 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Behave-XAI: Deep Explainable Learning of Behavioral Representational Data
Dec 30, 2022
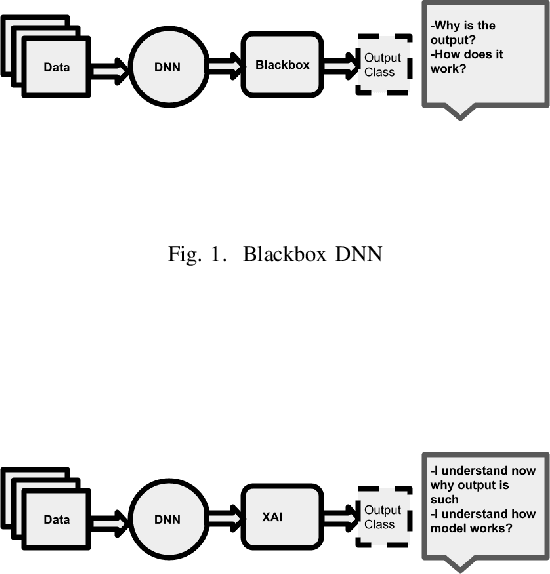
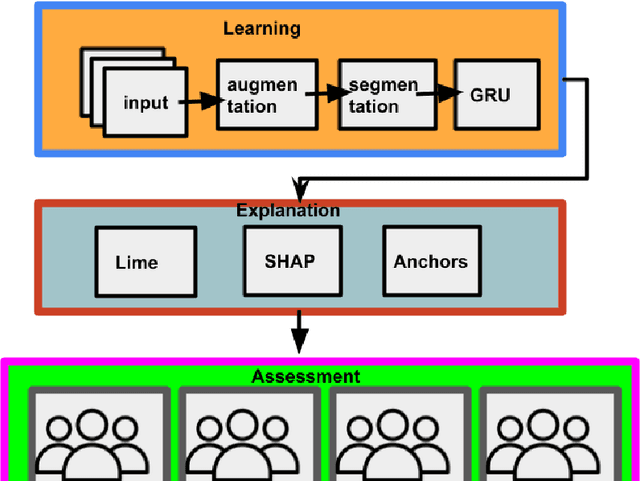
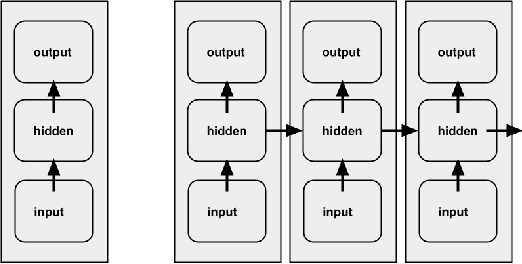
According to the latest trend of artificial intelligence, AI-systems needs to clarify regarding general,specific decisions,services provided by it. Only consumer is satisfied, with explanation , for example, why any classification result is the outcome of any given time. This actually motivates us using explainable or human understandable AI for a behavioral mining scenario, where users engagement on digital platform is determined from context, such as emotion, activity, weather, etc. However, the output of AI-system is not always systematically correct, and often systematically correct, but apparently not-perfect and thereby creating confusions, such as, why the decision is given? What is the reason underneath? In this context, we first formulate the behavioral mining problem in deep convolutional neural network architecture. Eventually, we apply a recursive neural network due to the presence of time-series data from users physiological and environmental sensor-readings. Once the model is developed, explanations are presented with the advent of XAI models in front of users. This critical step involves extensive trial with users preference on explanations over conventional AI, judgement of credibility of explanation.
Training Full Spike Neural Networks via Auxiliary Accumulation Pathway
Jan 27, 2023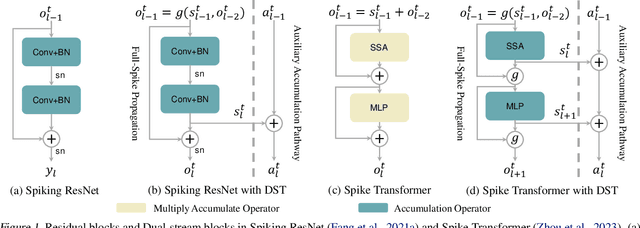

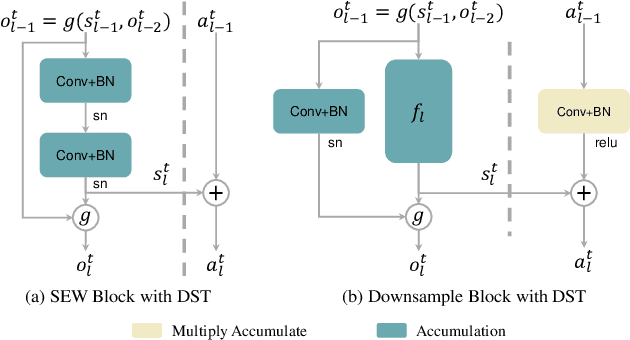
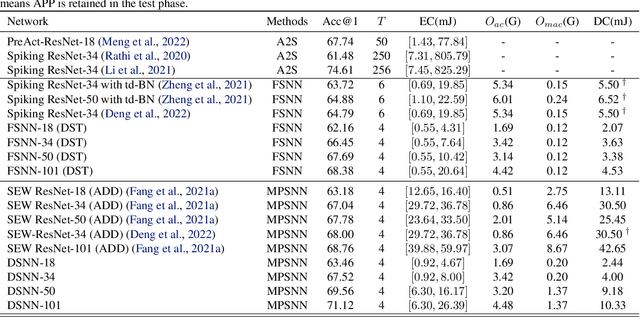
Due to the binary spike signals making converting the traditional high-power multiply-accumulation (MAC) into a low-power accumulation (AC) available, the brain-inspired Spiking Neural Networks (SNNs) are gaining more and more attention. However, the binary spike propagation of the Full-Spike Neural Networks (FSNN) with limited time steps is prone to significant information loss. To improve performance, several state-of-the-art SNN models trained from scratch inevitably bring many non-spike operations. The non-spike operations cause additional computational consumption and may not be deployed on some neuromorphic hardware where only spike operation is allowed. To train a large-scale FSNN with high performance, this paper proposes a novel Dual-Stream Training (DST) method which adds a detachable Auxiliary Accumulation Pathway (AAP) to the full spiking residual networks. The accumulation in AAP could compensate for the information loss during the forward and backward of full spike propagation, and facilitate the training of the FSNN. In the test phase, the AAP could be removed and only the FSNN remained. This not only keeps the lower energy consumption but also makes our model easy to deploy. Moreover, for some cases where the non-spike operations are available, the APP could also be retained in test inference and improve feature discrimination by introducing a little non-spike consumption. Extensive experiments on ImageNet, DVS Gesture, and CIFAR10-DVS datasets demonstrate the effectiveness of DST.
Cross-Domain Consumer Review Analysis
Dec 23, 2022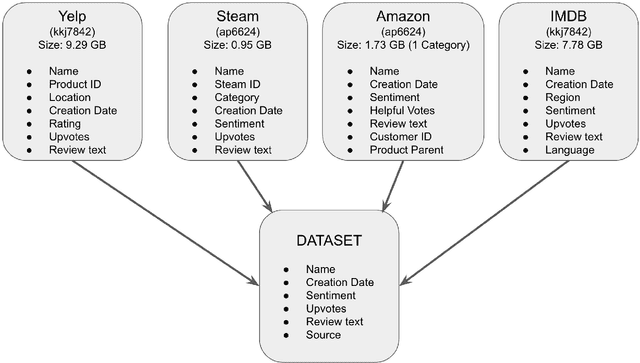
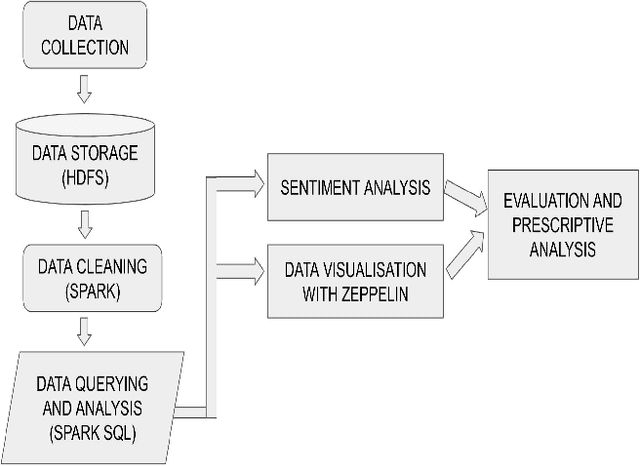
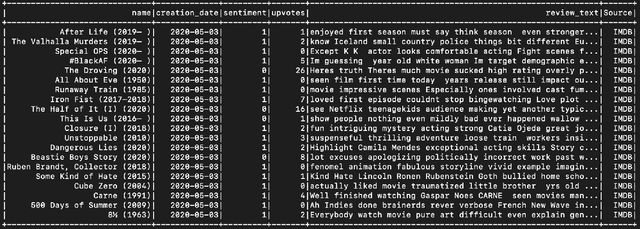
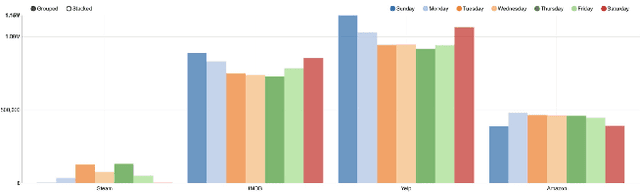
The paper presents a cross-domain review analysis on four popular review datasets: Amazon, Yelp, Steam, IMDb. The analysis is performed using Hadoop and Spark, which allows for efficient and scalable processing of large datasets. By examining close to 12 million reviews from these four online forums, we hope to uncover interesting trends in sales and customer sentiment over the years. Our analysis will include a study of the number of reviews and their distribution over time, as well as an examination of the relationship between various review attributes such as upvotes, creation time, rating, and sentiment. By comparing the reviews across different domains, we hope to gain insight into the factors that drive customer satisfaction and engagement in different product categories.
MTGFlow: Unsupervised Multivariate Time Series Anomaly Detection via Dynamic Graph and Entity-aware Normalizing Flow
Aug 03, 2022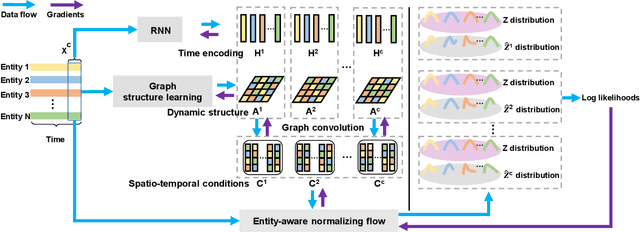

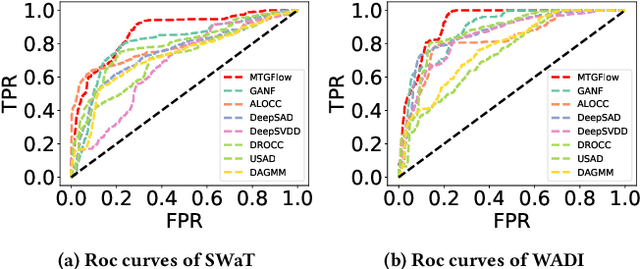

Multivariate time series anomaly detection has been extensively studied under the semi-supervised setting, where a training dataset with all normal instances is required. However, preparing such a dataset is very laborious since each single data instance should be fully guaranteed to be normal. It is, therefore, desired to explore multivariate time series anomaly detection methods based on the dataset without any label knowledge. In this paper, we propose MTGFlow, an unsupervised anomaly detection approach for Multivariate Time series anomaly detection via dynamic Graph and entity-aware normalizing Flow, leaning only on a widely accepted hypothesis that abnormal instances exhibit sparse densities than the normal. However, the complex interdependencies among entities and the diverse inherent characteristics of each entity pose significant challenges on the density estimation, let alone to detect anomalies based on the estimated possibility distribution. To tackle these problems, we propose to learn the mutual and dynamic relations among entities via a graph structure learning model, which helps to model accurate distribution of multivariate time series. Moreover, taking account of distinct characteristics of the individual entities, an entity-aware normalizing flow is developed to describe each entity into a parameterized normal distribution, thereby producing fine-grained density estimation. Incorporating these two strategies, MTGFlowachieves superior anomaly detection performance. Experiments on the real-world datasets are conducted, demonstrating that MTGFlow outperforms the state-of-the-art (SOTA) by 5.0% and 1.6% AUROC for SWaT and WADI datasets respectively. Also, through the anomaly scores contributed by individual entities, MTGFlow can provide explanation information for the detection results.
FastML Science Benchmarks: Accelerating Real-Time Scientific Edge Machine Learning
Jul 16, 2022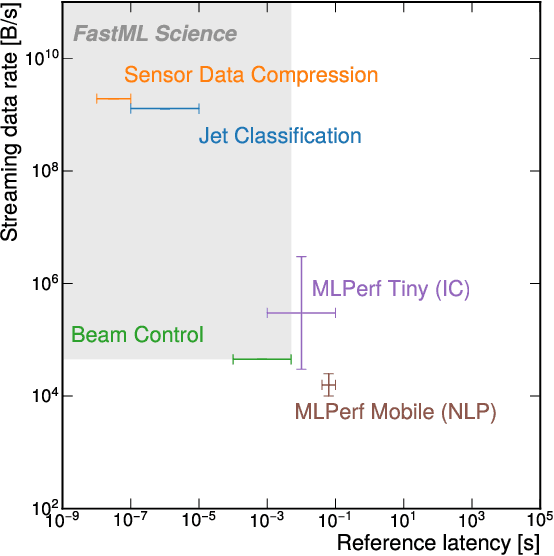
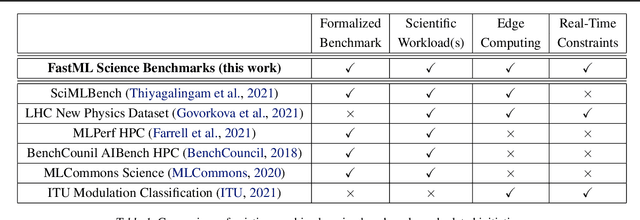
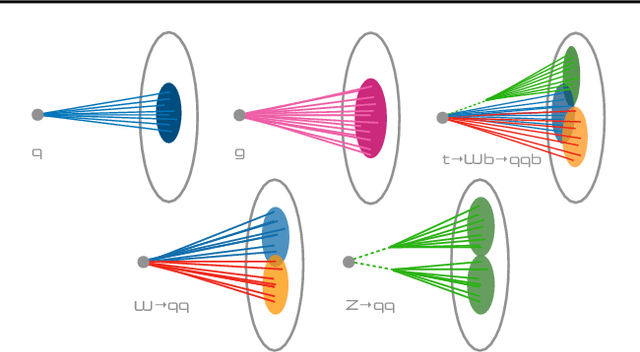

Applications of machine learning (ML) are growing by the day for many unique and challenging scientific applications. However, a crucial challenge facing these applications is their need for ultra low-latency and on-detector ML capabilities. Given the slowdown in Moore's law and Dennard scaling, coupled with the rapid advances in scientific instrumentation that is resulting in growing data rates, there is a need for ultra-fast ML at the extreme edge. Fast ML at the edge is essential for reducing and filtering scientific data in real-time to accelerate science experimentation and enable more profound insights. To accelerate real-time scientific edge ML hardware and software solutions, we need well-constrained benchmark tasks with enough specifications to be generically applicable and accessible. These benchmarks can guide the design of future edge ML hardware for scientific applications capable of meeting the nanosecond and microsecond level latency requirements. To this end, we present an initial set of scientific ML benchmarks, covering a variety of ML and embedded system techniques.
Plotly-Resampler: Effective Visual Analytics for Large Time Series
Jun 17, 2022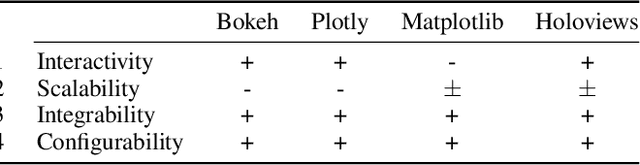
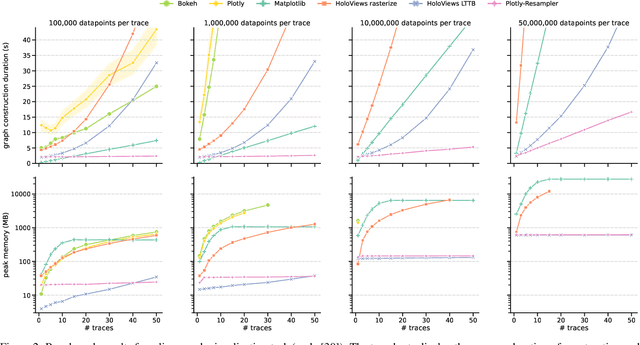
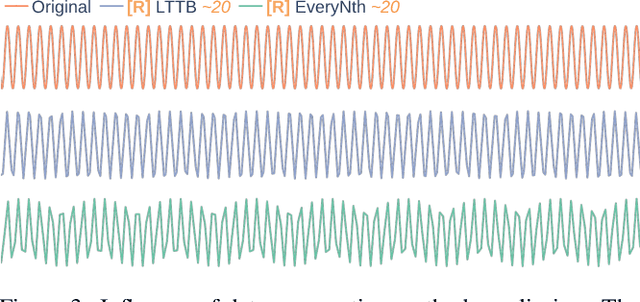
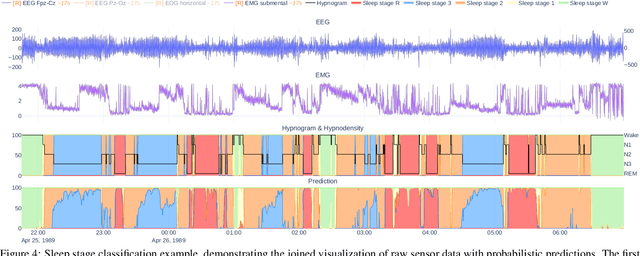
Visual analytics is arguably the most important step in getting acquainted with your data. This is especially the case for time series, as this data type is hard to describe and cannot be fully understood when using for example summary statistics. To realize effective time series visualization, four requirements have to be met; a tool should be (1) interactive, (2) scalable to millions of data points, (3) integrable in conventional data science environments, and (4) highly configurable. We observe that open source Python visualization toolkits empower data scientists in most visual analytics tasks, but lack the combination of scalability and interactivity to realize effective time series visualization. As a means to facilitate these requirements, we created Plotly-Resampler, an open source Python library. Plotly-Resampler is an add-on for Plotly's Python bindings, enhancing line chart scalability on top of an interactive toolkit by aggregating the underlying data depending on the current graph view. Plotly-Resampler is built to be snappy, as the reactivity of a tool qualitatively affects how analysts visually explore and analyze data. A benchmark task highlights how our toolkit scales better than alternatives in terms of number of samples and time series. Additionally, Plotly-Resampler's flexible data aggregation functionality paves the path towards researching novel aggregation techniques. Plotly-Resampler's integrability, together with its configurability, convenience, and high scalability, allows to effectively analyze high-frequency data in your day-to-day Python environment.
Dissecting the Effects of SGD Noise in Distinct Regimes of Deep Learning
Jan 31, 2023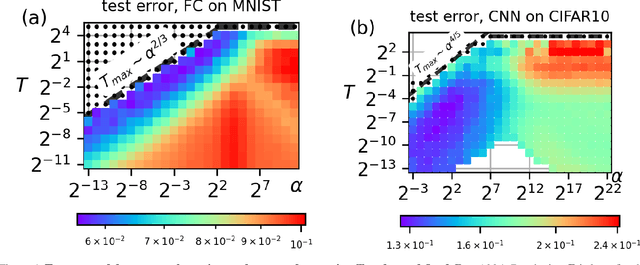
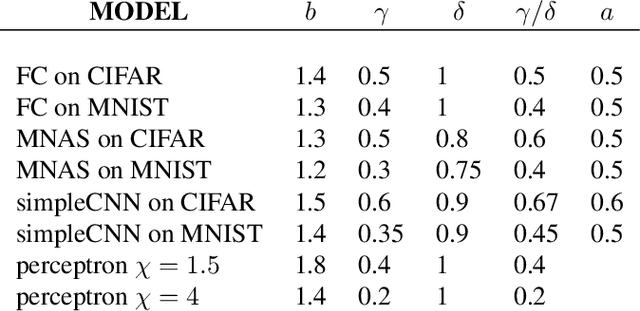
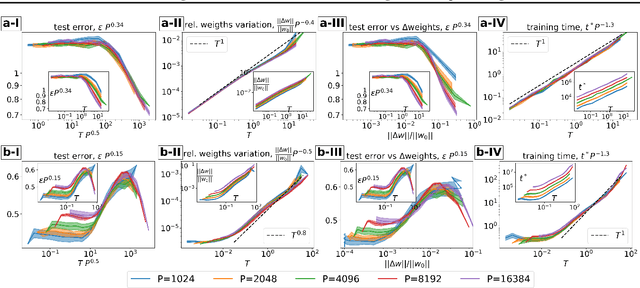
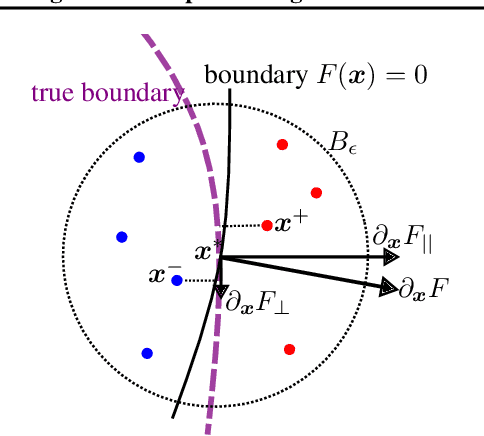
Understanding when the noise in stochastic gradient descent (SGD) affects generalization of deep neural networks remains a challenge, complicated by the fact that networks can operate in distinct training regimes. Here we study how the magnitude of this noise $T$ affects performance as the size of the training set $P$ and the scale of initialization $\alpha$ are varied. For gradient descent, $\alpha$ is a key parameter that controls if the network is `lazy' ($\alpha\gg 1$) or instead learns features ($\alpha\ll 1$). For classification of MNIST and CIFAR10 images, our central results are: (i) obtaining phase diagrams for performance in the $(\alpha,T)$ plane. They show that SGD noise can be detrimental or instead useful depending on the training regime. Moreover, although increasing $T$ or decreasing $\alpha$ both allow the net to escape the lazy regime, these changes can have opposite effects on performance. (ii) Most importantly, we find that key dynamical quantities (including the total variations of weights during training) depend on both $T$ and $P$ as power laws, and the characteristic temperature $T_c$, where the noise of SGD starts affecting performance, is a power law of $P$. These observations indicate that a key effect of SGD noise occurs late in training, by affecting the stopping process whereby all data are fitted. We argue that due to SGD noise, nets must develop a stronger `signal', i.e. larger informative weights, to fit the data, leading to a longer training time. The same effect occurs at larger training set $P$. We confirm this view in the perceptron model, where signal and noise can be precisely measured. Interestingly, exponents characterizing the effect of SGD depend on the density of data near the decision boundary, as we explain.
Telerobotic Mars Mission for Lava Tube Exploration and Examination of Life
Jan 31, 2023



The general profile and overarching goal of this proposed mission is to pioneer potentially highly beneficial (even vital) and cost-effective techniques for the future human colonization of Mars. Adopting radically new and disruptive solutions untested in the Martian context, our approach is one of high risk and high reward. The real possibility of such a solution failing has prompted us to base our mission architecture around a rover carrying a set of 6 distinct experimental payloads, each capable of operating independently on the others, thus substantially increasing the chances of the mission yielding some valuable findings. At the same time, we sought to exploit available synergies by assembling a combination of payloads that would together form a coherent experimental ecosystem, with each payload providing potential value to the others. Apart from providing such a testbed for evaluation of novel technological solutions, another aim of our proposed mission is to help generate scientific know-how enhancing our understanding of the Red Planet. To this end, our mission takes aim at the Nili-Fossae region, rich in natural resources (and carbonates in particular), past water repositories and signs of volcanic activity. With our proposed experimental payloads, we intend to explore existing lava-tubes, search for signs of past life and assess their potentially valuable geological features for future base building. We will evaluate biomatter in the form of plants and fungi as possible food and base-building materials respectively. Finally, we seek to explore a variety of novel power generation techniques using the Martian atmosphere and gravity. As detailed throughout the remainder of this chapter, this assemblage of experimental payloads, then, constitutes the backbone of our proposed telerobotic mission to Mars.
Dynamics-informed deconvolutional neural networks for super-resolution identification of regime changes in epidemiological time series
Sep 16, 2022Inferring the timing and amplitude of perturbations in epidemiological systems from their stochastically spread low-resolution outcomes is as relevant as challenging. It is a requirement for current approaches to overcome the need to know the details of the perturbations to proceed with the analyses. However, the general problem of connecting epidemiological curves with the underlying incidence lacks the highly effective methodology present in other inverse problems, such as super-resolution and dehazing from computer vision. Here, we develop an unsupervised physics-informed convolutional neural network approach in reverse to connect death records with incidence that allows the identification of regime changes at single-day resolution. Applied to COVID-19 data with proper regularization and model-selection criteria, the approach can identify the implementation and removal of lockdowns and other nonpharmaceutical interventions with 0.93-day accuracy over the time span of a year.
Semantic Communications with Discrete-time Analog Transmission: A PAPR Perspective
Aug 17, 2022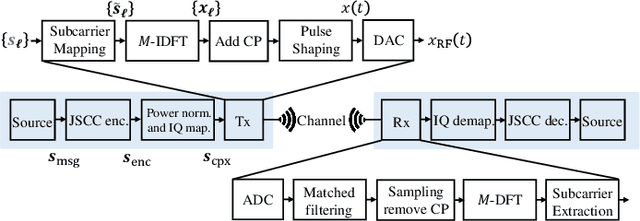
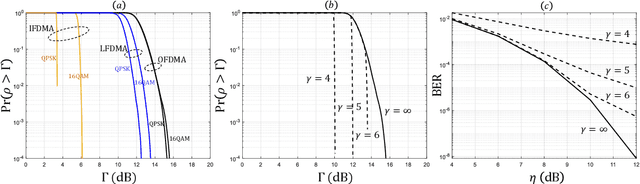
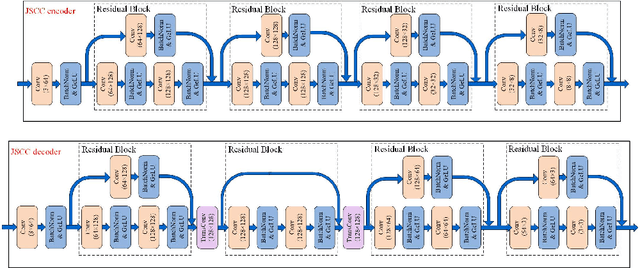
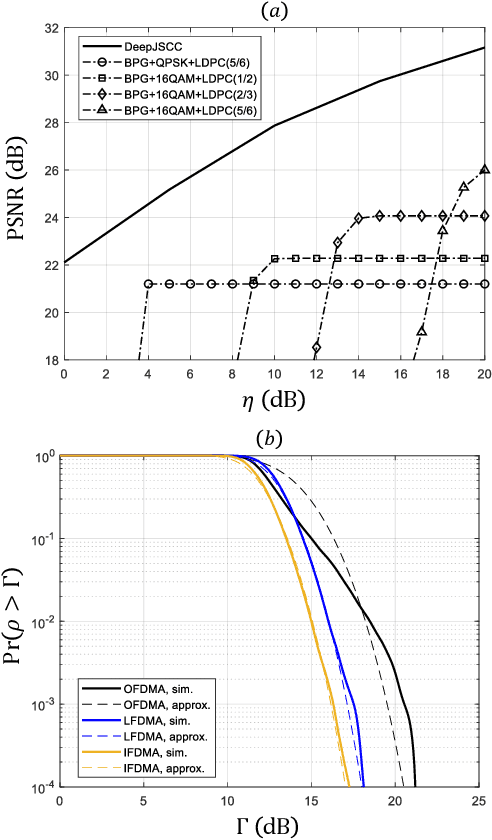
Recent progress in deep learning (DL)-based joint source-channel coding (DeepJSCC) has led to a new paradigm of semantic communications. Two salient features of DeepJSCC-based semantic communications are the exploitation of semantic-aware features directly from the source signal, and the discrete-time analog transmission (DTAT) of these features. Compared with traditional digital communications, semantic communications with DeepJSCC provide superior reconstruction performance at the receiver and graceful degradation with diminishing channel quality, but also exhibit a large peak-to-average power ratio (PAPR) in the transmitted signal. An open question has been whether the gains of DeepJSCC come from the additional freedom brought by the high-PAPR continuous-amplitude signal. In this paper, we address this question by exploring three PAPR reduction techniques in the application of image transmission. We confirm that the superior image reconstruction performance of DeepJSCC-based semantic communications can be retained while the transmitted PAPR is suppressed to an acceptable level. This observation is an important step towards the implementation of DeepJSCC in practical semantic communication systems.