 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Minimax Optimality of Model-based Robust Reinforcement Learning
Feb 10, 2023
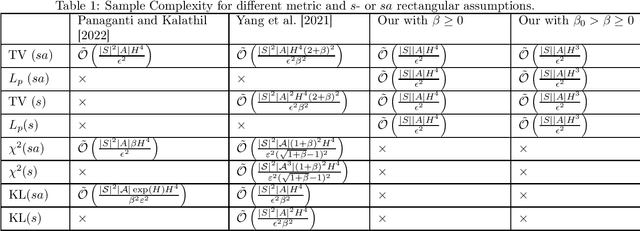
We study the sample complexity of obtaining an $\epsilon$-optimal policy in \emph{Robust} discounted Markov Decision Processes (RMDPs), given only access to a generative model of the nominal kernel. This problem is widely studied in the non-robust case, and it is known that any planning approach applied to an empirical MDP estimated with $\tilde{\mathcal{O}}(\frac{H^3 \mid S \mid\mid A \mid}{\epsilon^2})$ samples provides an $\epsilon$-optimal policy, which is minimax optimal. Results in the robust case are much more scarce. For $sa$- (resp $s$-)rectangular uncertainty sets, the best known sample complexity is $\tilde{\mathcal{O}}(\frac{H^4 \mid S \mid^2\mid A \mid}{\epsilon^2})$ (resp. $\tilde{\mathcal{O}}(\frac{H^4 \mid S \mid^2\mid A \mid^2}{\epsilon^2})$), for specific algorithms and when the uncertainty set is based on the total variation (TV), the KL or the Chi-square divergences. In this paper, we consider uncertainty sets defined with an $L_p$-ball (recovering the TV case), and study the sample complexity of \emph{any} planning algorithm (with high accuracy guarantee on the solution) applied to an empirical RMDP estimated using the generative model. In the general case, we prove a sample complexity of $\tilde{\mathcal{O}}(\frac{H^4 \mid S \mid\mid A \mid}{\epsilon^2})$ for both the $sa$- and $s$-rectangular cases (improvements of $\mid S \mid$ and $\mid S \mid\mid A \mid$ respectively). When the size of the uncertainty is small enough, we improve the sample complexity to $\tilde{\mathcal{O}}(\frac{H^3 \mid S \mid\mid A \mid }{\epsilon^2})$, recovering the lower-bound for the non-robust case for the first time and a robust lower-bound when the size of the uncertainty is small enough.
Privacy Against Agnostic Inference Attack in Vertical Federated Learning
Feb 10, 2023A novel form of inference attack in vertical federated learning (VFL) is proposed, where two parties collaborate in training a machine learning (ML) model. Logistic regression is considered for the VFL model. One party, referred to as the active party, possesses the ground truth labels of the samples in the training phase, while the other, referred to as the passive party, only shares a separate set of features corresponding to these samples. It is shown that the active party can carry out inference attacks on both training and prediction phase samples by acquiring an ML model independently trained on the training samples available to them. This type of inference attack does not require the active party to be aware of the score of a specific sample, hence it is referred to as an agnostic inference attack. It is shown that utilizing the observed confidence scores during the prediction phase, before the time of the attack, can improve the performance of the active party's autonomous model, and thus improve the quality of the agnostic inference attack. As a countermeasure, privacy-preserving schemes (PPSs) are proposed. While the proposed schemes preserve the utility of the VFL model, they systematically distort the VFL parameters corresponding to the passive party's features. The level of the distortion imposed on the passive party's parameters is adjustable, giving rise to a trade-off between privacy of the passive party and interpretabiliy of the VFL outcomes by the active party. The distortion level of the passive party's parameters could be chosen carefully according to the privacy and interpretabiliy concerns of the passive and active parties, respectively, with the hope of keeping both parties (partially) satisfied. Finally, experimental results demonstrate the effectiveness of the proposed attack and the PPSs.
Industrial and Medical Anomaly Detection Through Cycle-Consistent Adversarial Networks
Feb 10, 2023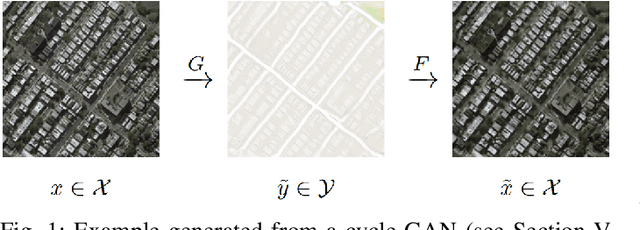
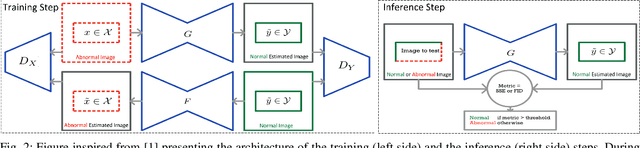
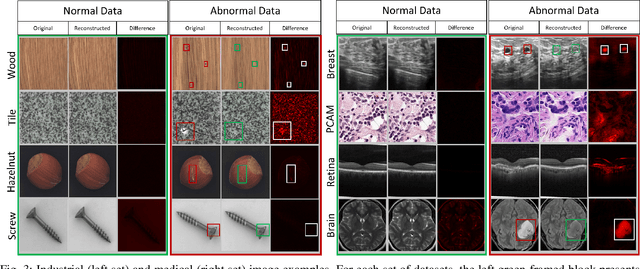
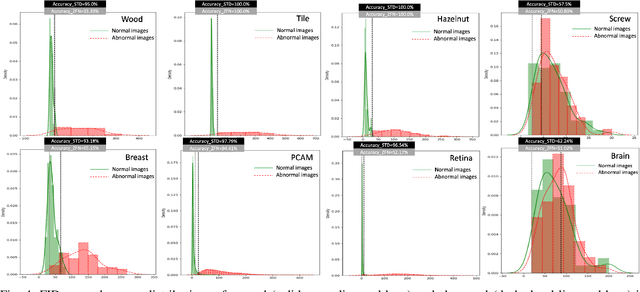
In this study, a new Anomaly Detection (AD) approach for real-world images is proposed. This method leverages the theoretical strengths of unsupervised learning and the data availability of both normal and abnormal classes. The AD is often formulated as an unsupervised task motivated by the frequent imbalanced nature of the datasets, as well as the challenge of capturing the entirety of the abnormal class. Such methods only rely on normal images during training, which are devoted to be reconstructed through an autoencoder architecture for instance. However, the information contained in the abnormal data is also valuable for this reconstruction. Indeed, the model would be able to identify its weaknesses by better learning how to transform an abnormal (or normal) image into a normal (or abnormal) image. Each of these tasks could help the entire model to learn with higher precision than a single normal to normal reconstruction. To address this challenge, the proposed method utilizes Cycle-Generative Adversarial Networks (Cycle-GANs) for abnormal-to-normal translation. To the best of our knowledge, this is the first time that Cycle-GANs have been studied for this purpose. After an input image has been reconstructed by the normal generator, an anomaly score describes the differences between the input and reconstructed images. Based on a threshold set with a business quality constraint, the input image is then flagged as normal or not. The proposed method is evaluated on industrial and medical images, including cases with balanced datasets and others with as few as 30 abnormal images. The results demonstrate accurate performance and good generalization for all kinds of anomalies, specifically for texture-shaped images where the method reaches an average accuracy of 97.2% (85.4% with an additional zero false negative constraint).
OppLoD: the Opponency based Looming Detector, Model Extension of Looming Sensitivity from LGMD to LPLC2
Feb 10, 2023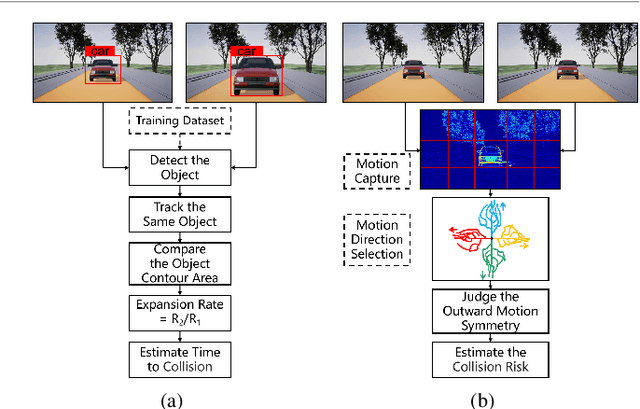
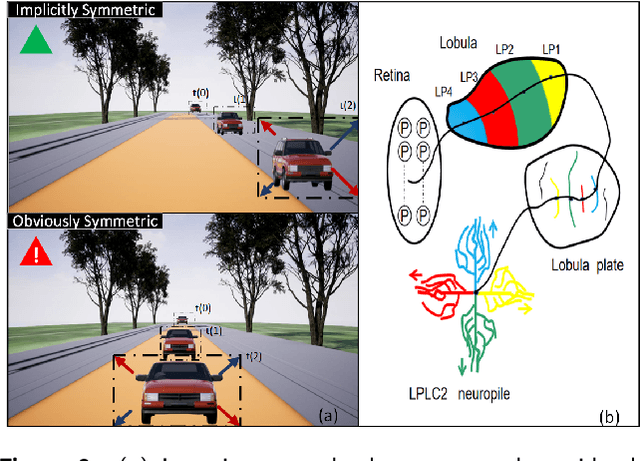
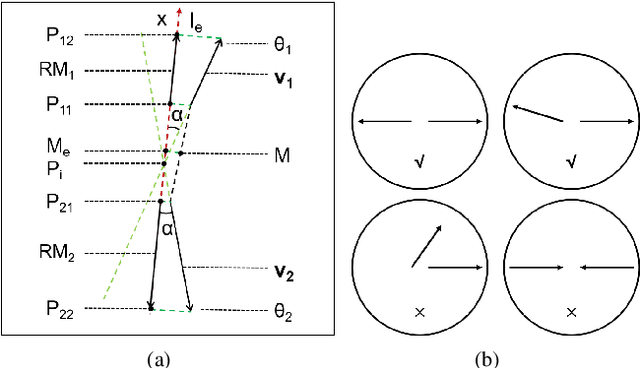
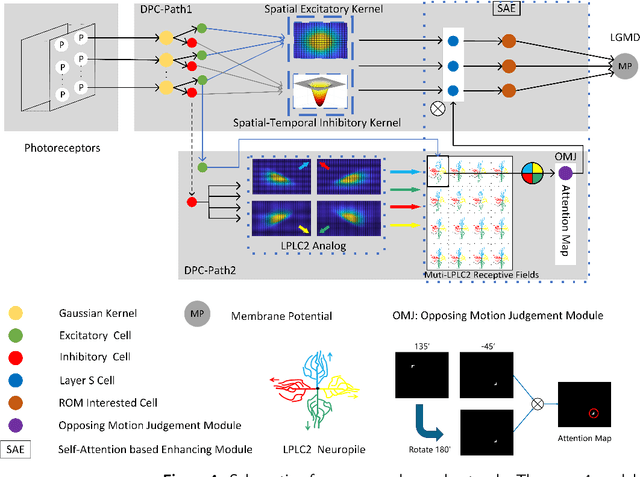
Looming detection plays an important role in insect collision prevention systems. As a vital capability evolutionary survival, it has been extensively studied in neuroscience and is attracting increasing research interest in robotics due to its close relationship with collision detection and navigation. Visual cues such as angular size, angular velocity, and expansion have been widely studied for looming detection by means of optic flow or elementary neural computing research. However, a critical visual motion cue has been long neglected because it is so easy to be confused with expansion, that is radial-opponent-motion (ROM). Recent research on the discovery of LPLC2, a ROM-sensitive neuron in Drosophila, has revealed its ultra-selectivity because it only responds to stimuli with focal, outward movement. This characteristic of ROM-sensitivity is consistent with the demand for collision detection because it is strongly associated with danger looming that is moving towards the center of the observer. Thus, we hope to extend the well-studied neural model of the lobula giant movement detector (LGMD) with ROM-sensibility in order to enhance robustness and accuracy at the same time. In this paper, we investigate the potential to extend an image velocity-based looming detector, the lobula giant movement detector (LGMD), with ROM-sensibility. To achieve this, we propose the mathematical definition of ROM and its main property, the radial motion opponency (RMO). Then, a synaptic neuropile that analogizes the synaptic processing of LPLC2 is proposed in the form of lateral inhibition and attention. Thus, our proposed model is the first to perform both image velocity selectivity and ROM sensitivity. Systematic experiments are conducted to exhibit the huge potential of the proposed bio-inspired looming detector.
Generalizable Memory-driven Transformer for Multivariate Long Sequence Time-series Forecasting
Jul 16, 2022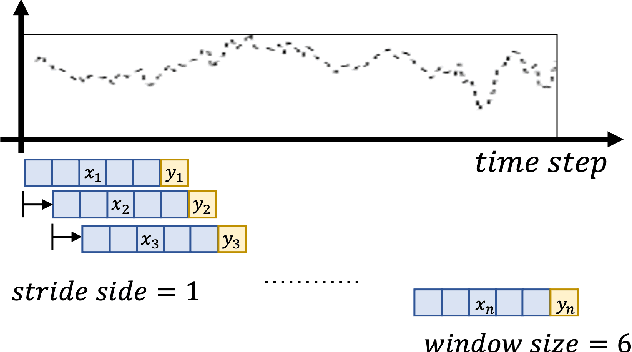
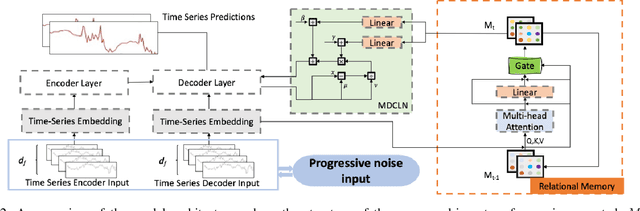
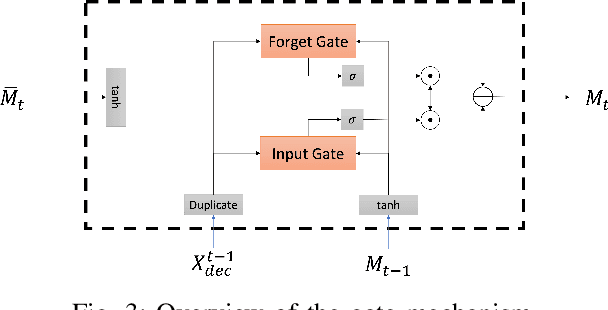
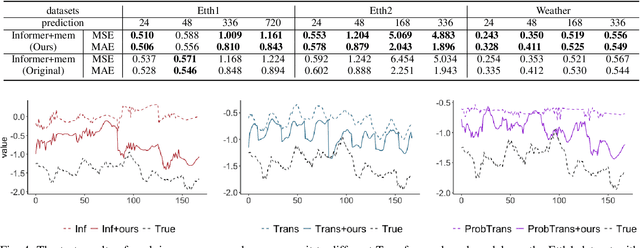
Multivariate long sequence time-series forecasting (M-LSTF) is a practical but challenging problem. Unlike traditional timer-series forecasting tasks, M-LSTF tasks are more challenging from two aspects: 1) M-LSTF models need to learn time-series patterns both within and between multiple time features; 2) Under the rolling forecasting setting, the similarity between two consecutive training samples increases with the increasing prediction length, which makes models more prone to overfitting. In this paper, we propose a generalizable memory-driven Transformer to target M-LSTF problems. Specifically, we first propose a global-level memory component to drive the forecasting procedure by integrating multiple time-series features. In addition, we adopt a progressive fashion to train our model to increase its generalizability, in which we gradually introduce Bernoulli noises to training samples. Extensive experiments have been performed on five different datasets across multiple fields. Experimental results demonstrate that our approach can be seamlessly plugged into varying Transformer-based models to improve their performances up to roughly 30%. Particularly, this is the first work to specifically focus on the M-LSTF tasks to the best of our knowledge.
Temporal Disaggregation of the Cumulative Grass Growth
Dec 21, 2022Information on the grass growth over a year is essential for some models simulating the use of this resource to feed animals on pasture or at barn with hay or grass silage. Unfortunately, this information is rarely available. The challenge is to reconstruct grass growth from two sources of information: usual daily climate data (rainfall, radiation, etc.) and cumulative growth over the year. We have to be able to capture the effect of seasonal climatic events which are known to distort the growth curve within the year. In this paper, we formulate this challenge as a problem of disaggregating the cumulative growth into a time series. To address this problem, our method applies time series forecasting using climate information and grass growth from previous time steps. Several alternatives of the method are proposed and compared experimentally using a database generated from a grassland process-based model. The results show that our method can accurately reconstruct the time series, independently of the use of the cumulative growth information.
GRU-TV: Time- and velocity-aware GRU for patient representation on multivariate clinical time-series data
May 04, 2022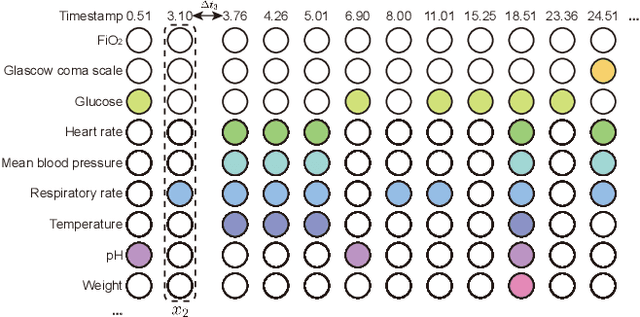
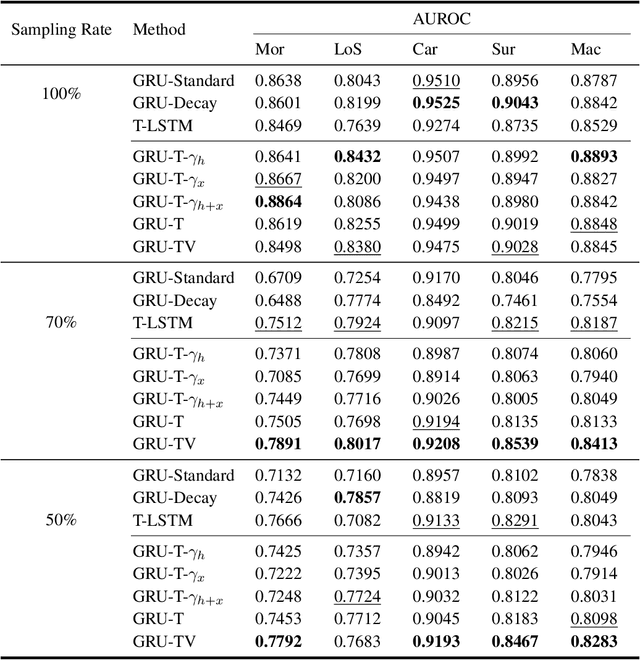
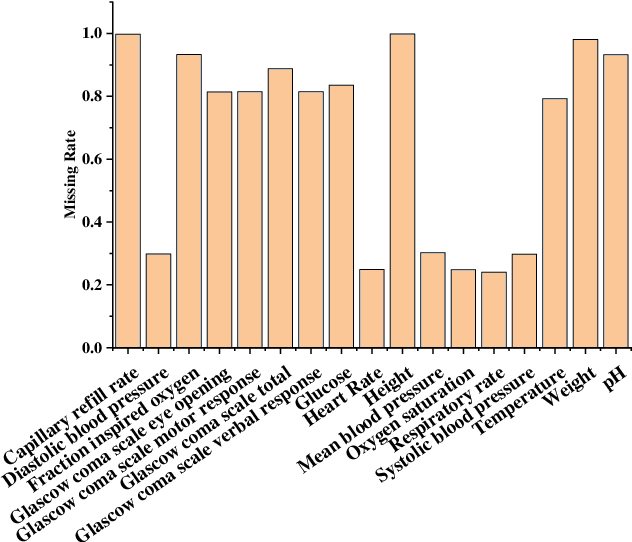
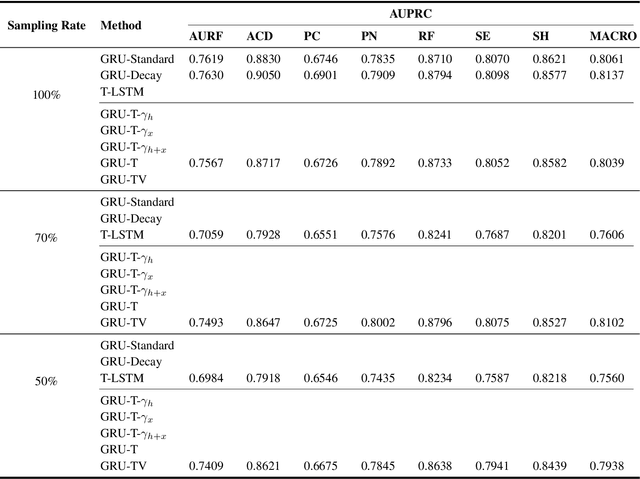
Electronic health records (EHRs) provide a rich repository to track a patient's health status. EHRs seek to fully document the patient's physiological status, and include data that is is high dimensional, heterogeneous, and multimodal. The significant differences in the sampling frequency of clinical variables can result in high missing rates and uneven time intervals between adjacent records in the multivariate clinical time-series data extracted from EHRs. Current studies using clinical time-series data for patient characterization view the patient's physiological status as a discrete process described by sporadically collected values, while the dynamics in patient's physiological status are time-continuous. In addition, recurrent neural networks (RNNs) models widely used for patient representation learning lack the perception of time intervals and velocity, which limits the ability of the model to represent the physiological status of the patient. In this paper, we propose an improved gated recurrent unit (GRU), namely time- and velocity-aware GRU (GRU-TV), for patient representation learning of clinical multivariate time-series data in a time-continuous manner. In proposed GRU-TV, the neural ordinary differential equations (ODEs) and velocity perception mechanism are used to perceive the time interval between records in the time-series data and changing rate of the patient's physiological status, respectively. Experimental results on two real-world clinical EHR datasets(PhysioNet2012, MIMIC-III) show that GRU-TV achieve state-of-the-art performance in computer aided diagnosis (CAD) tasks, and is more advantageous in processing sampled data.
Interpretable and Scalable Graphical Models for Complex Spatio-temporal Processes
Jan 15, 2023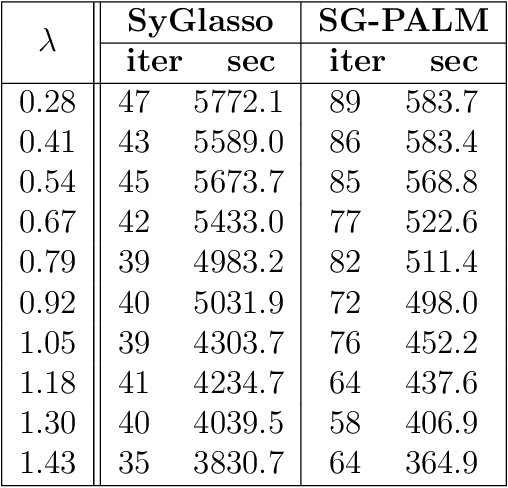
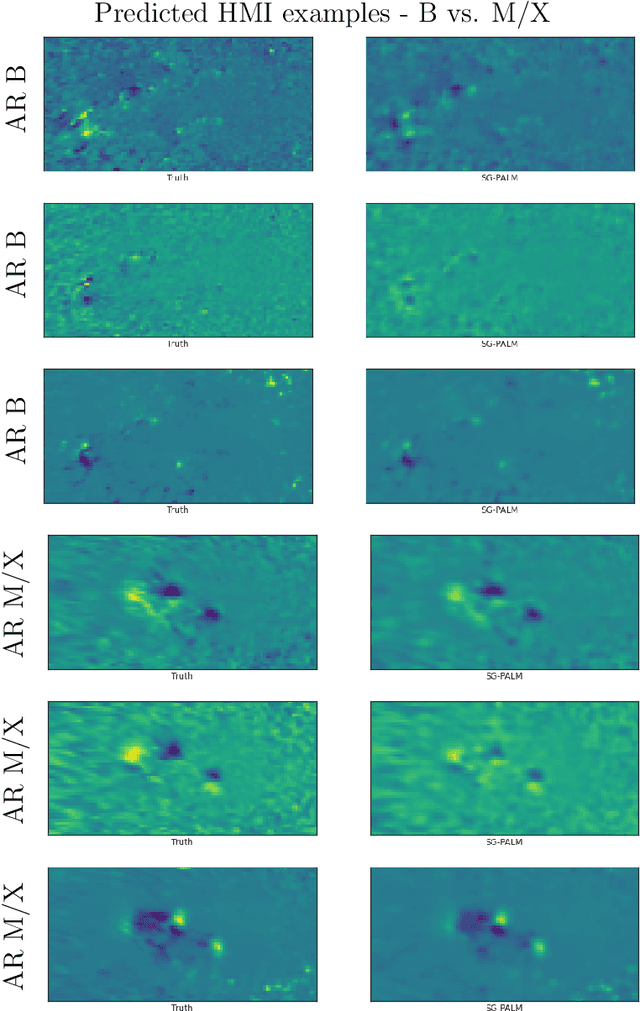
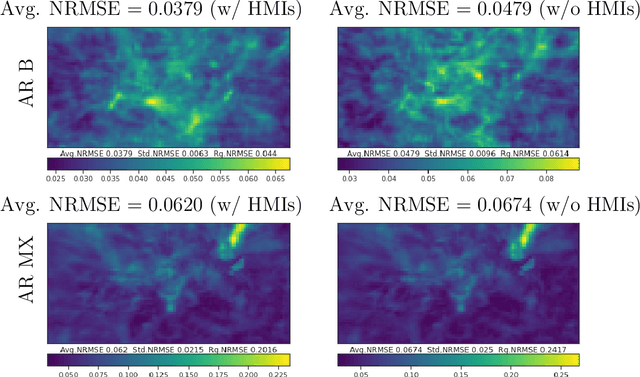
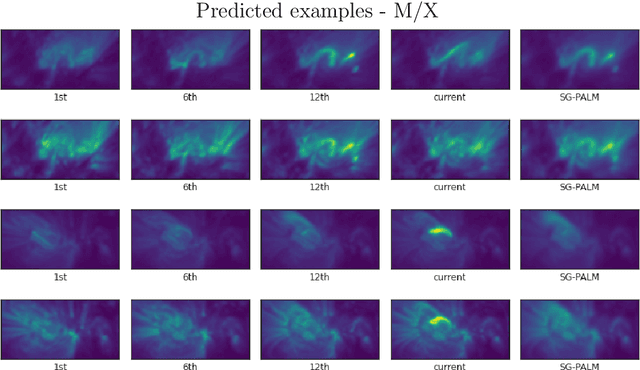
This thesis focuses on data that has complex spatio-temporal structure and on probabilistic graphical models that learn the structure in an interpretable and scalable manner. We target two research areas of interest: Gaussian graphical models for tensor-variate data and summarization of complex time-varying texts using topic models. This work advances the state-of-the-art in several directions. First, it introduces a new class of tensor-variate Gaussian graphical models via the Sylvester tensor equation. Second, it develops an optimization technique based on a fast-converging proximal alternating linearized minimization method, which scales tensor-variate Gaussian graphical model estimations to modern big-data settings. Third, it connects Kronecker-structured (inverse) covariance models with spatio-temporal partial differential equations (PDEs) and introduces a new framework for ensemble Kalman filtering that is capable of tracking chaotic physical systems. Fourth, it proposes a modular and interpretable framework for unsupervised and weakly-supervised probabilistic topic modeling of time-varying data that combines generative statistical models with computational geometric methods. Throughout, practical applications of the methodology are considered using real datasets. This includes brain-connectivity analysis using EEG data, space weather forecasting using solar imaging data, longitudinal analysis of public opinions using Twitter data, and mining of mental health related issues using TalkLife data. We show in each case that the graphical modeling framework introduced here leads to improved interpretability, accuracy, and scalability.
Radar Sensing via OTFS Signaling: A Delay Doppler Signal Processing Perspective
Jan 24, 2023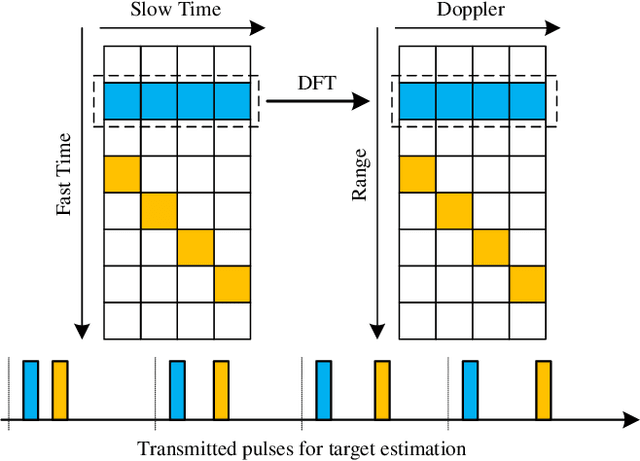
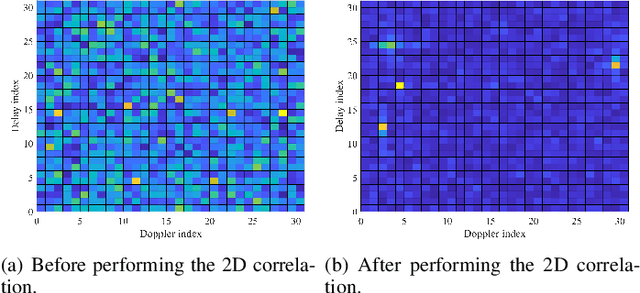
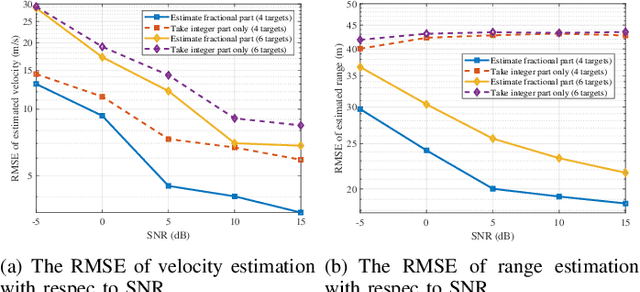
The recently proposed orthogonal time frequency space (OTFS) modulation multiplexes data symbols in the delay-Doppler (DD) domain. Since the range and velocity, which can be derived from the delay and Doppler shifts, are the parameters of interest for radar sensing, it is natural to consider implementing DD signal processing for radar sensing. In this paper, we investigate the potential connections between the OTFS and DD domain radar signal processing. Our analysis shows that the range-Doppler matrix computing process in radar sensing is exactly the demodulation of OTFS with a rectangular pulse shaping filter. Furthermore, we propose a two-dimensional (2D) correlation-based algorithm to estimate the fractional delay and Doppler parameters for radar sensing. Simulation results show that the proposed algorithm can efficiently obtain the delay and Doppler shifts associated with multiple targets.
CMOS-based area-and-power-efficient neuron and synapse circuits for time-domain analog spiking neural networks
Aug 25, 2022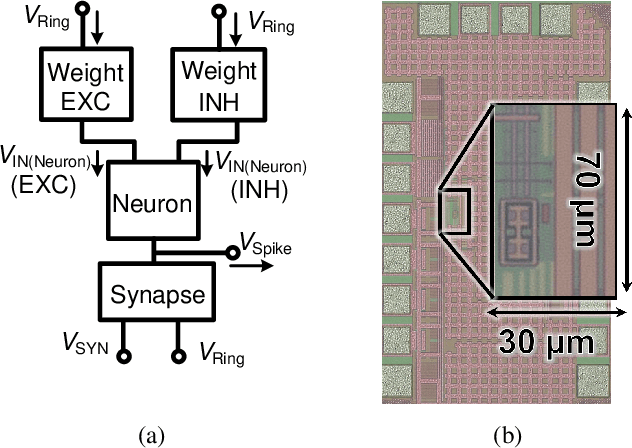
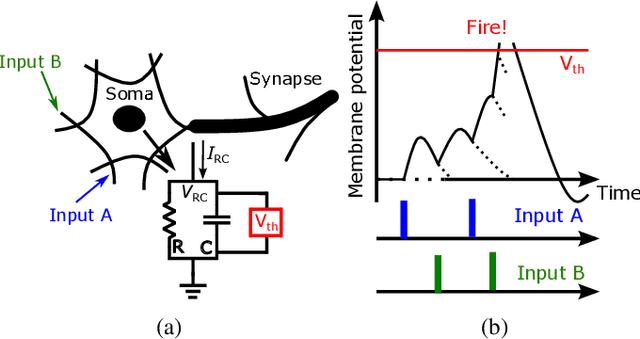
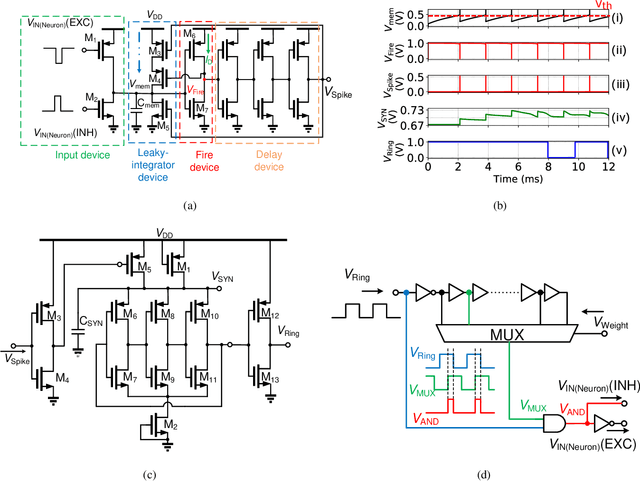
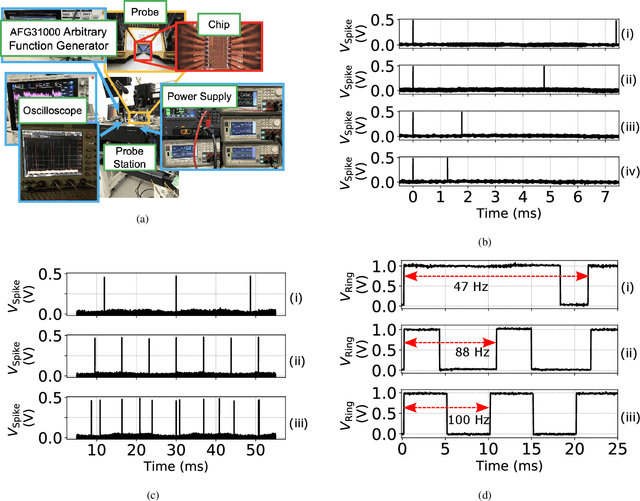
Conventional neural structures tend to communicate through analog quantities such as currents or voltages, however, as CMOS devices shrink and supply voltages decrease, the dynamic range of voltage/current-domain analog circuits becomes narrower, the available margin becomes smaller, and noise immunity decreases. More than that, the use of operational amplifiers (op-amps) and clocked or asynchronous comparators in conventional designs leads to high energy consumption and large chip area, which would be detrimental to building spiking neural networks. In view of this, we propose a neural structure for generating and transmitting time-domain signals, including a neuron module, a synapse module, and two weight modules. The proposed neural structure is driven by leakage currents in the transistor triode region and does not use op-amps and comparators, thus providing higher energy and area efficiency compared to conventional designs. In addition, the structure provides greater noise immunity due to internal communication via time-domain signals, which simplifies the wiring between the modules. The proposed neural structure is fabricated using TSMC 65 nm CMOS technology. The proposed neuron and synapse occupy an area of 127 um2 and 231 um2, respectively, while achieving millisecond time constants. Actual chip measurements show that the proposed structure successfully implements the temporal signal communication function with millisecond time constants, which is a critical step toward hardware reservoir computing for human-computer interaction.