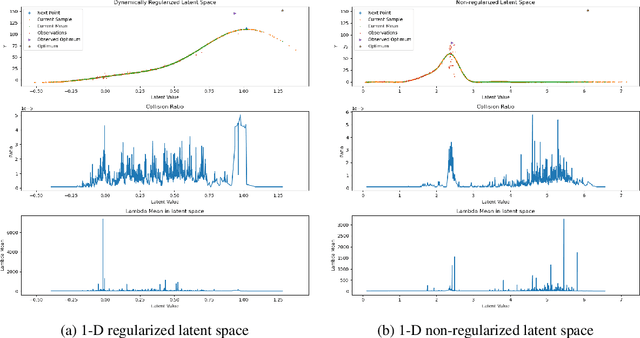
Bayesian optimization has been challenged by datasets with large-scale, high-dimensional, and non-stationary characteristics, which are common in real-world scenarios. Recent works attempt to handle such input by applying neural networks ahead of the classical Gaussian process to learn a latent representation. We show that even with proper network design, such learned representation often leads to collision in the latent space: two points with significantly different observations collide in the learned latent space, leading to degraded optimization performance. To address this issue, we propose LOCo, an efficient deep Bayesian optimization framework which employs a novel regularizer to reduce the collision in the learned latent space and encourage the mapping from the latent space to the objective value to be Lipschitz continuous. LOCo takes in pairs of data points and penalizes those too close in the latent space compared to their target space distance. We provide a rigorous theoretical justification for LOCo by inspecting the regret of this dynamic-embedding-based Bayesian optimization algorithm, where the neural network is iteratively retrained with the regularizer. Our empirical results demonstrate the effectiveness of LOCo on several synthetic and real-world benchmark Bayesian optimization tasks.
Machine Learning and Cosmology
Mar 15, 2022Methods based on machine learning have recently made substantial inroads in many corners of cosmology. Through this process, new computational tools, new perspectives on data collection, model development, analysis, and discovery, as well as new communities and educational pathways have emerged. Despite rapid progress, substantial potential at the intersection of cosmology and machine learning remains untapped. In this white paper, we summarize current and ongoing developments relating to the application of machine learning within cosmology and provide a set of recommendations aimed at maximizing the scientific impact of these burgeoning tools over the coming decade through both technical development as well as the fostering of emerging communities.