 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pylon: Semantic Table Union Search in Data Lakes
Jan 13, 2023

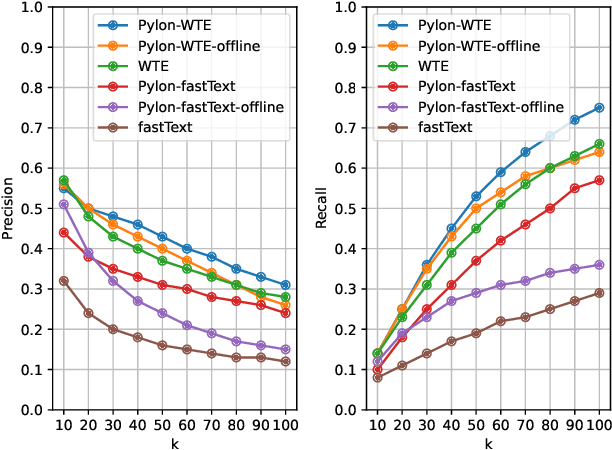
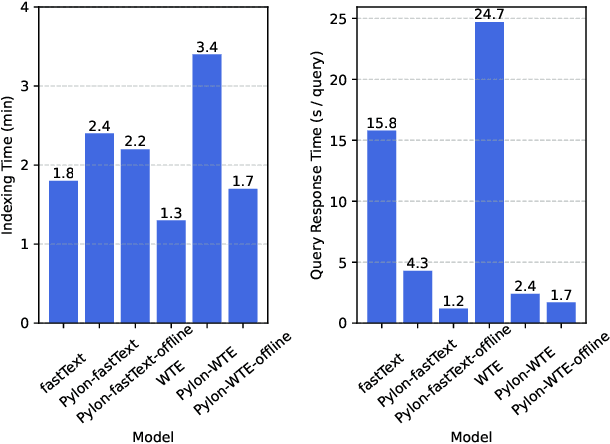
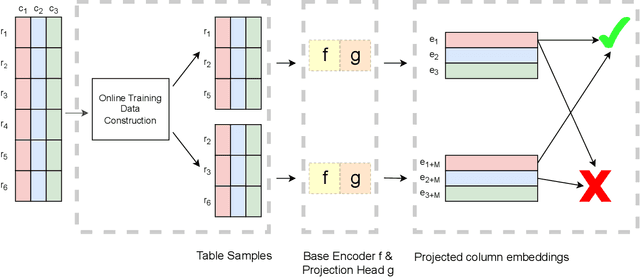
The large size and fast growth of data repositories, such as data lakes, has spurred the need for data discovery to help analysts find related data. The problem has become challenging as (i) a user typically does not know what datasets exist in an enormous data repository; and (ii) there is usually a lack of a unified data model to capture the interrelationships between heterogeneous datasets from disparate sources. In this work, we address one important class of discovery needs: finding union-able tables. The task is to find tables in a data lake that can be unioned with a given query table. The challenge is to recognize union-able columns even if they are represented differently. In this paper, we propose a data-driven learning approach: specifically, an unsupervised representation learning and embedding retrieval task. Our key idea is to exploit self-supervised contrastive learning to learn an embedding model that takes into account the indexing/search data structure and produces embeddings close by for columns with semantically similar values while pushing apart columns with semantically dissimilar values. We then find union-able tables based on similarities between their constituent columns in embedding space. On a real-world data lake, we demonstrate that our best-performing model achieves significant improvements in precision ($16\% \uparrow$), recall ($17\% \uparrow $), and query response time (7x faster) compared to the state-of-the-art.
Time-Constrained Learning
Feb 04, 2022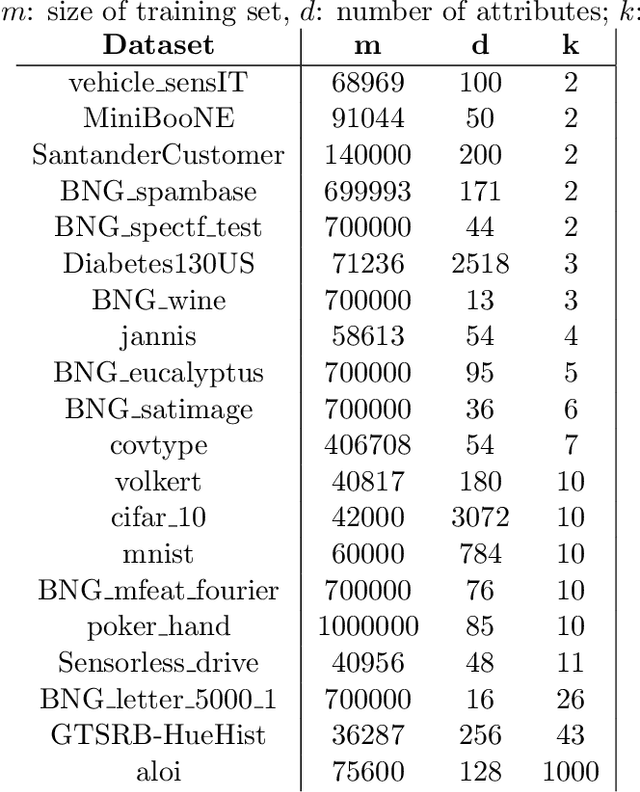
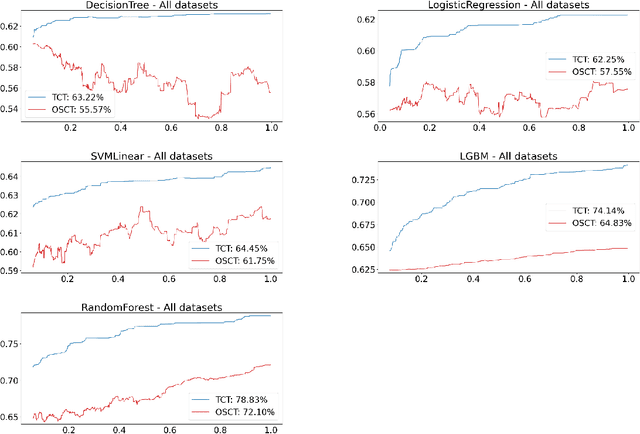
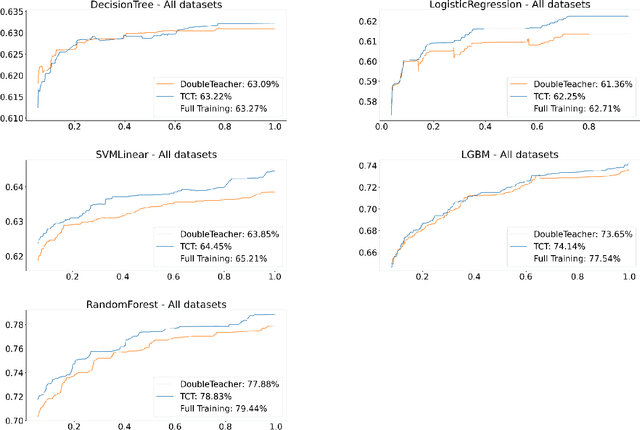
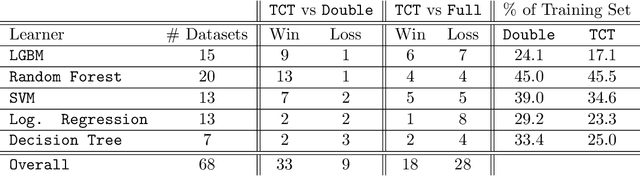
Consider a scenario in which we have a huge labeled dataset ${\cal D}$ and a limited time to train some given learner using ${\cal D}$. Since we may not be able to use the whole dataset, how should we proceed? Questions of this nature motivate the definition of the Time-Constrained Learning Task (TCL): Given a dataset ${\cal D}$ sampled from an unknown distribution $\mu$, a learner ${\cal L}$ and a time limit $T$, the goal is to obtain in at most $T$ units of time the classification model with highest possible accuracy w.r.t. to $\mu$, among those that can be built by ${\cal L}$ using the dataset ${\cal D}$. We propose TCT, an algorithm for the TCL task designed based that on principles from Machine Teaching. We present an experimental study involving 5 different Learners and 20 datasets where we show that TCT consistently outperforms two other algorithms: the first is a Teacher for black-box learners proposed in [Dasgupta et al., ICML 19] and the second is a natural adaptation of random sampling for the TCL setting. We also compare TCT with Stochastic Gradient Descent training -- our method is again consistently better. While our work is primarily practical, we also show that a stripped-down version of TCT has provable guarantees. Under reasonable assumptions, the time our algorithm takes to achieve a certain accuracy is never much bigger than the time it takes the batch teacher (which sends a single batch of examples) to achieve similar accuracy, and in some case it is almost exponentially better.
The necessity of depth for artificial neural networks to approximate certain classes of smooth and bounded functions without the curse of dimensionality
Jan 19, 2023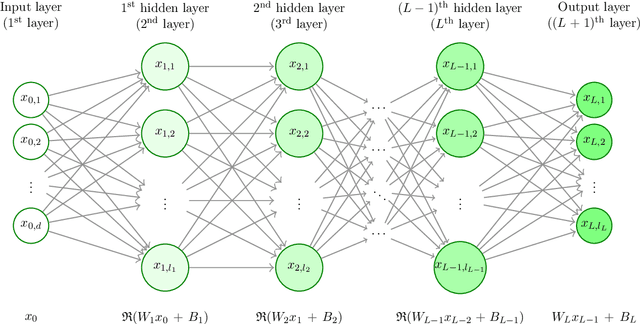
In this article we study high-dimensional approximation capacities of shallow and deep artificial neural networks (ANNs) with the rectified linear unit (ReLU) activation. In particular, it is a key contribution of this work to reveal that for all $a,b\in\mathbb{R}$ with $b-a\geq 7$ we have that the functions $[a,b]^d\ni x=(x_1,\dots,x_d)\mapsto\prod_{i=1}^d x_i\in\mathbb{R}$ for $d\in\mathbb{N}$ as well as the functions $[a,b]^d\ni x =(x_1,\dots, x_d)\mapsto\sin(\prod_{i=1}^d x_i) \in \mathbb{R} $ for $ d \in \mathbb{N} $ can neither be approximated without the curse of dimensionality by means of shallow ANNs nor insufficiently deep ANNs with ReLU activation but can be approximated without the curse of dimensionality by sufficiently deep ANNs with ReLU activation. We show that the product functions and the sine of the product functions are polynomially tractable approximation problems among the approximating class of deep ReLU ANNs with the number of hidden layers being allowed to grow in the dimension $ d \in \mathbb{N} $. We establish the above outlined statements not only for the product functions and the sine of the product functions but also for other classes of target functions, in particular, for classes of uniformly globally bounded $ C^{ \infty } $-functions with compact support on any $[a,b]^d$ with $a\in\mathbb{R}$, $b\in(a,\infty)$. Roughly speaking, in this work we lay open that simple approximation problems such as approximating the sine or cosine of products cannot be solved in standard implementation frameworks by shallow or insufficiently deep ANNs with ReLU activation in polynomial time, but can be approximated by sufficiently deep ReLU ANNs with the number of parameters growing at most polynomially.
Timestomping Vulnerability of Age-Sensitive Gossip Networks
Dec 29, 2022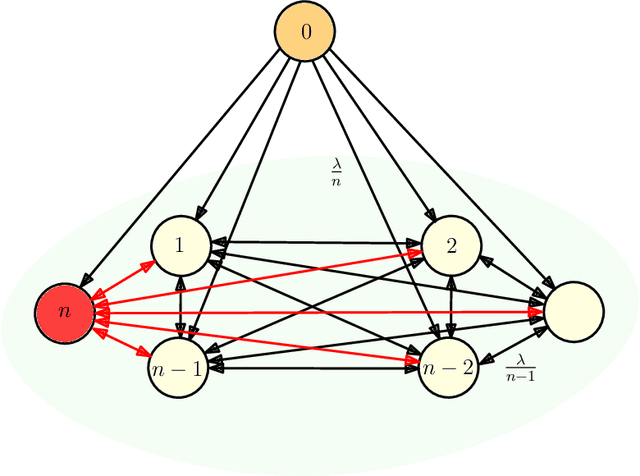
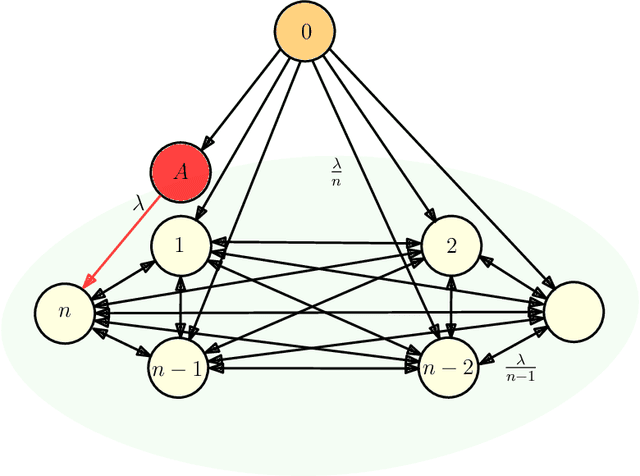
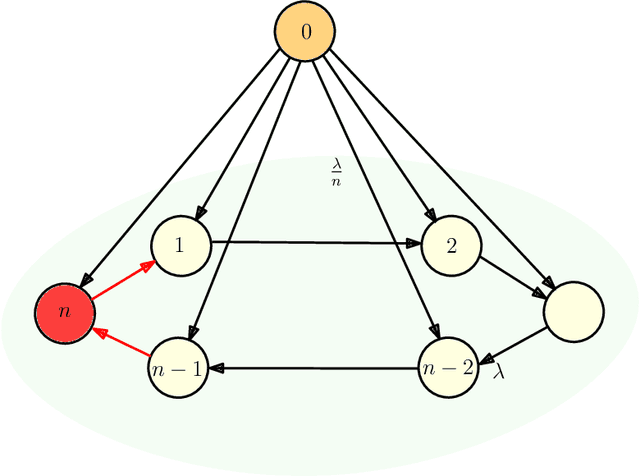
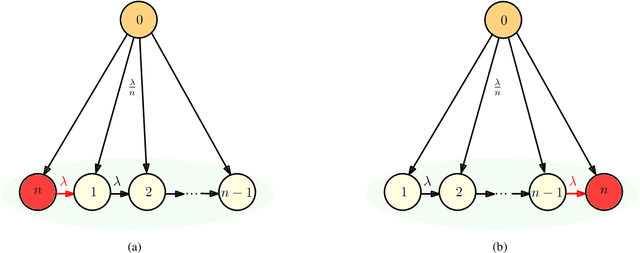
We consider gossip networks consisting of a source that maintains the current version of a file, $n$ nodes that use asynchronous gossip mechanisms to disseminate fresh information in the network, and an oblivious adversary who infects the packets at a target node through data timestamp manipulation, with the intent to replace circulation of fresh packets with outdated packets in the network. We demonstrate how network topology capacitates an adversary to influence age scaling in a network. We show that in a fully connected network, a single infected node increases the expected age from $O(\log n)$ to $O(n)$. Further, we show that the optimal behavior for an adversary is to reset the timestamps of all outgoing packets to the current time and of all incoming packets to an outdated time for the infected node; thereby preventing any fresh information to go into the infected node, and facilitating acceptance of stale information out of the infected node into other network nodes. Lastly for fully connected network, we show that if an infected node contacts only a single node instead of all nodes of the network, the system age can still be degraded to $O(n)$. These show that fully connected nature of a network can be both a benefit and a detriment for information freshness; full connectivity, while enabling fast dissemination of information, also enables fast dissipation of adversarial inputs. We then analyze the unidirectional ring network, the other end of the network connectivity spectrum, where we show that the adversarial effect on age scaling of a node is limited by its distance from the adversary, and the age scaling for a large fraction of the network continues to be $O(\sqrt{n})$, unchanged from the case with no adversary. We finally support our findings with simulations.
Censor-aware Semi-supervised Learning for Survival Time Prediction from Medical Images
May 26, 2022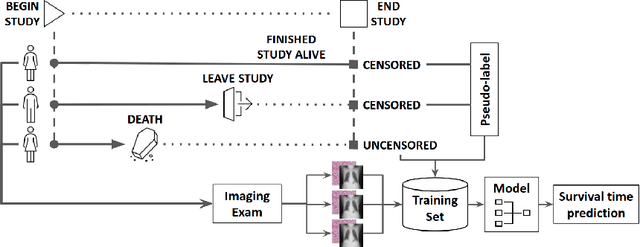
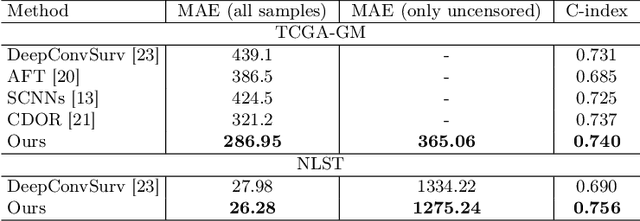
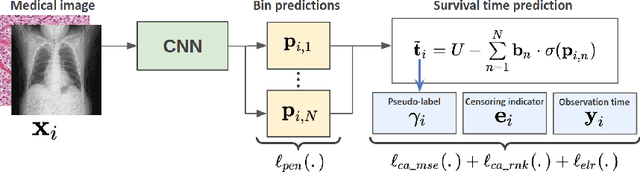
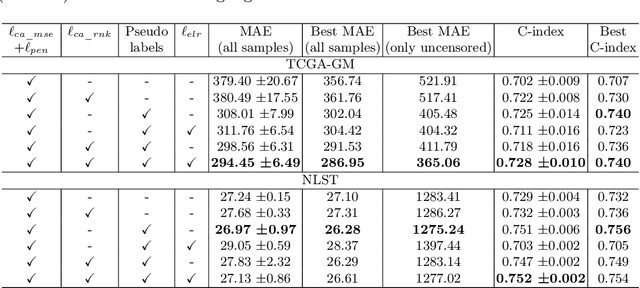
Survival time prediction from medical images is important for treatment planning, where accurate estimations can improve healthcare quality. One issue affecting the training of survival models is censored data. Most of the current survival prediction approaches are based on Cox models that can deal with censored data, but their application scope is limited because they output a hazard function instead of a survival time. On the other hand, methods that predict survival time usually ignore censored data, resulting in an under-utilization of the training set. In this work, we propose a new training method that predicts survival time using all censored and uncensored data. We propose to treat censored data as samples with a lower-bound time to death and estimate pseudo labels to semi-supervise a censor-aware survival time regressor. We evaluate our method on pathology and x-ray images from the TCGA-GM and NLST datasets. Our results establish the state-of-the-art survival prediction accuracy on both datasets.
SepLUT: Separable Image-adaptive Lookup Tables for Real-time Image Enhancement
Jul 18, 2022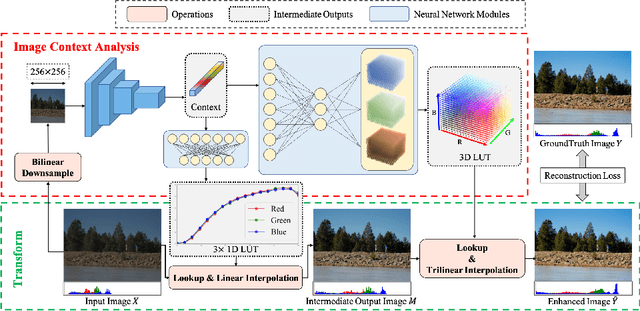
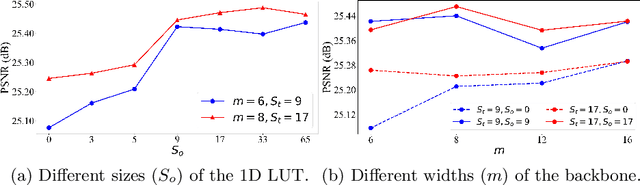
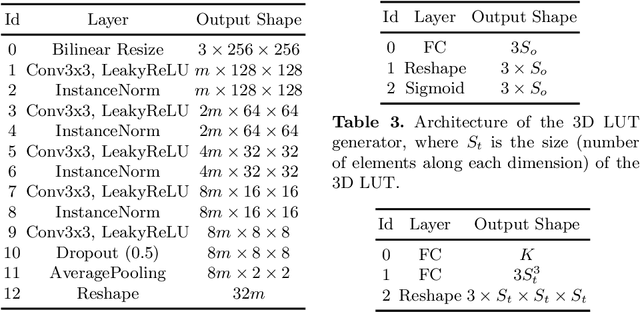
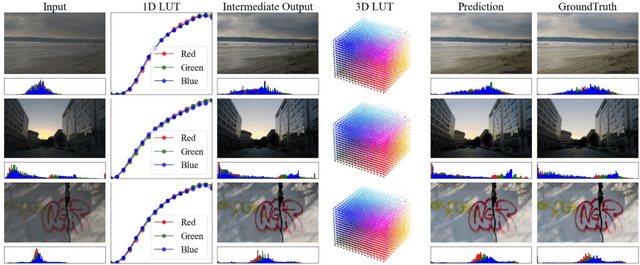
Image-adaptive lookup tables (LUTs) have achieved great success in real-time image enhancement tasks due to their high efficiency for modeling color transforms. However, they embed the complete transform, including the color component-independent and the component-correlated parts, into only a single type of LUTs, either 1D or 3D, in a coupled manner. This scheme raises a dilemma of improving model expressiveness or efficiency due to two factors. On the one hand, the 1D LUTs provide high computational efficiency but lack the critical capability of color components interaction. On the other, the 3D LUTs present enhanced component-correlated transform capability but suffer from heavy memory footprint, high training difficulty, and limited cell utilization. Inspired by the conventional divide-and-conquer practice in the image signal processor, we present SepLUT (separable image-adaptive lookup table) to tackle the above limitations. Specifically, we separate a single color transform into a cascade of component-independent and component-correlated sub-transforms instantiated as 1D and 3D LUTs, respectively. In this way, the capabilities of two sub-transforms can facilitate each other, where the 3D LUT complements the ability to mix up color components, and the 1D LUT redistributes the input colors to increase the cell utilization of the 3D LUT and thus enable the use of a more lightweight 3D LUT. Experiments demonstrate that the proposed method presents enhanced performance on photo retouching benchmark datasets than the current state-of-the-art and achieves real-time processing on both GPUs and CPUs.
GraphCast: Learning skillful medium-range global weather forecasting
Dec 24, 2022
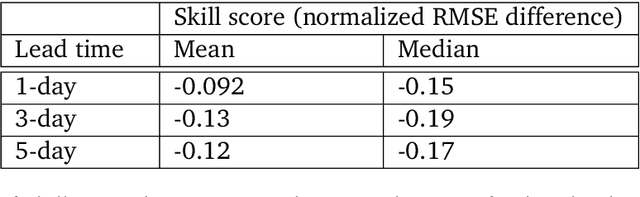
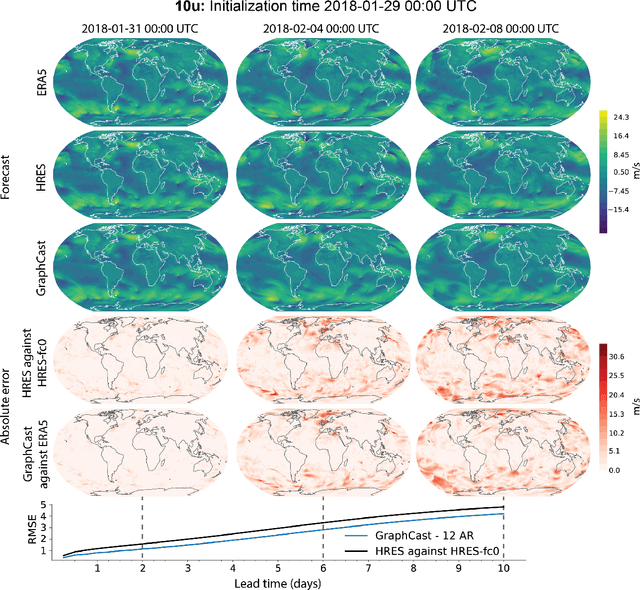
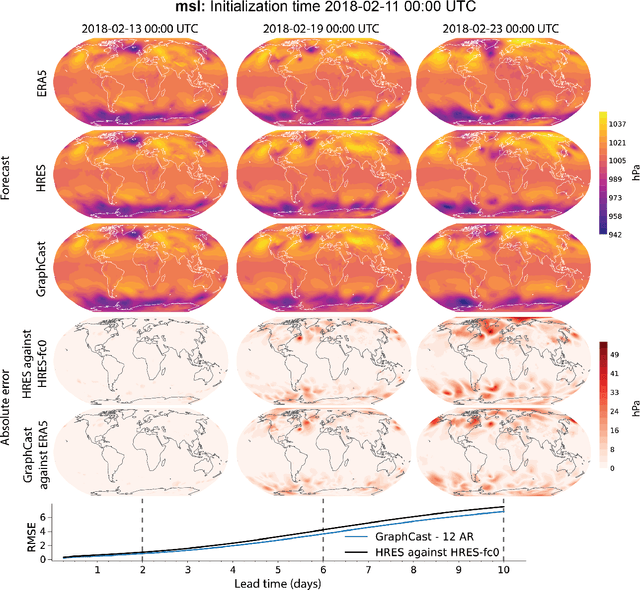
We introduce a machine-learning (ML)-based weather simulator--called "GraphCast"--which outperforms the most accurate deterministic operational medium-range weather forecasting system in the world, as well as all previous ML baselines. GraphCast is an autoregressive model, based on graph neural networks and a novel high-resolution multi-scale mesh representation, which we trained on historical weather data from the European Centre for Medium-Range Weather Forecasts (ECMWF)'s ERA5 reanalysis archive. It can make 10-day forecasts, at 6-hour time intervals, of five surface variables and six atmospheric variables, each at 37 vertical pressure levels, on a 0.25-degree latitude-longitude grid, which corresponds to roughly 25 x 25 kilometer resolution at the equator. Our results show GraphCast is more accurate than ECMWF's deterministic operational forecasting system, HRES, on 90.0% of the 2760 variable and lead time combinations we evaluated. GraphCast also outperforms the most accurate previous ML-based weather forecasting model on 99.2% of the 252 targets it reported. GraphCast can generate a 10-day forecast (35 gigabytes of data) in under 60 seconds on Cloud TPU v4 hardware. Unlike traditional forecasting methods, ML-based forecasting scales well with data: by training on bigger, higher quality, and more recent data, the skill of the forecasts can improve. Together these results represent a key step forward in complementing and improving weather modeling with ML, open new opportunities for fast, accurate forecasting, and help realize the promise of ML-based simulation in the physical sciences.
Self-supervised Learning for Segmentation and Quantification of Dopamine Neurons in $\text{Parkinson's Disease}$
Jan 11, 2023

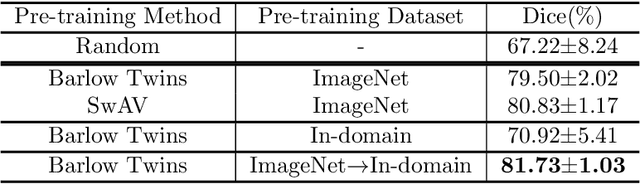

$\text{Parkinson's Disease}$ (PD) is the second most common neurodegenerative disease in humans. PD is characterized by the gradual loss of dopaminergic neurons in the Substantia Nigra (a part of the mid-brain). Counting the number of dopaminergic neurons in the Substantia Nigra is one of the most important indexes in evaluating drug efficacy in PD animal models. Currently, analyzing and quantifying dopaminergic neurons is conducted manually by experts through analysis of digital pathology images which is laborious, time-consuming, and highly subjective. As such, a reliable and unbiased automated system is demanded for the quantification of dopaminergic neurons in digital pathology images. We propose an end-to-end deep learning framework for the segmentation and quantification of dopaminergic neurons in PD animal models. To the best of knowledge, this is the first machine learning model that detects the cell body of dopaminergic neurons, counts the number of dopaminergic neurons and provides the phenotypic characteristics of individual dopaminergic neurons as a numerical output. Extensive experiments demonstrate the effectiveness of our model in quantifying neurons with a high precision, which can provide quicker turnaround for drug efficacy studies, better understanding of dopaminergic neuronal health status and unbiased results in PD pre-clinical research.
Age of Information in Deep Learning-Driven Task-Oriented Communications
Jan 11, 2023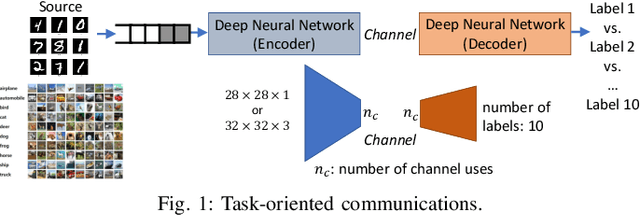
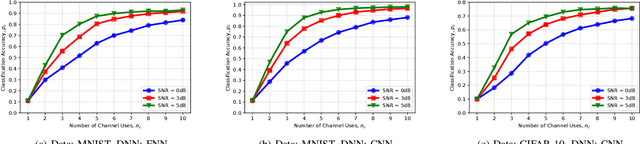
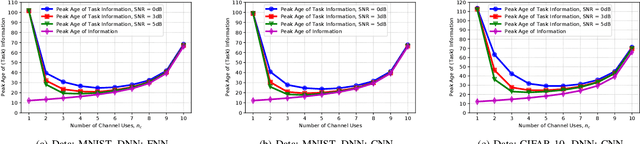
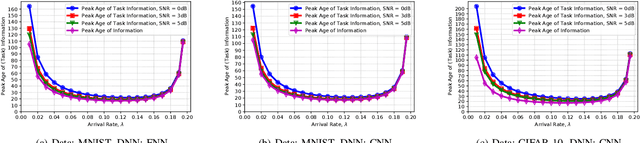
This paper studies the notion of age in task-oriented communications that aims to execute a task at a receiver utilizing the data at its transmitter. The transmitter-receiver operations are modeled as an encoder-decoder pair of deep neural networks (DNNs) that are jointly trained while considering channel effects. The encoder converts data samples into feature vectors of small dimension and transmits them with a small number of channel uses thereby reducing the number of transmissions and latency. Instead of reconstructing input samples, the decoder performs a task, e.g., classification, on the received signals. Applying different DNNs on MNIST and CIFAR-10 image data, the classifier accuracy is shown to increase with the number of channel uses at the expense of longer service time. The peak age of task information (PAoTI) is introduced to analyze this accuracy-latency tradeoff when the age grows unless a received signal is classified correctly. By incorporating channel and traffic effects, design guidelines are obtained for task-oriented communications by characterizing how the PAoTI first decreases and then increases with the number of channels uses. A dynamic update mechanism is presented to adapt the number of channel uses to channel and traffic conditions, and reduce the PAoTI in task-oriented communications.
Learning to Exploit Temporal Structure for Biomedical Vision-Language Processing
Jan 11, 2023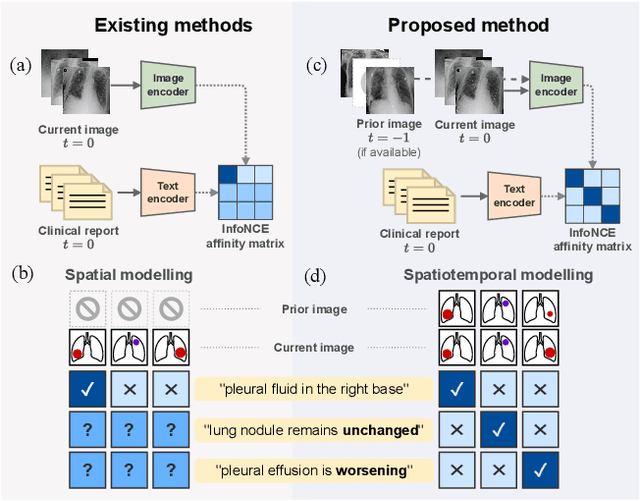
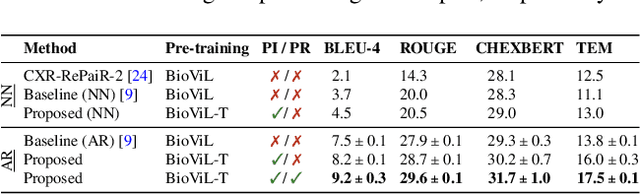
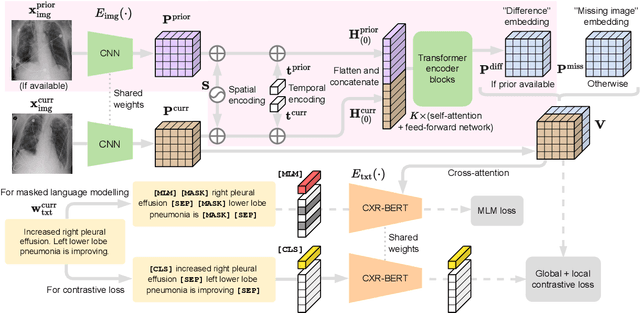
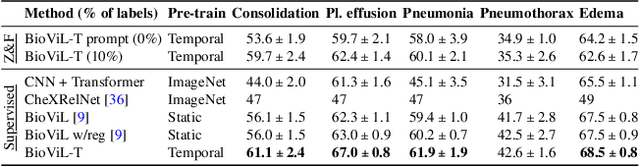
Self-supervised learning in vision-language processing exploits semantic alignment between imaging and text modalities. Prior work in biomedical VLP has mostly relied on the alignment of single image and report pairs even though clinical notes commonly refer to prior images. This does not only introduce poor alignment between the modalities but also a missed opportunity to exploit rich self-supervision through existing temporal content in the data. In this work, we explicitly account for prior images and reports when available during both training and fine-tuning. Our approach, named BioViL-T, uses a CNN-Transformer hybrid multi-image encoder trained jointly with a text model. It is designed to be versatile to arising challenges such as pose variations and missing input images across time. The resulting model excels on downstream tasks both in single- and multi-image setups, achieving state-of-the-art performance on (I) progression classification, (II) phrase grounding, and (III) report generation, whilst offering consistent improvements on disease classification and sentence-similarity tasks. We release a novel multi-modal temporal benchmark dataset, MS-CXR-T, to quantify the quality of vision-language representations in terms of temporal semantics. Our experimental results show the advantages of incorporating prior images and reports to make most use of the data.