 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Privacy-Preserving Models for Legal Natural Language Processing
Nov 05, 2022

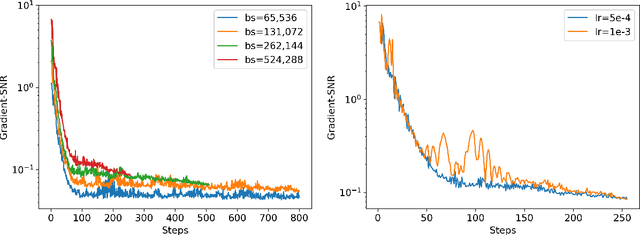
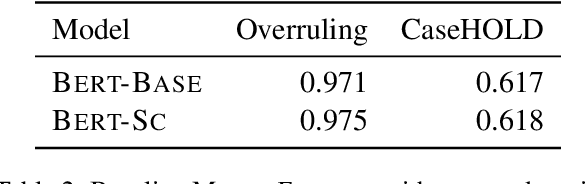
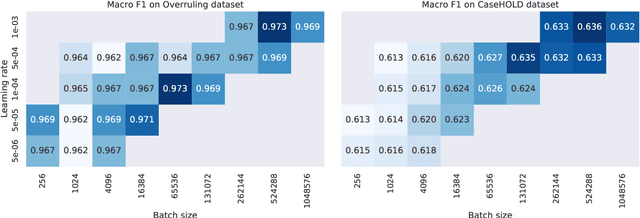
Pre-training large transformer models with in-domain data improves domain adaptation and helps gain performance on the domain-specific downstream tasks. However, sharing models pre-trained on potentially sensitive data is prone to adversarial privacy attacks. In this paper, we asked to which extent we can guarantee privacy of pre-training data and, at the same time, achieve better downstream performance on legal tasks without the need of additional labeled data. We extensively experiment with scalable self-supervised learning of transformer models under the formal paradigm of differential privacy and show that under specific training configurations we can improve downstream performance without sacrifying privacy protection for the in-domain data. Our main contribution is utilizing differential privacy for large-scale pre-training of transformer language models in the legal NLP domain, which, to the best of our knowledge, has not been addressed before.
Neural multi-event forecasting on spatio-temporal point processes using probabilistically enriched transformers
Nov 05, 2022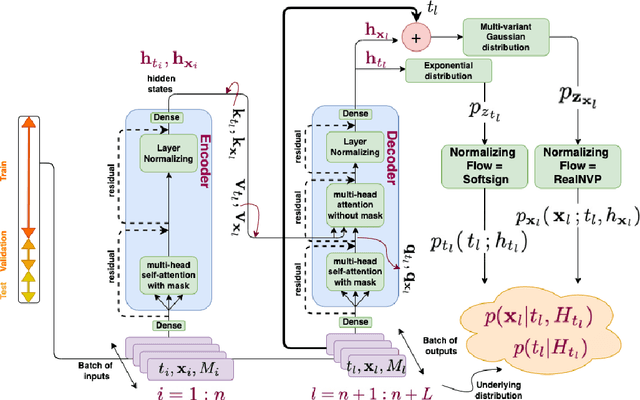
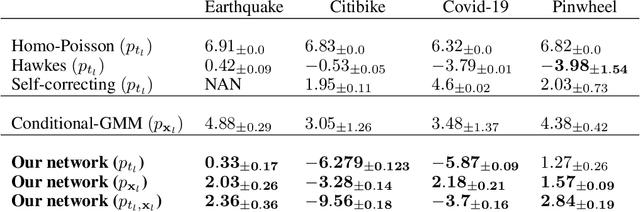
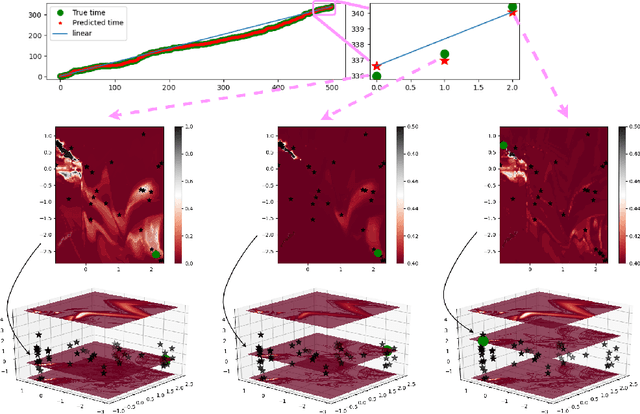
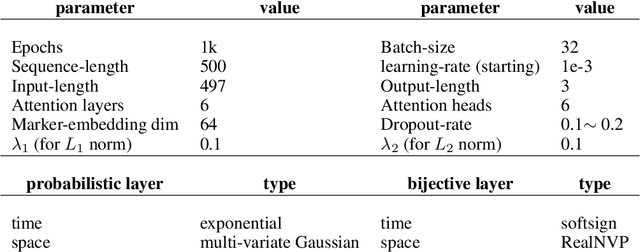
Predicting discrete events in time and space has many scientific applications, such as predicting hazardous earthquakes and outbreaks of infectious diseases. History-dependent spatio-temporal Hawkes processes are often used to mathematically model these point events. However, previous approaches have faced numerous challenges, particularly when attempting to forecast one or multiple future events. In this work, we propose a new neural architecture for multi-event forecasting of spatio-temporal point processes, utilizing transformers, augmented with normalizing flows and probabilistic layers. Our network makes batched predictions of complex history-dependent spatio-temporal distributions of future discrete events, achieving state-of-the-art performance on a variety of benchmark datasets including the South California Earthquakes, Citibike, Covid-19, and Hawkes synthetic pinwheel datasets. More generally, we illustrate how our network can be applied to any dataset of discrete events with associated markers, even when no underlying physics is known.
LVOS: A Benchmark for Long-term Video Object Segmentation
Nov 18, 2022
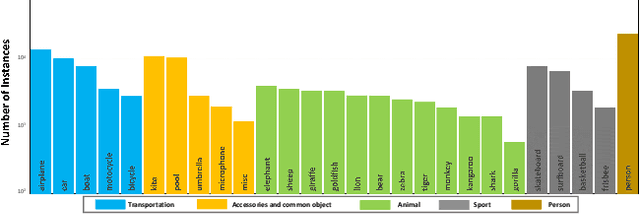
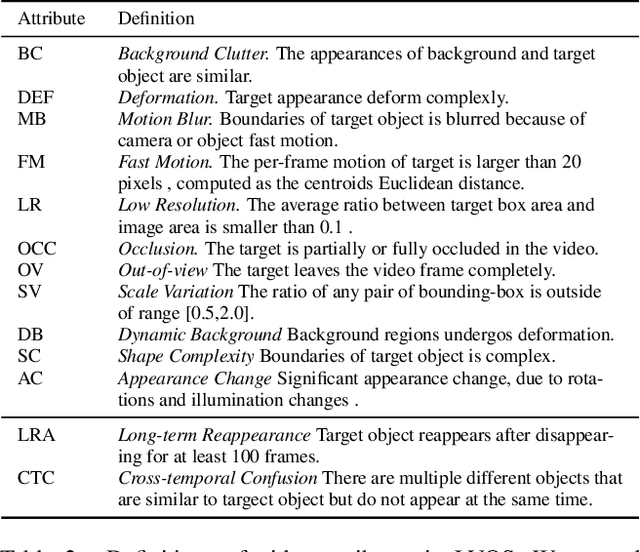
Existing video object segmentation (VOS) benchmarks focus on short-term videos which just last about 3-5 seconds and where objects are visible most of the time. These videos are poorly representative of practical applications, and the absence of long-term datasets restricts further investigation of VOS on the application in realistic scenarios. So, in this paper, we present a new benchmark dataset and evaluation methodology named LVOS, which consists of 220 videos with a total duration of 421 minutes. To the best of our knowledge, LVOS is the first densely annotated long-term VOS dataset. The videos in our LVOS last 1.59 minutes on average, which is 20 times longer than videos in existing VOS datasets. Each video includes various attributes, especially challenges deriving from the wild, such as long-term reappearing and cross-temporal similar objeccts. Moreover, we provide additional language descriptions to encourage the exploration of integrating linguistic and visual features for video object segmentation. Based on LVOS, we assess existing video object segmentation algorithms and propose a Diverse Dynamic Memory network (DDMemory) that consists of three complementary memory banks to exploit temporal information adequately. The experiment results demonstrate the strength and weaknesses of prior methods, pointing promising directions for further study. Our objective is to provide the community with a large and varied benchmark to boost the advancement of long-term VOS. Data and code are available at \url{https://lingyihongfd.github.io/lvos.github.io/}.
Estimating defection in subscription-type markets: empirical analysis from the scholarly publishing industry
Nov 18, 2022
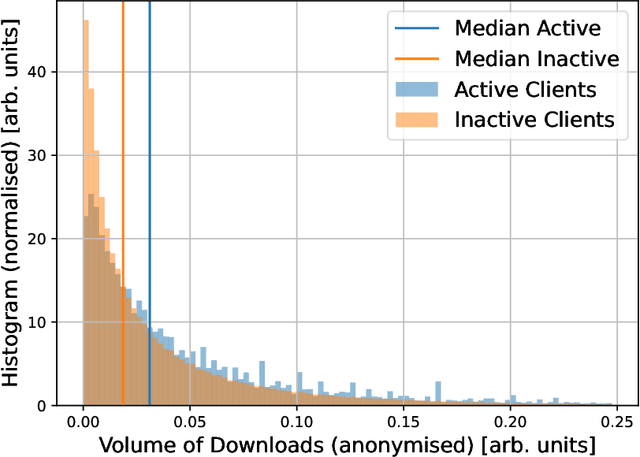
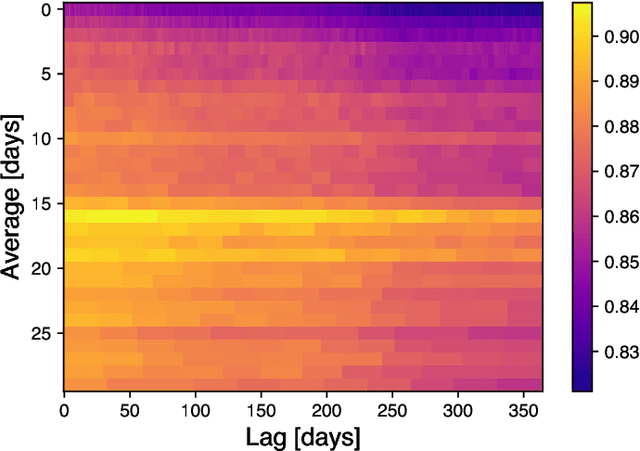
We present the first empirical study on customer churn prediction in the scholarly publishing industry. The study examines our proposed method for prediction on a customer subscription data over a period of 6.5 years, which was provided by a major academic publisher. We explore the subscription-type market within the context of customer defection and modelling, and provide analysis of the business model of such markets, and how these characterise the academic publishing business. The proposed method for prediction attempts to provide inference of customer's likelihood of defection on the basis of their re-sampled use of provider resources -in this context, the volume and frequency of content downloads. We show that this approach can be both accurate as well as uniquely useful in the business-to-business context, with which the scholarly publishing business model shares similarities. The main findings of this work suggest that whilst all predictive models examined, especially ensemble methods of machine learning, achieve substantially accurate prediction of churn, nearly a year ahead, this can be furthermore achieved even when the specific behavioural attributes that can be associated to each customer probability to churn are overlooked. Allowing as such highly accurate inference of churn from minimal possible data. We show that modelling churn on the basis of re-sampling customers' use of resources over subscription time is a better (simplified) approach than when considering the high granularity that can often characterise consumption behaviour.
Computational Short Cuts in Infinite Domain Constraint Satisfaction
Nov 18, 2022

A backdoor in a finite-domain CSP instance is a set of variables where each possible instantiation moves the instance into a polynomial-time solvable class. Backdoors have found many applications in artificial intelligence and elsewhere, and the algorithmic problem of finding such backdoors has consequently been intensively studied. Sioutis and Janhunen (Proc. 42nd German Conference on AI (KI-2019)) have proposed a generalised backdoor concept suitable for infinite-domain CSP instances over binary constraints. We generalise their concept into a large class of CSPs that allow for higher-arity constraints. We show that this kind of infinite-domain backdoors have many of the positive computational properties that finite-domain backdoors have: the associated computational problems are fixed-parameter tractable whenever the underlying constraint language is finite. On the other hand, we show that infinite languages make the problems considerably harder: the general backdoor detection problem is W[2]-hard and fixed-parameter tractability is ruled out under standard complexity-theoretic assumptions. We demonstrate that backdoors may have suboptimal behaviour on binary constraints -- this is detrimental from an AI perspective where binary constraints are predominant in, for instance, spatiotemporal applications. In response to this, we introduce sidedoors as an alternative to backdoors. The fundamental computational problems for sidedoors remain fixed-parameter tractable for finite constraint language (possibly also containing non-binary relations). Moreover, the sidedoor approach has appealing computational properties that sometimes leads to faster algorithms than the backdoor approach.
Improved Cross-view Completion Pre-training for Stereo Matching
Nov 18, 2022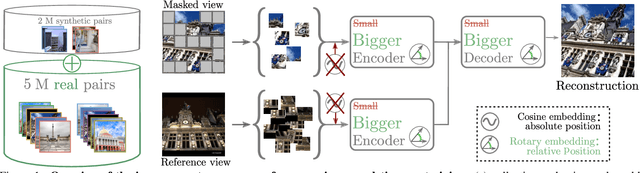



Despite impressive performance for high-level downstream tasks, self-supervised pre-training methods have not yet fully delivered on dense geometric vision tasks such as stereo matching. The application of self-supervised learning concepts, such as instance discrimination or masked image modeling, to geometric tasks is an active area of research. In this work we build on the recent cross-view completion framework: this variation of masked image modeling leverages a second view from the same scene, which is well suited for binocular downstream tasks. However, the applicability of this concept has so far been limited in at least two ways: (a) by the difficulty of collecting real-world image pairs - in practice only synthetic data had been used - and (b) by the lack of generalization of vanilla transformers to dense downstream tasks for which relative position is more meaningful than absolute position. We explore three avenues of improvement: first, we introduce a method to collect suitable real-world image pairs at large scale. Second, we experiment with relative positional embeddings and demonstrate that they enable vision transformers to perform substantially better. Third, we scale up vision transformer based cross-completion architectures, which is made possible by the use of large amounts of data. With these improvements, we show for the first time that state-of-the-art results on deep stereo matching can be reached without using any standard task-specific techniques like correlation volume, iterative estimation or multi-scale reasoning.
A Multi-Scale Time-Frequency Spectrogram Discriminator for GAN-based Non-Autoregressive TTS
Mar 22, 2022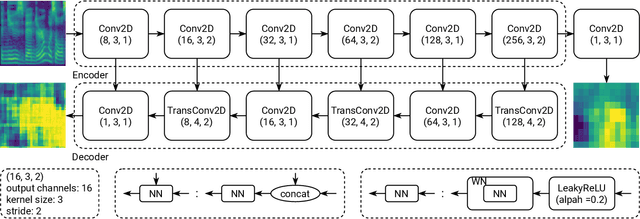
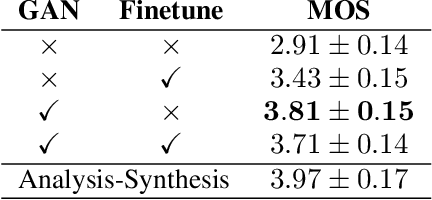

The generative adversarial network (GAN) has shown its outstanding capability in improving Non-Autoregressive TTS (NAR-TTS) by adversarially training it with an extra model that discriminates between the real and the generated speech. To maximize the benefits of GAN, it is crucial to find a powerful discriminator that can capture rich distinguishable information. In this paper, we propose a multi-scale time-frequency spectrogram discriminator to help NAR-TTS generate high-fidelity Mel-spectrograms. It treats the spectrogram as a 2D image to exploit the correlation among different components in the time-frequency domain. And a U-Net-based model structure is employed to discriminate at different scales to capture both coarse-grained and fine-grained information. We conduct subjective tests to evaluate the proposed approach. Both multi-scale and time-frequency discriminating bring significant improvement in the naturalness and fidelity. When combining the neural vocoder, it is shown more effective and concise than fine-tuning the vocoder. Finally, we visualize the discriminating maps to compare their difference to verify the effectiveness of multi-scale discriminating.
Physics Informed RNN-DCT Networks for Time-Dependent Partial Differential Equations
Feb 24, 2022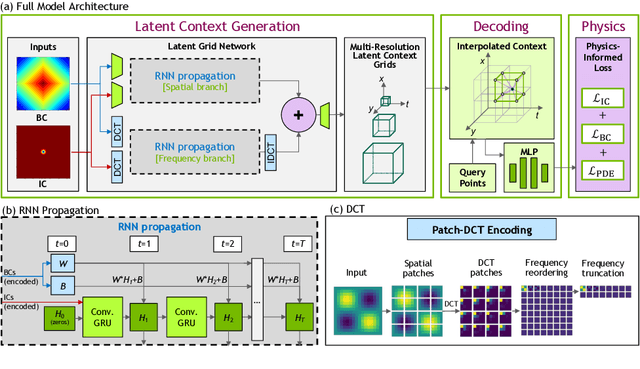
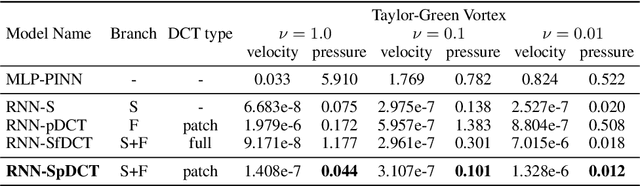
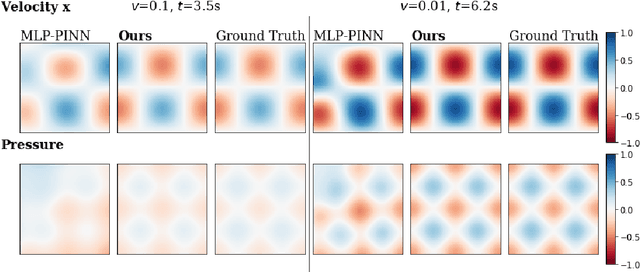
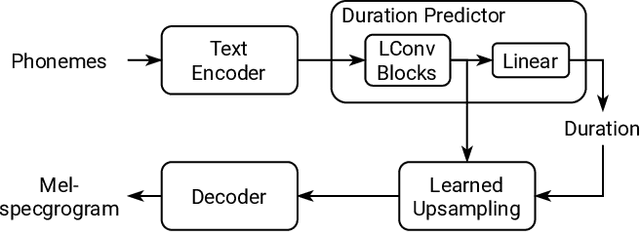
Physics-informed neural networks allow models to be trained by physical laws described by general nonlinear partial differential equations. However, traditional architectures struggle to solve more challenging time-dependent problems due to their architectural nature. In this work, we present a novel physics-informed framework for solving time-dependent partial differential equations. Using only the governing differential equations and problem initial and boundary conditions, we generate a latent representation of the problem's spatio-temporal dynamics. Our model utilizes discrete cosine transforms to encode spatial frequencies and recurrent neural networks to process the time evolution. This efficiently and flexibly produces a compressed representation which is used for additional conditioning of physics-informed models. We show experimental results on the Taylor-Green vortex solution to the Navier-Stokes equations. Our proposed model achieves state-of-the-art performance on the Taylor-Green vortex relative to other physics-informed baseline models.
Prediction and Uncertainty Quantification of SAFARI-1 Axial Neutron Flux Profiles with Neural Networks
Nov 16, 2022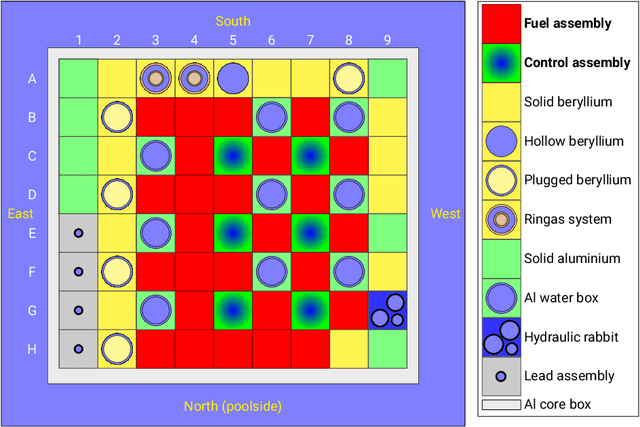
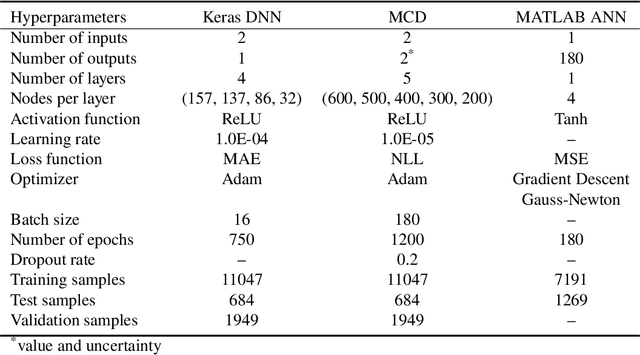
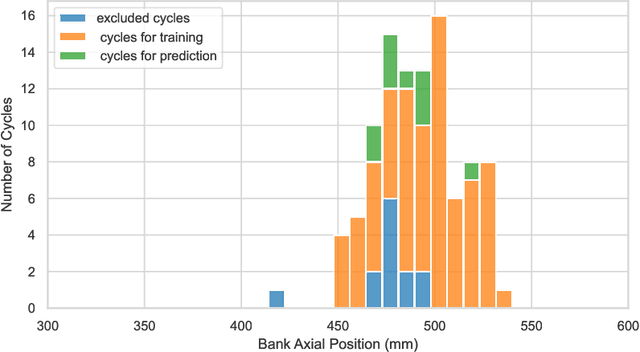
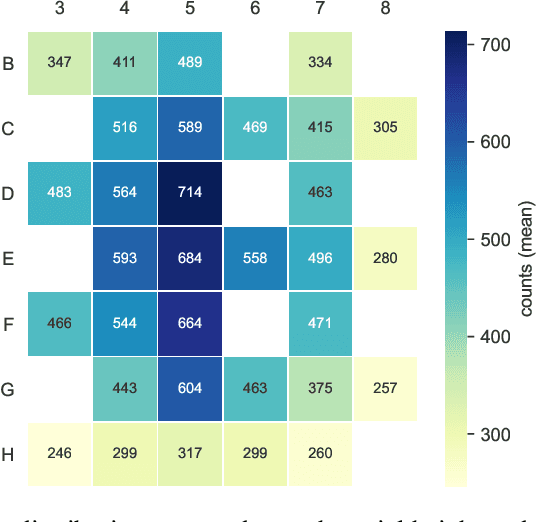
Artificial Neural Networks (ANNs) have been successfully used in various nuclear engineering applications, such as predicting reactor physics parameters within reasonable time and with a high level of accuracy. Despite this success, they cannot provide information about the model prediction uncertainties, making it difficult to assess ANN prediction credibility, especially in extrapolated domains. In this study, Deep Neural Networks (DNNs) are used to predict the assembly axial neutron flux profiles in the SAFARI-1 research reactor, with quantified uncertainties in the ANN predictions and extrapolation to cycles not used in the training process. The training dataset consists of copper-wire activation measurements, the axial measurement locations and the measured control bank positions obtained from the reactor's historical cycles. Uncertainty Quantification of the regular DNN models' predictions is performed using Monte Carlo Dropout (MCD) and Bayesian Neural Networks solved by Variational Inference (BNN VI). The regular DNNs, DNNs solved with MCD and BNN VI results agree very well among each other as well as with the new measured dataset not used in the training process, thus indicating good prediction and generalization capability. The uncertainty bands produced by MCD and BNN VI agree very well, and in general, they can fully envelop the noisy measurement data points. The developed ANNs are useful in supporting the experimental measurements campaign and neutronics code Verification and Validation (V&V).
Fast and Accurate FSA System Using ELBERT: An Efficient and Lightweight BERT
Nov 16, 2022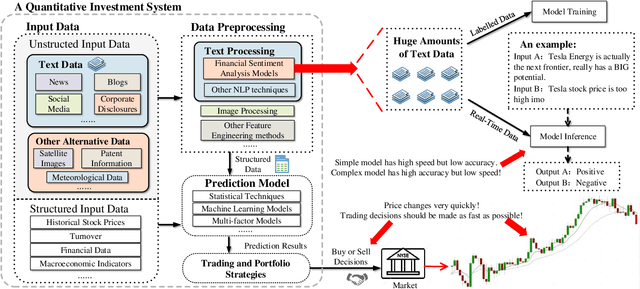
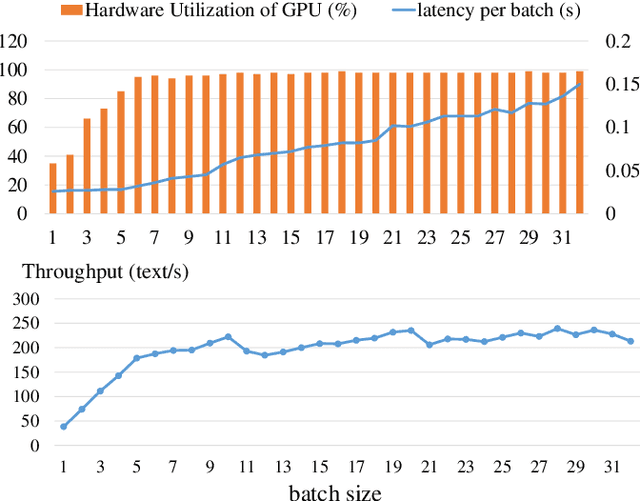
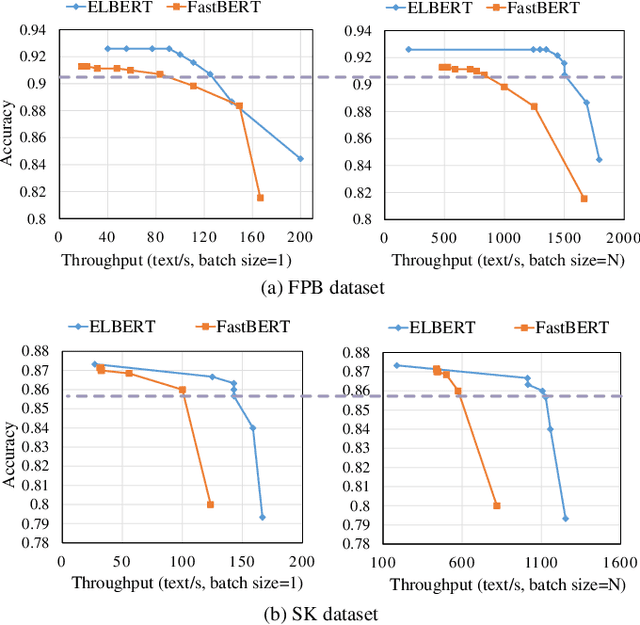
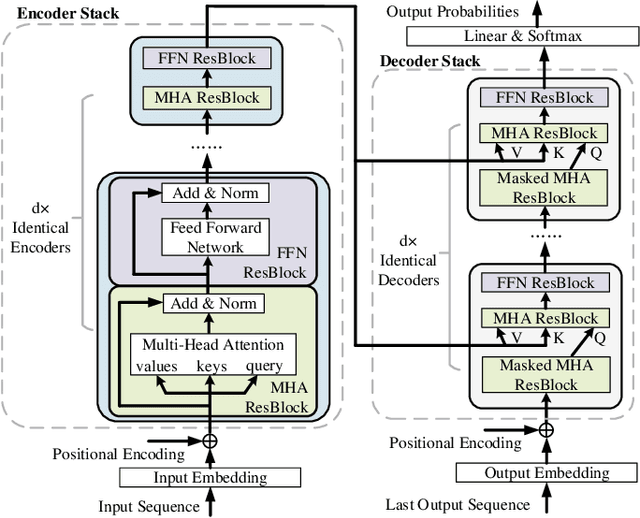
As an application of Natural Language Processing (NLP) techniques, financial sentiment analysis (FSA) has become an invaluable tool for investors. Its speed and accuracy can significantly impact the returns of trading strategies.With the development of deep learning and Transformer-based pre-trained models like BERT, the accuracy of FSA has been much improved, but these time-consuming big models will also slow down the computation. To boost the processing speed of the FSA system and ensure high precision, we first propose an efficient and lightweight BERT (ELBERT) along with a novel confidence-window-based (CWB) early exit mechanism. Based on ELBERT, an innovative method to accelerate text processing on the GPU platform is developed, solving the difficult problem of making the early exit mechanism work more effectively with a large input batch size. Afterward, a fast and high-accuracy FSA system is built. Experimental results show that the proposed CWB early exit mechanism achieves significantly higher accuracy than existing early exit methods on BERT under the same computation cost. Besides, our FSA system can boost the processing speed to over 1000 texts per second with sufficient accuracy by using this acceleration method, which is nearly twice as fast as the FastBERT. Hence, this system can enable modern trading systems to quickly and accurately process financial text data.