 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Few-shot Multimodal Sentiment Analysis based on Multimodal Probabilistic Fusion Prompts
Nov 12, 2022

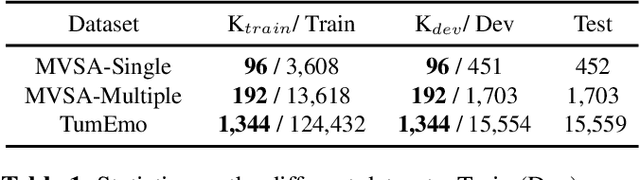
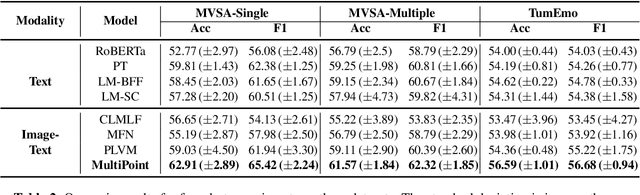
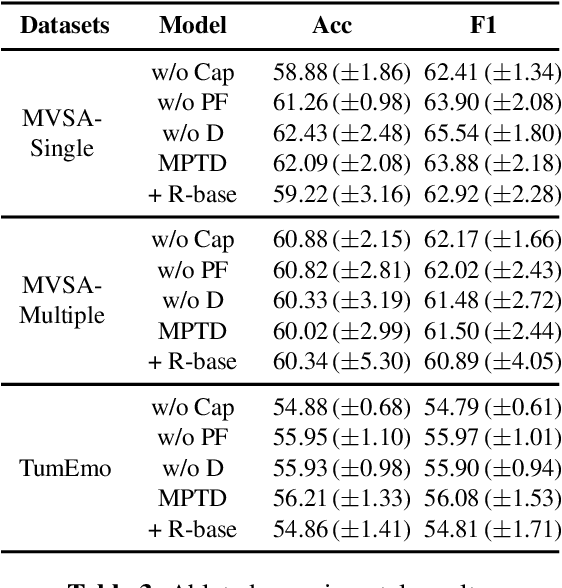
Multimodal sentiment analysis is a trending topic with the explosion of multimodal content on the web. Present studies in multimodal sentiment analysis rely on large-scale supervised data. Collating supervised data is time-consuming and labor-intensive. As such, it is essential to investigate the problem of few-shot multimodal sentiment analysis. Previous works in few-shot models generally use language model prompts, which can improve performance in low-resource settings. However, the textual prompt ignores the information from other modalities. We propose Multimodal Probabilistic Fusion Prompts, which can provide diverse cues for multimodal sentiment detection. We first design a unified multimodal prompt to reduce the discrepancy in different modal prompts. To improve the robustness of our model, we then leverage multiple diverse prompts for each input and propose a probabilistic method to fuse the output predictions. Extensive experiments conducted on three datasets confirm the effectiveness of our approach.
Consecutive Question Generation via Dynamic Multitask Learning
Nov 16, 2022
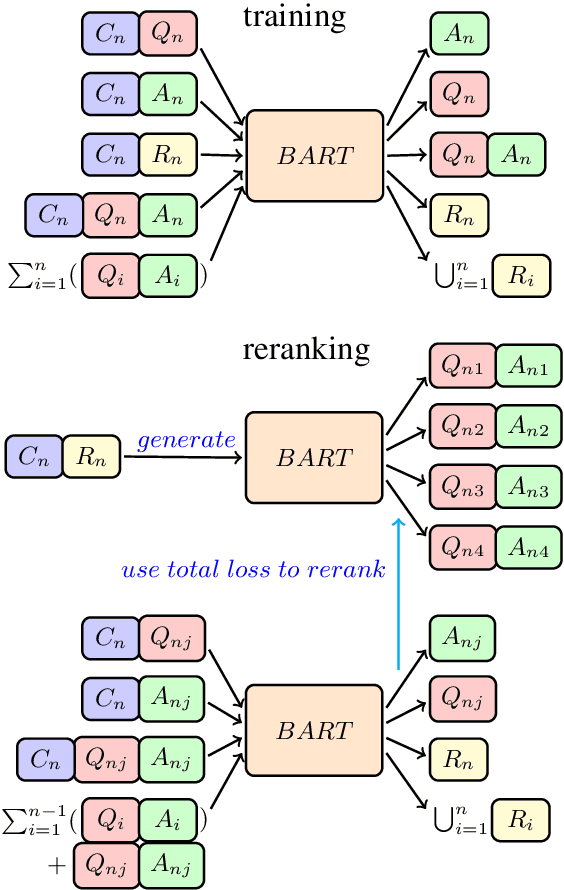

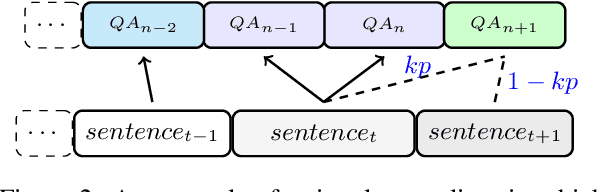
In this paper, we propose the task of consecutive question generation (CQG), which generates a set of logically related question-answer pairs to understand a whole passage, with a comprehensive consideration of the aspects including accuracy, coverage, and informativeness. To achieve this, we first examine the four key elements of CQG, i.e., question, answer, rationale, and context history, and propose a novel dynamic multitask framework with one main task generating a question-answer pair, and four auxiliary tasks generating other elements. It directly helps the model generate good questions through both joint training and self-reranking. At the same time, to fully explore the worth-asking information in a given passage, we make use of the reranking losses to sample the rationales and search for the best question series globally. Finally, we measure our strategy by QA data augmentation and manual evaluation, as well as a novel application of generated question-answer pairs on DocNLI. We prove that our strategy can improve question generation significantly and benefit multiple related NLP tasks.
Deep Emotion Recognition in Textual Conversations: A Survey
Nov 16, 2022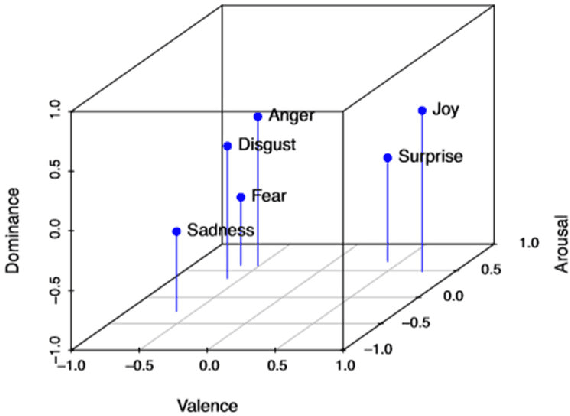

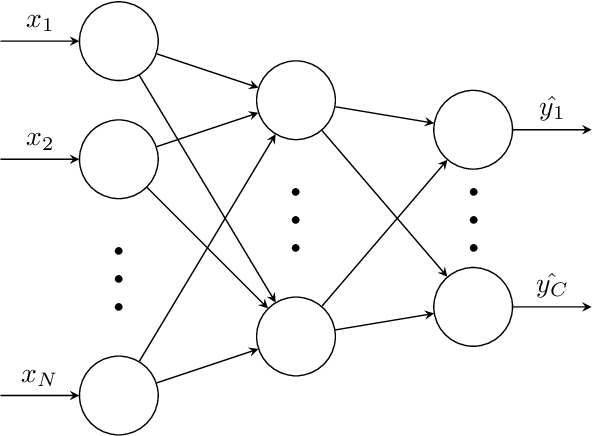
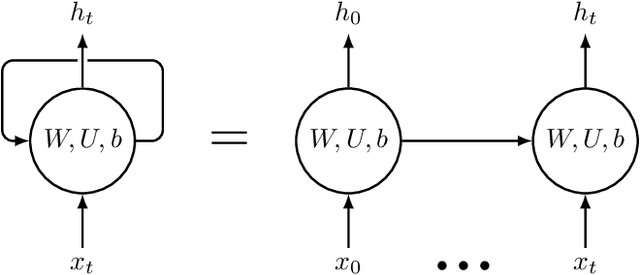
While Emotion Recognition in Conversations (ERC) has seen a tremendous advancement in the last few years, new applications and implementation scenarios present novel challenges and opportunities. These range from leveraging the conversational context, speaker and emotion dynamics modelling, to interpreting common sense expressions, informal language and sarcasm, addressing challenges of real time ERC and recognizing emotion causes. This survey starts by introducing ERC, elaborating on the challenges and opportunities pertaining to this task. It proceeds with a description of the main emotion taxonomies and methods to deal with subjectivity in annotations. It then describes Deep Learning methods relevant for ERC, word embeddings, and elaborates on the use of performance metrics for the task and methods to deal with the typically unbalanced ERC datasets. This is followed by a description and benchmark of key ERC works along with comprehensive tables comparing several works regarding their methods and performance across different datasets. The survey highlights the advantage of leveraging techniques to address unbalanced data, the exploration of mixed emotions and the benefits of incorporating annotation subjectivity in the learning phase.
SWIN-SFTNet : Spatial Feature Expansion and Aggregation using Swin Transformer For Whole Breast micro-mass segmentation
Nov 16, 2022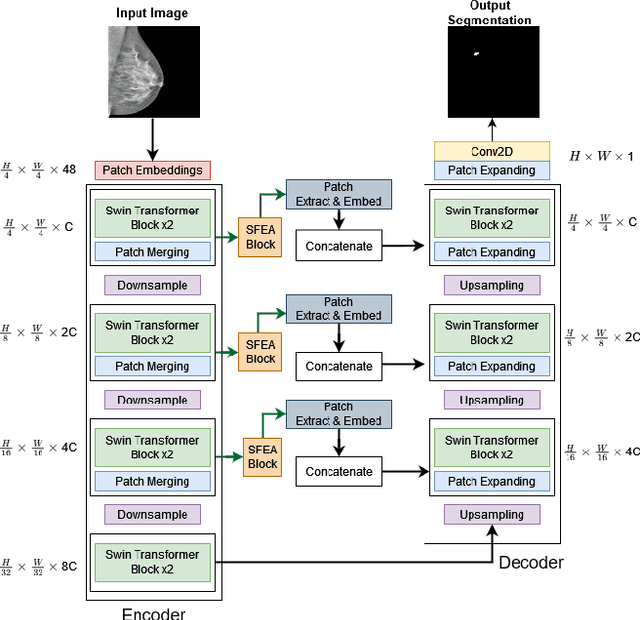
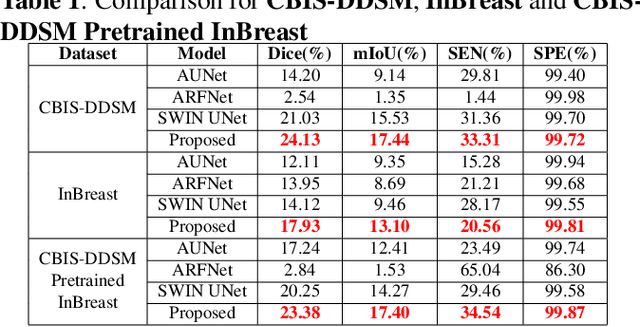
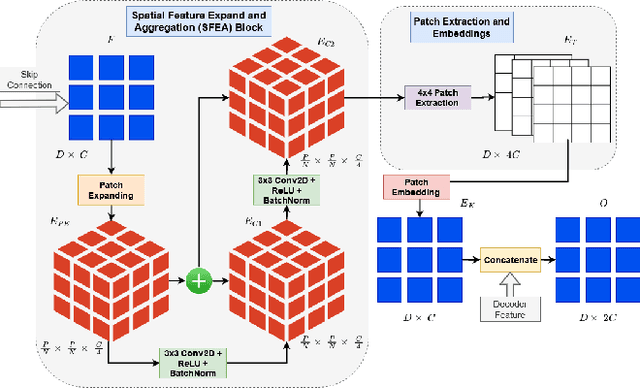

Incorporating various mass shapes and sizes in training deep learning architectures has made breast mass segmentation challenging. Moreover, manual segmentation of masses of irregular shapes is time-consuming and error-prone. Though Deep Neural Network has shown outstanding performance in breast mass segmentation, it fails in segmenting micro-masses. In this paper, we propose a novel U-net-shaped transformer-based architecture, called Swin-SFTNet, that outperforms state-of-the-art architectures in breast mammography-based micro-mass segmentation. Firstly to capture the global context, we designed a novel Spatial Feature Expansion and Aggregation Block(SFEA) that transforms sequential linear patches into a structured spatial feature. Next, we combine it with the local linear features extracted by the swin transformer block to improve overall accuracy. We also incorporate a novel embedding loss that calculates similarities between linear feature embeddings of the encoder and decoder blocks. With this approach, we achieve higher segmentation dice over the state-of-the-art by 3.10% on CBIS-DDSM, 3.81% on InBreast, and 3.13% on CBIS pre-trained model on the InBreast test data set.
Interacting Hand-Object Pose Estimation via Dense Mutual Attention
Nov 16, 2022
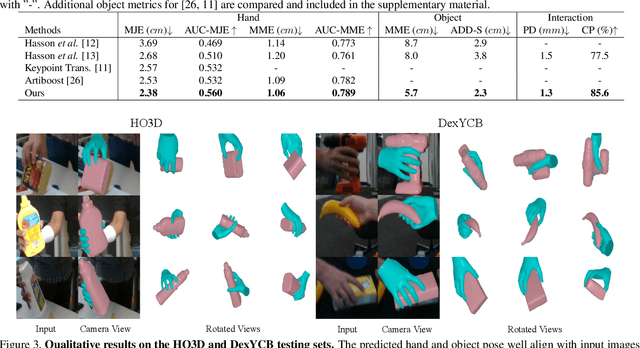
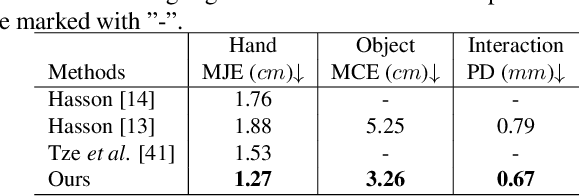
3D hand-object pose estimation is the key to the success of many computer vision applications. The main focus of this task is to effectively model the interaction between the hand and an object. To this end, existing works either rely on interaction constraints in a computationally-expensive iterative optimization, or consider only a sparse correlation between sampled hand and object keypoints. In contrast, we propose a novel dense mutual attention mechanism that is able to model fine-grained dependencies between the hand and the object. Specifically, we first construct the hand and object graphs according to their mesh structures. For each hand node, we aggregate features from every object node by the learned attention and vice versa for each object node. Thanks to such dense mutual attention, our method is able to produce physically plausible poses with high quality and real-time inference speed. Extensive quantitative and qualitative experiments on large benchmark datasets show that our method outperforms state-of-the-art methods. The code is available at https://github.com/rongakowang/DenseMutualAttention.git.
Mention Annotations Alone Enable Efficient Domain Adaptation for Coreference Resolution
Oct 14, 2022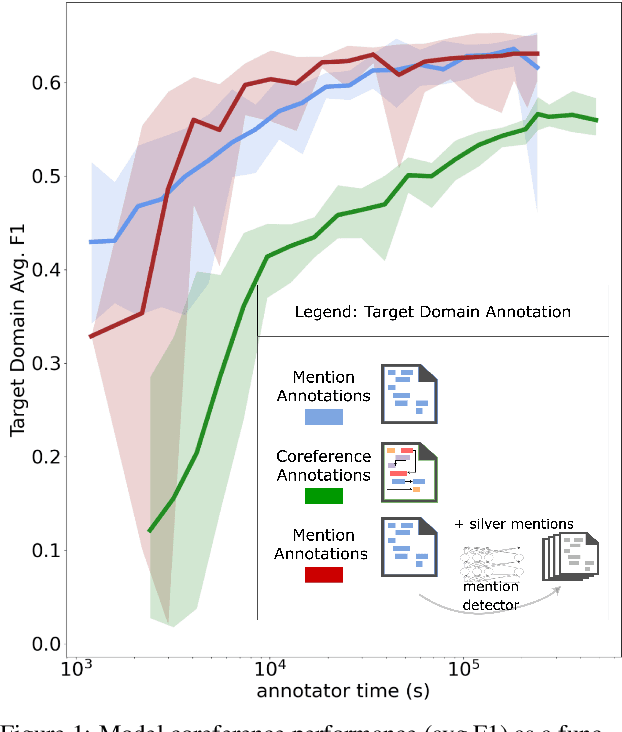

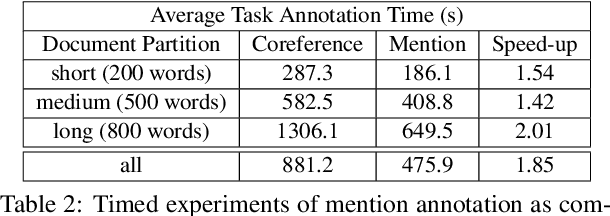
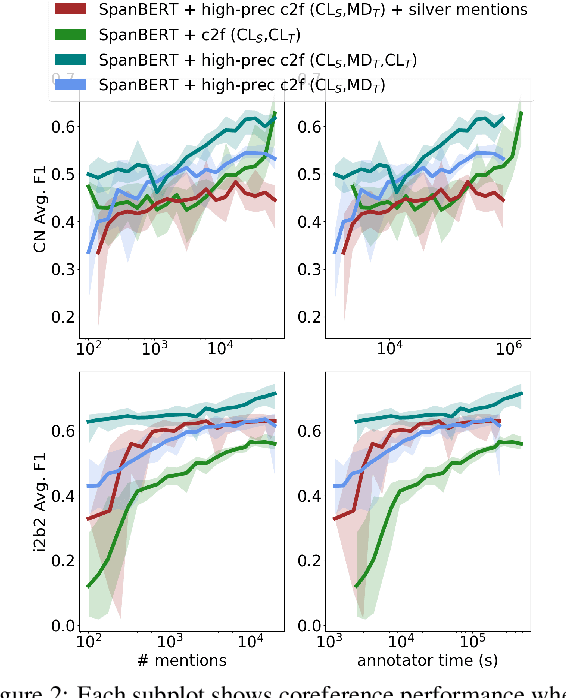
Although, recent advances in neural network models for coreference resolution have led to substantial improvements on benchmark datasets, it remains a challenge to successfully transfer those models to new target domains containing many out-of-vocabulary spans and requiring differing annotation schemes. Typical approaches for domain adaptation involve continued training on coreference annotations in the target domain, but obtaining those annotations is costly and time-consuming. In this work, we show that adapting mention detection is the key component to successful domain adaptation of coreference models, rather than antecedent linking. Through timed annotation experiments, we also show annotating mentions alone is nearly twice as fast as annotating full coreference chains. Based on these insights, we propose a method for effectively adapting coreference models that requires only mention annotations in the target domain. We use an auxiliary mention detection objective trained with mention examples in the target domain resulting in higher mention precision. We demonstrate that our approach facilitates sample- and time-efficient transfer to new annotation schemes and lexicons in extensive evaluation across three English coreference datasets: CoNLL-2012 (news/conversation), i2b2/VA (medical case notes), and a dataset of child welfare case notes. We show that annotating mentions results in 7-14% improvement in average F1 over annotating coreference over an equivalent amount of time.
Covariance-aware Feature Alignment with Pre-computed Source Statistics for Test-time Adaptation
Apr 28, 2022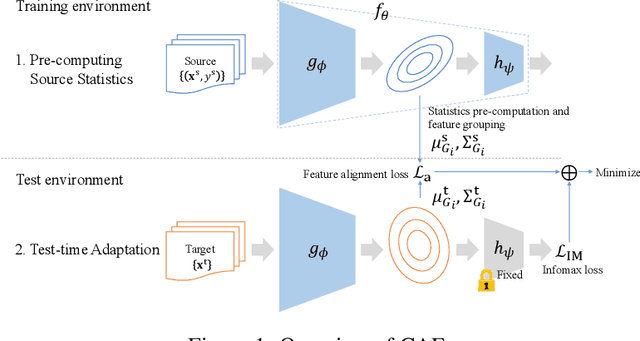
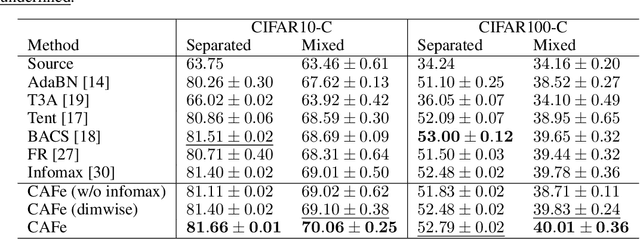
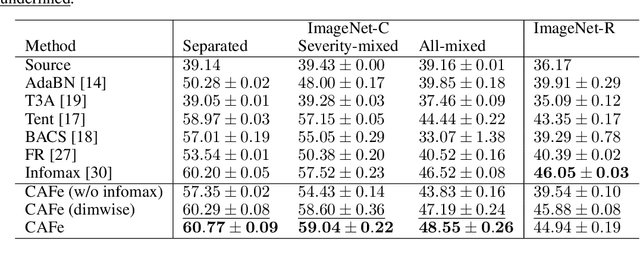
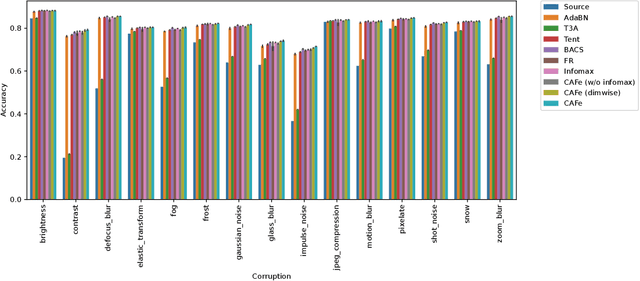
The accuracy of deep neural networks is degraded when the distribution of features in the test environment (target domain) differs from that of the training (source) environment. To mitigate the degradation, test-time adaptation (TTA), where a model adapts to the target domain without access to the source dataset, can be used in the test environment. However, the existing TTA methods lack feature distribution alignment between the source and target domains, which unsupervised domain adaptation mainly addresses, because accessing the source dataset is prohibited in the TTA setting. In this paper, we propose a novel TTA method, named Covariance-Aware Feature alignment (CAFe), which explicitly aligns the source and target feature distributions at test time. To perform alignment without accessing the source data, CAFe uses auxiliary feature statistics (mean and covariance) pre-computed on the source domain, which are lightweight and easily prepared. Further, to improve efficiency and stability, we propose feature grouping, which splits the feature dimensions into groups according to their correlations by using spectral clustering to avoid degeneration of the covariance matrix. We empirically show that CAFe outperforms prior TTA methods on a variety of distribution shifts.
Transformer Inertial Poser: Attention-based Real-time Human Motion Reconstruction from Sparse IMUs
Mar 29, 2022
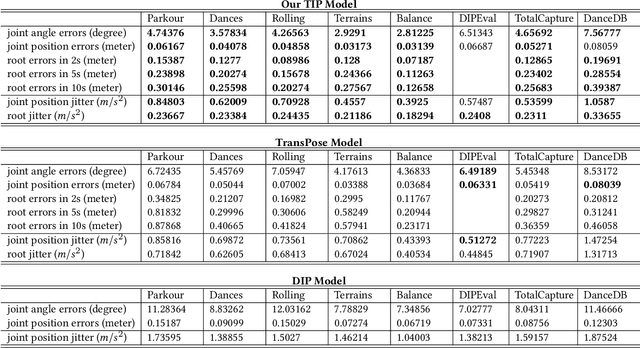
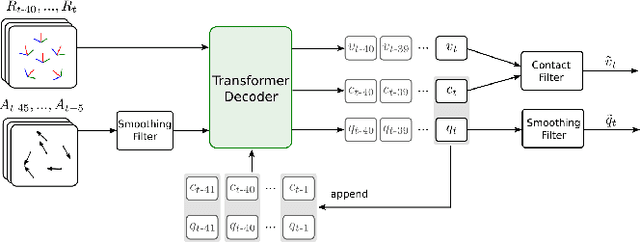
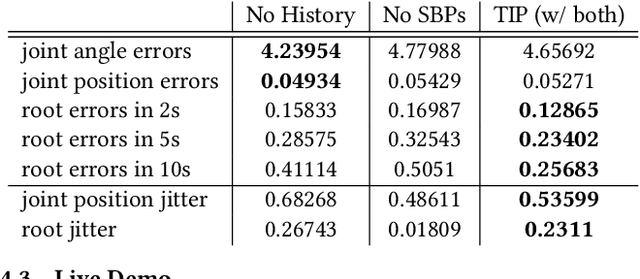
Real-time human motion reconstruction from a sparse set of wearable IMUs provides an non-intrusive and economic approach to motion capture. Without the ability to acquire absolute position information using IMUs, many prior works took data-driven approaches that utilize large human motion datasets to tackle the under-determined nature of the problem. Still, challenges such as temporal consistency, global translation estimation, and diverse coverage of motion or terrain types remain. Inspired by recent success of Transformer models in sequence modeling, we propose an attention-based deep learning method to reconstruct full-body motion from six IMU sensors in real-time. Together with a physics-based learning objective to predict "stationary body points", our method achieves new state-of-the-art results both quantitatively and qualitatively, while being simple to implement and smaller in size. We evaluate our method extensively on synthesized and real IMU data, and with real-time live demos.
There is a Time and Place for Reasoning Beyond the Image
Mar 28, 2022
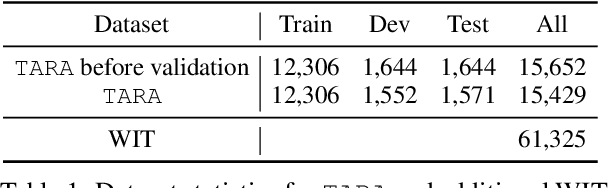

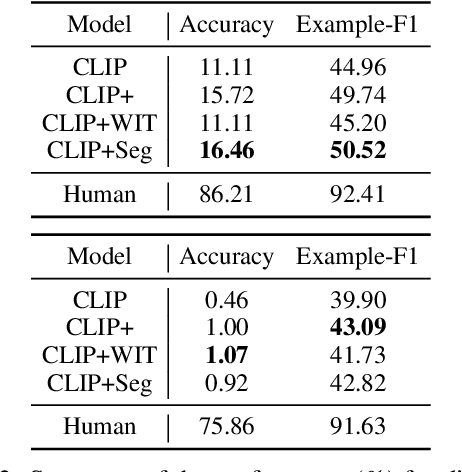
Images are often more significant than only the pixels to human eyes, as we can infer, associate, and reason with contextual information from other sources to establish a more complete picture. For example, in Figure 1, we can find a way to identify the news articles related to the picture through segment-wise understandings of the signs, the buildings, the crowds, and more. This reasoning could provide the time and place the image was taken, which will help us in subsequent tasks, such as automatic storyline construction, correction of image source in intended effect photographs, and upper-stream processing such as image clustering for certain location or time. In this work, we formulate this problem and introduce TARA: a dataset with 16k images with their associated news, time, and location, automatically extracted from New York Times, and an additional 61k examples as distant supervision from WIT. On top of the extractions, we present a crowdsourced subset in which we believe it is possible to find the images' spatio-temporal information for evaluation purpose. We show that there exists a $70\%$ gap between a state-of-the-art joint model and human performance, which is slightly filled by our proposed model that uses segment-wise reasoning, motivating higher-level vision-language joint models that can conduct open-ended reasoning with world knowledge. The data and code are publicly available at https://github.com/zeyofu/TARA.
Learning to Learn: How to Continuously Teach Humans and Machines
Nov 28, 2022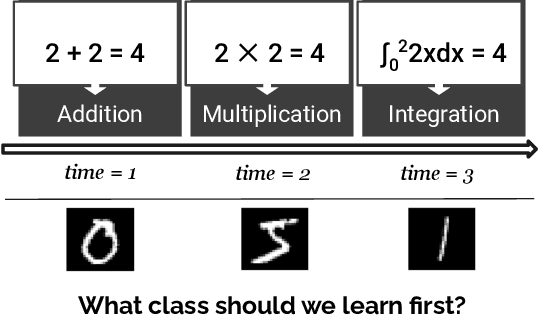
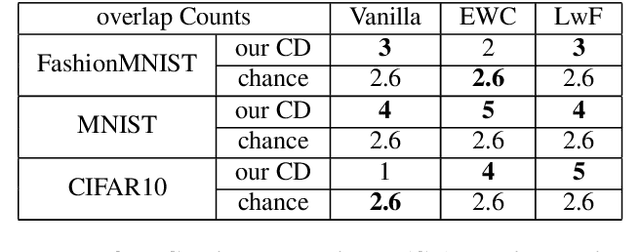
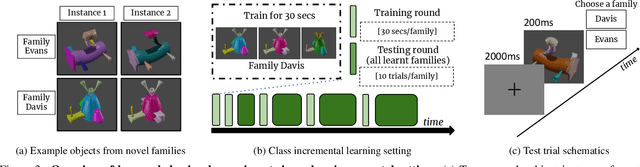
Our education system comprises a series of curricula. For example, when we learn mathematics at school, we learn in order from addition, to multiplication, and later to integration. Delineating a curriculum for teaching either a human or a machine shares the underlying goal of maximizing the positive knowledge transfer from early to later tasks and minimizing forgetting of the early tasks. Here, we exhaustively surveyed the effect of curricula on existing continual learning algorithms in the class-incremental setting, where algorithms must learn classes one at a time from a continuous stream of data. We observed that across a breadth of possible class orders (curricula), curricula influence the retention of information and that this effect is not just a product of stochasticity. Further, as a primary effort toward automated curriculum design, we proposed a method capable of designing and ranking effective curricula based on inter-class feature similarities. We compared the predicted curricula against empirically determined effectual curricula and observed significant overlaps between the two. To support the study of a curriculum designer, we conducted a series of human psychophysics experiments and contributed a new Continual Learning benchmark in object recognition. We assessed the degree of agreement in effective curricula between humans and machines. Surprisingly, our curriculum designer successfully predicts an optimal set of curricula that is effective for human learning. There are many considerations in curriculum design, such as timely student feedback and learning with multiple modalities. Our study is the first attempt to set a standard framework for the community to tackle the problem of teaching humans and machines to learn to learn continuously.