 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoop Closure using AnyLoc Visual Place Recognition in DPV-SLAM
Jan 06, 2026Loop closure is crucial for maintaining the accuracy and consistency of visual SLAM. We propose a method to improve loop closure performance in DPV-SLAM. Our approach integrates AnyLoc, a learning-based visual place recognition technique, as a replacement for the classical Bag of Visual Words (BoVW) loop detection method. In contrast to BoVW, which relies on handcrafted features, AnyLoc utilizes deep feature representations, enabling more robust image retrieval across diverse viewpoints and lighting conditions. Furthermore, we propose an adaptive mechanism that dynamically adjusts similarity threshold based on environmental conditions, removing the need for manual tuning. Experiments on both indoor and outdoor datasets demonstrate that our method significantly outperforms the original DPV-SLAM in terms of loop closure accuracy and robustness. The proposed method offers a practical and scalable solution for enhancing loop closure performance in modern SLAM systems.
Uniformity First: Uniformity-aware Test-time Adaptation of Vision-language Models against Image Corruption
May 19, 2025Pre-trained vision-language models such as contrastive language-image pre-training (CLIP) have demonstrated a remarkable generalizability, which has enabled a wide range of applications represented by zero-shot classification. However, vision-language models still suffer when they face datasets with large gaps from training ones, i.e., distribution shifts. We found that CLIP is especially vulnerable to sensor degradation, a type of realistic distribution shift caused by sensor conditions such as weather, light, or noise. Collecting a new dataset from a test distribution for fine-tuning highly costs since sensor degradation occurs unexpectedly and has a range of variety. Thus, we investigate test-time adaptation (TTA) of zero-shot classification, which enables on-the-fly adaptation to the test distribution with unlabeled test data. Existing TTA methods for CLIP mainly focus on modifying image and text embeddings or predictions to address distribution shifts. Although these methods can adapt to domain shifts, such as fine-grained labels spaces or different renditions in input images, they fail to adapt to distribution shifts caused by sensor degradation. We found that this is because image embeddings are "corrupted" in terms of uniformity, a measure related to the amount of information. To make models robust to sensor degradation, we propose a novel method called uniformity-aware information-balanced TTA (UnInfo). To address the corruption of image embeddings, we introduce uniformity-aware confidence maximization, information-aware loss balancing, and knowledge distillation from the exponential moving average (EMA) teacher. Through experiments, we demonstrate that our UnInfo improves accuracy under sensor degradation by retaining information in terms of uniformity.
Post-pre-training for Modality Alignment in Vision-Language Foundation Models
Apr 17, 2025



Contrastive language image pre-training (CLIP) is an essential component of building modern vision-language foundation models. While CLIP demonstrates remarkable zero-shot performance on downstream tasks, the multi-modal feature spaces still suffer from a modality gap, which is a gap between image and text feature clusters and limits downstream task performance. Although existing works attempt to address the modality gap by modifying pre-training or fine-tuning, they struggle with heavy training costs with large datasets or degradations of zero-shot performance. This paper presents CLIP-Refine, a post-pre-training method for CLIP models at a phase between pre-training and fine-tuning. CLIP-Refine aims to align the feature space with 1 epoch training on small image-text datasets without zero-shot performance degradations. To this end, we introduce two techniques: random feature alignment (RaFA) and hybrid contrastive-distillation (HyCD). RaFA aligns the image and text features to follow a shared prior distribution by minimizing the distance to random reference vectors sampled from the prior. HyCD updates the model with hybrid soft labels generated by combining ground-truth image-text pair labels and outputs from the pre-trained CLIP model. This contributes to achieving both maintaining the past knowledge and learning new knowledge to align features. Our extensive experiments with multiple classification and retrieval tasks show that CLIP-Refine succeeds in mitigating the modality gap and improving the zero-shot performance.
Test-time Adaptation for Regression by Subspace Alignment
Oct 04, 2024



This paper investigates test-time adaptation (TTA) for regression, where a regression model pre-trained in a source domain is adapted to an unknown target distribution with unlabeled target data. Although regression is one of the fundamental tasks in machine learning, most of the existing TTA methods have classification-specific designs, which assume that models output class-categorical predictions, whereas regression models typically output only single scalar values. To enable TTA for regression, we adopt a feature alignment approach, which aligns the feature distributions between the source and target domains to mitigate the domain gap. However, we found that naive feature alignment employed in existing TTA methods for classification is ineffective or even worse for regression because the features are distributed in a small subspace and many of the raw feature dimensions have little significance to the output. For an effective feature alignment in TTA for regression, we propose Significant-subspace Alignment (SSA). SSA consists of two components: subspace detection and dimension weighting. Subspace detection finds the feature subspace that is representative and significant to the output. Then, the feature alignment is performed in the subspace during TTA. Meanwhile, dimension weighting raises the importance of the dimensions of the feature subspace that have greater significance to the output. We experimentally show that SSA outperforms various baselines on real-world datasets.
Evaluating Time-Series Training Dataset through Lens of Spectrum in Deep State Space Models
Aug 29, 2024



This study investigates a method to evaluate time-series datasets in terms of the performance of deep neural networks (DNNs) with state space models (deep SSMs) trained on the dataset. SSMs have attracted attention as components inside DNNs to address time-series data. Since deep SSMs have powerful representation capacities, training datasets play a crucial role in solving a new task. However, the effectiveness of training datasets cannot be known until deep SSMs are actually trained on them. This can increase the cost of data collection for new tasks, as a trial-and-error process of data collection and time-consuming training are needed to achieve the necessary performance. To advance the practical use of deep SSMs, the metric of datasets to estimate the performance early in the training can be one key element. To this end, we introduce the concept of data evaluation methods used in system identification. In system identification of linear dynamical systems, the effectiveness of datasets is evaluated by using the spectrum of input signals. We introduce this concept to deep SSMs, which are nonlinear dynamical systems. We propose the K-spectral metric, which is the sum of the top-K spectra of signals inside deep SSMs, by focusing on the fact that each layer of a deep SSM can be regarded as a linear dynamical system. Our experiments show that the K-spectral metric has a large absolute value of the correlation coefficient with the performance and can be used to evaluate the quality of training datasets.
Test-time Adaptation Meets Image Enhancement: Improving Accuracy via Uncertainty-aware Logit Switching
Mar 26, 2024



Deep neural networks have achieved remarkable success in a variety of computer vision applications. However, there is a problem of degrading accuracy when the data distribution shifts between training and testing. As a solution of this problem, Test-time Adaptation~(TTA) has been well studied because of its practicality. Although TTA methods increase accuracy under distribution shift by updating the model at test time, using high-uncertainty predictions is known to degrade accuracy. Since the input image is the root of the distribution shift, we incorporate a new perspective on enhancing the input image into TTA methods to reduce the prediction's uncertainty. We hypothesize that enhancing the input image reduces prediction's uncertainty and increase the accuracy of TTA methods. On the basis of our hypothesis, we propose a novel method: Test-time Enhancer and Classifier Adaptation~(TECA). In TECA, the classification model is combined with the image enhancement model that transforms input images into recognition-friendly ones, and these models are updated by existing TTA methods. Furthermore, we found that the prediction from the enhanced image does not always have lower uncertainty than the prediction from the original image. Thus, we propose logit switching, which compares the uncertainty measure of these predictions and outputs the lower one. In our experiments, we evaluate TECA with various TTA methods and show that TECA reduces prediction's uncertainty and increases accuracy of TTA methods despite having no hyperparameters and little parameter overhead.
Test-time Similarity Modification for Person Re-identification toward Temporal Distribution Shift
Mar 21, 2024



Person re-identification (re-id), which aims to retrieve images of the same person in a given image from a database, is one of the most practical image recognition applications. In the real world, however, the environments that the images are taken from change over time. This causes a distribution shift between training and testing and degrades the performance of re-id. To maintain re-id performance, models should continue adapting to the test environment's temporal changes. Test-time adaptation (TTA), which aims to adapt models to the test environment with only unlabeled test data, is a promising way to handle this problem because TTA can adapt models instantly in the test environment. However, the previous TTA methods are designed for classification and cannot be directly applied to re-id. This is because the set of people's identities in the dataset differs between training and testing in re-id, whereas the set of classes is fixed in the current TTA methods designed for classification. To improve re-id performance in changing test environments, we propose TEst-time similarity Modification for Person re-identification (TEMP), a novel TTA method for re-id. TEMP is the first fully TTA method for re-id, which does not require any modification to pre-training. Inspired by TTA methods that refine the prediction uncertainty in classification, we aim to refine the uncertainty in re-id. However, the uncertainty cannot be computed in the same way as classification in re-id since it is an open-set task, which does not share person labels between training and testing. Hence, we propose re-id entropy, an alternative uncertainty measure for re-id computed based on the similarity between the feature vectors. Experiments show that the re-id entropy can measure the uncertainty on re-id and TEMP improves the performance of re-id in online settings where the distribution changes over time.
Adaptive Random Feature Regularization on Fine-tuning Deep Neural Networks
Mar 15, 2024While fine-tuning is a de facto standard method for training deep neural networks, it still suffers from overfitting when using small target datasets. Previous methods improve fine-tuning performance by maintaining knowledge of the source datasets or introducing regularization terms such as contrastive loss. However, these methods require auxiliary source information (e.g., source labels or datasets) or heavy additional computations. In this paper, we propose a simple method called adaptive random feature regularization (AdaRand). AdaRand helps the feature extractors of training models to adaptively change the distribution of feature vectors for downstream classification tasks without auxiliary source information and with reasonable computation costs. To this end, AdaRand minimizes the gap between feature vectors and random reference vectors that are sampled from class conditional Gaussian distributions. Furthermore, AdaRand dynamically updates the conditional distribution to follow the currently updated feature extractors and balance the distance between classes in feature spaces. Our experiments show that AdaRand outperforms the other fine-tuning regularization, which requires auxiliary source information and heavy computation costs.
Fast Regularized Discrete Optimal Transport with Group-Sparse Regularizers
Mar 14, 2023



Regularized discrete optimal transport (OT) is a powerful tool to measure the distance between two discrete distributions that have been constructed from data samples on two different domains. While it has a wide range of applications in machine learning, in some cases the sampled data from only one of the domains will have class labels such as unsupervised domain adaptation. In this kind of problem setting, a group-sparse regularizer is frequently leveraged as a regularization term to handle class labels. In particular, it can preserve the label structure on the data samples by corresponding the data samples with the same class label to one group-sparse regularization term. As a result, we can measure the distance while utilizing label information by solving the regularized optimization problem with gradient-based algorithms. However, the gradient computation is expensive when the number of classes or data samples is large because the number of regularization terms and their respective sizes also turn out to be large. This paper proposes fast discrete OT with group-sparse regularizers. Our method is based on two ideas. The first is to safely skip the computations of the gradients that must be zero. The second is to efficiently extract the gradients that are expected to be nonzero. Our method is guaranteed to return the same value of the objective function as that of the original method. Experiments show that our method is up to 8.6 times faster than the original method without degrading accuracy.
Covariance-aware Feature Alignment with Pre-computed Source Statistics for Test-time Adaptation
Apr 28, 2022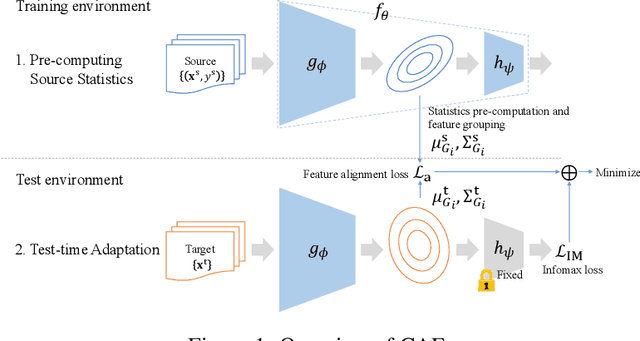
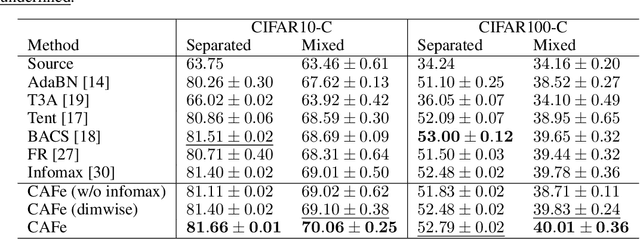
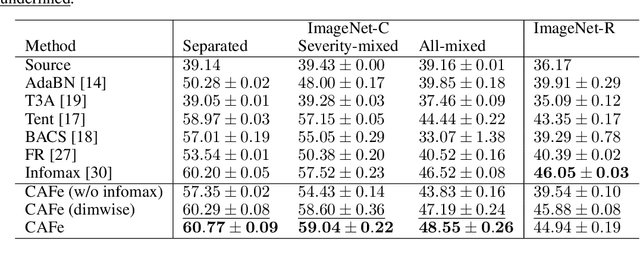
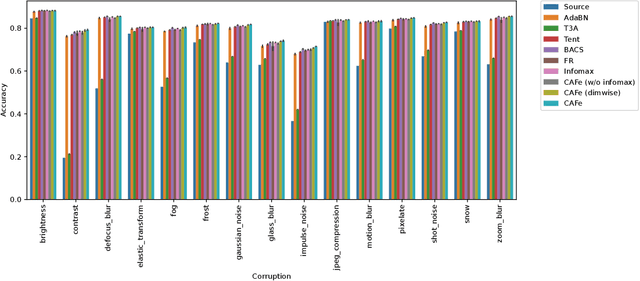
The accuracy of deep neural networks is degraded when the distribution of features in the test environment (target domain) differs from that of the training (source) environment. To mitigate the degradation, test-time adaptation (TTA), where a model adapts to the target domain without access to the source dataset, can be used in the test environment. However, the existing TTA methods lack feature distribution alignment between the source and target domains, which unsupervised domain adaptation mainly addresses, because accessing the source dataset is prohibited in the TTA setting. In this paper, we propose a novel TTA method, named Covariance-Aware Feature alignment (CAFe), which explicitly aligns the source and target feature distributions at test time. To perform alignment without accessing the source data, CAFe uses auxiliary feature statistics (mean and covariance) pre-computed on the source domain, which are lightweight and easily prepared. Further, to improve efficiency and stability, we propose feature grouping, which splits the feature dimensions into groups according to their correlations by using spectral clustering to avoid degeneration of the covariance matrix. We empirically show that CAFe outperforms prior TTA methods on a variety of distribution shifts.