 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Scale Time-Frequency Spectrogram Discriminator for GAN-based Non-Autoregressive TTS
Paper and Code
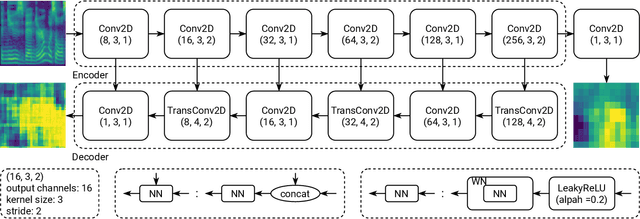
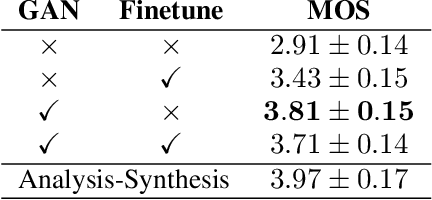
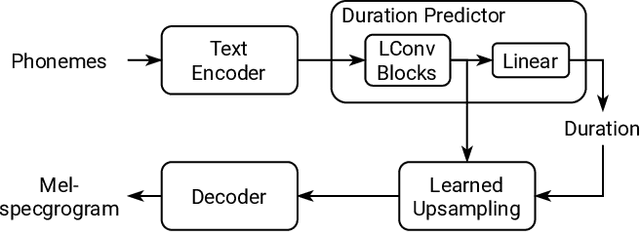

The generative adversarial network (GAN) has shown its outstanding capability in improving Non-Autoregressive TTS (NAR-TTS) by adversarially training it with an extra model that discriminates between the real and the generated speech. To maximize the benefits of GAN, it is crucial to find a powerful discriminator that can capture rich distinguishable information. In this paper, we propose a multi-scale time-frequency spectrogram discriminator to help NAR-TTS generate high-fidelity Mel-spectrograms. It treats the spectrogram as a 2D image to exploit the correlation among different components in the time-frequency domain. And a U-Net-based model structure is employed to discriminate at different scales to capture both coarse-grained and fine-grained information. We conduct subjective tests to evaluate the proposed approach. Both multi-scale and time-frequency discriminating bring significant improvement in the naturalness and fidelity. When combining the neural vocoder, it is shown more effective and concise than fine-tuning the vocoder. Finally, we visualize the discriminating maps to compare their difference to verify the effectiveness of multi-scale discriminating.