 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigger Isn't Always Memorizing: Early Stopping Overparameterized Diffusion Models
May 22, 2025



Diffusion probabilistic models have become a cornerstone of modern generative AI, yet the mechanisms underlying their generalization remain poorly understood. In fact, if these models were perfectly minimizing their training loss, they would just generate data belonging to their training set, i.e., memorize, as empirically found in the overparameterized regime. We revisit this view by showing that, in highly overparameterized diffusion models, generalization in natural data domains is progressively achieved during training before the onset of memorization. Our results, ranging from image to language diffusion models, systematically support the empirical law that memorization time is proportional to the dataset size. Generalization vs. memorization is then best understood as a competition between time scales. We show that this phenomenology is recovered in diffusion models learning a simple probabilistic context-free grammar with random rules, where generalization corresponds to the hierarchical acquisition of deeper grammar rules as training time grows, and the generalization cost of early stopping can be characterized. We summarize these results in a phase diagram. Overall, our results support that a principled early-stopping criterion - scaling with dataset size - can effectively optimize generalization while avoiding memorization, with direct implications for hyperparameter transfer and privacy-sensitive applications.
Scaling Laws and Representation Learning in Simple Hierarchical Languages: Transformers vs. Convolutional Architectures
May 11, 2025



How do neural language models acquire a language's structure when trained for next-token prediction? We address this question by deriving theoretical scaling laws for neural network performance on synthetic datasets generated by the Random Hierarchy Model (RHM) -- an ensemble of probabilistic context-free grammars designed to capture the hierarchical structure of natural language while remaining analytically tractable. Previously, we developed a theory of representation learning based on data correlations that explains how deep learning models capture the hierarchical structure of the data sequentially, one layer at a time. Here, we extend our theoretical framework to account for architectural differences. In particular, we predict and empirically validate that convolutional networks, whose structure aligns with that of the generative process through locality and weight sharing, enjoy a faster scaling of performance compared to transformer models, which rely on global self-attention mechanisms. This finding clarifies the architectural biases underlying neural scaling laws and highlights how representation learning is shaped by the interaction between model architecture and the statistical properties of data.
How compositional generalization and creativity improve as diffusion models are trained
Feb 17, 2025



Natural data is often organized as a hierarchical composition of features. How many samples do generative models need to learn the composition rules, so as to produce a combinatorial number of novel data? What signal in the data is exploited to learn? We investigate these questions both theoretically and empirically. Theoretically, we consider diffusion models trained on simple probabilistic context-free grammars - tree-like graphical models used to represent the structure of data such as language and images. We demonstrate that diffusion models learn compositional rules with the sample complexity required for clustering features with statistically similar context, a process similar to the word2vec algorithm. However, this clustering emerges hierarchically: higher-level, more abstract features associated with longer contexts require more data to be identified. This mechanism leads to a sample complexity that scales polynomially with the said context size. As a result, diffusion models trained on intermediate dataset size generate data coherent up to a certain scale, but that lacks global coherence. We test these predictions in different domains, and find remarkable agreement: both generated texts and images achieve progressively larger coherence lengths as the training time or dataset size grows. We discuss connections between the hierarchical clustering mechanism we introduce here and the renormalization group in physics.
Probing the Latent Hierarchical Structure of Data via Diffusion Models
Oct 17, 2024



High-dimensional data must be highly structured to be learnable. Although the compositional and hierarchical nature of data is often put forward to explain learnability, quantitative measurements establishing these properties are scarce. Likewise, accessing the latent variables underlying such a data structure remains a challenge. In this work, we show that forward-backward experiments in diffusion-based models, where data is noised and then denoised to generate new samples, are a promising tool to probe the latent structure of data. We predict in simple hierarchical models that, in this process, changes in data occur by correlated chunks, with a length scale that diverges at a noise level where a phase transition is known to take place. Remarkably, we confirm this prediction in both text and image datasets using state-of-the-art diffusion models. Our results show how latent variable changes manifest in the data and establish how to measure these effects in real data using diffusion models.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
A Phase Transition in Diffusion Models Reveals the Hierarchical Nature of Data
Mar 04, 2024



Understanding the structure of real data is paramount in advancing modern deep-learning methodologies. Natural data such as images are believed to be composed of features organised in a hierarchical and combinatorial manner, which neural networks capture during learning. Recent advancements show that diffusion models can generate high-quality images, hinting at their ability to capture this underlying structure. We study this phenomenon in a hierarchical generative model of data. We find that the backward diffusion process acting after a time $t$ is governed by a phase transition at some threshold time, where the probability of reconstructing high-level features, like the class of an image, suddenly drops. Instead, the reconstruction of low-level features, such as specific details of an image, evolves smoothly across the whole diffusion process. This result implies that at times beyond the transition, the class has changed but the generated sample may still be composed of low-level elements of the initial image. We validate these theoretical insights through numerical experiments on class-unconditional ImageNet diffusion models. Our analysis characterises the relationship between time and scale in diffusion models and puts forward generative models as powerful tools to model combinatorial data properties.
On the different regimes of Stochastic Gradient Descent
Sep 21, 2023Modern deep networks are trained with stochastic gradient descent (SGD) whose key parameters are the number of data considered at each step or batch size $B$, and the step size or learning rate $\eta$. For small $B$ and large $\eta$, SGD corresponds to a stochastic evolution of the parameters, whose noise amplitude is governed by the `temperature' $T\equiv \eta/B$. Yet this description is observed to break down for sufficiently large batches $B\geq B^*$, or simplifies to gradient descent (GD) when the temperature is sufficiently small. Understanding where these cross-overs take place remains a central challenge. Here we resolve these questions for a teacher-student perceptron classification model, and show empirically that our key predictions still apply to deep networks. Specifically, we obtain a phase diagram in the $B$-$\eta$ plane that separates three dynamical phases: $\textit{(i)}$ a noise-dominated SGD governed by temperature, $\textit{(ii)}$ a large-first-step-dominated SGD and $\textit{(iii)}$ GD. These different phases also corresponds to different regimes of generalization error. Remarkably, our analysis reveals that the batch size $B^*$ separating regimes $\textit{(i)}$ and $\textit{(ii)}$ scale with the size $P$ of the training set, with an exponent that characterizes the hardness of the classification problem.
Dissecting the Effects of SGD Noise in Distinct Regimes of Deep Learning
Jan 31, 2023Understanding when the noise in stochastic gradient descent (SGD) affects generalization of deep neural networks remains a challenge, complicated by the fact that networks can operate in distinct training regimes. Here we study how the magnitude of this noise $T$ affects performance as the size of the training set $P$ and the scale of initialization $\alpha$ are varied. For gradient descent, $\alpha$ is a key parameter that controls if the network is `lazy' ($\alpha\gg 1$) or instead learns features ($\alpha\ll 1$). For classification of MNIST and CIFAR10 images, our central results are: (i) obtaining phase diagrams for performance in the $(\alpha,T)$ plane. They show that SGD noise can be detrimental or instead useful depending on the training regime. Moreover, although increasing $T$ or decreasing $\alpha$ both allow the net to escape the lazy regime, these changes can have opposite effects on performance. (ii) Most importantly, we find that key dynamical quantities (including the total variations of weights during training) depend on both $T$ and $P$ as power laws, and the characteristic temperature $T_c$, where the noise of SGD starts affecting performance, is a power law of $P$. These observations indicate that a key effect of SGD noise occurs late in training, by affecting the stopping process whereby all data are fitted. We argue that due to SGD noise, nets must develop a stronger `signal', i.e. larger informative weights, to fit the data, leading to a longer training time. The same effect occurs at larger training set $P$. We confirm this view in the perceptron model, where signal and noise can be precisely measured. Interestingly, exponents characterizing the effect of SGD depend on the density of data near the decision boundary, as we explain.
Failure and success of the spectral bias prediction for Kernel Ridge Regression: the case of low-dimensional data
Feb 16, 2022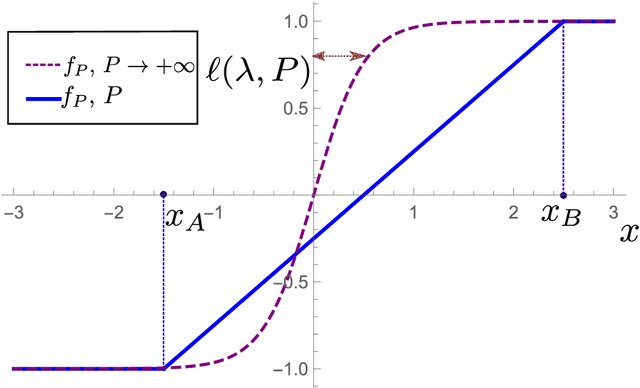
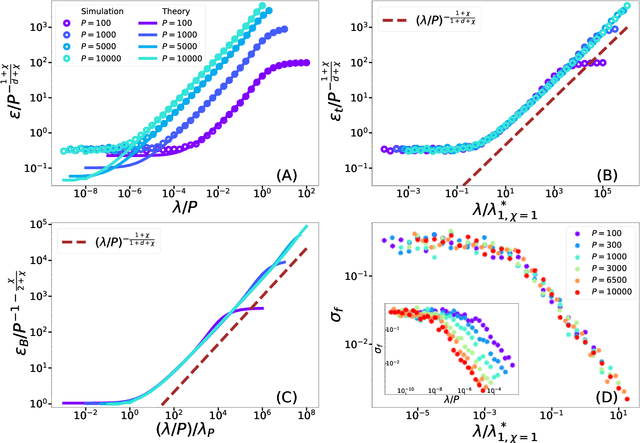
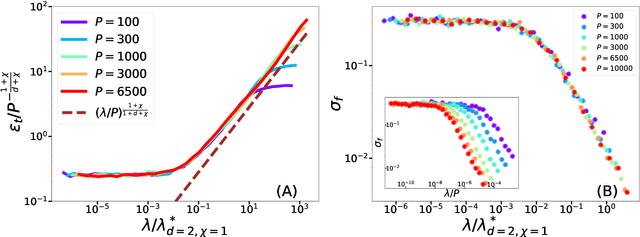
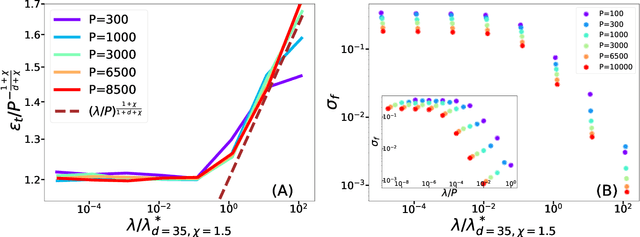
Recently, several theories including the replica method made predictions for the generalization error of Kernel Ridge Regression. In some regimes, they predict that the method has a `spectral bias': decomposing the true function $f^*$ on the eigenbasis of the kernel, it fits well the coefficients associated with the O(P) largest eigenvalues, where $P$ is the size of the training set. This prediction works very well on benchmark data sets such as images, yet the assumptions these approaches make on the data are never satisfied in practice. To clarify when the spectral bias prediction holds, we first focus on a one-dimensional model where rigorous results are obtained and then use scaling arguments to generalize and test our findings in higher dimensions. Our predictions include the classification case $f(x)=$sign$(x_1)$ with a data distribution that vanishes at the decision boundary $p(x)\sim x_1^{\chi}$. For $\chi>0$ and a Laplace kernel, we find that (i) there exists a cross-over ridge $\lambda^*_{d,\chi}(P)\sim P^{-\frac{1}{d+\chi}}$ such that for $\lambda\gg \lambda^*_{d,\chi}(P)$, the replica method applies, but not for $\lambda\ll\lambda^*_{d,\chi}(P)$, (ii) in the ridge-less case, spectral bias predicts the correct training curve exponent only in the limit $d\rightarrow\infty$.