 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Test-time Adaptation for Real Image Denoising via Meta-transfer Learning
Jul 05, 2022
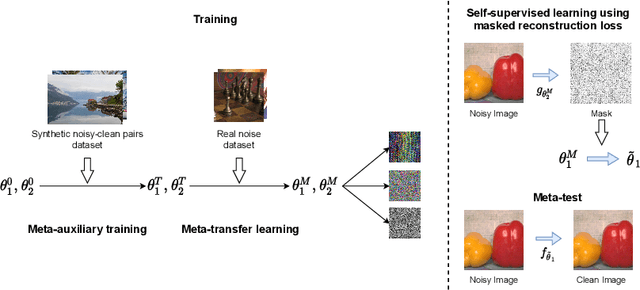
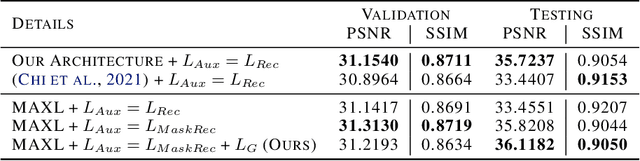
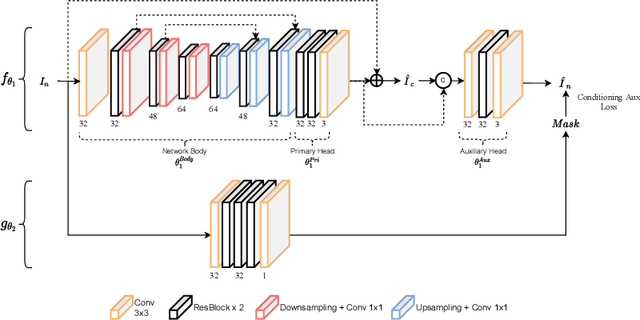
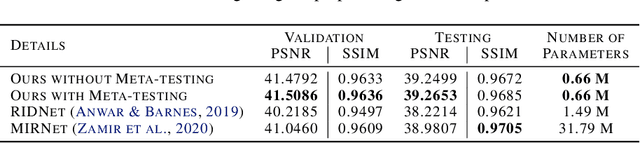
In recent years, a ton of research has been conducted on real image denoising tasks. However, the efforts are more focused on improving real image denoising through creating a better network architecture. We explore a different direction where we propose to improve real image denoising performance through a better learning strategy that can enable test-time adaptation on the multi-task network. The learning strategy is two stages where the first stage pre-train the network using meta-auxiliary learning to get better meta-initialization. Meanwhile, we use meta-learning for fine-tuning (meta-transfer learning) the network as the second stage of our training to enable test-time adaptation on real noisy images. To exploit a better learning strategy, we also propose a network architecture with self-supervised masked reconstruction loss. Experiments on a real noisy dataset show the contribution of the proposed method and show that the proposed method can outperform other SOTA methods.
Learning Representations that Enable Generalization in Assistive Tasks
Dec 05, 2022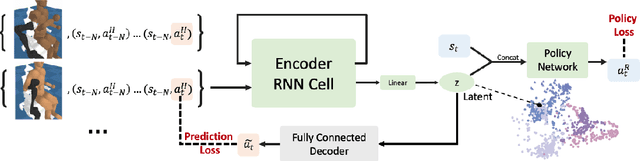
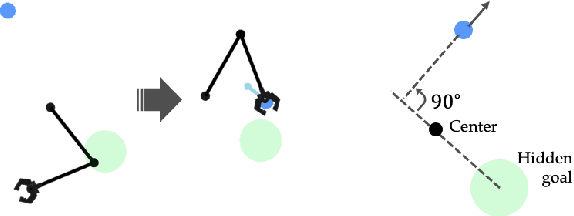
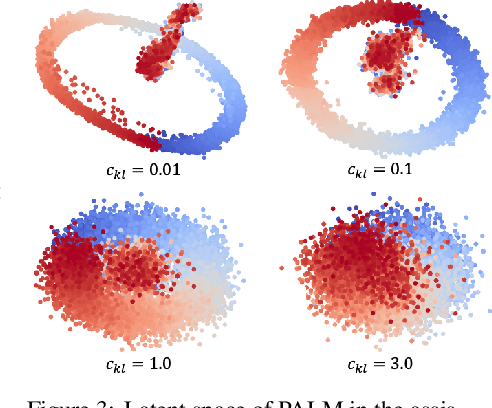
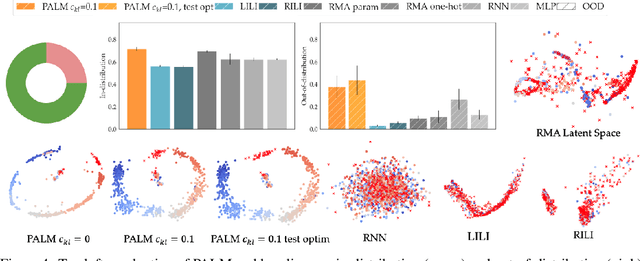
Recent work in sim2real has successfully enabled robots to act in physical environments by training in simulation with a diverse ''population'' of environments (i.e. domain randomization). In this work, we focus on enabling generalization in assistive tasks: tasks in which the robot is acting to assist a user (e.g. helping someone with motor impairments with bathing or with scratching an itch). Such tasks are particularly interesting relative to prior sim2real successes because the environment now contains a human who is also acting. This complicates the problem because the diversity of human users (instead of merely physical environment parameters) is more difficult to capture in a population, thus increasing the likelihood of encountering out-of-distribution (OOD) human policies at test time. We advocate that generalization to such OOD policies benefits from (1) learning a good latent representation for human policies that test-time humans can accurately be mapped to, and (2) making that representation adaptable with test-time interaction data, instead of relying on it to perfectly capture the space of human policies based on the simulated population only. We study how to best learn such a representation by evaluating on purposefully constructed OOD test policies. We find that sim2real methods that encode environment (or population) parameters and work well in tasks that robots do in isolation, do not work well in assistance. In assistance, it seems crucial to train the representation based on the history of interaction directly, because that is what the robot will have access to at test time. Further, training these representations to then predict human actions not only gives them better structure, but also enables them to be fine-tuned at test-time, when the robot observes the partner act. https://adaptive-caregiver.github.io.
Time-to-Green predictions for fully-actuated signal control systems with supervised learning
Aug 24, 2022
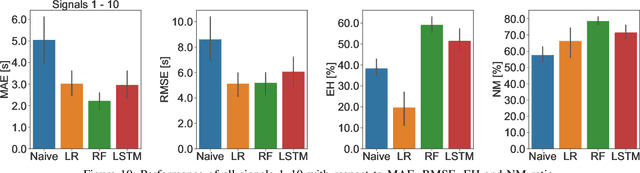
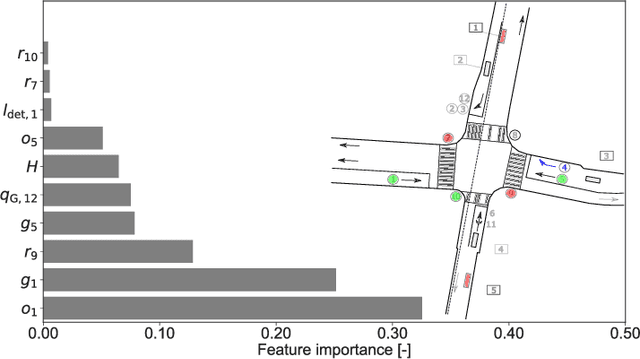
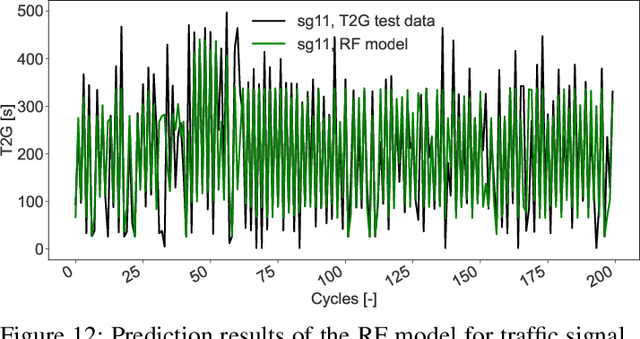
Recently, efforts have been made to standardize signal phase and timing (SPaT) messages. These messages contain signal phase timings of all signalized intersection approaches. This information can thus be used for efficient motion planning, resulting in more homogeneous traffic flows and uniform speed profiles. Despite efforts to provide robust predictions for semi-actuated signal control systems, predicting signal phase timings for fully-actuated controls remains challenging. This paper proposes a time series prediction framework using aggregated traffic signal and loop detector data. We utilize state-of-the-art machine learning models to predict future signal phases' duration. The performance of a Linear Regression (LR), a Random Forest (RF), and a Long-Short-Term-Memory (LSTM) neural network are assessed against a naive baseline model. Results based on an empirical data set from a fully-actuated signal control system in Zurich, Switzerland, show that machine learning models outperform conventional prediction methods. Furthermore, tree-based decision models such as the RF perform best with an accuracy that meets requirements for practical applications.
PlasmoFAB: A Benchmark to Foster Machine Learning for Plasmodium falciparum Protein Antigen Candidate Prediction
Jan 16, 2023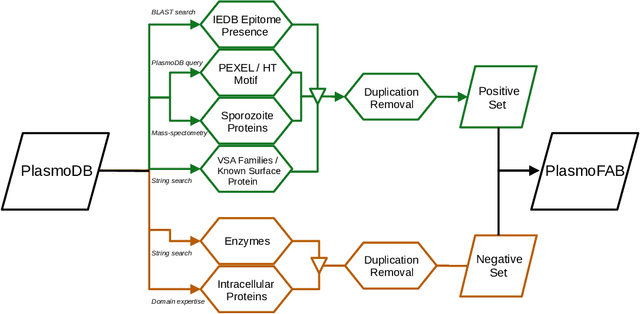

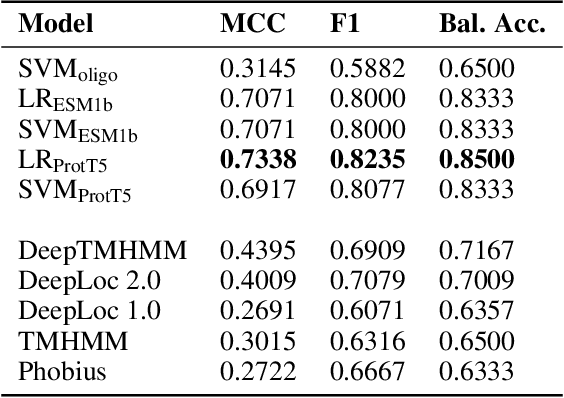
Motivation: Machine learning methods can be used to support scientific discovery in healthcare-related research fields. However, these methods can only be reliably used if they can be trained on high-quality and curated datasets. Currently, no such dataset for the exploration of Plasmodium falciparum protein antigen candidates exists. The parasite Plasmodium falciparum causes the infectious disease malaria. Thus, identifying potential antigens is of utmost importance for the development of antimalarial drugs and vaccines. Since exploring antigen candidates experimentally is an expensive and time-consuming process, applying machine learning methods to support this process has the potential to accelerate the development of drugs and vaccines which are needed for fighting and controlling malaria. Results: We developed PlasmoFAB, a curated benchmark that can be used to train machine learning methods for the exploration of Plasmodium falciparum protein antigen candidates. We combined an extensive literature search with domain expertise to create high-quality labels for Plasmodium falciparum specific proteins that distinguish between antigen candidates and intracellular proteins. Additionally, we used our benchmark to compare different well-known prediction models and available protein localization prediction services on the task of identifying protein antigen candidates. We show that available general-purpose services are unable to provide sufficient performance on identifying protein antigen candidates and are outperformed by models that were trained on specialized data.
Joint Non-parametric Point Process model for Treatments and Outcomes: Counterfactual Time-series Prediction Under Policy Interventions
Sep 09, 2022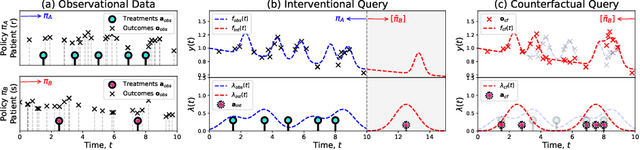
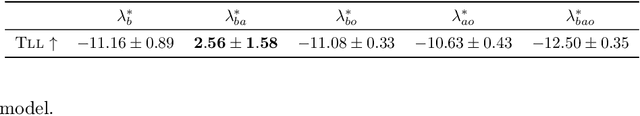
Policy makers need to predict the progression of an outcome before adopting a new treatment policy, which defines when and how a sequence of treatments affecting the outcome occurs in continuous time. Commonly, algorithms that predict interventional future outcome trajectories take a fixed sequence of future treatments as input. This either neglects the dependence of future treatments on outcomes preceding them or implicitly assumes the treatment policy is known, and hence excludes scenarios where the policy is unknown or a counterfactual analysis is needed. To handle these limitations, we develop a joint model for treatments and outcomes, which allows for the estimation of treatment policies and effects from sequential treatment--outcome data. It can answer interventional and counterfactual queries about interventions on treatment policies, as we show with real-world data on blood glucose progression and a simulation study building on top of this.
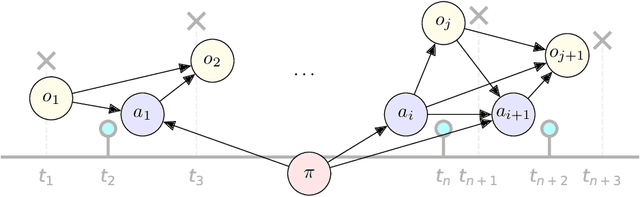
A Comprehensive Architecture for Dynamic Role Allocation and Collaborative Task Planning in Mixed Human-Robot Teams
Jan 19, 2023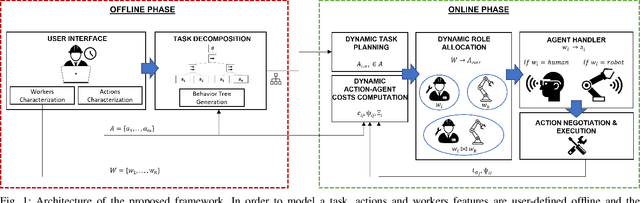

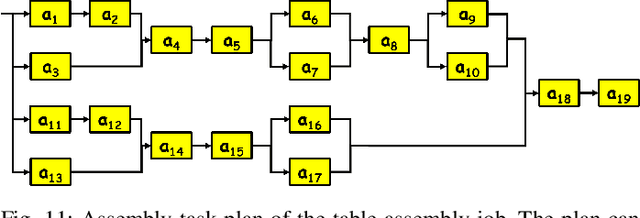
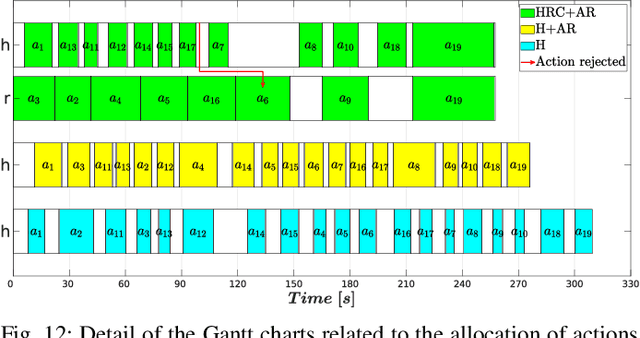
The growing deployment of human-robot collaborative processes in several industrial applications, such as handling, welding, and assembly, unfolds the pursuit of systems which are able to manage large heterogeneous teams and, at the same time, monitor the execution of complex tasks. In this paper, we present a novel architecture for dynamic role allocation and collaborative task planning in a mixed human-robot team of arbitrary size. The architecture capitalizes on a centralized reactive and modular task-agnostic planning method based on Behavior Trees (BTs), in charge of actions scheduling, while the allocation problem is formulated through a Mixed-Integer Linear Program (MILP), that assigns dynamically individual roles or collaborations to the agents of the team. Different metrics used as MILP cost allow the architecture to favor various aspects of the collaboration (e.g. makespan, ergonomics, human preferences). Human preference are identified through a negotiation phase, in which, an human agent can accept/refuse to execute the assigned task.In addition, bilateral communication between humans and the system is achieved through an Augmented Reality (AR) custom user interface that provides intuitive functionalities to assist and coordinate workers in different action phases. The computational complexity of the proposed methodology outperforms literature approaches in industrial sized jobs and teams (problems up to 50 actions and 20 agents in the team with collaborations are solved within 1\;s). The different allocated roles, as the cost functions change, highlights the flexibility of the architecture to several production requirements. Finally, the subjective evaluation demonstrating the high usability level and the suitability for the targeted scenario.
Regularizing disparity estimation via multi task learning with structured light reconstruction
Jan 19, 2023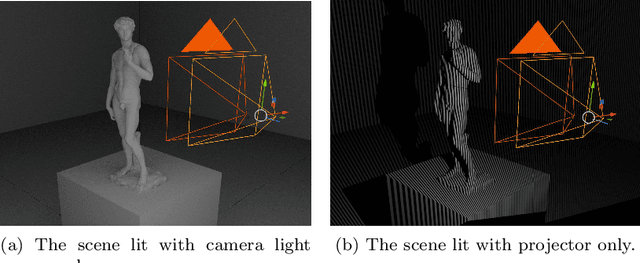

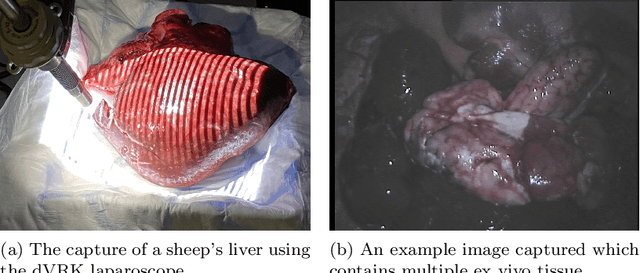
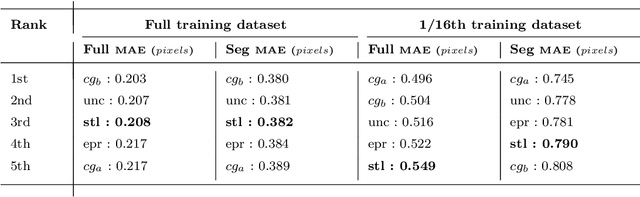
3D reconstruction is a useful tool for surgical planning and guidance. However, the lack of available medical data stunts research and development in this field, as supervised deep learning methods for accurate disparity estimation rely heavily on large datasets containing ground truth information. Alternative approaches to supervision have been explored, such as self-supervision, which can reduce or remove entirely the need for ground truth. However, no proposed alternatives have demonstrated performance capabilities close to what would be expected from a supervised setup. This work aims to alleviate this issue. In this paper, we investigate the learning of structured light projections to enhance the development of direct disparity estimation networks. We show for the first time that it is possible to accurately learn the projection of structured light on a scene, implicitly learning disparity. Secondly, we \textcolor{black}{explore the use of a multi task learning (MTL) framework for the joint training of structured light and disparity. We present results which show that MTL with structured light improves disparity training; without increasing the number of model parameters. Our MTL setup outperformed the single task learning (STL) network in every validation test. Notably, in the medical generalisation test, the STL error was 1.4 times worse than that of the best MTL performance. The benefit of using MTL is emphasised when the training data is limited.} A dataset containing stereoscopic images, disparity maps and structured light projections on medical phantoms and ex vivo tissue was created for evaluation together with virtual scenes. This dataset will be made publicly available in the future.
$\texttt{tasksource}$: Structured Dataset Preprocessing Annotations for Frictionless Extreme Multi-Task Learning and Evaluation
Jan 14, 2023
The HuggingFace Datasets Hub hosts thousands of datasets. This provides exciting opportunities for language model training and evaluation. However, the datasets for a given type of task are stored with different schemas, and harmonization is harder than it seems (https://xkcd.com/927/). Multi-task training or evaluation requires manual work to fit data into task templates. Various initiatives independently address this problem by releasing the harmonized datasets or harmonization codes to preprocess datasets to the same format. We identify patterns across previous preprocessings, e.g. mapping of column names, and extraction of a specific sub-field from structured data in a column, and propose a structured annotation framework that makes our annotations fully exposed and not buried in unstructured code. We release a dataset annotation framework and dataset annotations for more than 400 English tasks (https://github.com/sileod/tasksource). These annotations provide metadata, like the name of the columns that should be used as input or labels for all datasets, and can save time for future dataset preprocessings, even if they do not use our framework. We fine-tune a multi-task text encoder on all tasksource tasks, outperforming every publicly available text encoder of comparable size on an external evaluation https://hf.co/sileod/deberta-v3-base-tasksource-nli.
Modulation spectral features for speech emotion recognition using deep neural networks
Jan 14, 2023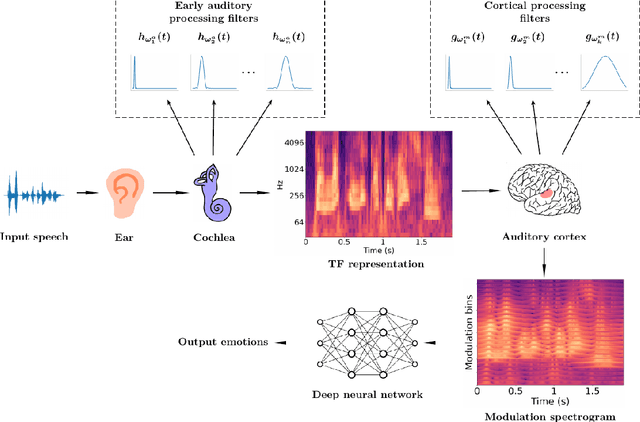
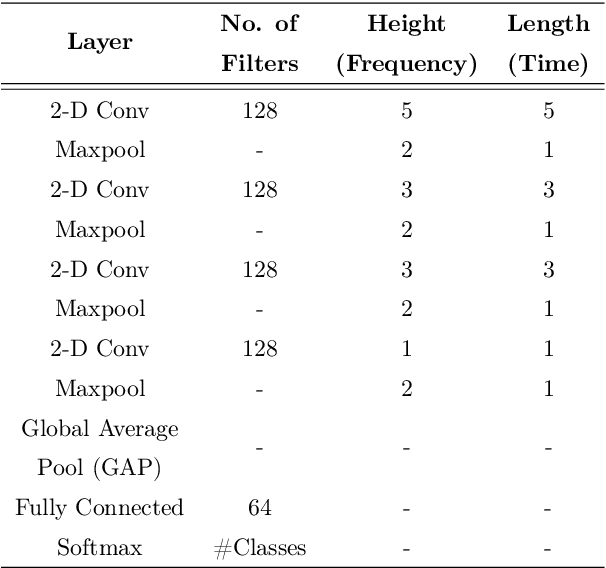


This work explores the use of constant-Q transform based modulation spectral features (CQT-MSF) for speech emotion recognition (SER). The human perception and analysis of sound comprise of two important cognitive parts: early auditory analysis and cortex-based processing. The early auditory analysis considers spectrogram-based representation whereas cortex-based analysis includes extraction of temporal modulations from the spectrogram. This temporal modulation representation of spectrogram is called modulation spectral feature (MSF). As the constant-Q transform (CQT) provides higher resolution at emotion salient low-frequency regions of speech, we find that CQT-based spectrogram, together with its temporal modulations, provides a representation enriched with emotion-specific information. We argue that CQT-MSF when used with a 2-dimensional convolutional network can provide a time-shift invariant and deformation insensitive representation for SER. Our results show that CQT-MSF outperforms standard mel-scale based spectrogram and its modulation features on two popular SER databases, Berlin EmoDB and RAVDESS. We also show that our proposed feature outperforms the shift and deformation invariant scattering transform coefficients, hence, showing the importance of joint hand-crafted and self-learned feature extraction instead of reliance on complete hand-crafted features. Finally, we perform Grad-CAM analysis to visually inspect the contribution of constant-Q modulation features over SER.
* Accepted for publication in Elsevier's Speech Communication Journal
UnifySpeech: A Unified Framework for Zero-shot Text-to-Speech and Voice Conversion
Jan 10, 2023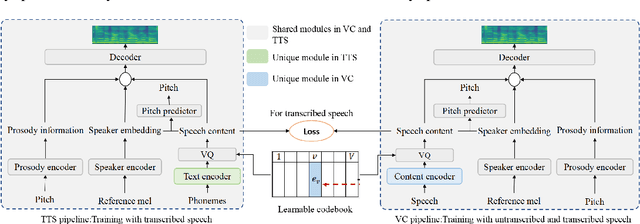

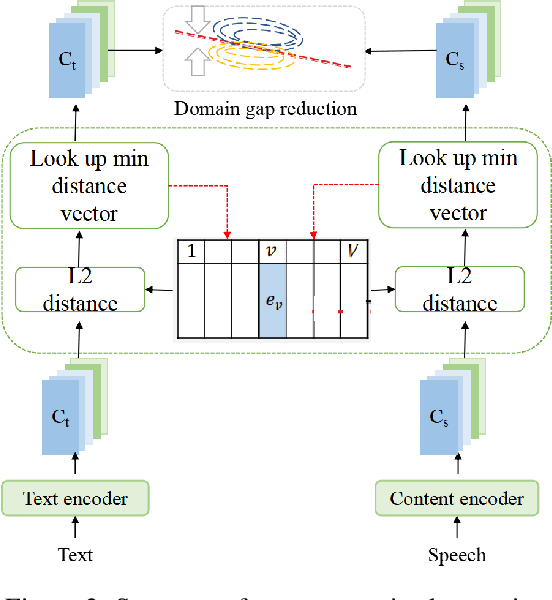
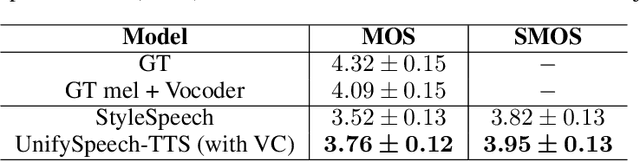
Text-to-speech (TTS) and voice conversion (VC) are two different tasks both aiming at generating high quality speaking voice according to different input modality. Due to their similarity, this paper proposes UnifySpeech, which brings TTS and VC into a unified framework for the first time. The model is based on the assumption that speech can be decoupled into three independent components: content information, speaker information, prosody information. Both TTS and VC can be regarded as mining these three parts of information from the input and completing the reconstruction of speech. For TTS, the speech content information is derived from the text, while in VC it's derived from the source speech, so all the remaining units are shared except for the speech content extraction module in the two tasks. We applied vector quantization and domain constrain to bridge the gap between the content domains of TTS and VC. Objective and subjective evaluation shows that by combining the two task, TTS obtains better speaker modeling ability while VC gets hold of impressive speech content decoupling capability.