 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Perching on Moving Inclined Surfaces using Uncertainty Tolerant Planner and Thrust Regulation
Dec 21, 2022
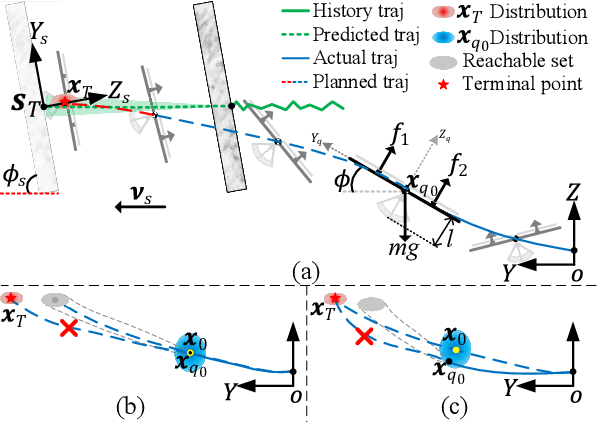
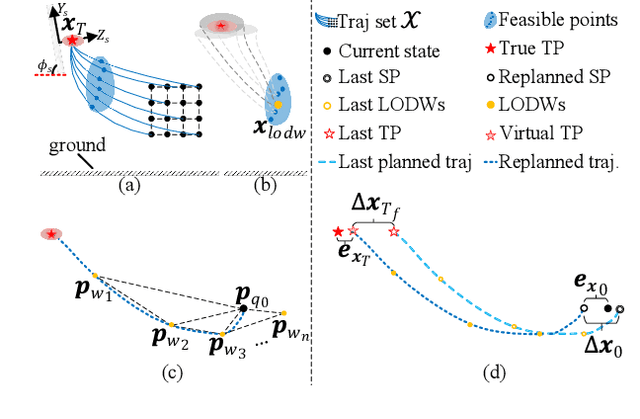
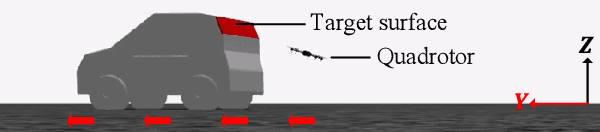
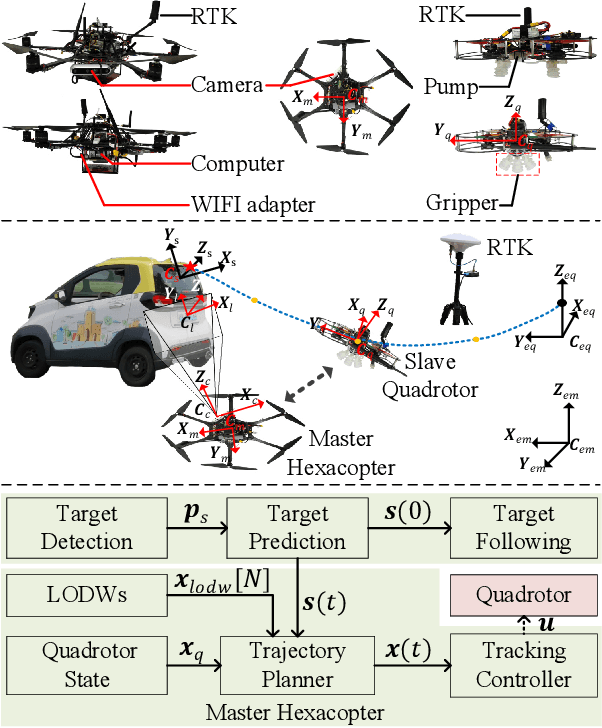
Quadrotors with the ability to perch on moving inclined surfaces can save energy and extend their travel distance by leveraging ground vehicles. Achieving dynamic perching places high demands on the performance of trajectory planning and terminal state accuracy in SE(3). However, in the perching process, uncertainties in target surface prediction, tracking control and external disturbances may cause trajectory planning failure or lead to unacceptable terminal errors. To address these challenges, we first propose a trajectory planner that considers adaptation to uncertainties in target prediction and tracking control. To facilitate this work, the reachable set of quadrotors' states is first analyzed. The states whose reachable sets possess the largest coverage probability for uncertainty targets, are defined as optimal waypoints. Subsequently, an approach to seek local optimal waypoints for static and moving uncertainty targets is proposed. A real-time trajectory planner based on optimized waypoints is developed accordingly. Secondly, thrust regulation is also implemented in the terminal attitude tracking stage to handle external disturbances. When a quadrotor's attitude is commanded to align with target surfaces, the thrust is optimized to minimize terminal errors. This makes the terminal position and velocity be controlled in closed-loop manner. Therefore, the resistance to disturbances and terminal accuracy is improved. Extensive simulation experiments demonstrate that our methods can improve the accuracy of terminal states under uncertainties. The success rate is approximately increased by $50\%$ compared to the two-end planner without thrust regulation. Perching on the rear window of a car is also achieved using our proposed heterogeneous cooperation system outdoors. This validates the feasibility and practicality of our methods.
Neural networks: solving the chemistry of the interstellar medium
Nov 28, 2022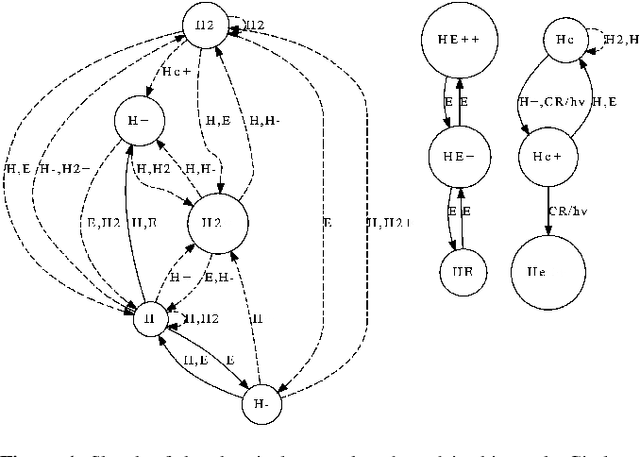
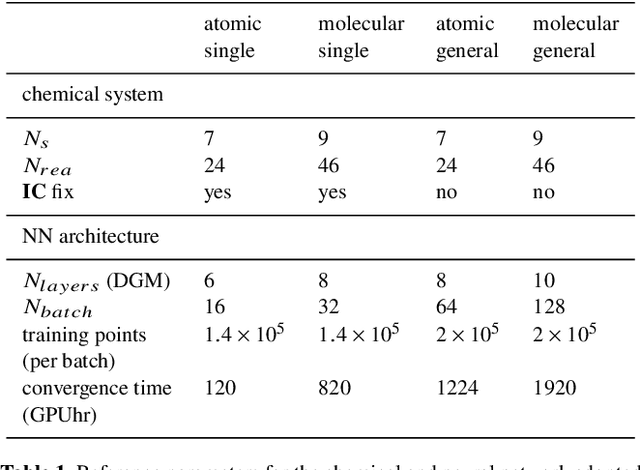
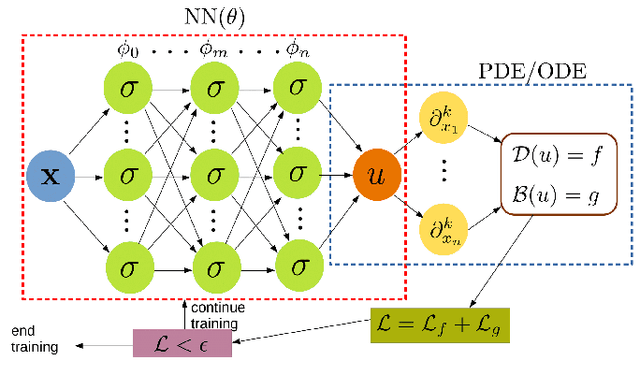
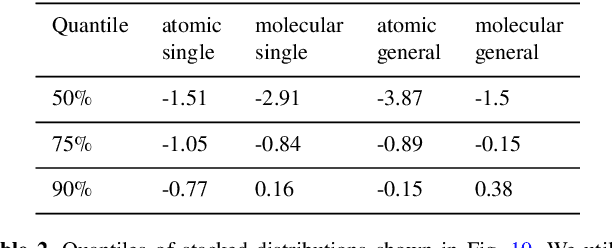
Non-equilibrium chemistry is a key process in the study of the InterStellar Medium (ISM), in particular the formation of molecular clouds and thus stars. However, computationally it is among the most difficult tasks to include in astrophysical simulations, because of the typically high (>40) number of reactions, the short evolutionary timescales (about $10^4$ times less than the ISM dynamical time) and the characteristic non-linearity and stiffness of the associated Ordinary Differential Equations system (ODEs). In this proof of concept work, we show that Physics Informed Neural Networks (PINN) are a viable alternative to traditional ODE time integrators for stiff thermo-chemical systems, i.e. up to molecular hydrogen formation (9 species and 46 reactions). Testing different chemical networks in a wide range of densities ($-2< \log n/{\rm cm}^{-3}< 3$) and temperatures ($1 < \log T/{\rm K}< 5$), we find that a basic architecture can give a comfortable convergence only for simplified chemical systems: to properly capture the sudden chemical and thermal variations a Deep Galerkin Method is needed. Once trained ($\sim 10^3$ GPUhr), the PINN well reproduces the strong non-linear nature of the solutions (errors $\lesssim 10\%$) and can give speed-ups up to a factor of $\sim 200$ with respect to traditional ODE solvers. Further, the latter have completion times that vary by about $\sim 30\%$ for different initial $n$ and $T$, while the PINN method gives negligible variations. Both the speed-up and the potential improvement in load balancing imply that PINN-powered simulations are a very palatable way to solve complex chemical calculation in astrophysical and cosmological problems.
Learning Label Initialization for Time-Dependent Harmonic Extension
May 03, 2022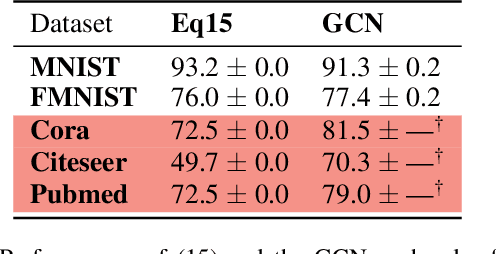
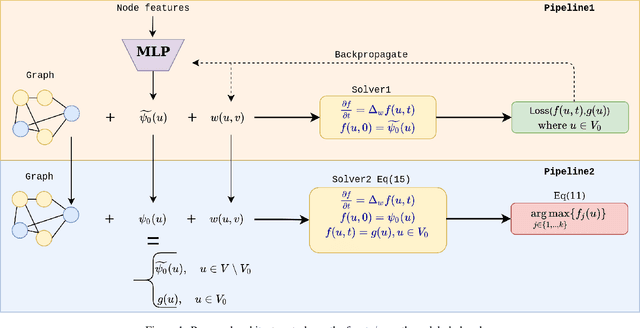
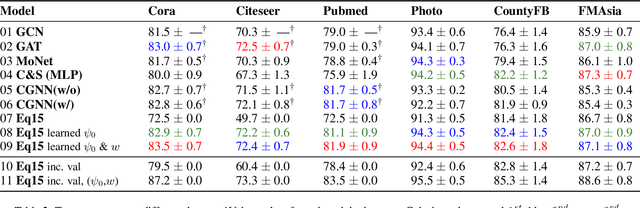
Node classification on graphs can be formulated as the Dirichlet problem on graphs where the signal is given at the labeled nodes, and the harmonic extension is done on the unlabeled nodes. This paper considers a time-dependent version of the Dirichlet problem on graphs and shows how to improve its solution by learning the proper initialization vector on the unlabeled nodes. Further, we show that the improved solution is at par with state-of-the-art methods used for node classification. Finally, we conclude this paper by discussing the importance of parameter t, pros, and future directions.
Lattice-Free Sequence Discriminative Training for Phoneme-Based Neural Transducers
Dec 07, 2022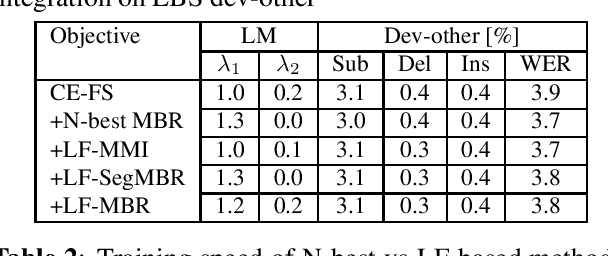
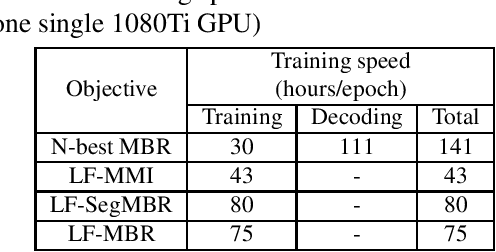
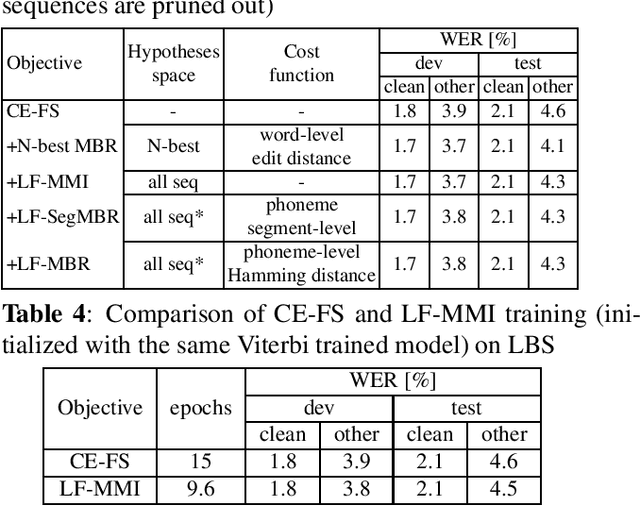
Recently, RNN-Transducers have achieved remarkable results on various automatic speech recognition tasks. However, lattice-free sequence discriminative training methods, which obtain superior performance in hybrid modes, are rarely investigated in RNN-Transducers. In this work, we propose three lattice-free training objectives, namely lattice-free maximum mutual information, lattice-free segment-level minimum Bayes risk, and lattice-free minimum Bayes risk, which are used for the final posterior output of the phoneme-based neural transducer with a limited context dependency. Compared to criteria using N-best lists, lattice-free methods eliminate the decoding step for hypotheses generation during training, which leads to more efficient training. Experimental results show that lattice-free methods gain up to 6.5% relative improvement in word error rate compared to a sequence-level cross-entropy trained model. Compared to the N-best-list based minimum Bayes risk objectives, lattice-free methods gain 40% - 70% relative training time speedup with a small degradation in performance.
Towards Generalization on Real Domain for Single Image Dehazing via Meta-Learning
Nov 14, 2022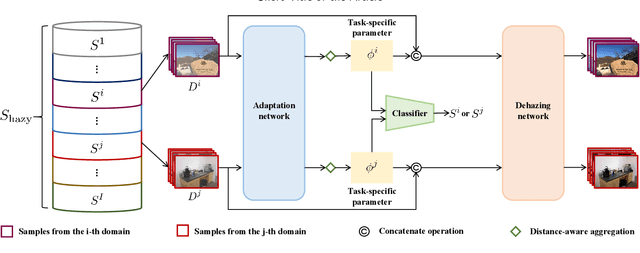

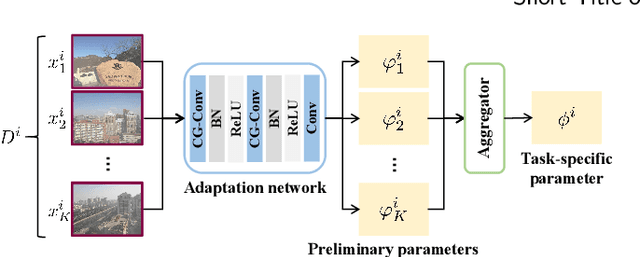
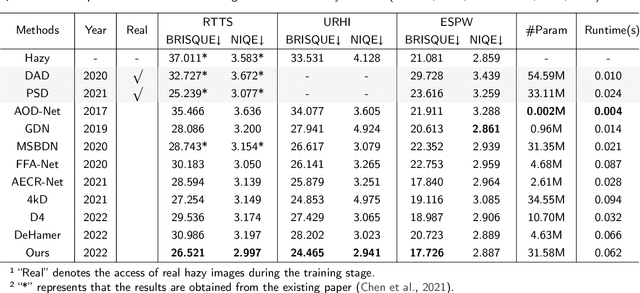
Learning-based image dehazing methods are essential to assist autonomous systems in enhancing reliability. Due to the domain gap between synthetic and real domains, the internal information learned from synthesized images is usually sub-optimal in real domains, leading to severe performance drop of dehaizing models. Driven by the ability on exploring internal information from a few unseen-domain samples, meta-learning is commonly adopted to address this issue via test-time training, which is hyperparameter-sensitive and time-consuming. In contrast, we present a domain generalization framework based on meta-learning to dig out representative and discriminative internal properties of real hazy domains without test-time training. To obtain representative domain-specific information, we attach two entities termed adaptation network and distance-aware aggregator to our dehazing network. The adaptation network assists in distilling domain-relevant information from a few hazy samples and caching it into a collection of features. The distance-aware aggregator strives to summarize the generated features and filter out misleading information for more representative internal properties. To enhance the discrimination of distilled internal information, we present a novel loss function called domain-relevant contrastive regularization, which encourages the internal features generated from the same domain more similar and that from diverse domains more distinct. The generated representative and discriminative features are regarded as some external variables of our dehazing network to regress a particular and powerful function for a given domain. The extensive experiments on real hazy datasets, such as RTTS and URHI, validate that our proposed method has superior generalization ability than the state-of-the-art competitors.
Feature Engineering vs BERT on Twitter Data
Oct 28, 2022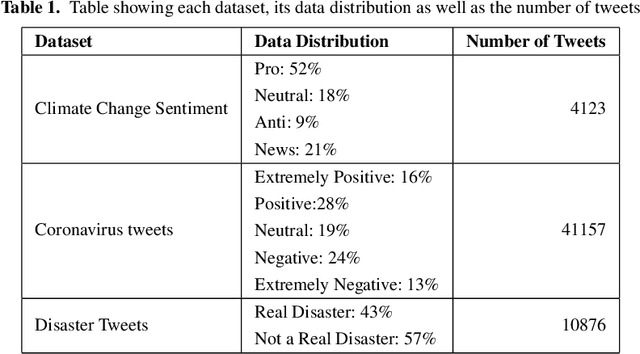

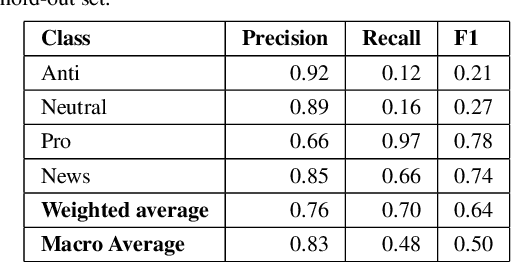
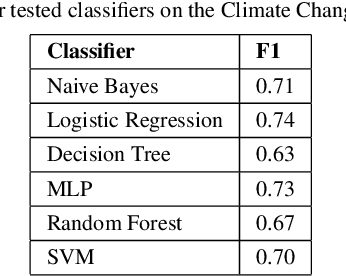
In this paper, we compare the performances of traditional machine learning models using feature engineering and word vectors and the state-of-the-art language model BERT using word embeddings on three datasets. We also consider the time and cost efficiency of feature engineering compared to BERT. From our results we conclude that the use of the BERT model was only worth the time and cost trade-off for one of the three datasets we used for comparison, where the BERT model significantly outperformed any kind of traditional classifier that uses feature vectors, instead of embeddings. Using the BERT model for the other datasets only achieved an increase of 0.03 and 0.05 of accuracy and F1 score respectively, which could be argued makes its use not worth the time and cost of GPU.
A Dataset for Hyper-Relational Extraction and a Cube-Filling Approach
Nov 18, 2022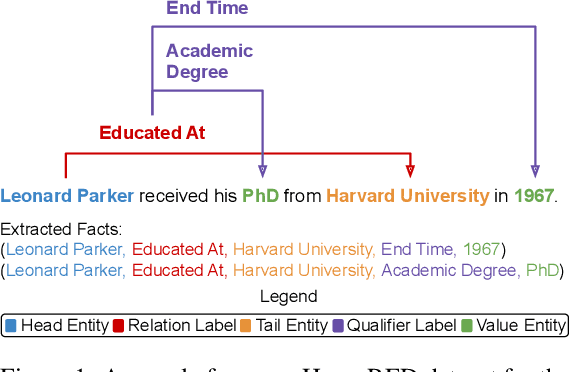
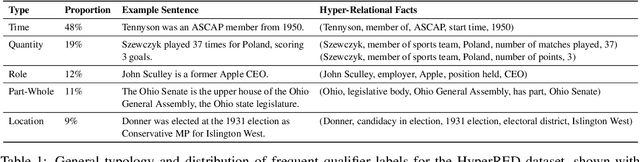
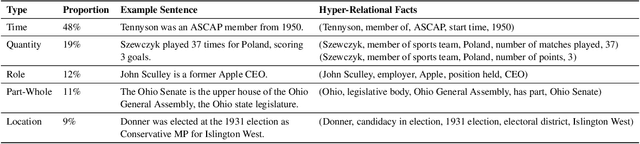
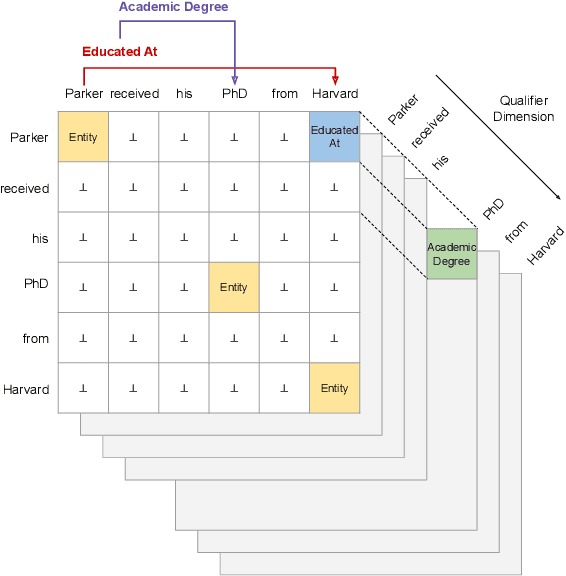
Relation extraction has the potential for large-scale knowledge graph construction, but current methods do not consider the qualifier attributes for each relation triplet, such as time, quantity or location. The qualifiers form hyper-relational facts which better capture the rich and complex knowledge graph structure. For example, the relation triplet (Leonard Parker, Educated At, Harvard University) can be factually enriched by including the qualifier (End Time, 1967). Hence, we propose the task of hyper-relational extraction to extract more specific and complete facts from text. To support the task, we construct HyperRED, a large-scale and general-purpose dataset. Existing models cannot perform hyper-relational extraction as it requires a model to consider the interaction between three entities. Hence, we propose CubeRE, a cube-filling model inspired by table-filling approaches and explicitly considers the interaction between relation triplets and qualifiers. To improve model scalability and reduce negative class imbalance, we further propose a cube-pruning method. Our experiments show that CubeRE outperforms strong baselines and reveal possible directions for future research. Our code and data are available at github.com/declare-lab/HyperRED.
Intrusion Detection in Internet of Things using Convolutional Neural Networks
Nov 18, 2022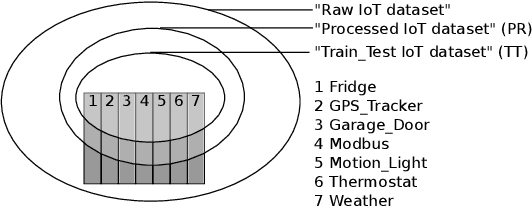
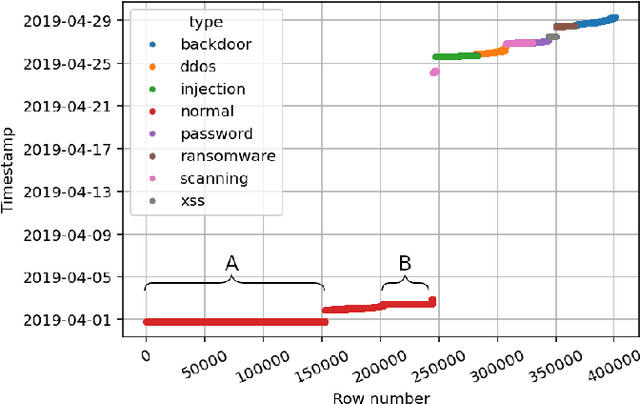
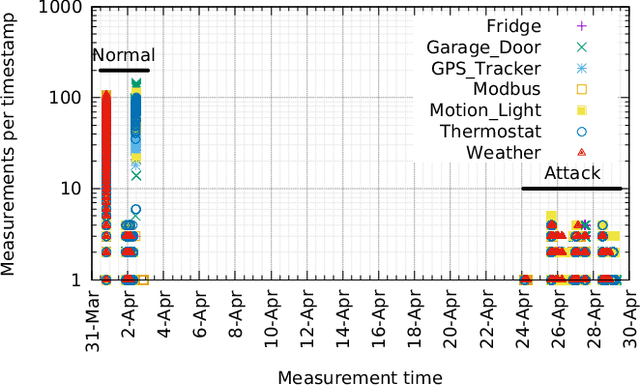
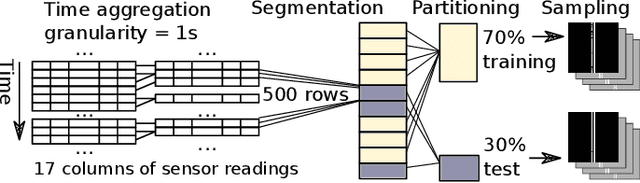
Internet of Things (IoT) has become a popular paradigm to fulfil needs of the industry such as asset tracking, resource monitoring and automation. As security mechanisms are often neglected during the deployment of IoT devices, they are more easily attacked by complicated and large volume intrusion attacks using advanced techniques. Artificial Intelligence (AI) has been used by the cyber security community in the past decade to automatically identify such attacks. However, deep learning methods have yet to be extensively explored for Intrusion Detection Systems (IDS) specifically for IoT. Most recent works are based on time sequential models like LSTM and there is short of research in CNNs as they are not naturally suited for this problem. In this article, we propose a novel solution to the intrusion attacks against IoT devices using CNNs. The data is encoded as the convolutional operations to capture the patterns from the sensors data along time that are useful for attacks detection by CNNs. The proposed method is integrated with two classical CNNs: ResNet and EfficientNet, where the detection performance is evaluated. The experimental results show significant improvement in both true positive rate and false positive rate compared to the baseline using LSTM.
* Keywords: Cybersecurity, Intrusion Detection, IoT, Deep Learning, Convolutional Neural Networks; https://ieeexplore.ieee.org/abstract/document/9647828
Attack on Unfair ToS Clause Detection: A Case Study using Universal Adversarial Triggers
Nov 28, 2022
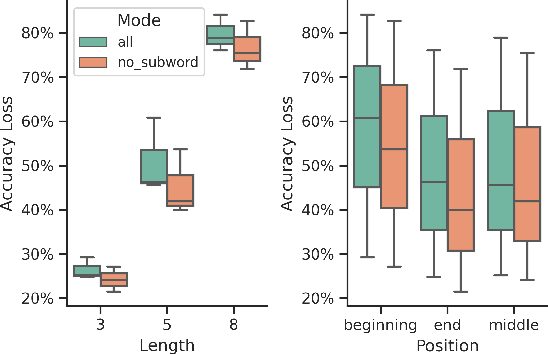
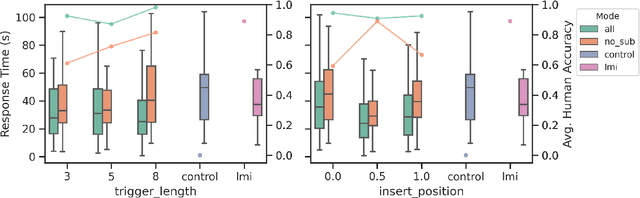
Recent work has demonstrated that natural language processing techniques can support consumer protection by automatically detecting unfair clauses in the Terms of Service (ToS) Agreement. This work demonstrates that transformer-based ToS analysis systems are vulnerable to adversarial attacks. We conduct experiments attacking an unfair-clause detector with universal adversarial triggers. Experiments show that a minor perturbation of the text can considerably reduce the detection performance. Moreover, to measure the detectability of the triggers, we conduct a detailed human evaluation study by collecting both answer accuracy and response time from the participants. The results show that the naturalness of the triggers remains key to tricking readers.
Pangu-Weather: A 3D High-Resolution Model for Fast and Accurate Global Weather Forecast
Nov 03, 2022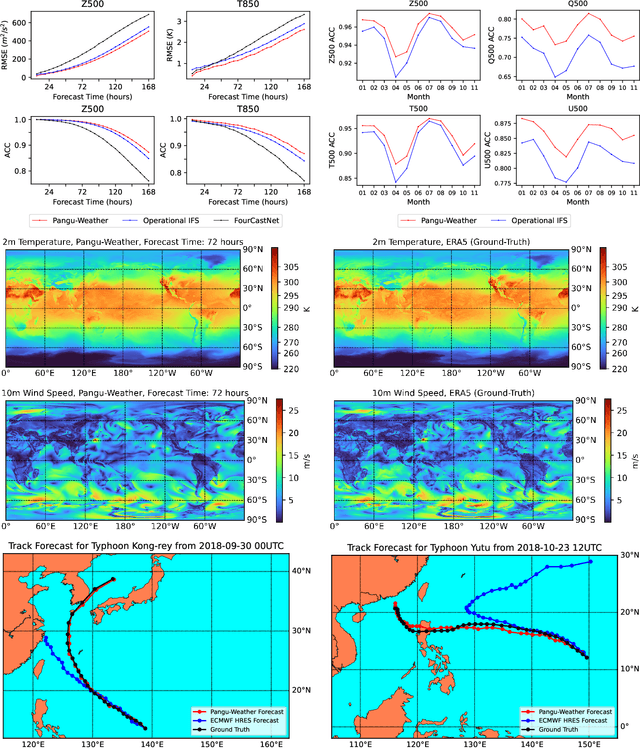
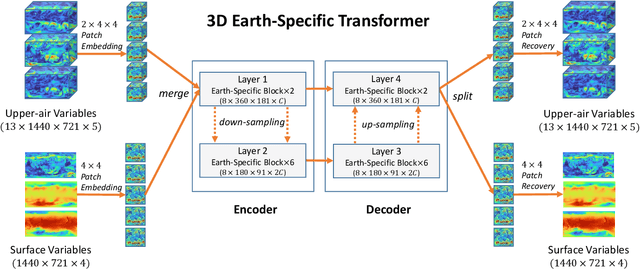
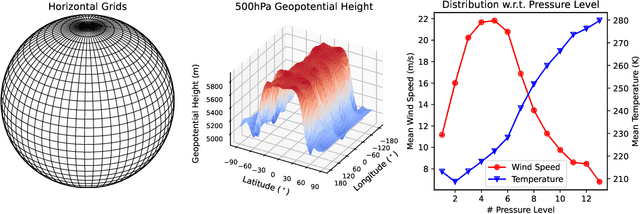
In this paper, we present Pangu-Weather, a deep learning based system for fast and accurate global weather forecast. For this purpose, we establish a data-driven environment by downloading $43$ years of hourly global weather data from the 5th generation of ECMWF reanalysis (ERA5) data and train a few deep neural networks with about $256$ million parameters in total. The spatial resolution of forecast is $0.25^\circ\times0.25^\circ$, comparable to the ECMWF Integrated Forecast Systems (IFS). More importantly, for the first time, an AI-based method outperforms state-of-the-art numerical weather prediction (NWP) methods in terms of accuracy (latitude-weighted RMSE and ACC) of all factors (e.g., geopotential, specific humidity, wind speed, temperature, etc.) and in all time ranges (from one hour to one week). There are two key strategies to improve the prediction accuracy: (i) designing a 3D Earth Specific Transformer (3DEST) architecture that formulates the height (pressure level) information into cubic data, and (ii) applying a hierarchical temporal aggregation algorithm to alleviate cumulative forecast errors. In deterministic forecast, Pangu-Weather shows great advantages for short to medium-range forecast (i.e., forecast time ranges from one hour to one week). Pangu-Weather supports a wide range of downstream forecast scenarios, including extreme weather forecast (e.g., tropical cyclone tracking) and large-member ensemble forecast in real-time. Pangu-Weather not only ends the debate on whether AI-based methods can surpass conventional NWP methods, but also reveals novel directions for improving deep learning weather forecast systems.