 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ice Core Dating using Probabilistic Programming
Oct 29, 2022
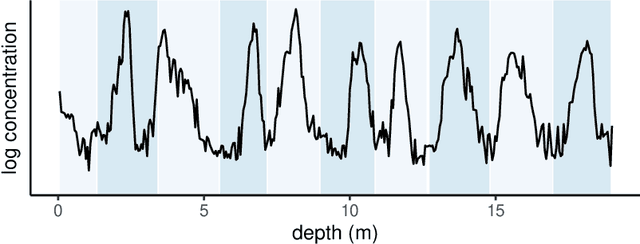
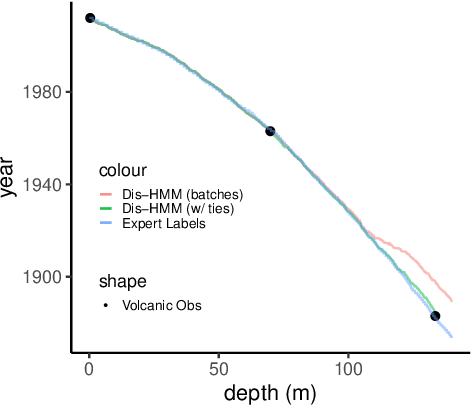
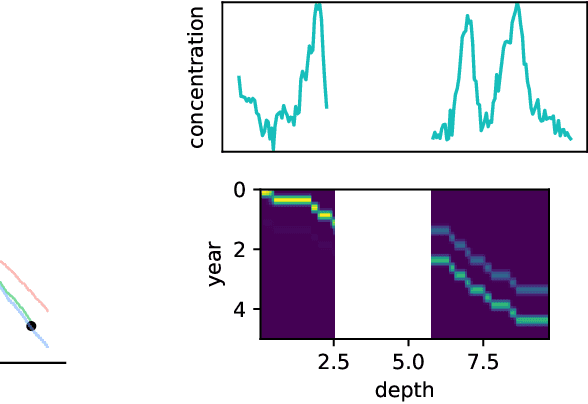
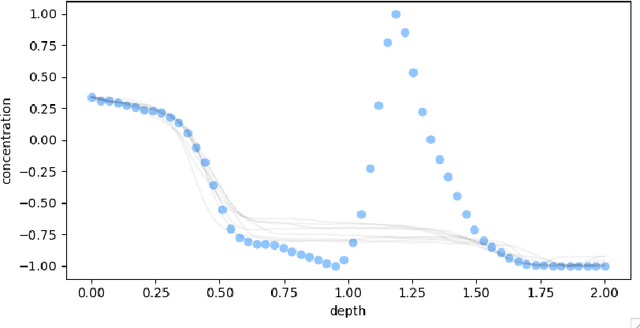
Ice cores record crucial information about past climate. However, before ice core data can have scientific value, the chronology must be inferred by estimating the age as a function of depth. Under certain conditions, chemicals locked in the ice display quasi-periodic cycles that delineate annual layers. Manually counting these noisy seasonal patterns to infer the chronology can be an imperfect and time-consuming process, and does not capture uncertainty in a principled fashion. In addition, several ice cores may be collected from a region, introducing an aspect of spatial correlation between them. We present an exploration of the use of probabilistic models for automatic dating of ice cores, using probabilistic programming to showcase its use for prototyping, automatic inference and maintainability, and demonstrate common failure modes of these tools.
CapillaryX: A Software Design Pattern for Analyzing Medical Images in Real-time using Deep Learning
Apr 13, 2022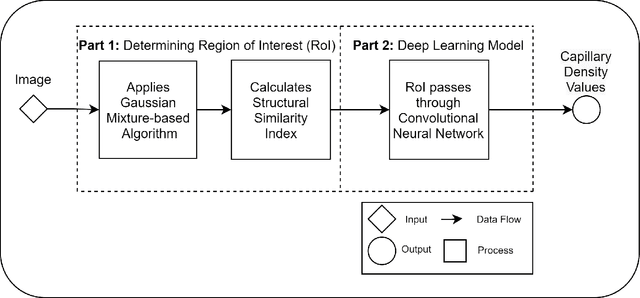
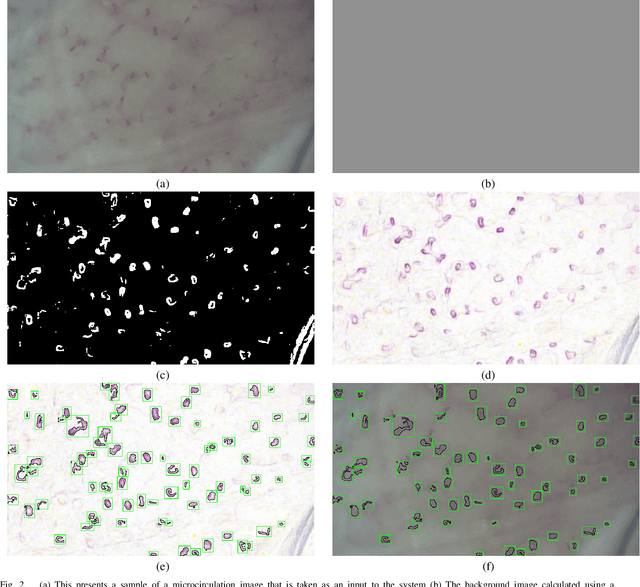
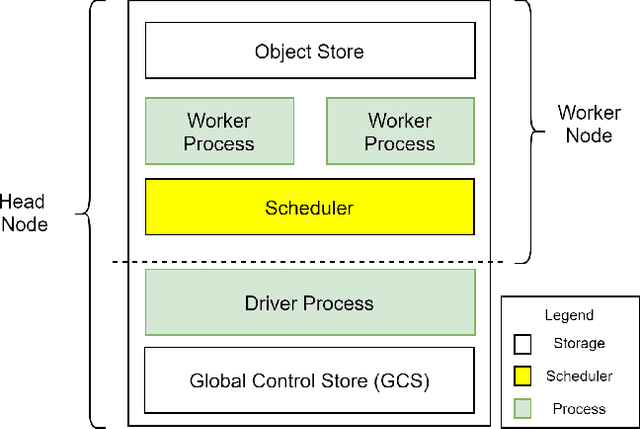
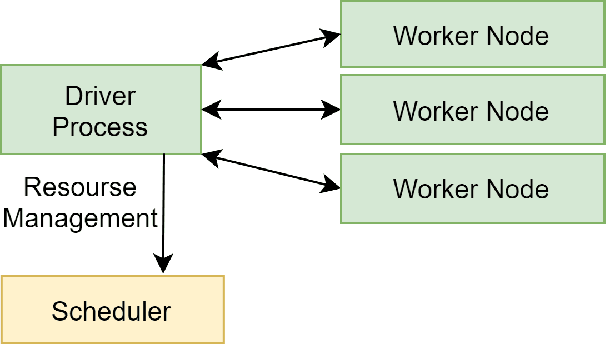
Recent advances in digital imaging, e.g., increased number of pixels captured, have meant that the volume of data to be processed and analyzed from these images has also increased. Deep learning algorithms are state-of-the-art for analyzing such images, given their high accuracy when trained with a large data volume of data. Nevertheless, such analysis requires considerable computational power, making such algorithms time- and resource-demanding. Such high demands can be met by using third-party cloud service providers. However, analyzing medical images using such services raises several legal and privacy challenges and does not necessarily provide real-time results. This paper provides a computing architecture that locally and in parallel can analyze medical images in real-time using deep learning thus avoiding the legal and privacy challenges stemming from uploading data to a third-party cloud provider. To make local image processing efficient on modern multi-core processors, we utilize parallel execution to offset the resource-intensive demands of deep neural networks. We focus on a specific medical-industrial case study, namely the quantifying of blood vessels in microcirculation images for which we have developed a working system. It is currently used in an industrial, clinical research setting as part of an e-health application. Our results show that our system is approximately 78% faster than its serial system counterpart and 12% faster than a master-slave parallel system architecture.
SOCIALMAPF: Optimal and Efficient Multi-Agent Path Finding with Strategic Agents for Social Navigation
Oct 15, 2022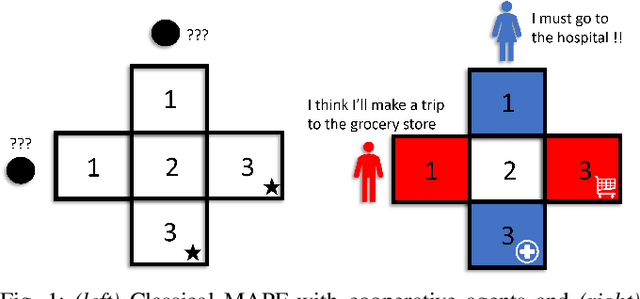

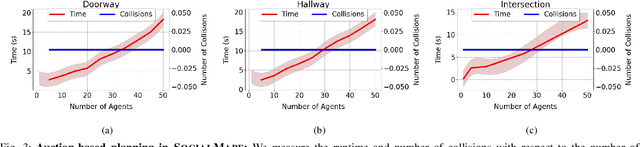

We propose an extension to the MAPF formulation, called SocialMAPF, to account for private incentives of agents in constrained environments such as doorways, narrow hallways, and corridor intersections. SocialMAPF is able to, for instance, accurately reason about the urgent incentive of an agent rushing to the hospital over another agent's less urgent incentive of going to a grocery store; MAPF ignores such agent-specific incentives. Our proposed formulation addresses the open problem of optimal and efficient path planning for agents with private incentives. To solve SocialMAPF, we propose a new class of algorithms that use mechanism design during conflict resolution to simultaneously optimize agents' private local utilities and the global system objective. We perform an extensive array of experiments that show that optimal search-based MAPF techniques lead to collisions and increased time-to-goal in SocialMAPF compared to our proposed method using mechanism design. Furthermore, we empirically demonstrate that mechanism design results in models that maximizes agent utility and minimizes the overall time-to-goal of the entire system. We further showcase the capabilities of mechanism design-based planning by successfully deploying it in environments with static obstacles. To conclude, we briefly list several research directions using the SocialMAPF formulation, such as exploring motion planning in the continuous domain for agents with private incentives.
STPOTR: Simultaneous Human Trajectory and Pose Prediction Using a Non-Autoregressive Transformer for Robot Following Ahead
Sep 27, 2022
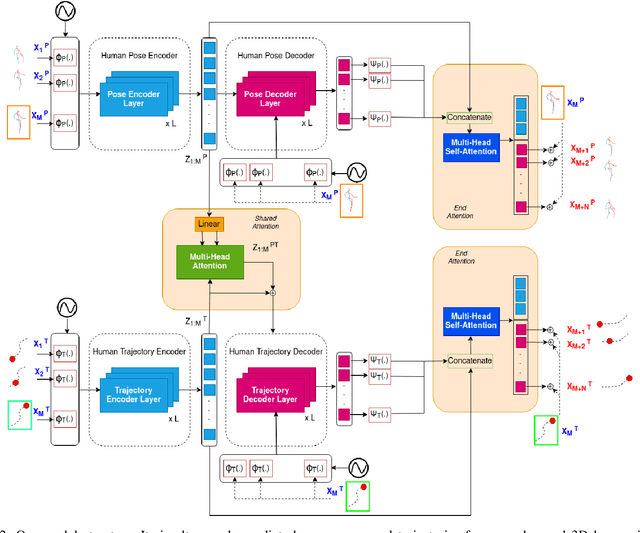


In this paper, we develop a neural network model to predict future human motion from an observed human motion history. We propose a non-autoregressive transformer architecture to leverage its parallel nature for easier training and fast, accurate predictions at test time. The proposed architecture divides human motion prediction into two parts: 1) the human trajectory, which is the hip joint 3D position over time and 2) the human pose which is the all other joints 3D positions over time with respect to a fixed hip joint. We propose to make the two predictions simultaneously, as the shared representation can improve the model performance. Therefore, the model consists of two sets of encoders and decoders. First, a multi-head attention module applied to encoder outputs improves human trajectory. Second, another multi-head self-attention module applied to encoder outputs concatenated with decoder outputs facilitates learning of temporal dependencies. Our model is well-suited for robotic applications in terms of test accuracy and speed, and compares favorably with respect to state-of-the-art methods. We demonstrate the real-world applicability of our work via the Robot Follow-Ahead task, a challenging yet practical case study for our proposed model.
Bridging CLIP and StyleGAN through Latent Alignment for Image Editing
Oct 10, 2022

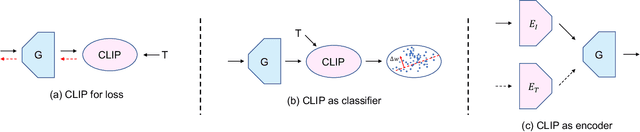
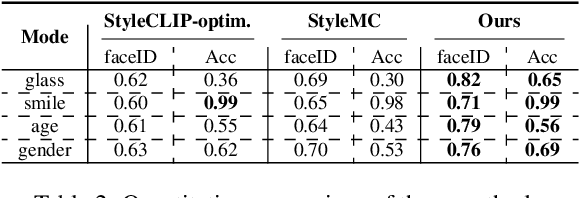
Text-driven image manipulation is developed since the vision-language model (CLIP) has been proposed. Previous work has adopted CLIP to design a text-image consistency-based objective to address this issue. However, these methods require either test-time optimization or image feature cluster analysis for single-mode manipulation direction. In this paper, we manage to achieve inference-time optimization-free diverse manipulation direction mining by bridging CLIP and StyleGAN through Latent Alignment (CSLA). More specifically, our efforts consist of three parts: 1) a data-free training strategy to train latent mappers to bridge the latent space of CLIP and StyleGAN; 2) for more precise mapping, temporal relative consistency is proposed to address the knowledge distribution bias problem among different latent spaces; 3) to refine the mapped latent in s space, adaptive style mixing is also proposed. With this mapping scheme, we can achieve GAN inversion, text-to-image generation and text-driven image manipulation. Qualitative and quantitative comparisons are made to demonstrate the effectiveness of our method.
A Two-Stage Deep Representation Learning-Based Speech Enhancement Method Using Variational Autoencoder and Adversarial Training
Nov 16, 2022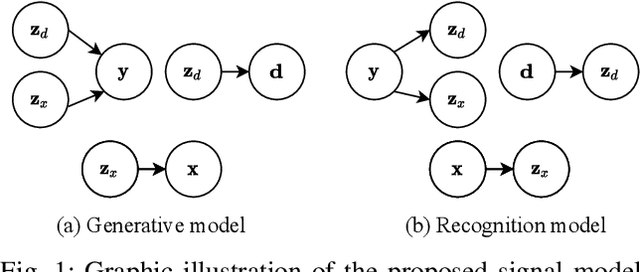
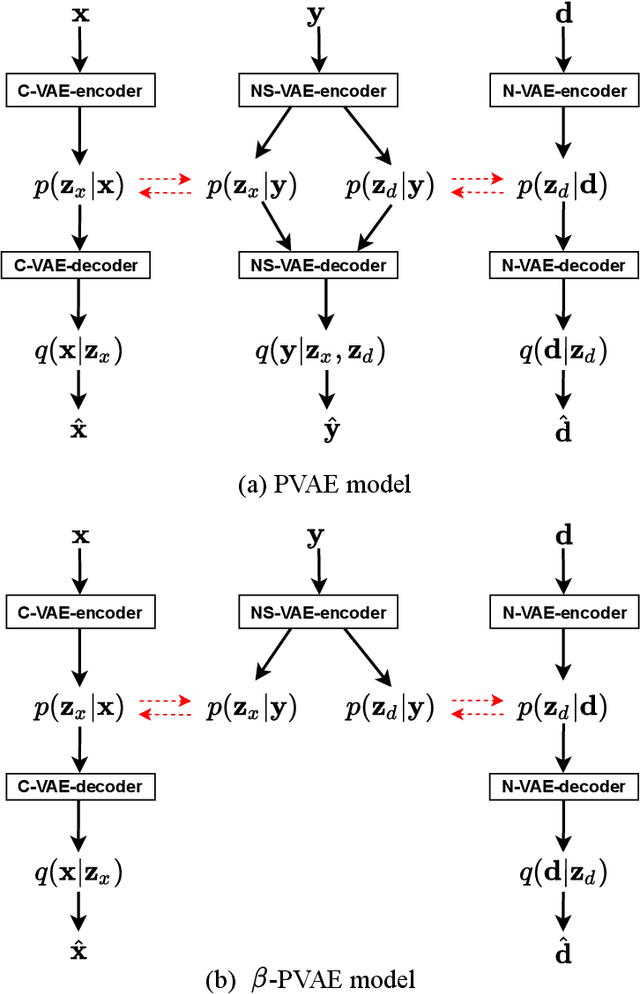
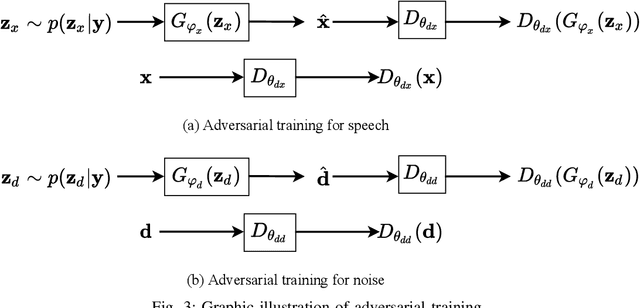
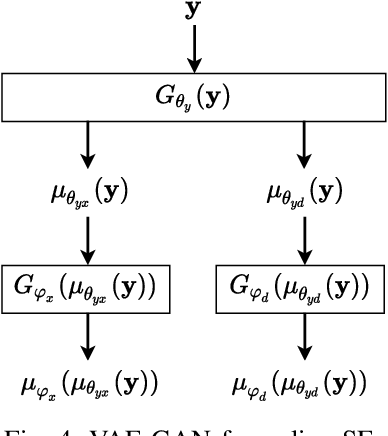
This paper focuses on leveraging deep representation learning (DRL) for speech enhancement (SE). In general, the performance of the deep neural network (DNN) is heavily dependent on the learning of data representation. However, the DRL's importance is often ignored in many DNN-based SE algorithms. To obtain a higher quality enhanced speech, we propose a two-stage DRL-based SE method through adversarial training. In the first stage, we disentangle different latent variables because disentangled representations can help DNN generate a better enhanced speech. Specifically, we use the $\beta$-variational autoencoder (VAE) algorithm to obtain the speech and noise posterior estimations and related representations from the observed signal. However, since the posteriors and representations are intractable and we can only apply a conditional assumption to estimate them, it is difficult to ensure that these estimations are always pretty accurate, which may potentially degrade the final accuracy of the signal estimation. To further improve the quality of enhanced speech, in the second stage, we introduce adversarial training to reduce the effect of the inaccurate posterior towards signal reconstruction and improve the signal estimation accuracy, making our algorithm more robust for the potentially inaccurate posterior estimations. As a result, better SE performance can be achieved. The experimental results indicate that the proposed strategy can help similar DNN-based SE algorithms achieve higher short-time objective intelligibility (STOI), perceptual evaluation of speech quality (PESQ), and scale-invariant signal-to-distortion ratio (SI-SDR) scores. Moreover, the proposed algorithm can also outperform recent competitive SE algorithms.
The availability, outage, and capacity of spatially correlated, Australasian free-space optical networks
Nov 16, 2022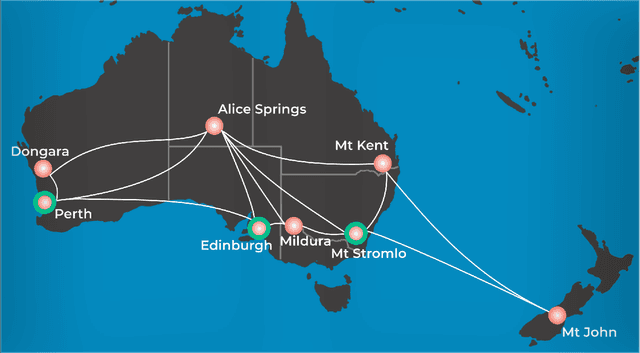
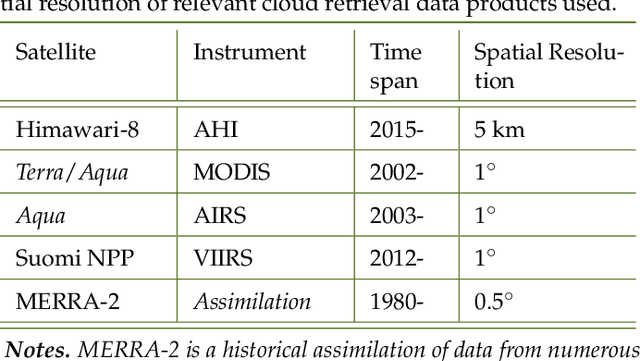
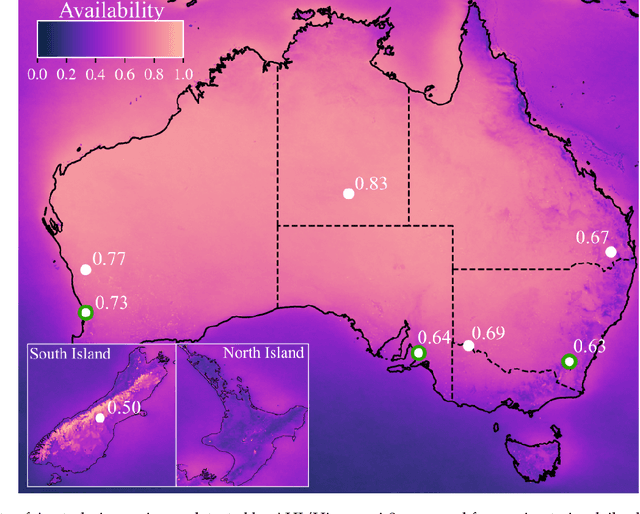
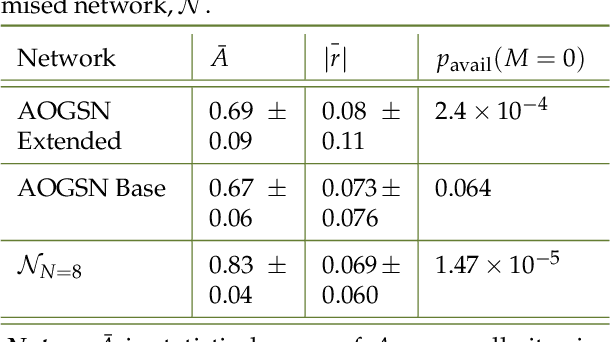
Network capacity and reliability for free space optical communication (FSOC) is strongly driven by ground station availability, dominated by local cloud cover causing an outage, and how availability relations between stations produce network diversity. We combine remote sensing data and novel methods to provide a generalised framework for assessing and optimising optical ground station networks. This work is guided by an example network of eight Australian and New Zealand optical communication ground stations which would span approximately $60^\circ$ in longitude and $20^\circ$ in latitude. Utilising time-dependent cloud cover data from five satellites, we present a detailed analysis determining the availability and diversity of the network, finding the Australasian region is well-suited for an optical network with a 69% average site availability and low spatial cloud cover correlations. Employing methods from computational neuroscience, we provide a Monte Carlo method for sampling the joint probability distribution of site availabilities for an arbitrarily sized and point-wise correlated network of ground stations. Furthermore, we develop a general heuristic for site selection under availability and correlation optimisations, and combine this with orbital propagation simulations to compare the data capacity between optimised networks and the example network. We show that the example network may be capable of providing tens of terabits per day to a LEO satellite, and up to 99.97% reliability to GEO satellites. We therefore use the Australasian region to demonstrate novel, generalised tools for assessing and optimising FSOC ground station networks, and additionally, the suitability of the region for hosting such a network.
Squeeze flow of micro-droplets: convolutional neural network with trainable and tunable refinement
Nov 16, 2022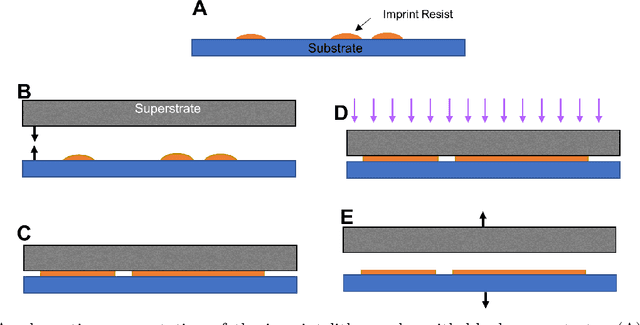
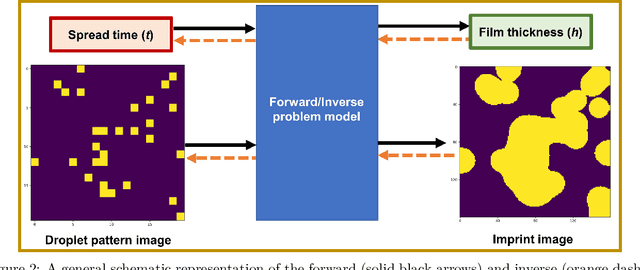
We propose a platform based on neural networks to solve the image-to-image translation problem in the context of squeeze flow of micro-droplets. In the first part of this paper, we present the governing partial differential equations to lay out the underlying physics of the problem. We also discuss our developed Python package, sqflow, which can potentially serve as free, flexible, and scalable standardized benchmarks in the fields of machine learning and computer vision. In the second part of this paper, we introduce a residual convolutional neural network to solve the corresponding inverse problem: to translate a high-resolution (HR) imprint image with a specific liquid film thickness to a low-resolution (LR) droplet pattern image capable of producing the given imprint image for an appropriate spread time of droplets. We propose a neural network architecture that learns to systematically tune the refinement level of its residual convolutional blocks by using the function approximators that are trained to map a given input parameter (film thickness) to an appropriate refinement level indicator. We use multiple stacks of convolutional layers the output of which is translated according to the refinement level indicators provided by the directly-connected function approximators. Together with a non-linear activation function, such a translation mechanism enables the HR imprint image to be refined sequentially in multiple steps until the target LR droplet pattern image is revealed. The proposed platform can be potentially applied to data compression and data encryption. The developed package and datasets are publicly available on GitHub at https://github.com/sqflow/sqflow.
A novel GAN-based paradigm for weakly supervised brain tumor segmentation of MR images
Nov 10, 2022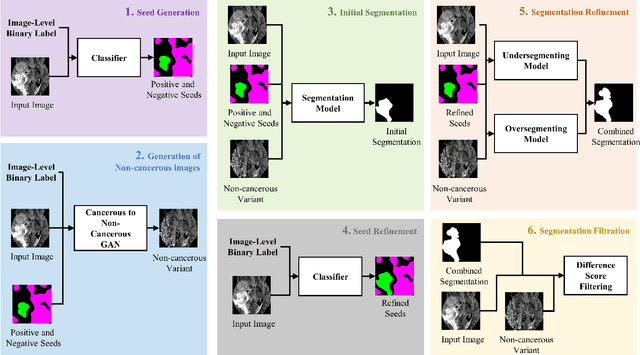
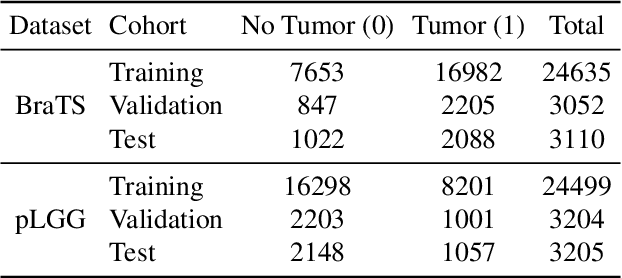
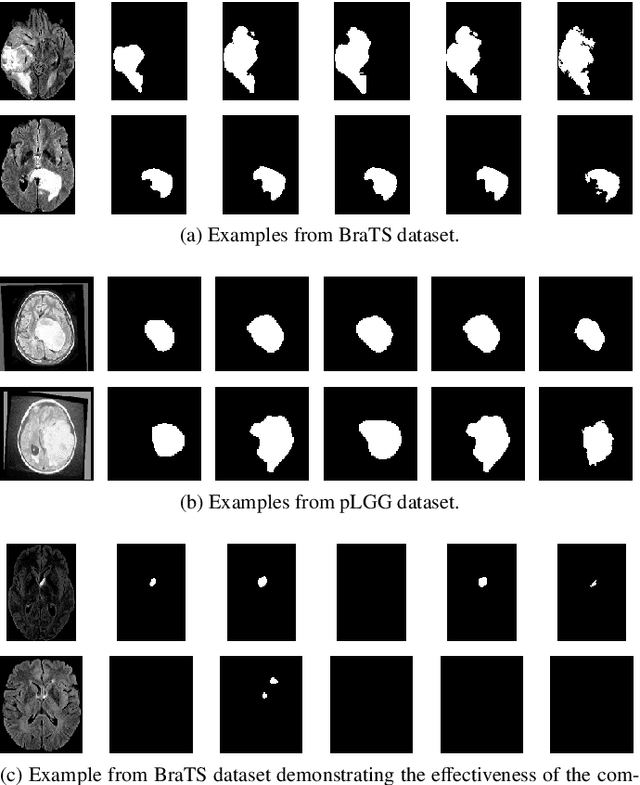
Segmentation of regions of interest (ROIs) for identifying abnormalities is a leading problem in medical imaging. Using Machine Learning (ML) for this problem generally requires manually annotated ground-truth segmentations, demanding extensive time and resources from radiologists. This work presents a novel weakly supervised approach that utilizes binary image-level labels, which are much simpler to acquire, to effectively segment anomalies in medical Magnetic Resonance (MR) images without ground truth annotations. We train a binary classifier using these labels and use it to derive seeds indicating regions likely and unlikely to contain tumors. These seeds are used to train a generative adversarial network (GAN) that converts cancerous images to healthy variants, which are then used in conjunction with the seeds to train a ML model that generates effective segmentations. This method produces segmentations that achieve Dice coefficients of 0.7903, 0.7868, and 0.7712 on the MICCAI Brain Tumor Segmentation (BraTS) 2020 dataset for the training, validation, and test cohorts respectively. We also propose a weakly supervised means of filtering the segmentations, removing a small subset of poorer segmentations to acquire a large subset of high quality segmentations. The proposed filtering further improves the Dice coefficients to up to 0.8374, 0.8232, and 0.8136 for training, validation, and test, respectively.
RARE: Renewable Energy Aware Resource Management in Datacenters
Nov 10, 2022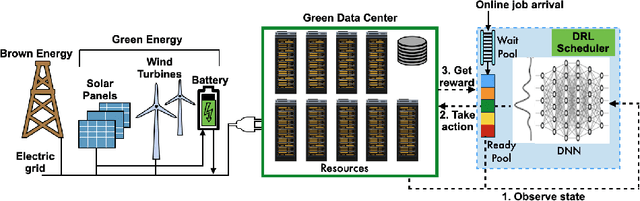

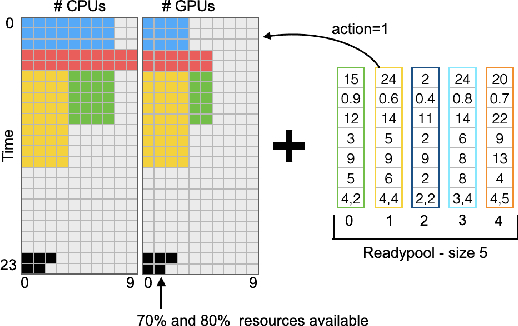
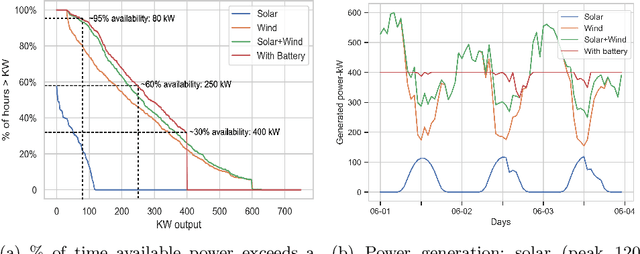
The exponential growth in demand for digital services drives massive datacenter energy consumption and negative environmental impacts. Promoting sustainable solutions to pressing energy and digital infrastructure challenges is crucial. Several hyperscale cloud providers have announced plans to power their datacenters using renewable energy. However, integrating renewables to power the datacenters is challenging because the power generation is intermittent, necessitating approaches to tackle power supply variability. Hand engineering domain-specific heuristics-based schedulers to meet specific objective functions in such complex dynamic green datacenter environments is time-consuming, expensive, and requires extensive tuning by domain experts. The green datacenters need smart systems and system software to employ multiple renewable energy sources (wind and solar) by intelligently adapting computing to renewable energy generation. We present RARE (Renewable energy Aware REsource management), a Deep Reinforcement Learning (DRL) job scheduler that automatically learns effective job scheduling policies while continually adapting to datacenters' complex dynamic environment. The resulting DRL scheduler performs better than heuristic scheduling policies with different workloads and adapts to the intermittent power supply from renewables. We demonstrate DRL scheduler system design parameters that, when tuned correctly, produce better performance. Finally, we demonstrate that the DRL scheduler can learn from and improve upon existing heuristic policies using Offline Learning.