 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stochastic Contextual Bandits with Long Horizon Rewards
Feb 03, 2023

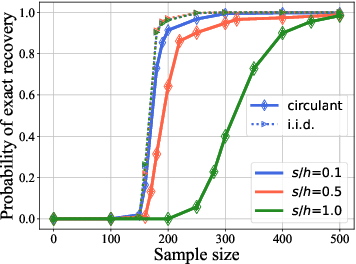
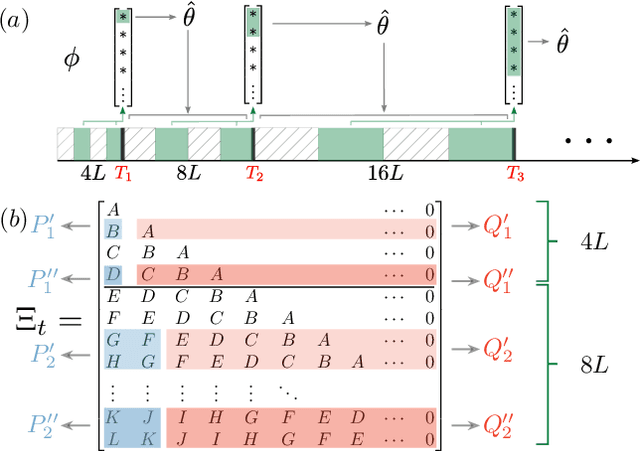
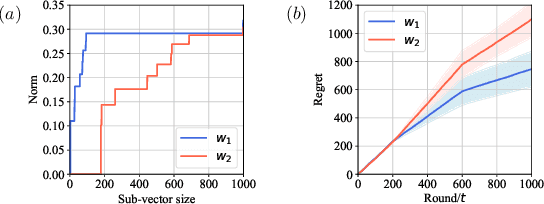
The growing interest in complex decision-making and language modeling problems highlights the importance of sample-efficient learning over very long horizons. This work takes a step in this direction by investigating contextual linear bandits where the current reward depends on at most $s$ prior actions and contexts (not necessarily consecutive), up to a time horizon of $h$. In order to avoid polynomial dependence on $h$, we propose new algorithms that leverage sparsity to discover the dependence pattern and arm parameters jointly. We consider both the data-poor ($T<h$) and data-rich ($T\ge h$) regimes, and derive respective regret upper bounds $\tilde O(d\sqrt{sT} +\min\{ q, T\})$ and $\tilde O(\sqrt{sdT})$, with sparsity $s$, feature dimension $d$, total time horizon $T$, and $q$ that is adaptive to the reward dependence pattern. Complementing upper bounds, we also show that learning over a single trajectory brings inherent challenges: While the dependence pattern and arm parameters form a rank-1 matrix, circulant matrices are not isometric over rank-1 manifolds and sample complexity indeed benefits from the sparse reward dependence structure. Our results necessitate a new analysis to address long-range temporal dependencies across data and avoid polynomial dependence on the reward horizon $h$. Specifically, we utilize connections to the restricted isometry property of circulant matrices formed by dependent sub-Gaussian vectors and establish new guarantees that are also of independent interest.
TT-TFHE: a Torus Fully Homomorphic Encryption-Friendly Neural Network Architecture
Feb 03, 2023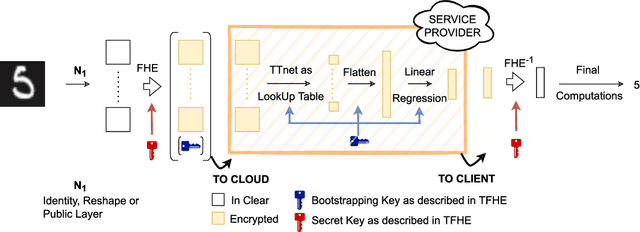
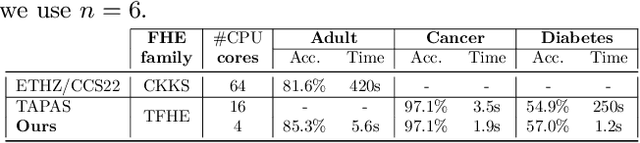
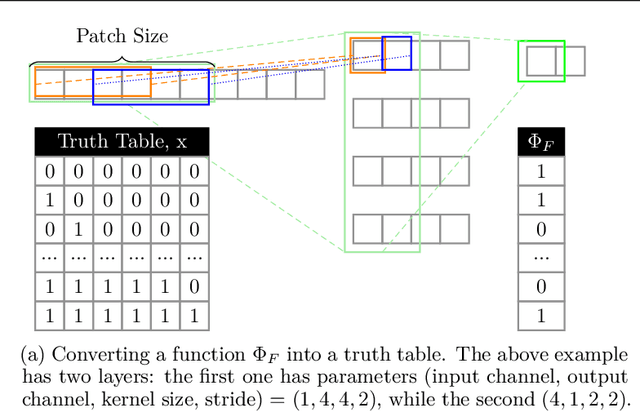
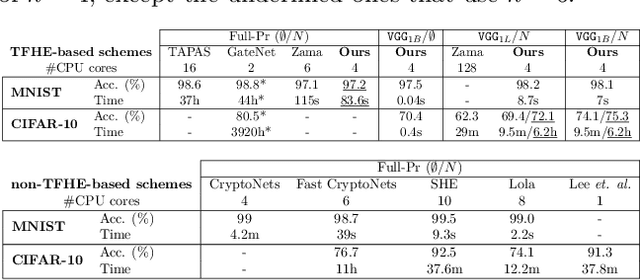
This paper presents TT-TFHE, a deep neural network Fully Homomorphic Encryption (FHE) framework that effectively scales Torus FHE (TFHE) usage to tabular and image datasets using a recent family of convolutional neural networks called Truth-Table Neural Networks (TTnet). The proposed framework provides an easy-to-implement, automated TTnet-based design toolbox with an underlying (python-based) open-source Concrete implementation (CPU-based and implementing lookup tables) for inference over encrypted data. Experimental evaluation shows that TT-TFHE greatly outperforms in terms of time and accuracy all Homomorphic Encryption (HE) set-ups on three tabular datasets, all other features being equal. On image datasets such as MNIST and CIFAR-10, we show that TT-TFHE consistently and largely outperforms other TFHE set-ups and is competitive against other HE variants such as BFV or CKKS (while maintaining the same level of 128-bit encryption security guarantees). In addition, our solutions present a very low memory footprint (down to dozens of MBs for MNIST), which is in sharp contrast with other HE set-ups that typically require tens to hundreds of GBs of memory per user (in addition to their communication overheads). This is the first work presenting a fully practical solution of private inference (i.e. a few seconds for inference time and a few dozens MBs of memory) on both tabular datasets and MNIST, that can easily scale to multiple threads and users on server side.
YOLO v3: Visual and Real-Time Object Detection Model for Smart Surveillance Systems(3s)
Sep 26, 2022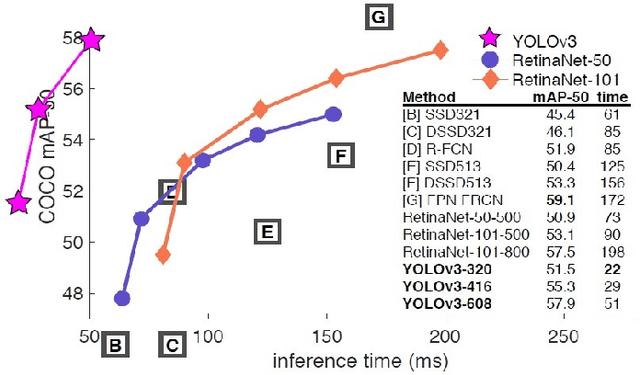



Can we see it all? Do we know it All? These are questions thrown to human beings in our contemporary society to evaluate our tendency to solve problems. Recent studies have explored several models in object detection; however, most have failed to meet the demand for objectiveness and predictive accuracy, especially in developing and under-developed countries. Consequently, several global security threats have necessitated the development of efficient approaches to tackle these issues. This paper proposes an object detection model for cyber-physical systems known as Smart Surveillance Systems (3s). This research proposes a 2-phase approach, highlighting the advantages of YOLO v3 deep learning architecture in real-time and visual object detection. A transfer learning approach was implemented for this research to reduce training time and computing resources. The dataset utilized for training the model is the MS COCO dataset which contains 328,000 annotated image instances. Deep learning techniques such as Pre-processing, Data pipelining, and detection was implemented to improve efficiency. Compared to other novel research models, the proposed model's results performed exceedingly well in detecting WILD objects in surveillance footages. An accuracy of 99.71% was recorded, with an improved mAP of 61.5.
Accelerating Guided Diffusion Sampling with Splitting Numerical Methods
Jan 27, 2023
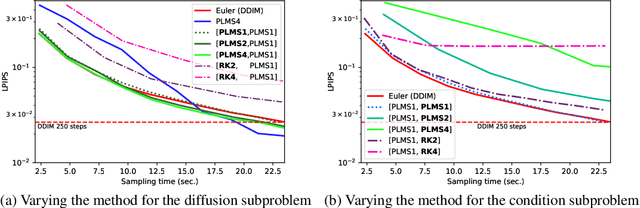
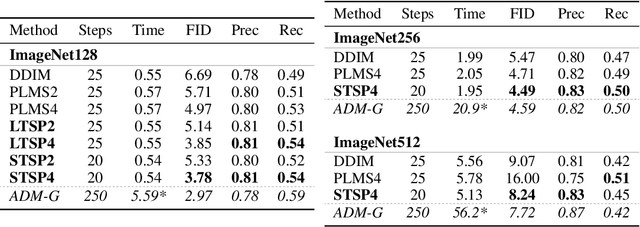
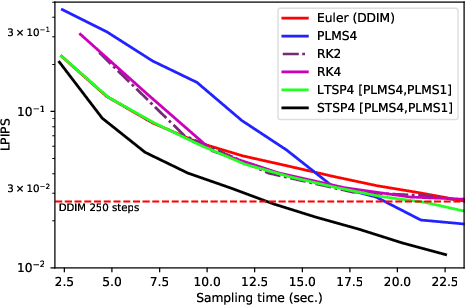
Guided diffusion is a technique for conditioning the output of a diffusion model at sampling time without retraining the network for each specific task. One drawback of diffusion models, however, is their slow sampling process. Recent techniques can accelerate unguided sampling by applying high-order numerical methods to the sampling process when viewed as differential equations. On the contrary, we discover that the same techniques do not work for guided sampling, and little has been explored about its acceleration. This paper explores the culprit of this problem and provides a solution based on operator splitting methods, motivated by our key finding that classical high-order numerical methods are unsuitable for the conditional function. Our proposed method can re-utilize the high-order methods for guided sampling and can generate images with the same quality as a 250-step DDIM baseline using 32-58% less sampling time on ImageNet256. We also demonstrate usage on a wide variety of conditional generation tasks, such as text-to-image generation, colorization, inpainting, and super-resolution.
A Ray-tracing and Deep Learning Fusion Super-resolution Modeling Method for Wireless Mobile Channel
Jan 27, 2023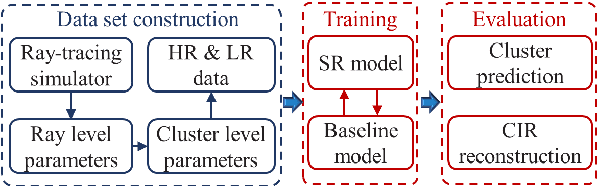
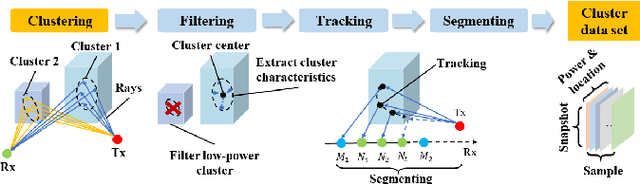
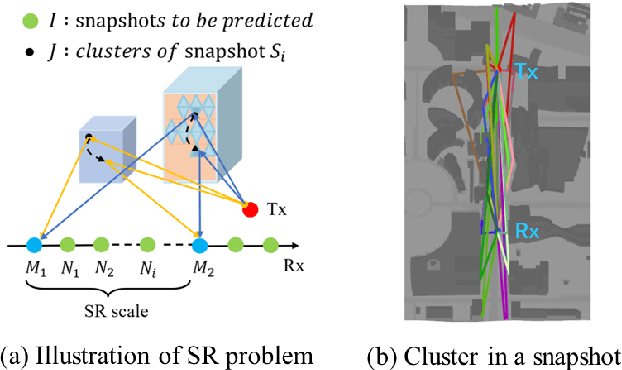
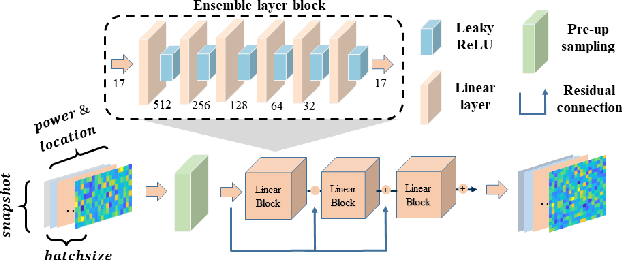
Mobile channel modeling has always been the core part for design, deployment and optimization of communication system, especially in 5G and beyond era. Deterministic channel modeling could precisely achieve mobile channel description, however with defects of equipment and time consuming. In this paper, we proposed a novel super resolution (SR) model for cluster characteristics prediction. The model is based on deep neural networks with residual connection. A series of simulations at 3.5 GHz are conducted by a three-dimensional ray tracing (RT) simulator in diverse scenarios. Cluster characteristics are extracted and corresponding data sets are constructed to train the model. Experiments demonstrate that the proposed SR approach could achieve better power and cluster location prediction performance than traditional interpolation method and the root mean square error (RMSE) drops by 51% and 78% relatively. Channel impulse response (CIR) is reconstructed based on cluster characteristics, which could match well with the multi-path component (MPC). The proposed method can be used to efficiently and accurately generate big data of mobile channel, which significantly reduces the computation time of RT-only.
Bi-AM-RRT*: A Fast and Efficient Sampling-Based Motion Planning Algorithm in Dynamic Environments
Jan 27, 2023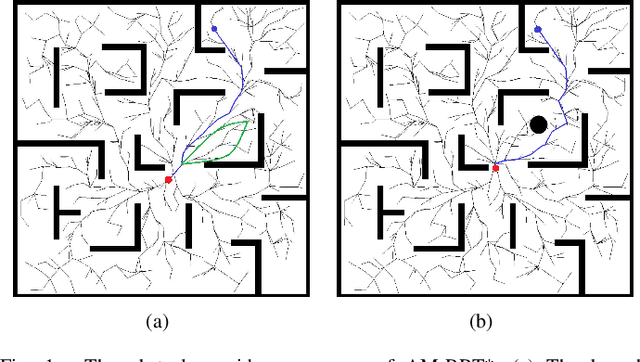
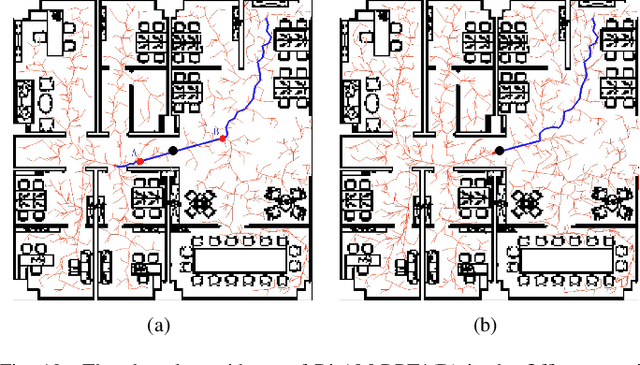
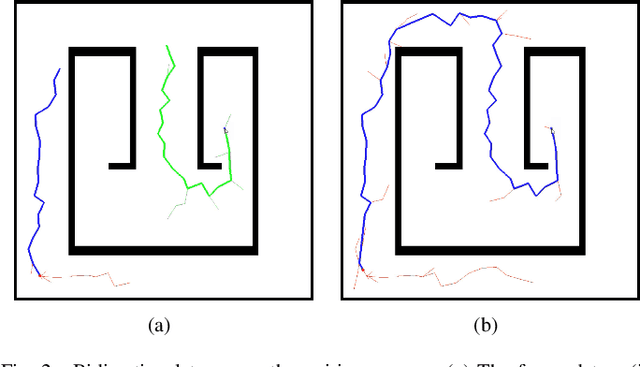
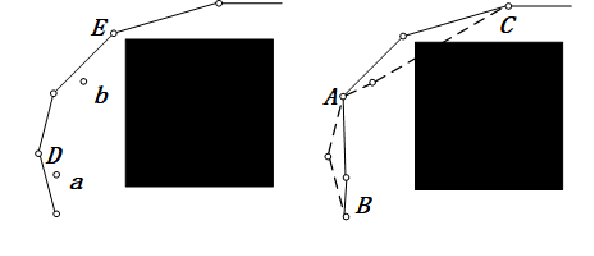
The efficiency of sampling-based motion planning brings wide application in autonomous mobile robots. Conventional rapidly exploring random tree (RRT) algorithm and its variants have gained great successes, but there are still challenges for the real-time optimal motion planning of mobile robots in dynamic environments. In this paper, based on Bidirectional RRT (Bi-RRT) and the use of an assisting metric (AM), we propose a novel motion planning algorithm, namely Bi-AM-RRT*. Different from the existing RRT-based methods, the AM is introduced in this paper to optimize the performance of robot motion planning in dynamic environments with obstacles. On this basis, the bidirectional search sampling strategy is employed, in order to increase the planning efficiency. Further, we present an improved rewiring method to shorten path lengths. The effectiveness and efficiency of the proposed Bi-AM-RRT* are proved through comparative experiments in different environments. Experimental results show that the Bi-AM-RRT* algorithm can achieve better performance in terms of path length and search time.
Improving Interpretability via Explicit Word Interaction Graph Layer
Feb 03, 2023
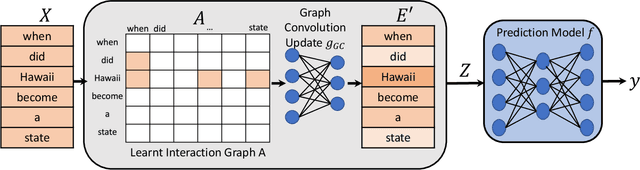
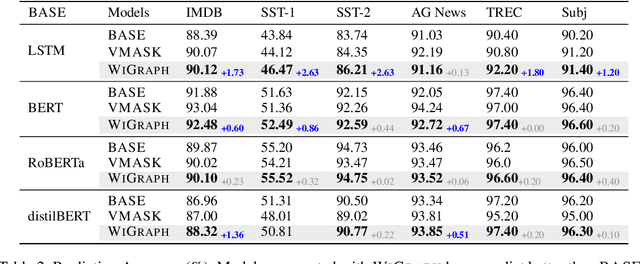
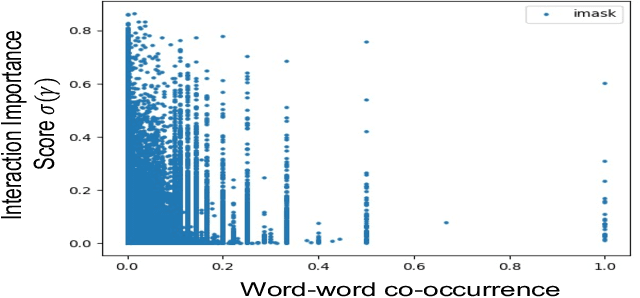
Recent NLP literature has seen growing interest in improving model interpretability. Along this direction, we propose a trainable neural network layer that learns a global interaction graph between words and then selects more informative words using the learned word interactions. Our layer, we call WIGRAPH, can plug into any neural network-based NLP text classifiers right after its word embedding layer. Across multiple SOTA NLP models and various NLP datasets, we demonstrate that adding the WIGRAPH layer substantially improves NLP models' interpretability and enhances models' prediction performance at the same time.
* 15 pages, AAAI 2023
Network-Assisted Full-Duplex Cell-Free mmWave Massive MIMO Systems with DAC Quantization and Fronthaul Compression
Feb 17, 2023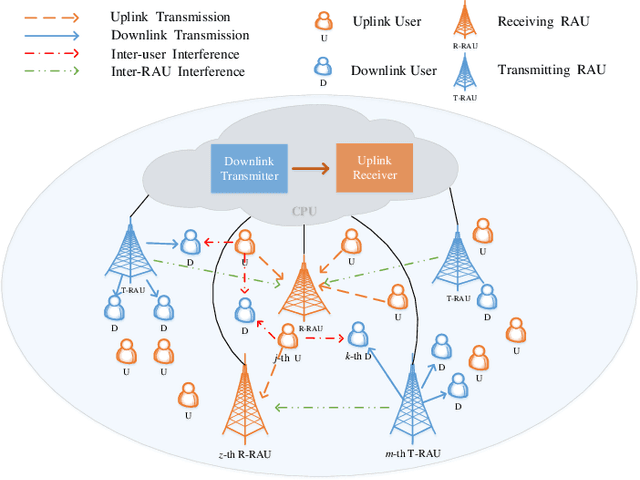
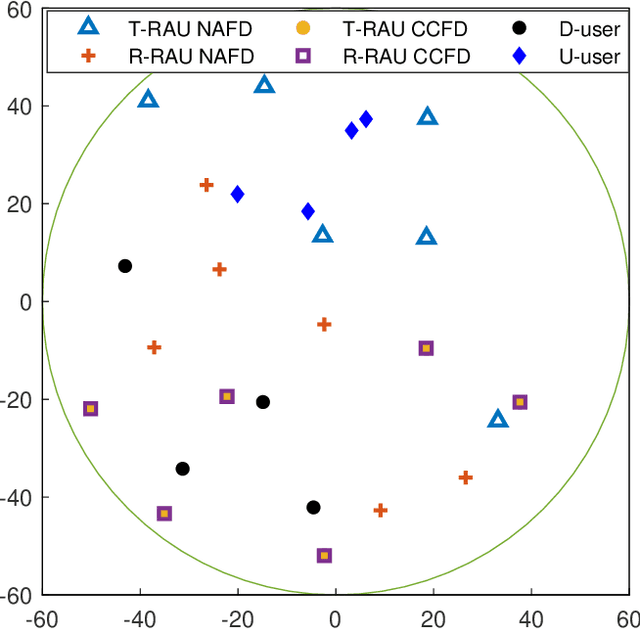
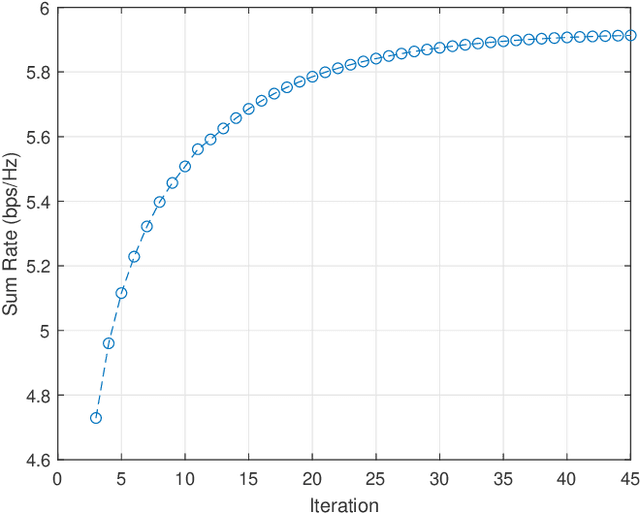
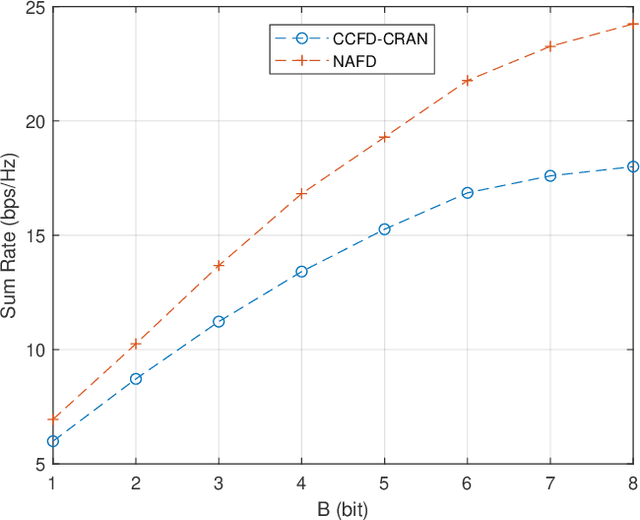
In this paper, we investigate network-assisted full-duplex (NAFD) cell-free millimeter-wave (mmWave) massive multiple-input multiple-output (MIMO) systems with digital-to-analog converter (DAC) quantization and fronthaul compression. We propose to maximize the weighted uplink and downlink sum rate by jointly optimizing the power allocation of both the transmitting remote antenna units (T-RAUs) and uplink users and the variances of the downlink and uplink fronthaul compression noises. To deal with this challenging problem, we further apply a successive convex approximation (SCA) method to handle the non-convex bidirectional limited-capacity fronthaul constraints. The simulation results verify the convergence of the proposed SCA-based algorithm and analyze the impact of fronthaul capacity and DAC quantization on the spectral efficiency of the NAFD cell-free mmWave massive MIMO systems. Moreover, some insightful conclusions are obtained through the comparisons of spectral efficiency, which shows that NAFD achieves better performance gains than co-time co-frequency full-duplex cloud radio access network (CCFD C-RAN) in the cases of practical limited-resolution DACs. Specifically, their performance gaps with 8-bit DAC quantization are larger than that with 1-bit DAC quantization, which attains a 5.5-fold improvement.
OTFS Signaling for SCMA With Coordinated Multi-Point Vehicle Communications
Feb 17, 2023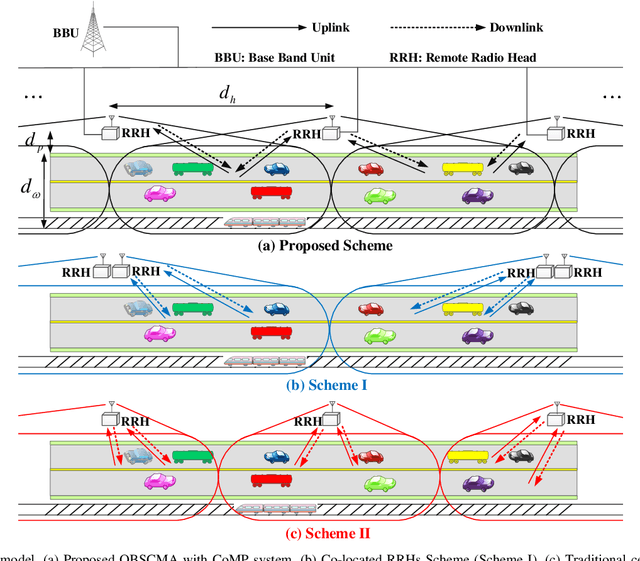
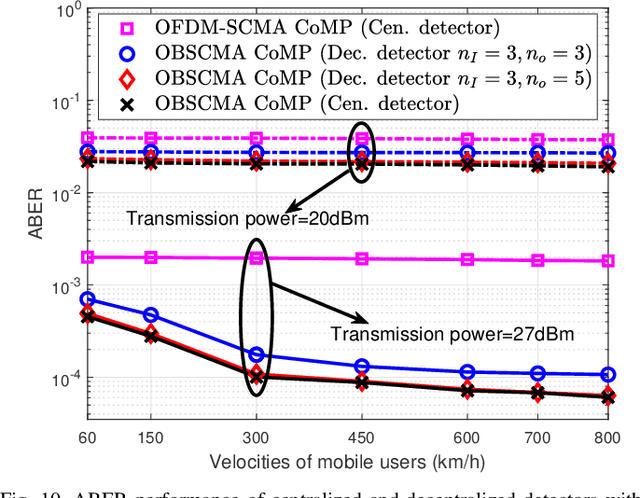
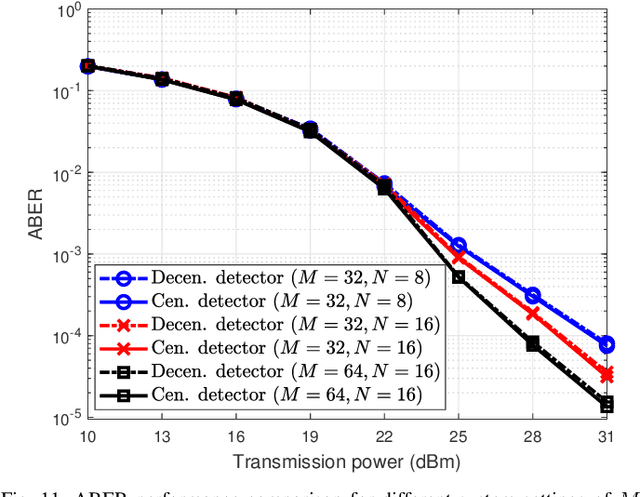

This paper investigates an uplink coordinated multi-point (CoMP) coverage scenario, in which multiple mobile users are grouped for sparse code multiple access (SCMA), and served by the remote radio head (RRH) in front of them and the RRH behind them simultaneously. We apply orthogonal time frequency space (OTFS) modulation for each user to exploit the degrees of freedom arising from both the delay and Doppler domains. As the signals received by the RRHs in front of and behind the users experience respectively positive and negative Doppler frequency shifts, our proposed OTFS-based SCMA (OBSCMA) with CoMP system can effectively harvest extra Doppler and spatial diversity for better performance. Based on maximum likelihood (ML) detector, we analyze the single-user average bit error rate (ABER) bound as the benchmark of the ABER performance for our proposed OBSCMA with CoMP system. We also develop a customized Gaussian approximation with expectation propagation (GAEP) algorithm for multi-user detection and propose efficient algorithm structures for centralized and decentralized detectors. Our proposed OBSCMA with CoMP system leads to stronger performance than the existing solutions. The proposed centralized and decentralized detectors exhibit effective reception and robustness under channel state information uncertainty.
Designing Equitable Algorithms
Feb 17, 2023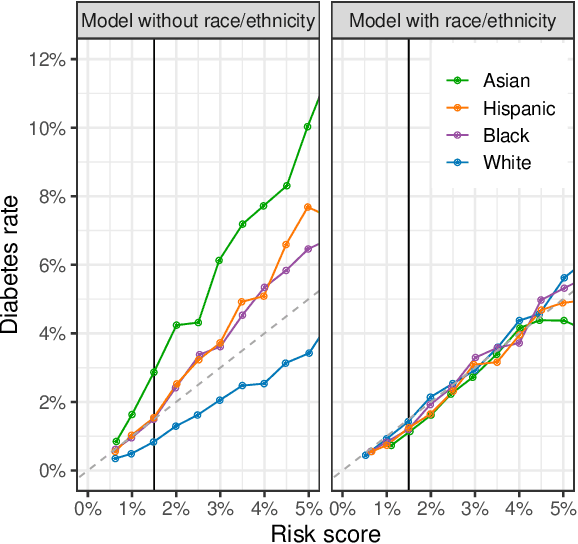
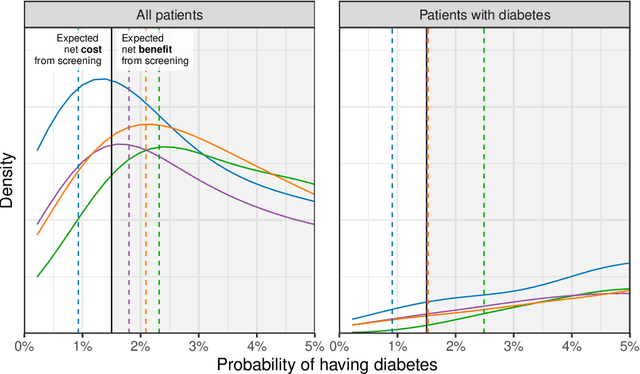
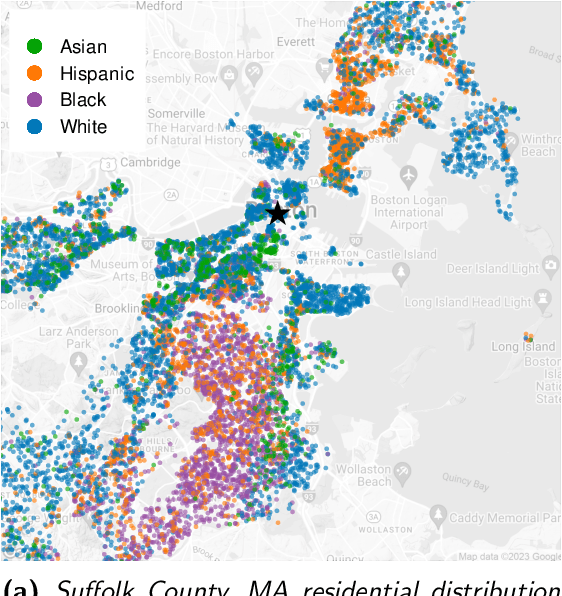
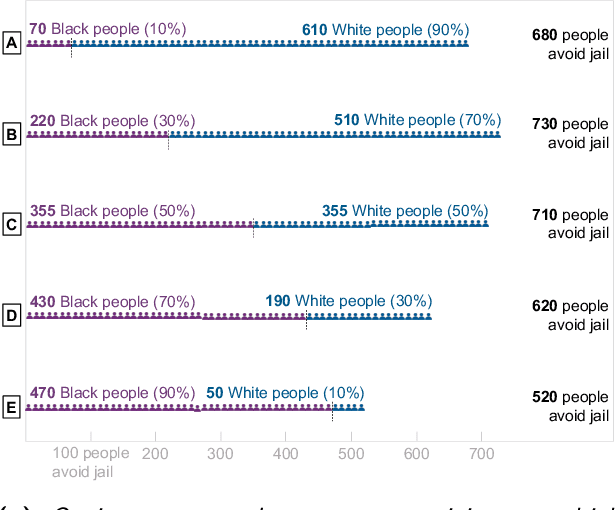
Predictive algorithms are now used to help distribute a large share of our society's resources and sanctions, such as healthcare, loans, criminal detentions, and tax audits. Under the right circumstances, these algorithms can improve the efficiency and equity of decision-making. At the same time, there is a danger that the algorithms themselves could entrench and exacerbate disparities, particularly along racial, ethnic, and gender lines. To help ensure their fairness, many researchers suggest that algorithms be subject to at least one of three constraints: (1) no use of legally protected features, such as race, ethnicity, and gender; (2) equal rates of "positive" decisions across groups; and (3) equal error rates across groups. Here we show that these constraints, while intuitively appealing, often worsen outcomes for individuals in marginalized groups, and can even leave all groups worse off. The inherent trade-off we identify between formal fairness constraints and welfare improvements -- particularly for the marginalized -- highlights the need for a more robust discussion on what it means for an algorithm to be "fair". We illustrate these ideas with examples from healthcare and the criminal-legal system, and make several proposals to help practitioners design more equitable algorithms.